【全网最全】RAG评估指南:全面解析评估指标并提供代码示例
最近我一直在关注和优化RAG(Retrieval-Augmented Generation)相关的内容,总结了一下RAG的痛点和最佳实践,然后重点会介绍如何评估RAG。
一、RAG痛点介绍
最近我一直在关注和优化RAG(Retrieval-Augmented Generation)相关的内容,总结了一下RAG的痛点和最佳实践,然后重点会介绍如何评估RAG。


二、RAG痛点优化
认识了RAG的痛点,就知道如何进行优化了,下面是RAG最佳实践的总结。
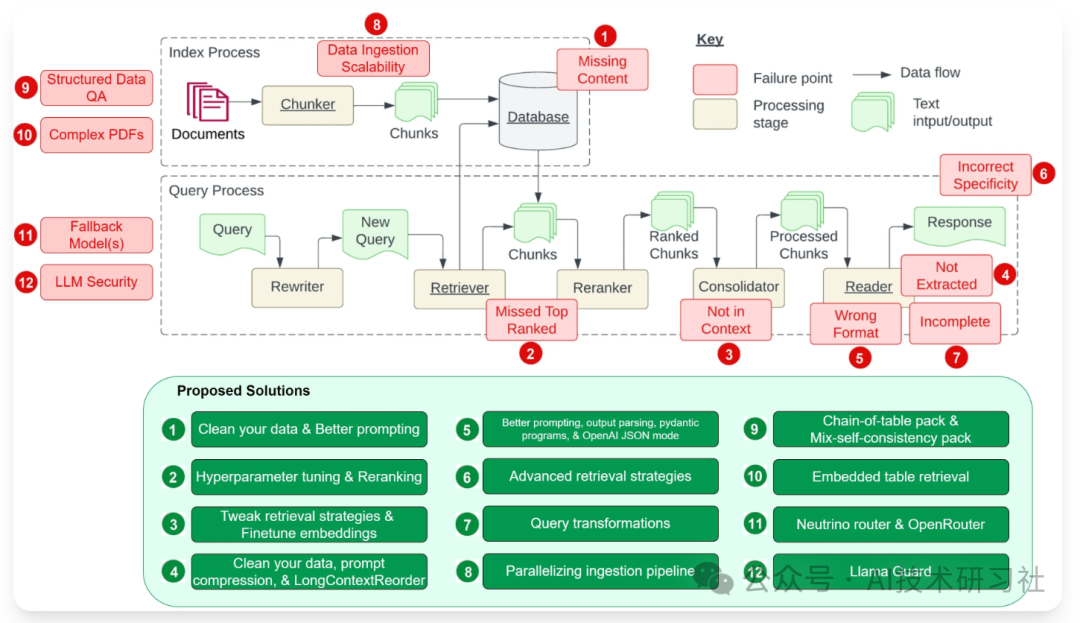
首先,总结一下日常对RAG(Retrieval-Augmented Generation)的最佳实践中,通常会涉及以下关键问题和优化策略:
1. 数据如何处理的?
-
清洗和预处理:在使用数据之前,确保数据是干净和结构化的。这可能包括去除噪音、处理缺失值、标准化格式等。
-
分段和标注:将长文档分成较小的段落(chunks),并为每个段落添加相关标签或元数据,以便更好地进行检索和生成。
import pandas as pd`` ``# 读取数据``data = pd.read_csv('data.csv')`` ``# 数据清洗``data.dropna(inplace=True) # 去除缺失值``data['text'] = data['text'].str.lower() # 转换为小写``data['text'] = data['text'].str.replace(r'\d+', '', regex=True) # 去除数字`` ``# 数据分段和标注``def chunk_text(text, chunk_size=200):` `words = text.split()` `chunks = [' '.join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)]` `return chunks`` ``data['chunks'] = data['text'].apply(chunk_text)``
2. chunk-size如何设置的?
-
优化长度:chunk-size的设置需要平衡信息量和检索效率。一般来说,较短的chunk可以提高检索的准确性,但可能会丢失上下文信息;较长的chunk可以保留更多的上下文,但可能会增加冗余信息。常见的chunk大小在100到300个词之间,根据具体应用场景进行调整。
# 设置chunk大小``chunk_size = 150 # 例如设置为150个词`` ``# 分段函数``def chunk_text(text, chunk_size):` `words = text.split()` `chunks = [' '.join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)]` `return chunks`` ``data['chunks'] = data['text'].apply(lambda x: chunk_text(x, chunk_size))``
