Kokoro-onnx 打包成执行文件.exe
Kokoro-onnx 打包成执行文件.exe
Haodu-Kokoro-TTS
开发完成MS-Edge-TTS后,总觉得找一个本地生成语音的比较好点,毕竟,网络有时太不稳定,失败频频发生。
偶然发现竟然有82M的小模型语音生成库,太神奇了,kokoro-onnx · PyPI 。不得不说,AI开发无处不在,小小模型朗读的效果也很自然,还支持几国的语言,达到54个语音库。如果套壳开发一下,这下省下不少时间。开时,从MS-Edge-TTS界面直接移植过来,修改生成函数,直接就成就了Kokoro-onnx-TTS.
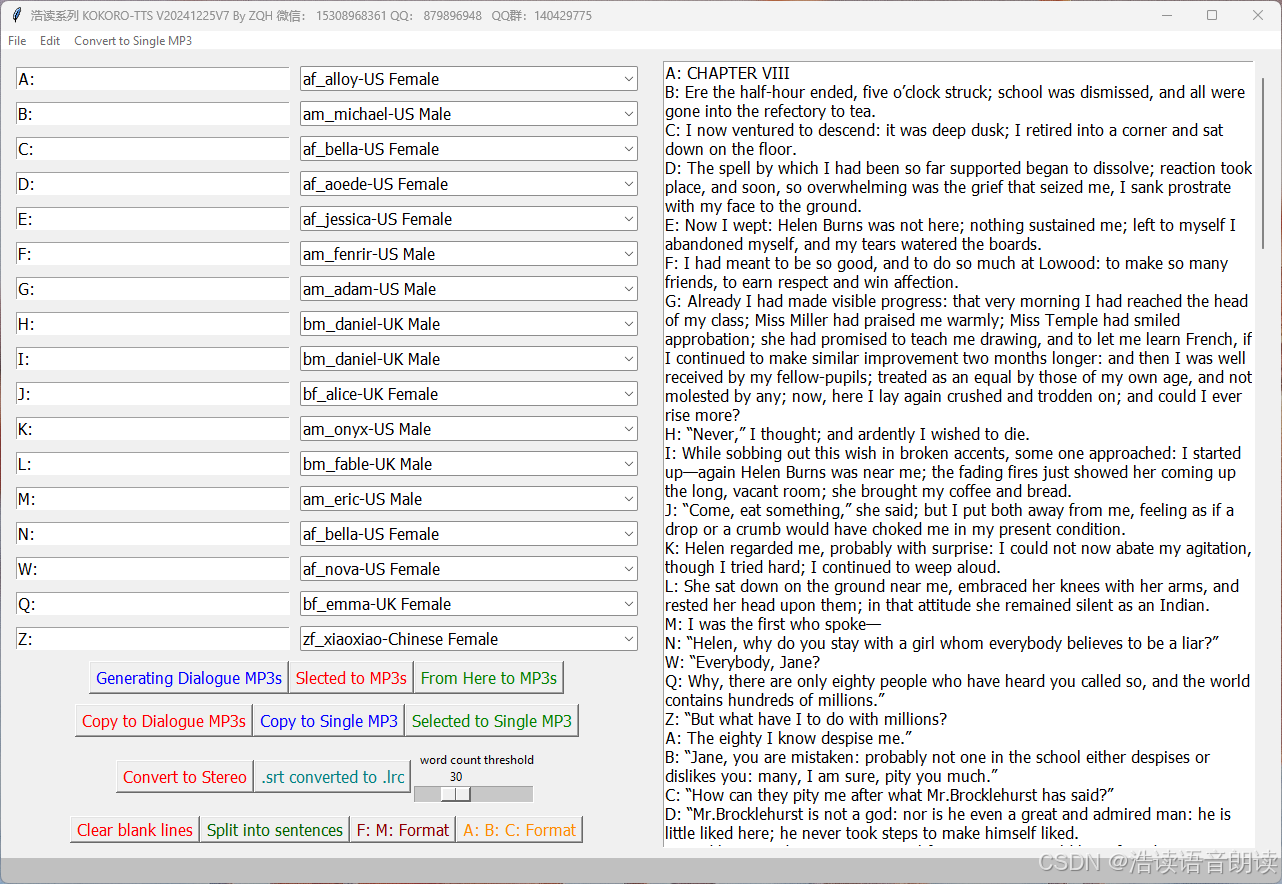 但到了打包成执行文件.exe阶段,十分折腾,足足折腾了近两个星期才发现其中的秘密:原来,这东西要求依赖的库很特别,要求要全部安装依赖库,并且版本要求要合它的要求,不能高也不能低。
但到了打包成执行文件.exe阶段,十分折腾,足足折腾了近两个星期才发现其中的秘密:原来,这东西要求依赖的库很特别,要求要全部安装依赖库,并且版本要求要合它的要求,不能高也不能低。
光安装kokoro-onnx时,就要安装一大堆的依赖库,这还不是完全的,但可以依赖python来运行,但一打包,出错连连,找了一个一个的原因,不断解决缺少的库,但最后还是无法成功,这让开发的怀疑人生, 只好到开发去看源代,突然发现有个不起眼的uv.lock.json, 翻看了一下,才发现其中的秘密,这里记录着运行kokoro-onnx 的所有的库,并且规定的版本。如何全部安装数据库json里的60多个库让它懊恼。
还好,第一步:
下载uv.lock.json, 把json转化requirements.txt, 然后生了可以安装的文本。
下面是转化代码:
import json
import os
def convert_uv_lock_to_requirements(uv_lock_file, requirements_file):
try:
# 读取un.lock.json文件
with open(uv_lock_file, 'r') as f:
data = json.load(f)
# 提取包信息
packages = data.get('package', [])
# 写入requirements.txt文件
with open(requirements_file, 'w') as f:
for package in packages:
name = package['name']
version = package['version']
f.write(f"{name}=={version}\n")
print(f"Successfully converted {uv_lock_file} to {requirements_file}")
except FileNotFoundError:
print(f"Error: The file {uv_lock_file} was not found.")
except json.JSONDecodeError:
print(f"Error: The file {uv_lock_file} is not a valid JSON file.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# 使用示例
uv_lock_file = 'uv.lock.json'
requirements_file = 'requirements.txt'
# 获取脚本所在的目录
script_dir = os.path.dirname(os.path.abspath(__file__))
# 构建完整的文件路径
uv_lock_path = os.path.join(script_dir, uv_lock_file)
requirements_path = os.path.join(script_dir, requirements_file)
convert_uv_lock_to_requirements(uv_lock_path, requirements_path)
如果下载不到.json, 只下载到uv.lock, 那么就用以下的代码转一下:
import re
def convert_uv_lock_to_requirements(uv_lock_file, requirements_file):
