最适合LLM推理的NVIDIA GPU全面指南
最适合LLM推理的NVIDIA GPU全面指南
介绍
大型语言模型(LLM)如GPT-4、BERT以及其他基于Transformer的模型已经革新人工智能领域。这些模型在训练和推理过程中需要大量的计算资源。选择合适的GPU进行LLM推理可以显著影响性能、成本效益和可扩展性。💡
🔍 本指南将帮助你选择最适合你需求的GPU,不论是为个人项目、研究环境还是大规模生产部署。🎯
下面这份零基础AI大模型学习资料已经上传网盘,朋友们如果需要可以下方链接即可免费领取↓↓↓

理解关键GPU规格
在深入了解推荐列表之前,让我们简要概述一些关键规格,这些规格决定了GPU是否适合LLM推理:
🖥️ CUDA核心:这是GPU的主要处理单元。更高的CUDA核心数通常意味着更好的并行处理性能。
🧠 张量核心:专门设计用于深度学习任务,例如矩阵乘法,这对神经网络操作至关重要。
💾 VRAM(视频RAM):这是GPU可用的内存,用于存储数据和模型。更多的VRAM可以更高效地处理大型模型和数据集。
⏱️ 时钟频率:表示GPU的操作速度,以MHz为单位。更高的频率通常意味着更好的性能。
🚀 内存带宽:这是数据读取或写入VRAM的速度,对LLM推理等任务的性能影响显著。
⚡ 功耗:以瓦特(W)为单位,表示GPU在运行时消耗的电量。更高的功耗可能导致冷却和能源成本增加。
💰 价格:GPU的成本是一个重要因素,特别是在预算有限的企业或研究实验室中。在性能需求和成本效益之间找到平衡非常重要。
适用于LLM推理的NVIDIA GPU选择
以下表格根据性能和价格对NVIDIA GPU进行了排名,以评估它们在LLM推理方面的适用性:
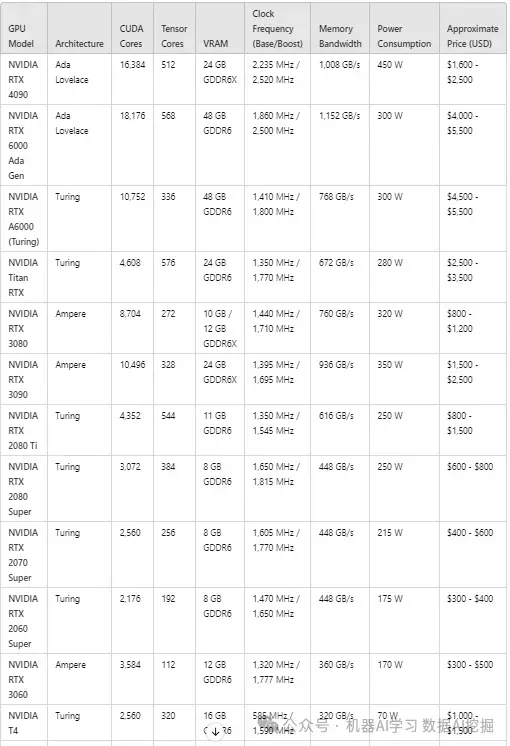
消费级和专业级GPU
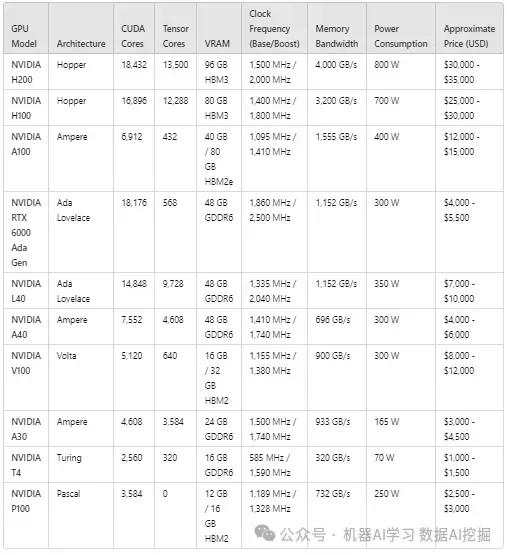
高端企业图形处理器
🔝 适合LLM推理的顶级选择
🔷 NVIDIA H200:
最佳应用:需要最大性能和内存带宽以处理大规模LLM推理任务的企业级AI部署。
性能:拥有18,432个CUDA核心、96GB HBM3内存和惊人的4,000GB/s带宽的无与伦比的GPU性能。
🔷 NVIDIA H100:
最佳应用:专注于大规模LLM推理的企业和研究实验室。
性能:拥有16,896个CUDA核心和80GB HBM3内存,H100在极致性能和功耗之间取得了平衡,非常适合AI驱动的工作负载。
🔷 NVIDIA A100:
最佳应用:相比于H100,需要高性能AI推理和训练,但价格更低的组织。
性能:提供大量的内存带宽(1,555GB/s)和40GB或80GB HBM2e内存选项,使其成为苛刻AI模型的理想选择。
🔷 NVIDIA RTX 6000 Ada Gen:
最佳应用:无需HBM3,专注于性能的专业LLM推理任务。
性能:提供48GB的GDDR6内存,18,176个CUDA核心,以及针对小型企业和研究设置的性能与价格平衡。
🔷 NVIDIA L40:
最佳应用:中型企业的高性能AI推理。
性能:L40通过提供9,728个Tensor核心和48GB GDDR6内存实现了卓越的性能,同时保持比H100更低的功耗。
💸 预算友好型LLM推理选项
🔷 NVIDIA RTX 4090:
最佳应用:高端消费级AI推理设置。