3. Embedding模型使用的什么?
-
选择合适的模型:常用的embedding模型包括BERT、RoBERTa、Sentence-BERT等。选择时需要考虑模型的性能、训练数据和计算资源。
from sentence_transformers import SentenceTransformer`` ``# 使用Sentence-BERT模型``model = SentenceTransformer('paraphrase-MiniLM-L6-v2')`` ``# 对数据进行embedding``embeddings = model.encode(data['chunks'].sum()) -
自定义训练:对于特定领域的应用,可以考虑对预训练模型进行微调,以提高嵌入的相关性和准确性。
from transformers import BertTokenizer, BertModel``import torch`` ``# 加载预训练模型和tokenizer``tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')``model = BertModel.from_pretrained('bert-base-uncased')`` ``# 微调模型``# 假设我们有一个自定义数据集custom_dataset``# for batch in custom_dataset:``# inputs = tokenizer(batch['text'], return_tensors='pt', padding=True, truncation=True)``# outputs = model(**inputs)``# # 在这里添加微调逻辑`` ``# 对数据进行embedding``inputs = tokenizer(data['chunks'].sum(), return_tensors='pt', padding=True, truncation=True)``with torch.no_grad():` `outputs = model(**inputs)``embeddings = outputs.last_hidden_state.mean(dim=1)``
4. Prompt如何设计?
-
Prompt设计:设计有效的prompt以引导生成模型产生所需的回答。Prompt应尽量清晰、具体,避免模糊或开放性太强。
# 示例prompt设计``prompt_template = "请根据以下内容回答问题:\n\n内容:{}\n\n问题:{}"`` ``def create_prompt(content, question):` `return prompt_template.format(content, question)`` ``# 使用示例``content = "这是一个示例内容。"``question = "这段内容的主要观点是什么?"``prompt = create_prompt(content, question)``
5. 检索的topN如何设置?
-
检索的topN设置:topN设置决定了在生成过程中使用多少个最相关的文档段落。常见的topN值在3到10之间,根据检索效果和生成质量进行调整。
from sklearn.metrics.pairwise import cosine_similarity``import numpy as np`` ``# 假设我们有一个查询的embedding``query_embedding = model.encode("示例查询")`` ``# 计算相似度``similarities = cosine_similarity([query_embedding], embeddings)[0]`` ``# 设置topN值``topN = 5`` ``# 获取最相似的topN个结果``topN_indices = np.argsort(similarities)[-topN:][::-1]``topN_chunks = [data['chunks'].sum()[i] for i in topN_indices]``

6. LLM模型选择的什么?
-
