YOLOv10实战:一种新的自适应阈值焦点损失函数loss,更多的注意力分配给目标特征 | NEU-DET为案列进行展开
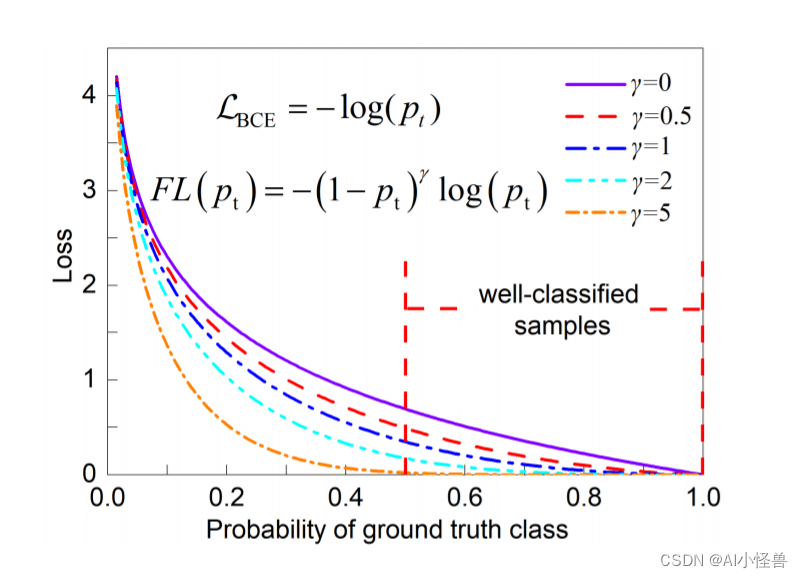
一种新的自适应阈值焦点损失函数loss,1)mAP50从0.683提升至0.702
💡💡💡本文改进:提出了一种新的自适应阈值焦点损失函数,该函数将目标和背景解耦,并利用自适应机制来调整损失权重,迫使模型将更多的注意力分配给目标特征。
一种新的自适应阈值焦点损失函数loss,1)mAP50从0.683提升至0.702
原文链接:
YOLOv10涨点改进:loss优化 |一种新的自适应阈值焦点损失函数loss,更多的注意力分配给目标特征,助力红外小目标暴力涨点-CSDN博客
1.YOLOv10介绍

论文: https://arxiv.org/pdf/2405.14458
代码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成为实时目标检测领域的主导范例。研究人员已经探索了YOLOS的架构设计、优化目标、数据增强策略等,并取得了显著进展。然而,对用于后处理的非最大抑制(NMS)的依赖妨碍了YOLOS的端到端部署,并且影响了推理延迟。此外,YOLOS中各部件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的性能。这导致次优的效率,以及相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOS的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法带来了有竞争力的性能和低推理延迟。此外,我们还介绍了YOLOS的整体效率-精度驱动模型设计策略。我们从效率和精度两个角度对YOLOS的各个组件进行了全面优化,大大降低了计算开销,增强了性能。我们努力的成果是用于实时端到端对象检测的新一代YOLO系列,称为YOLOV10。广泛的实验表明,YOLOV10在各种模型规模上实现了最先进的性能和效率。例如,在COCO上的类似AP下,我们的YOLOV10-S比RT-DETR-R18快1.8倍,同时具有2.8倍更少的参数和FLOPS。与YOLOV9-C相比,YOLOV10-B在性能相同的情况下,延迟减少了46%,参数减少了25%。

1.1 C2fUIB介绍
为了解决这个问题,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计降低被证明是冗余的阶段复杂度。我们首先提出了一个紧凑的倒置块(CIB)结构,它采用廉价的深度可分离卷积进行空间混合,以及成本效益高的点对点卷积进行通道混合
C2fUIB只是用CIB结构替换了YOLOv8中 C2f的Bottleneck结构
实现代码ultralytics/nn/modules/block.py


class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))1.2 PSA介绍
具体来说,我们在1×1卷积后将特征均匀地分为两部分。我们只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
实现代码ultralytics/nn/modules/block.py

