DeepSeek 细节(3)之 MTP(Multi-Token Prediction)
当前主流的 LLM 主要采用 Decoder-only 为基础的模型结构。这意味着无论是在训练还是推理阶段,序列的生成都是逐个 token 进行的。在生成每个 token 时,模型需要频繁地进行访存操作,加载 KV Cache,往往成为训练或推理过程中的瓶颈。通过优化解码阶段,可以将单个 token 的生成转变为多个 token 的生成,从而提升训练和推理的性能。具体而言,在训练阶段,通过一次生成
DeepSeek 细节(3)之 MTP(Multi-Token Prediction)
当前主流的 LLM 主要采用 Decoder-only 为基础的模型结构。这意味着无论是在训练还是推理阶段,序列的生成都是逐个 token 进行的。在生成每个 token 时,模型需要频繁地进行访存操作,加载 KV Cache,往往成为训练或推理过程中的瓶颈。
MTP 通过优化解码阶段,可以将单个 token 的生成转变为多个 token 的生成,从而提升训练和推理的性能。具体而言,在训练阶段,通过一次生成多个后续 token,可以同时学习多个位置的标签,从而提高样本的利用效率和训练速度。在推理阶段,通过一次生成多个 token,可以实现推理速度的成倍提升,从而增强推理性能。
更多 DeepSeek 细节可移步至~~
DeepSeek 细节(1)之 MLA (Multi-head Latent Attention)
DeepSeek 细节(2)之 MoE(Mixture-of-Experts)
Meta MTP
在介绍 deepSeek 的 MTP 之前,先来看看其 Meta MTP
前人的工作是如何实现的,详细推理过程可移步至~~ deepseek技术解读(2)-MTP(Multi-Token Prediction)的前世今生
- 传统自回归模型是 token-by-token 生成,是一种感知局部的训练方法,难以学习长距离的依赖关系,且在实际推理的过程中生成 token 的速度较慢