选择合适的生成模型:常用的大语言模型(LLM)包括GPT-3.5、GPT-4、4o等。选择时需要考虑模型的生成能力、推理速度和计算资源。
-
混合使用模型:在一些场景下,可以同时使用多个模型来提高生成效果,例如结合检索模型和生成模型的优势。
7. RAG检索生成效果优化策略
通过不断地实验和优化,可以找到最适合特定应用场景的RAG配置,从而实现更好的检索和生成效果。
经过各种优化之后,对RAG来说,最重要的就是如何评估其效果。
 三、为什么需要对RAG系统评估?
三、为什么需要对RAG系统评估?
评估是AI开发流程中的一个非常关键步骤,它被用于检查当前策略相对于其他策略的有效性,或在当你对流程进行更改时进行评估。因此在进行LLM项目的开发和改进时,必须要有衡量其表现的方法。
LlamaIndex中RAG处理过程(图片来源:https://docs.llamaindex.ai/en/stable/getting_started/concepts/ ):

为了评估RAG系统,我们通常使用两种类型的评估:
-
检索评估
-
响应评估
与传统的机器学习技术不同,传统技术有明确定量的度量指标(如Gini系数、R平方、AIC、BIC、混淆矩阵等),评估RAG系统更加复杂。这种复杂性的原因在于RAG系统生成的响应是非结构化文本,需要结合定性和定量指标来准确评估其性能。
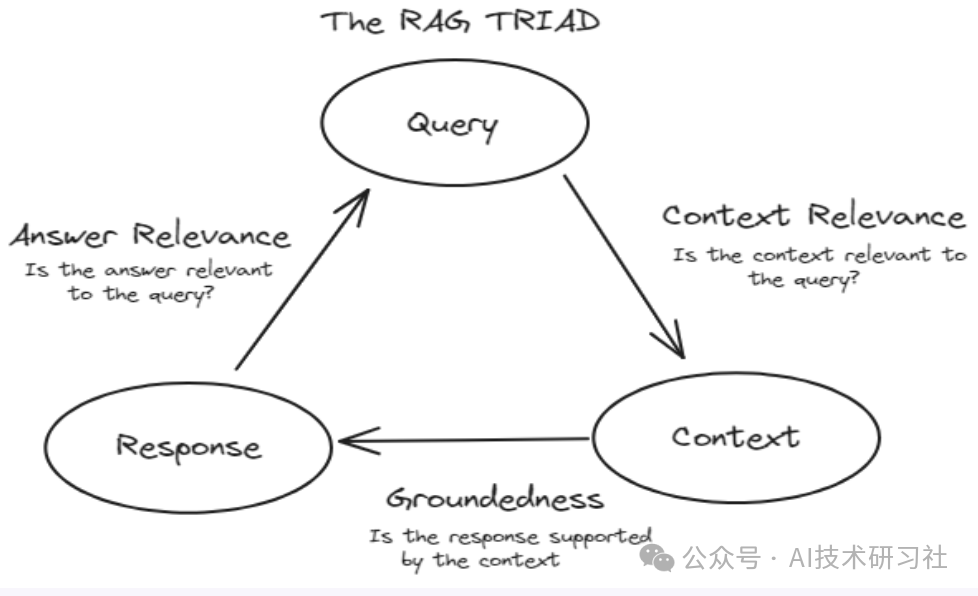
为了有效评估RAG系统,我们通常遵循TRIAD框架。该框架由三个主要组成部分组成:
-
上下文相关性:这个组件评估RAG系统的检索部分。它评估从大型数据集中准确检索到的文档。这里使用的度量指标包括精确度、召回率、MRR和MAP。
-
忠实度(基于检索):这个组件属于响应评估。它检查生成的响应是否准确无误,并且基于检索到的文档。通过人工评估、自动事实检查工具和一致性检查等方法来评估忠实度。
-
答案相关性:这也是响应评估的一部分。它衡量生成的响应对用户的查询提供了多少有用的信息。使用的度量指标包括BLEU、ROUGE、METEOR和基于嵌入的评估。
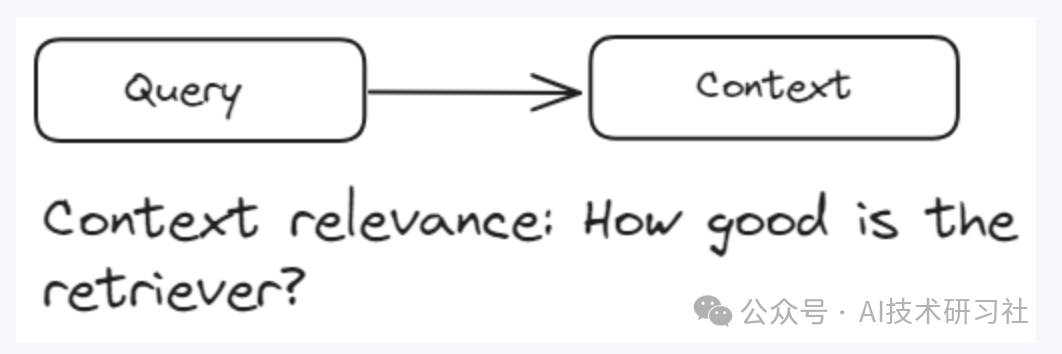
检索评估适用于RAG系统的检索器组件,该组件通常使用向量数据库。这些评估衡量检索器在响应用户查询时识别和排名相关文档的效果。检索评估的主要目标是评估上下文相关性,即检索到的文档与用户查询的匹配程度。它确保提供给生成组件的上下文是相关和准确的。
精确度
精确度衡量了检索到的文档的准确性。它是检索到的相关文档数量与检索到的文档总数之比。定义如下:

这意味着精确度评估了系统检索到的文档中有多少实际与用户查询相关。例如,如果检索器检索到了10个文档,其中7个是相关的,那么精确度将是0.7或70%。
def calculate_precision(retrieved_docs, relevant_docs):` `"""` `计算精确度`` ` `参数:` `retrieved_docs (list): 检索到的文档列表` `relevant_docs (list): 相关文档列表`` ` `返回:` `float: 精确度` `"""` `# 计算检索到的相关文档数量` `relevant_retrieved_docs = [doc for doc in retrieved_docs if doc in relevant_docs]`` ` `# 计算精确度` `precision = len(relevant_retrieved_docs) / len(retrieved_docs) if retrieved_docs else 0` `return precision`` ``# 示例数据``retrieved_docs = ['doc1', 'doc2', 'doc3', 'doc4', 'doc5']``relevant_docs = ['doc2', 'doc4', 'doc6']`` ``# 计算精确度``precision = calculate_precision(retrieved_docs, relevant_docs)``print(f"精确度: {precision:.2f}")``
精确度评估的是“系统检索到的所有文档中,有多少实际上是相关的?”