class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))1.3 SCDown
OLOs通常利用常规的3×3标准卷积,步长为2,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本O(9HWC^2)和参数数量O(18C^2)。相反,我们提议将空间缩减和通道增加操作解耦,以实现更高效的下采样。具体来说,我们首先利用点对点卷积来调整通道维度,然后利用深度可分离卷积进行空间下采样。这将计算成本降低到O(2HWC^2 + 9HWC),并将参数数量减少到O(2C^2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在减少延迟的同时保持了有竞争力的性能。
实现代码ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))2.YOLOv10魔改提升精度
2.1 一种新的自适应阈值焦点损失函数loss
原文链接:
YOLOv10涨点改进:loss优化 |一种新的自适应阈值焦点损失函数loss,更多的注意力分配给目标特征,助力红外小目标暴力涨点-CSDN博客
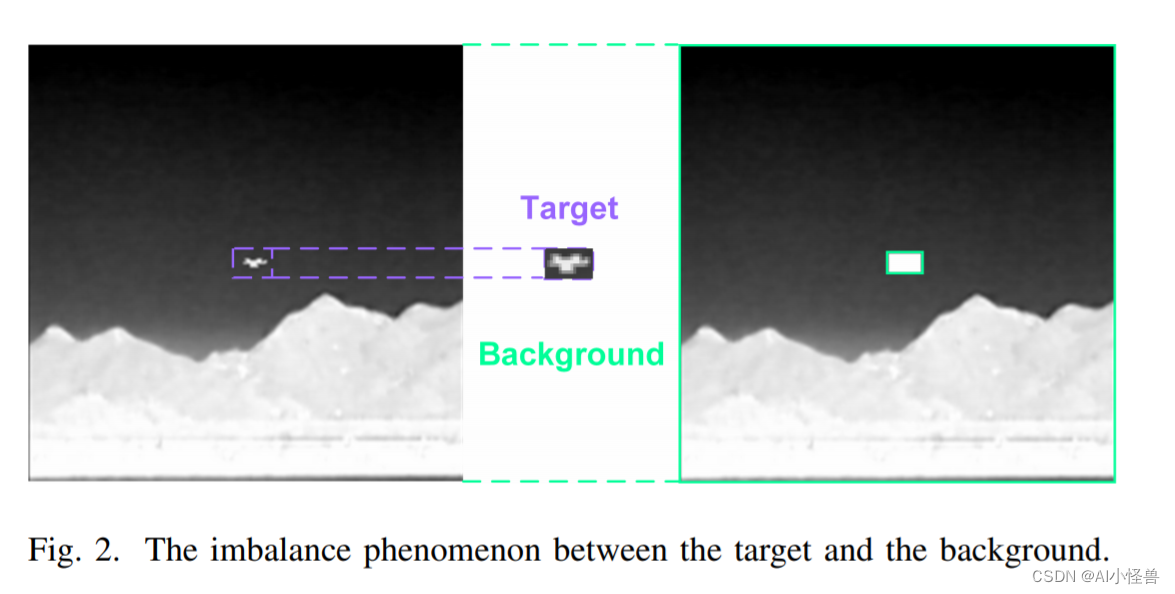
红外图像主要由背景组成,只有一小部分被目标占据,如图所示。因此,在训练过程中学习背景的特征比学习目标的特征更容易。背景可以看作是简单样本,目标可以看作是难样本。然而,即使是良好的学习背景,在训练过程中仍然会产生损失。实际上,占据红外图像主体部分的背景样本主导了梯度更新方向,淹没了目标信息。为了解决这个问题,我们提出了一个新的ATFL函数。首先,利用阈值设置将易识别的背景与难识别的目标解耦;其次,通过强化与目标相关的损失,减轻与背景相关的损失,我们迫使模型将更多的注意力分配到目标特征上,从而缓解目标与背景之间的不平衡。最后,将自适应设计应用于超参数,以减少调整超参数所带来的时间消耗。

我们提出了一种基于设定阈值解耦目标和背景的ATFL。根据预测概率值自适应调整损失值,旨在提高红外小目标的检测性能。
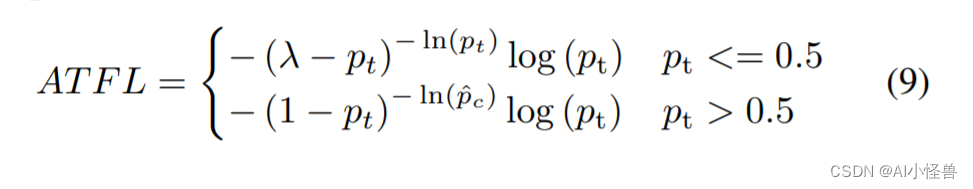
2.2 NEU-DET数据集为案列进行对比实验
NEU-DET钢材表面缺陷共有六大类,一共1800张,
类别分别为:'crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches'