- Meta MTP 在训练过程中,通过预测多个连续的 token,模型被迫(Teacher Forcing)去理解更长的上下文依赖关系,这有助于避免模型只关注局部信息的学习模式。同时,一次性预测多个 token 可以显著提高样本的利用效率,因为每次预测都能生成多个<predict, label>对来更新模型参数,这有助于加速模型的收敛过程
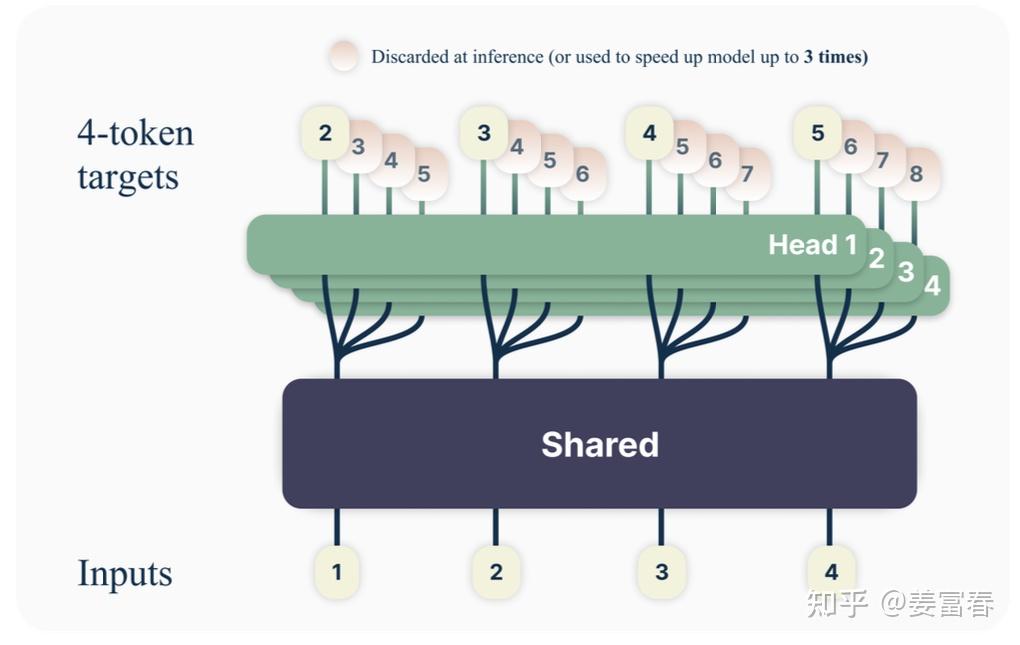
网络结构
- 如上图所示,一个共享的 transformer 的主网络,上面接入4个并行的 head ,针对输入 token 分别预测后续的4个 token
- head 是一个 transformer层(包括 MHA + 2层FFN),且每个 head 的 transformer 层参数是独立的
- 最后再将 head 层的输出通过 softmax 映射至词表中,来生成具体的 token
单 token 输入的框架如下图所示:
- 多个 head 的推理可并行计算
- 在模型训练时,多个头都会并行计算 loss,提升样本利用效率和加速模型收敛
DeepSeek MTP