在可能导致负面后果的情况下,精确度尤为重要。例如,在医学信息检索系统中,高精确度至关重要,因为提供不相关的医学文档可能导致错误信息和潜在的有害结果。
召回率
召回率衡量了检索到的文档的全面性。它是检索到的相关文档数量与数据库中相关文档的总数之比。定义如下:

这意味着召回率评估了数据库中存在的相关文档有多少被系统成功检索到。
def calculate_recall(retrieved_docs, relevant_docs):` `"""` `计算召回率`` ` `参数:` `retrieved_docs (list): 检索到的文档列表` `relevant_docs (list): 相关文档列表`` ` `返回:` `float: 召回率` `"""` `# 计算检索到的相关文档数量` `relevant_retrieved_docs = [doc for doc in retrieved_docs if doc in relevant_docs]`` ` `# 计算召回率` `recall = len(relevant_retrieved_docs) / len(relevant_docs) if relevant_docs else 0` `return recall`` ``# 示例数据``retrieved_docs = ['doc1', 'doc2', 'doc3', 'doc4', 'doc5']``relevant_docs = ['doc2', 'doc4', 'doc6', 'doc7']`` ``# 计算召回率``recall = calculate_recall(retrieved_docs, relevant_docs)``print(f"召回率: {recall:.2f}")``
召回率评估的是“数据库中存在的所有相关文档中,系统成功检索到了多少个?”
在可能错过相关信息会产生成本的情况下,召回率至关重要。例如,在法律信息检索系统中,高召回率至关重要,因为未能检索到相关的法律文件可能导致不完整的案例研究,并可能影响法律诉讼的结果。
精确度和召回率的平衡
通常需要平衡精确度和召回率,因为改善其中一个指标有时会降低另一个指标。目标是找到适合特定应用需求的最佳平衡。这种平衡有时可以用F1分数来量化,F1分数是精确度和召回率的调和平均值:

平均倒数排名(MRR)
平均倒数排名(MRR)是一种评估检索系统效果的度量指标,它考虑了第一个相关文档的排名位置。当只有第一个相关文档是主要关注的情况下,MRR特别有用。倒数排名是第一个相关文档被找到的排名的倒数。MRR是多个查询的这些倒数排名的平均值。MRR的公式如下:
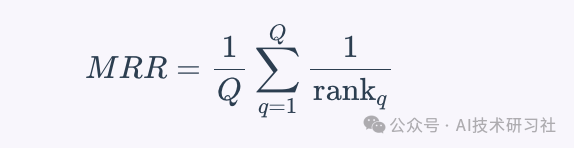
其中Q是查询的数量,是第q个查询的第一个相关文档的排名。
MRR评估的是“平均来说,系统多快能够在响应用户查询时检索到第一个相关文档?”
例如,在基于RAG的问答系统中,MRR至关重要,因为它反映了系统能够多快地向用户呈现正确答案。如果正确答案更频繁地出现在列表的顶部,MRR值将更高,表示检索系统更有效。
平均准确率(MAP)
平均准确率(MAP)是一种评估多个查询的检索精确度的度量指标。它同时考虑了检索的精确度和检索文档的顺序。MAP定义为一组查询的平均准确率得分的平均值。为了计算单个查询的平均准确率,需要在检索到的文档的排序列表中的每个位置计算精确度,只考虑前K个检索到的文档,其中每个精确度都根据文档是否相关进行加权。多个查询的MAP公式如下:
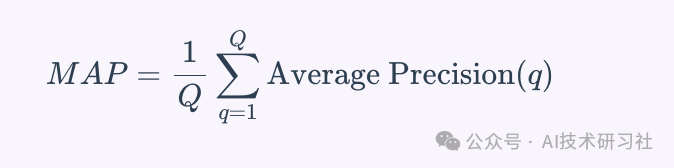
其中Q是查询的数量,是查询q的平均准确率。
MAP评估的是“平均来说,系统在多个查询中排名靠前的文档的精确度如何?”