2.3 实验结果分析
2.3.1 训练方式
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOv10
if __name__ == '__main__':
model = YOLOv10('ultralytics/cfg/models/v10/yolov10n-EMA_attention.yaml')
#model.load('yolov10n.pt') # loading pretrain weights
model.train(data='data/NEU-DET.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)原始YOLOv10n结果如下:
原始mAP50为0.683
YOLOv10n summary (fused): 285 layers, 2696756 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:12<00:00, 1.27it/s]
all 486 1069 0.634 0.662 0.683 0.392
crazing 486 149 0.409 0.248 0.298 0.0996
inclusion 486 222 0.677 0.774 0.768 0.411
patches 486 243 0.789 0.868 0.905 0.582
pitted_surface 486 130 0.752 0.722 0.757 0.492
rolled-in_scale 486 171 0.549 0.561 0.561 0.263
scratches 486 154 0.63 0.797 0.807 0.505
2.3.2 自适应阈值焦点损失函数loss
实验结果如下:
mAP50从0.683提升至0.702
YOLOv10n summary (fused): 301 layers, 2831604 parameters, 0 gradients, 8.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 16/16 [00:10<00:00, 1.46it/s]
all 486 1069 0.668 0.657 0.702 0.393
crazing 486 149 0.525 0.295 0.396 0.149
inclusion 486 222 0.69 0.73 0.777 0.428
patches 486 243 0.828 0.869 0.909 0.593
pitted_surface 486 130 0.77 0.738 0.778 0.485
rolled-in_scale 486 171 0.583 0.541 0.572 0.272
scratches 486 154 0.612 0.766 0.782 0.43 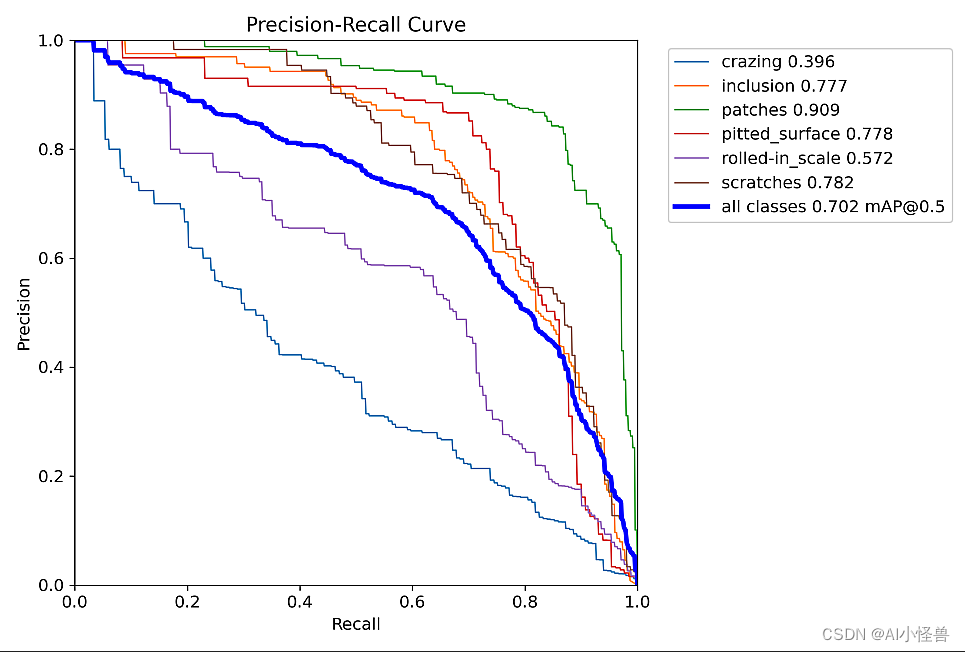
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!
欢迎点赞关注 订阅专栏,文末附微信!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 39
39 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)