DeepSeek MTP 的网络结构图如下,对比 Meta 的 MTP 结构图来看,结构略复杂但也是多头结构,但在序列推理的过程中保留了连接关系(causal chain),如下图中,从一个 Module 链接到后继 Module 的箭头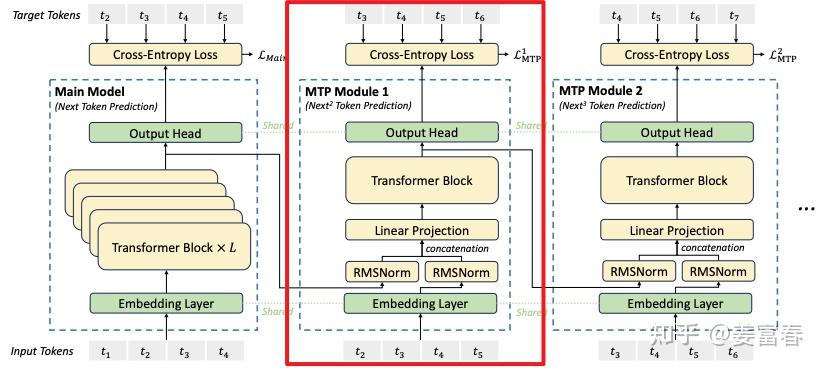
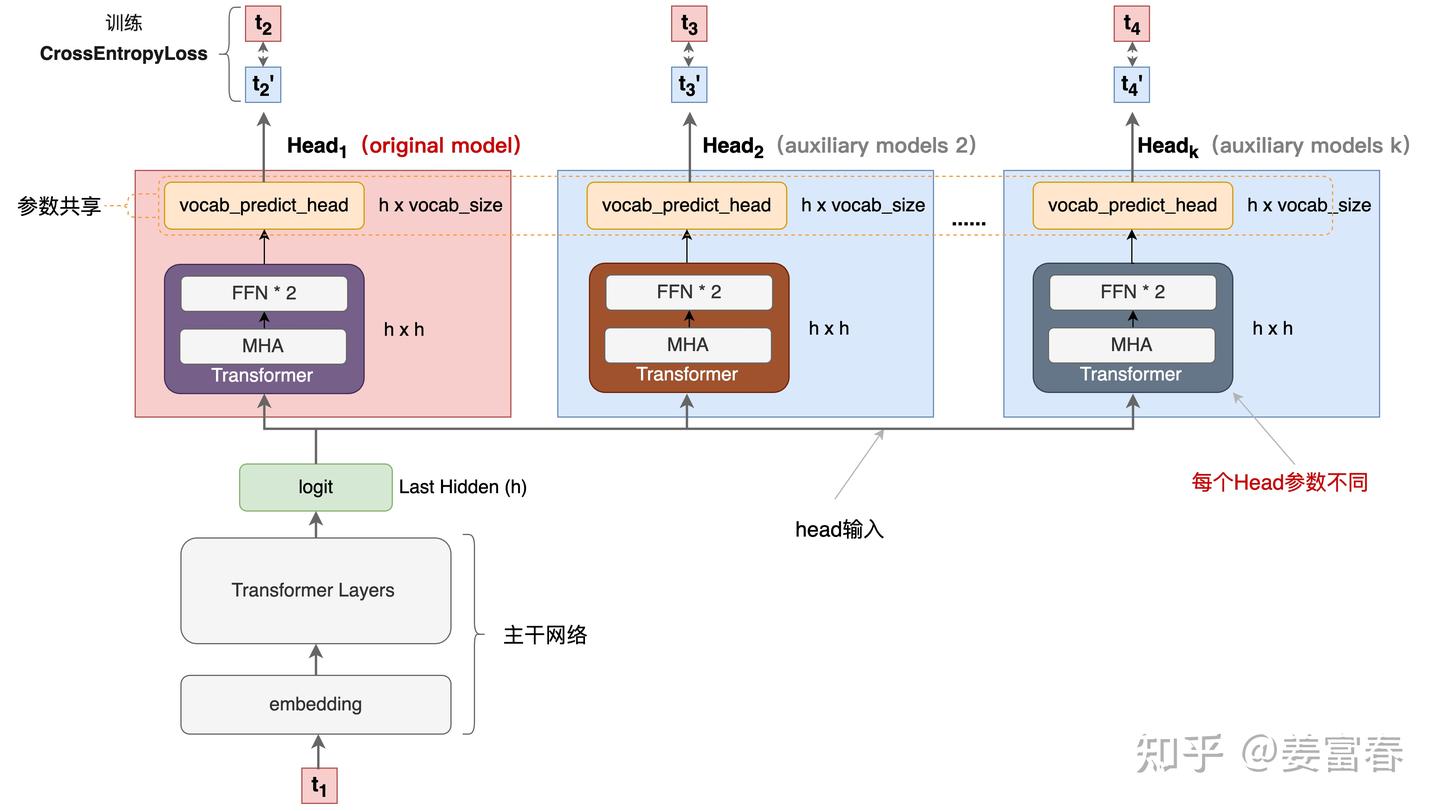
网络结构
- 输入token首先接入一层共享的embedding layer
- 对于第 i 个 token 和第 k 个预测深度的话(例如图中红框所示),首先 k-1 层的隐层做归一化(RMSNorm层)处理然后通过 causal chain 被链接过来,然后在对此时的 token embedding 做归一化处理,然后将两个结果 concat

- 然后在将隐藏向量输入到 transformer 层
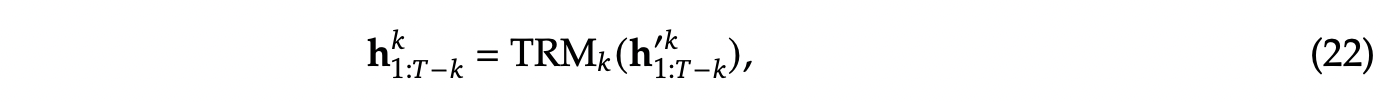