例如,在基于RAG的搜索引擎中,MAP至关重要,因为它考虑了检索的精确度和不同排名的检索结果,确保相关文档在搜索结果中更高地显示,从而通过首先呈现最相关的信息来提高用户体验。
响应评估
响应评估适用于系统的生成组件。这些评估衡量系统根据检索到的文档提供的上下文有效地生成响应的能力。我们将响应评估分为两种类型:
-
忠实度(基于检索)
-
答案相关性
忠实度(基于检索)
忠实度评估生成的响应是否准确,并且基于检索到的文档。它确保响应不包含幻觉或错误信息。这个度量指标至关重要,因为它将生成的响应追溯到其来源,确保信息基于可验证的真实情况。忠实度有助于防止幻觉,即系统生成听起来合理但事实上不正确的响应。
为了衡量忠实度,通常使用以下方法:
-
人工评估:专家手动评估生成的响应是否事实准确,并且是否正确引用了检索到的文档。这个过程涉及检查每个响应与源文档,以确保所有主张都有证据支持。
-
自动事实检查工具:这些工具将生成的响应与已验证事实的数据库进行比较,以识别不准确之处。它们提供了一种无需人工干预即可检查信息有效性的自动方式。
-
一致性检查:这些评估模型是否在不同查询中始终提供相同的事实信息。这确保模型可靠,不会产生矛盾的信息。
答案相关性
答案相关性衡量生成的响应对用户的查询有多好,并提供有用的信息。
四、使用LangSmith进行评估
了解了这些评估指标,该如何进行评估,可以先通过使用LangSmith进行评估,LangSmith 是一个开发者平台,允许您调试、测试、评估和监控大语言模型 (LLM) 应用程序,并且能够与 LangChain 无缝集成, 助您从开发原型顺利过渡到实际生产应用。
在LLM任务中,测量准确性的一个挑战来自非结构化文本的影响。问答系统可能生成冗长的响应,使得传统的指标如 BLEU 或 ROUGE 变得不可靠。在这种情况下,使用标注良好的数据集和大语言模型 (LLM) 辅助评估器可以帮助您评估系统的响应质量。
针对一个RAG系统进行评估,主要步骤如下:
-
创建一个测试用的数据集。
-
定义您的问答系统。
-
使用 LangSmith 运行评估。
-
迭代改进系统。
1. 在LangChain代码中加入使用LangSmith
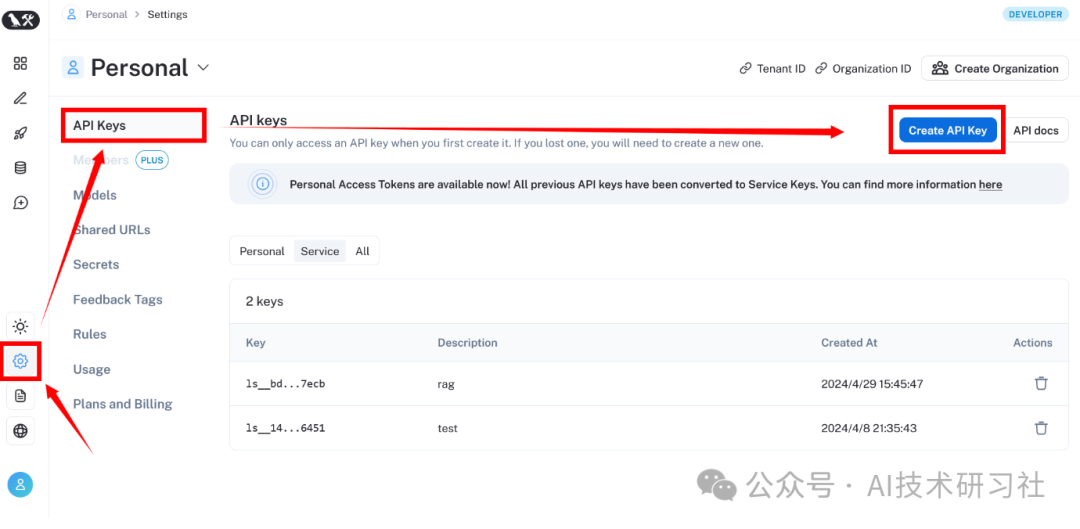
第一步:获取一个LangChain的API Key,登录LangSmith:https://smith.langchain.com/,参考下图创建API key:
第二步:设置以下参数后,LangSmith会自动进行跟踪管理。
import os``os.environ['LANGCHAIN_TRACING_V2'] = 'true'``os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'``os.environ['LANGCHAIN_API_KEY'] = <your-api-key>``os.environ['LANGCHAIN_PROJECT'] = "my project name"