性能:配备24GB的GDDR6X内存,内存带宽为1,008GB/s。作为一款消费级GPU,它提供了卓越的性能,尽管其450W的功耗相当显著。这使其非常适合以竞争性价格执行高性能任务。
🔷 NVIDIA RTX 6000 Ada Generation:
最佳应用:需要大量内存容量和高吞吐量的专业AI工作负载。
性能:提供48GB的GDDR6内存,大量CUDA和Tensor核心,以及1,152GB/s的内存带宽,确保大规模数据传输和LLM推理任务的高效执行。
🔷 NVIDIA Titan RTX:
最佳应用:AI开发者需要强劲Tensor核心性能的专业级AI开发和推理。
性能:Titan RTX提供24GB的GDDR6内存和672GB/s的内存带宽,为LLM推理和深度学习任务提供可靠的性能,尽管它缺乏最新的架构改进。
🔷 NVIDIA RTX 3080 & RTX 3090:
最佳应用:高性能游戏和AI开发,尤其是对于需要在更可访问的价格点上获得强大性能的开发者。
性能:这两款GPU提供了强劲的性能与价格比,RTX 3090拥有24GB的GDDR6X内存,使其特别适合内存密集型AI任务。这些型号在从事AI和游戏开发的开发人员中非常受欢迎。
🔷 NVIDIA T4:
最佳应用:需要更低功耗的基于云的推理工作负载或边缘计算。
性能:T4在提供足够的性能以处理基于云或边缘AI推理工作负载的同时,优化了更低的功耗(16GB的GDDR6内存),使其非常适合注重能耗的AI应用。
🎯 结论
选择适合LLM推理的正确GPU很大程度上取决于您的项目规模、模型复杂性以及预算限制。
对于企业级部署,NVIDIA H200和H100等GPU提供了无与伦比的性能,具有大量的CUDA和Tensor核心、高VRAM和惊人的内存带宽,非常适合最大的模型和最密集的AI工作负载。这些GPU价格较高,但为前沿AI应用和大规模LLM推理提供了必要的计算能力。
对于寻求在较低价格下获得高性能的组织,NVIDIA A100和RTX 6000 Ada Generation在功率和成本之间找到了平衡,提供了大量VRAM和强大的Tensor核心性能,非常适合中型企业和研究实验室的需求。
如果成本和能源效率是主要考虑因素,NVIDIA L40和A40等GPU提供了强大的Tensor核心数量、高VRAM容量以及高效的功耗。这些都是中型组织执行高效AI任务的优秀选择。
对于小型团队或个人开发者,如NVIDIA RTX 4090或RTX 3090等消费级GPU是优秀的选择,它们以专业级GPU的一小部分成本提供了强大的性能。这些GPU拥有大量的CUDA和Tensor核心以及充足的VRAM,非常适合本地AI开发环境或小规模的LLM推理任务。价格在$1,500至$2,500之间,它们为希望在没有企业级预算的情况下获得强大硬件的AI从业人员提供了极高的价值。
对于基于云的推理或边缘计算,NVIDIA T4和P100提供了成本低廉的专业级LLM推理入门点,具有较低的功耗,非常适合轻量级推理工作负载和小型AI应用。
最终,GPU的选择应与您的AI工作负载的具体需求相匹配,平衡性能、可扩展性和成本,以确保您能够高效地处理从小型模型到最苛刻的大语言模型的LLM推理任务。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 41
41 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)