- 最后将 transformer 输出的隐层输入到 OutHead 矩阵中,其中每个 MHA 是共享映射矩阵和词表的,在通过 softmax 层后输出具体的 token
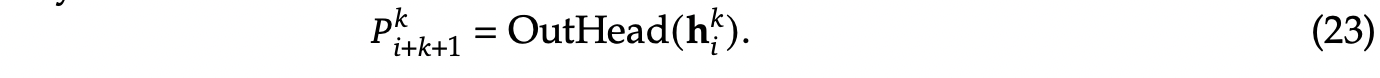
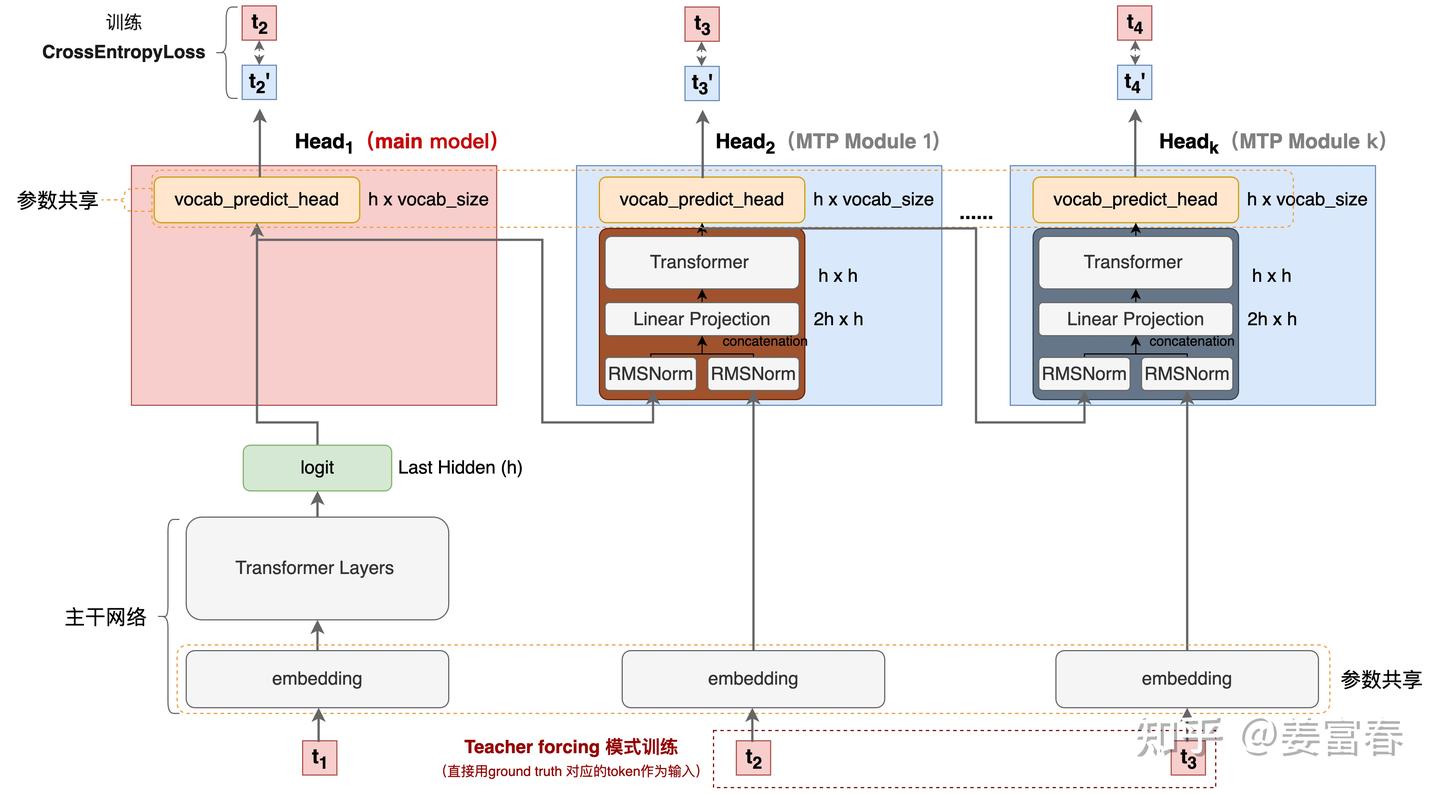
单 token 的网络结构图(上图)更加的清晰明了,但有几个细节值得一提:
- DeepSeek 的实现相对于之前的方法增加了 causal chain 的连接
- 红框中的 Teacher forcing,在训练阶段正常应该是拿上一个状态的输出但在序列建模训练中,直接用样本中的 ground truth 作为输入,效果会更好,模型的收敛会更快
MTP 在推理阶段 Teacher forcing 就完全失效了,与之对应的是 free-running 模式,如下图所示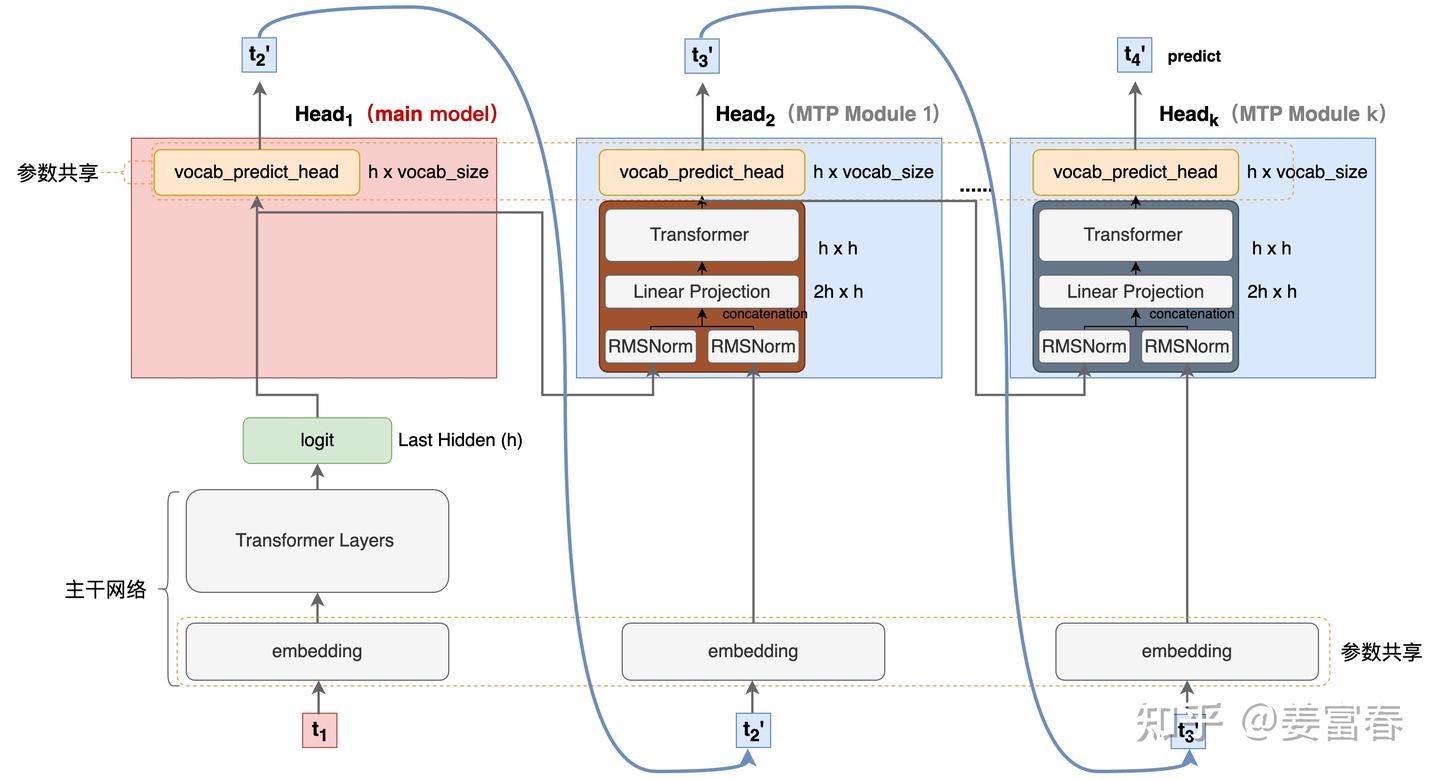
参考文献

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)