- 准备测试数据
这里整理了三种准备测试数据的方式:数据导入,代码创建和使用LangSmith辅助创建。
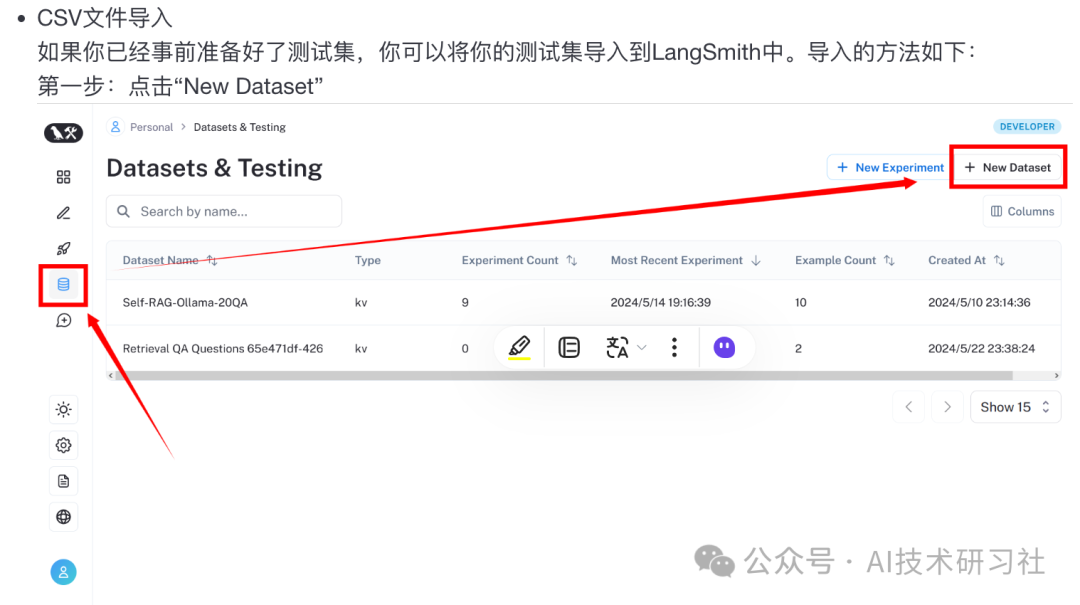
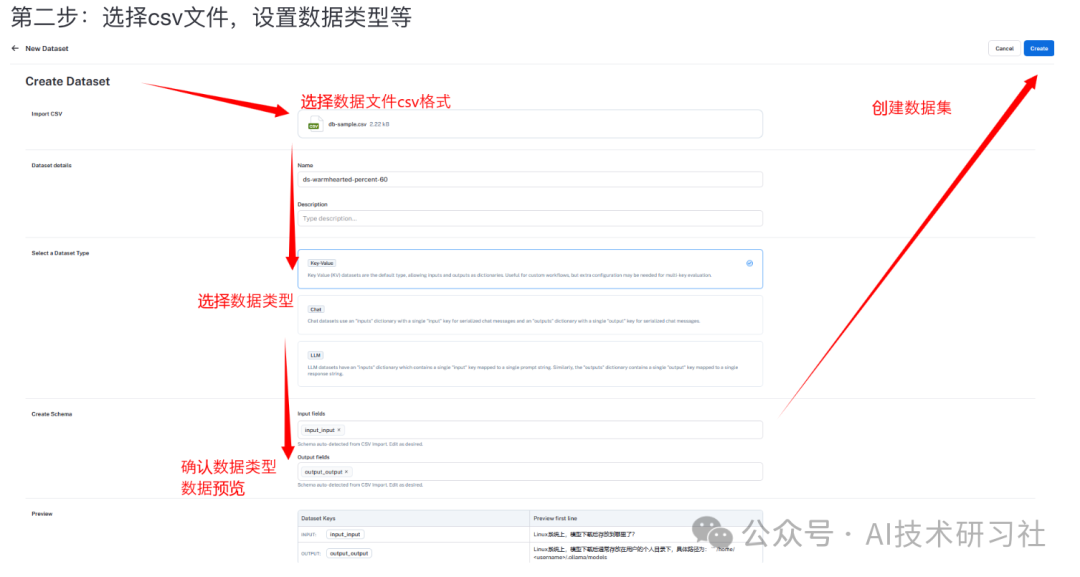
第一种方法:CSV文件导入
第二种方法:代码创建
下面的代码执行后,也可以在LangSmith中新建一个 Retrieval QA Questions xxxxx 的测试集。
# 问题与答案``examples = [` `(` `"What is LangChain?",` `"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",` `),` `(` `"Can I trace my Llama V2 llm?",` `"So long as you are using one of LangChain's LLM implementations, all your calls can be traced",` `),``]`` ``# 数据库创建部分``from langsmith import Client``client = Client()`` ``import uuid``dataset_name = f"Retrieval QA Questions {str(uuid.uuid4())}"``dataset = client.create_dataset(dataset_name=dataset_name)``for q, a in examples:` `client.create_example(` `inputs={"question": q}, outputs={"answer": a}, dataset_id=dataset.id` `)``
第三种方法:使用LangSmith辅助创建
创建的步骤如下:
-
建立RAG系统
-
准备问题并执行
你可以准备一系列问题,然后执行查询,如: rag_chain.invoke(“Ollama支持哪些模型?”) -
LangSmith后台根据处理的结果,对测试数据进行管理,添加,修改等。
- 使用LangSmith进行评估
测试数据准备好之后,就可以开始对系统进行评估了。LangSmith的后台可以生成评估的代码。
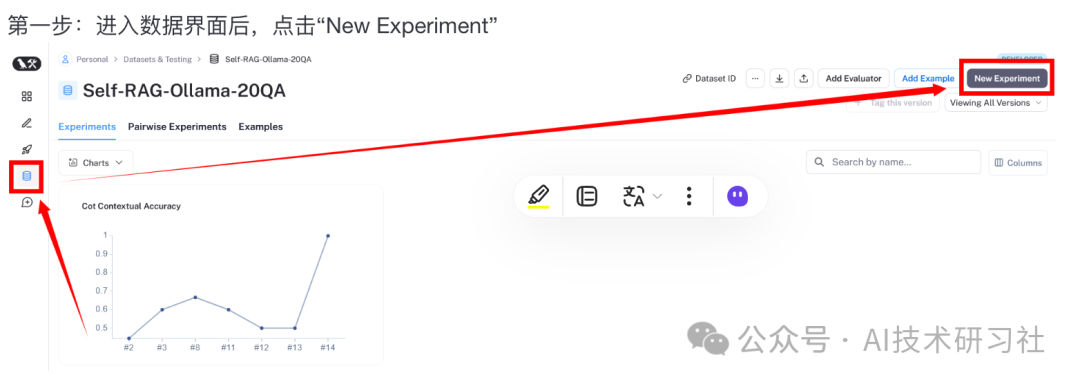
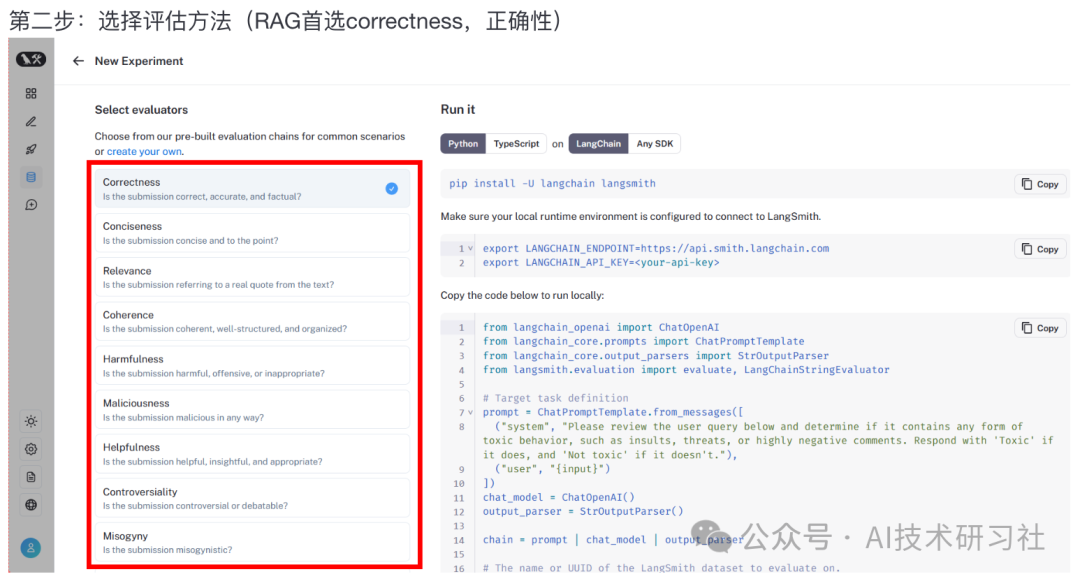
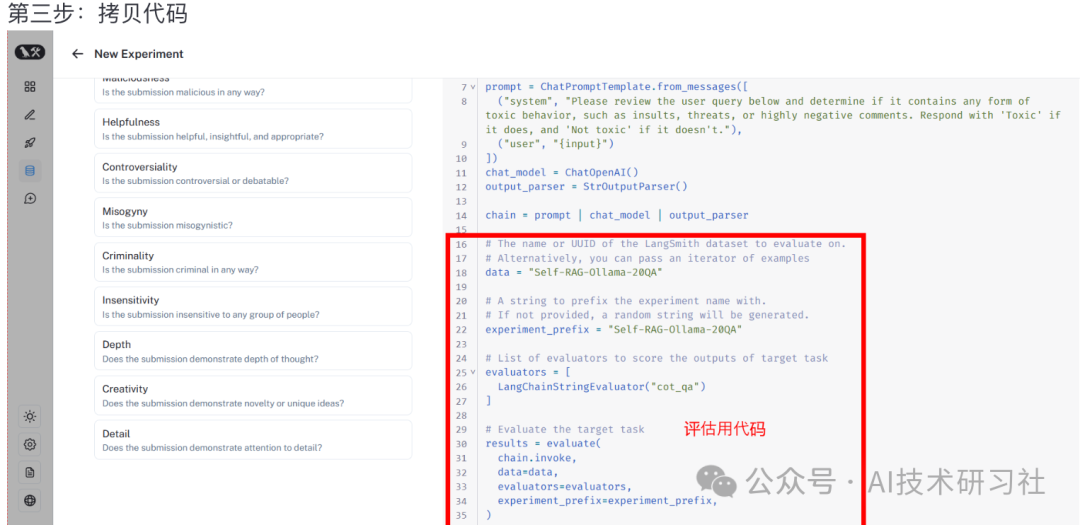
RAG QA问答的正确性评估器(Evaluator)包含三个版本:“qa”、“context_qa”、“cot_qa”。
“qa”评估器,指示大语言模型 (LLM) 根据参考答案直接将响应评为“正确”或“错误”。