with open(uv_lock_file, 'r') as f:
uv_lock_content = f.read()
packages = []
for package in re.finditer(r'\[\[package\]\]\s*name = "([^"]+)"\s*version = "([^"]+)"', uv_lock_content, re.DOTALL):
name = package.group(1)
version = package.group(2)
packages.append(f'{name}=={version}')
with open(requirements_file, 'w') as f:
f.write('\n'.join(packages))
uv_lock_file = 'uv.lock'
requirements_file = 'requirements.txt'
convert_uv_lock_to_requirements(uv_lock_file, requirements_file)下面是转换后的文本的内容:
attrs==24.3.0
audioread==3.0.1
babel==2.16.0
certifi==2024.12.14
cffi==1.17.1
charset-normalizer==3.4.1
clldutils==3.21.0
colorama==0.4.6
coloredlogs==15.0.1
colorlog==6.9.0
csvw==3.5.1
decorator==5.1.1
dlinfo==1.2.1
espeakng-loader==0.2.4
flatbuffers==24.12.23
humanfriendly==10.0
idna==3.10
importlib-metadata==8.5.0
isodate==0.7.2
joblib==1.4.2
jsonschema==4.23.0
jsonschema-specifications==2024.10.1
kokoro-onnx==0.4.2
language-tags==1.2.0
lazy-loader==0.4
librosa==0.10.2.post1
llvmlite==0.43.0
lxml==5.3.0
markdown==3.7
markupsafe==3.0.2
mpmath==1.3.0
msgpack==1.1.0
numba==0.60.0
numpy==2.0.2
onnxruntime==1.20.1
onnxruntime-gpu==1.20.1
packaging==24.2
phonemizer-fork==3.3.1
platformdirs==4.3.6
pooch==1.8.2
protobuf==5.29.2
pycparser==2.22
pylatexenc==2.10
pyparsing==3.2.1
pyreadline3==3.5.4
python-dateutil==2.9.0.post0
rdflib==7.1.1
referencing==0.35.1
regex==2024.11.6
requests==2.32.3
rfc3986==1.5.0
rpds-py==0.22.3
ruff==0.8.6
scikit-learn==1.6.0
scipy==1.13.1
segments==2.2.1
six==1.17.0
sounddevice==0.5.1
soundfile==0.13.0
soxr==0.5.0.post1
sympy==1.13.3
tabulate==0.9.0
threadpoolctl==3.5.0
typing-extensions==4.12.2
uritemplate==4.1.1
urllib3==2.3.0
zipp==3.21.0
把这些内容保存为文本:requirements.txt,并保存到开发的.py的目录下,如I:\kokoro\requirements.txt
第二步:
打开cmd, 转到I:\kokoro\, 输入命令: pip install -r requirements.txt,接着等待漫长的安装, 如果速度太慢可以转成国内源如