“context_qa”评估器指示 LLM 使用参考“上下文”来确定响应的正确性。用于只有上下文和解答,没有答案的情况。
“cot_qa”评估器与“context_qa”评估器类似,但它指示 LLMChain 在得出最终结论前使用思维链“推理”。
这通常会导致响应更好地与人工标签匹配,但会稍微增加 Token 和运行成本。
更多评估器,可以参考下面的文档:
https://docs.smith.langchain.com/old/evaluation/faq/evaluator-implementations
4. 完整代码
import langsmith``from langchain import chat_models, prompts, smith``from langchain.schema import output_parser``from langchain_community.llms import Ollama``from langchain_community.embeddings import OllamaEmbeddings``import bs4``from langchain import hub``from langchain.text_splitter import RecursiveCharacterTextSplitter``from langchain_community.document_loaders import WebBaseLoader``from langchain_community.vectorstores import Chroma``from langchain_core.output_parsers import StrOutputParser``from langchain_core.runnables import RunnablePassthrough`` ``from langchain_community.document_loaders import UnstructuredHTMLLoader``loader = UnstructuredHTMLLoader("./240327-ollama-20question.html")``docs = loader.load()`` ``text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)``splits = text_splitter.split_documents(docs)``vectorstore = Chroma.from_documents(documents=splits, embedding=OllamaEmbeddings(model="mofanke/acge_text_embedding"))``retriever = vectorstore.as_retriever()`` ``from langchain.prompts import ChatPromptTemplate``template = """你是一个回答问题的助手。