pip install -r requirements.txt --index-url https://pypi.tuna.tsinghua.edu.cn/simple
第三步: 安装结束后,检测安装是否上述的版本以及是不是全安装了, 确定全部安装,并且版本对了,就开始输入打包命令:
pyinstaller --onefile --add-data "kokoro-v1.0.onnx;." --add-data "voices-v1.0.bin;." --add-data "C:/py312/Lib/site-packages/language_tags/data/json/;language_tags/data/json" --add-data "C:/py312/Lib/site-packages/espeakng_loader/espeak-ng-data/;espeakng_loader/espeak-ng-data" --console "kokorotts.py"
然后其中kokoro-v1.0.onnx,oices-v1.0.bin要和kokorotts.py同一目录下。 -add-data "voices-v1.0.bin;." --add-data "C:/py312/Lib/site-packages/language_tags/data/json/;language_tags/data/json" --add-data "C:/py312/Lib/site-packages/espeakng_loader/espeak-ng-data/;espeakng_loader/espeak-ng-data" --add-data "C:/py312/Lib/site-packages/language_data/;language_data" 这几个是python安装目录下的,可以自行找到。换一下相应地址。
接着是近10分钟的等待, 生成一个近1.3G 可以执行文件。只要kokoro-v1.0.onnx,oices-v1.0.bin和这个执行文件放在一个目录,就可以成功运行了。
如本人生成的目录下就有这些文件:
I:\kokoro\dist\py312\
I:\kokoro\dist\kokoro-v1.0.onnx
I:\kokoro\dist\kokoro对话合并250215v9.exe
I:\kokoro\dist\t2v.txt
I:\kokoro\dist\voices-v1.0.bin
I:\kokoro\dist\对话合并25v7.exe
I:\kokoro\dist\把py312这个文件复制到:c\ 下
目前支持的语音库有:
af_alloy.npy
af_aoede.npy
af_bella.npy
af_heart.npy
af_jessica.npy
af_kore.npy
af_nicole.npy
af_nova.npy
af_river.npy
af_sarah.npy
af_sky.npy
am_adam.npy
am_echo.npy
am_eric.npy
am_fenrir.npy
am_liam.npy
am_michael.npy
am_onyx.npy
am_puck.npy
am_santa.npy
bf_alice.npy
bf_emma.npy
bf_isabella.npy
bf_lily.npy
bm_daniel.npy
bm_fable.npy
bm_george.npy
bm_lewis.npy
ef_dora.npy
em_alex.npy
em_santa.npy
ff_siwis.npy
hf_alpha.npy
hf_beta.npy
hm_omega.npy
hm_psi.npy
if_sara.npy
im_nicola.npy
jf_alpha.npy
jf_gongitsune.npy
jf_nezumi.npy
jf_tebukuro.npy
jm_kumo.npy
pf_dora.npy
pm_alex.npy
pm_santa.npy
zf_xiaobei.npy
zf_xiaoni.npy
zf_xiaoxiao.npy
zf_xiaoyi.npy
zm_yunjian.npy
zm_yunxi.npy
zm_yunxia.npy
zm_yunyang.npy
后记:感觉应该补写个实例:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)