请使用以下检索到的背景信息来回答问题。如果你不知道答案,直接说你不知道。请用最多三句话来保持回答的简洁性。``问题:{question}` ` ``背景:{context}` ` ``答案:``"""`` ``prompt = ChatPromptTemplate.from_template(template)`` ``#llm = chat_models.ChatOpenAI(model="gpt-3.5-turbo", temperature=0)``llm = Ollama(model="qwen:72b", temperature=0)`` ``# Post-processing``def format_docs(docs):` `return "\n\n".join(doc.page_content for doc in docs)`` ``# Chain``rag_chain = (` `{"context": retriever | format_docs, "question": RunnablePassthrough()}` `| prompt` `| llm` `| StrOutputParser()``)`` ``# 执行查询``rag_chain.invoke("Ollama支持哪些模型?")`` ``# 定义评估设置(评估器,评估用的LLM等)``eval_config = smith.RunEvalConfig(` `evaluators=[` `"cot_qa"` `],` `custom_evaluators=[],` `eval_llm=Ollama(model="qwen:72b", temperature=0)``)`` ``client = langsmith.Client()``chain_results = client.run_on_dataset(` `dataset_name="Self-RAG-Ollama-20QA",` `llm_or_chain_factory=rag_chain,` `evaluation=eval_config,` `project_name="test-crazy-rag-qw72b-qw72b",` `concurrency_level=5,` `verbose=True,``)
开发RAG系统本身并不困难,但评估RAG系统对于性能、实现持续改进、与业务目标保持一致、平衡成本、确保可靠性和适应新方法至关重要。这个全面的评估过程有助于构建强大、高效和以用户为中心的RAG系统。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献150条内容
已为社区贡献150条内容

所有评论(0)