华为MDC300F的操作记录
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入欢迎使用Mar
华为MDC300F的操作记录
之前在做MDC300F的相关工作时没有系统地记录,现做补充。
首先设备为MDC300f
华为MDC自动驾驶平台基于自研芯片的异构计算平台,CPU处理器采用ARM架构的鲲鹏920s,AI处理器采用昇腾310。
规格如下:
鲲鹏920s
•核数:12核
•主频:2.0 GHz
•制程:7nm FFC
•最大功耗:55W
Ascend310
•架构:达芬奇
•算力:16 TOPS@INT8
•制程:12nm FFC
•最大功耗:8
MDC300(F)版本
参考《MDC 300 (F) 升级指导书(升级至MDC300 1.0.033-T版本使用)》完成MDC300(F)升级,过程没遇到问题。
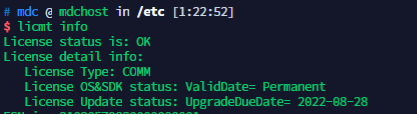
更新完成后,使用 licmt info 指令查询MDC的License信息。
执行命令:swmc -t 1 查询mdc当前版本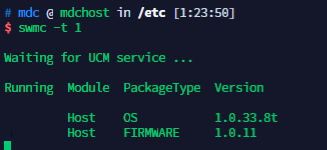
更新后注意事项
- 需要重新配置camera,由于之前没有备份camera的YAML文件导致更新后需要修改。
- 需要重新配置远程调试的用户权限,用户不能直接连接mdc用户,而需要先登录sshuser再切换mdc
工具链
MDC开发工具链基于Adaptive AUTOSAR,包括Mind Studio(AI开发工具,支持客户引入并应用AI能力),MDC Manifest Configurator(符合客户开发习惯的Adaptive AUTOSAR配置工具,MMC),MDC Development Studio(集成开发环境,帮助客户聚焦智能驾驶应用开发,MDS)
MindStudio
查看MindStudio版本 CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
开发环境:主要用于代码开发、编译、调测等开发活动。
(场景一)在昇腾AI设备上安装开发环境,同时可以作为运行环境,运行应用程序或进行训练脚本的迁移、开发&调试。
(场景二)在非昇腾AI设备上安装开发环境,仅能用于代码开发、编译等不依赖于昇腾设备的开发活动(例如ATC模型转换、算子和推理应用程序的纯代码开发)。
运行环境:在昇腾AI设备上运行用户开发的应用程序或进行训练脚本的迁移、开发&调试。
对于MDC300开发来说,上位机作为开发环境为非昇腾AI设备,在其基础上运行Mindstudio仅用于AI应用的编译开发,最终编译好的应用要放在装在有Ascend310芯片的MDC300设备上运行。
相关配置
首先需要配置toolkit。toolkit:开发套件包。主要用于用户开发应用、自定义算子和模型转换。开发套件包包含开发应用程序所需的库文件、开发辅助工具如ATC模型转换工具。
使用mindstudio需要安装对应的Acend工具包2.1.0版本mindstudio对应Ascend-1.32.2版本工具包。由于运行环境在MDC的arm架构下,所以需要安装X86和aarch64两个版本的ddk包。就是下面两个:
在第一次进入MindStudio时就需要配置x86版本的ddk包,而aarch64的ddk包只包含lib文件需要在IDE中导入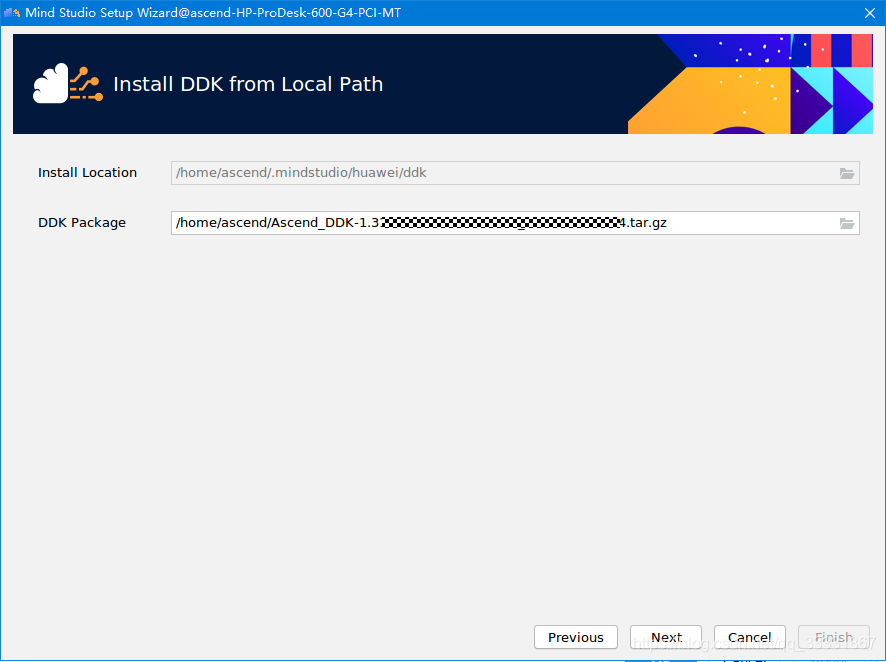
进入IDE后在Mind Studio工程界面依次选择“Tools > Device Management”,弹出设备管理界面,单击右侧工具栏的增加设备。然后点拷贝(双向箭头)
我添加了Mini0作为远程运行环境,这样Mindstudio就会自动从远程环境拷贝ddk包(mini0下的)。如图我的拷贝ddk为1.32.2B100,这个RC包是在更新0.33版本的MDC时安装的。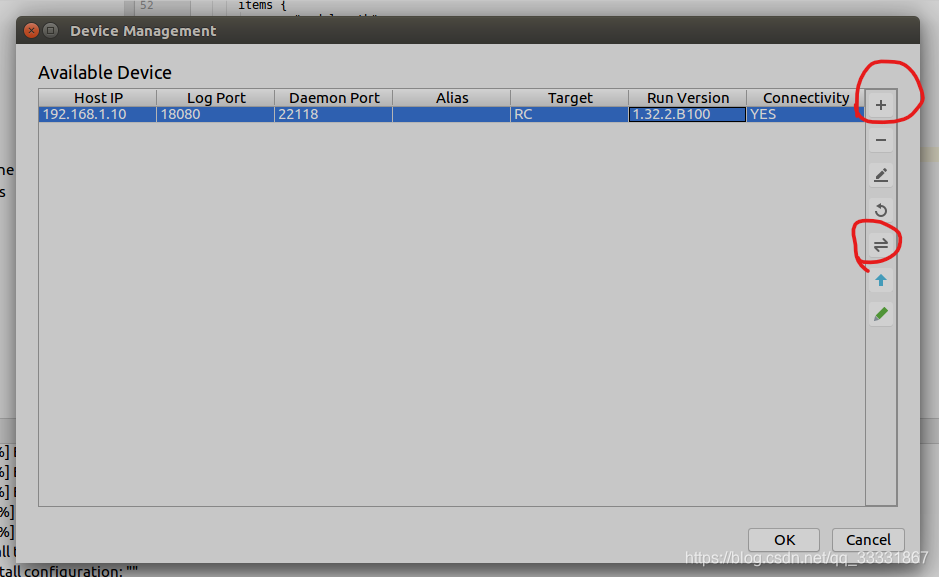
AI应用开发
基于昇腾芯片的AI应用开发有别于普通的AI应用开发,如下图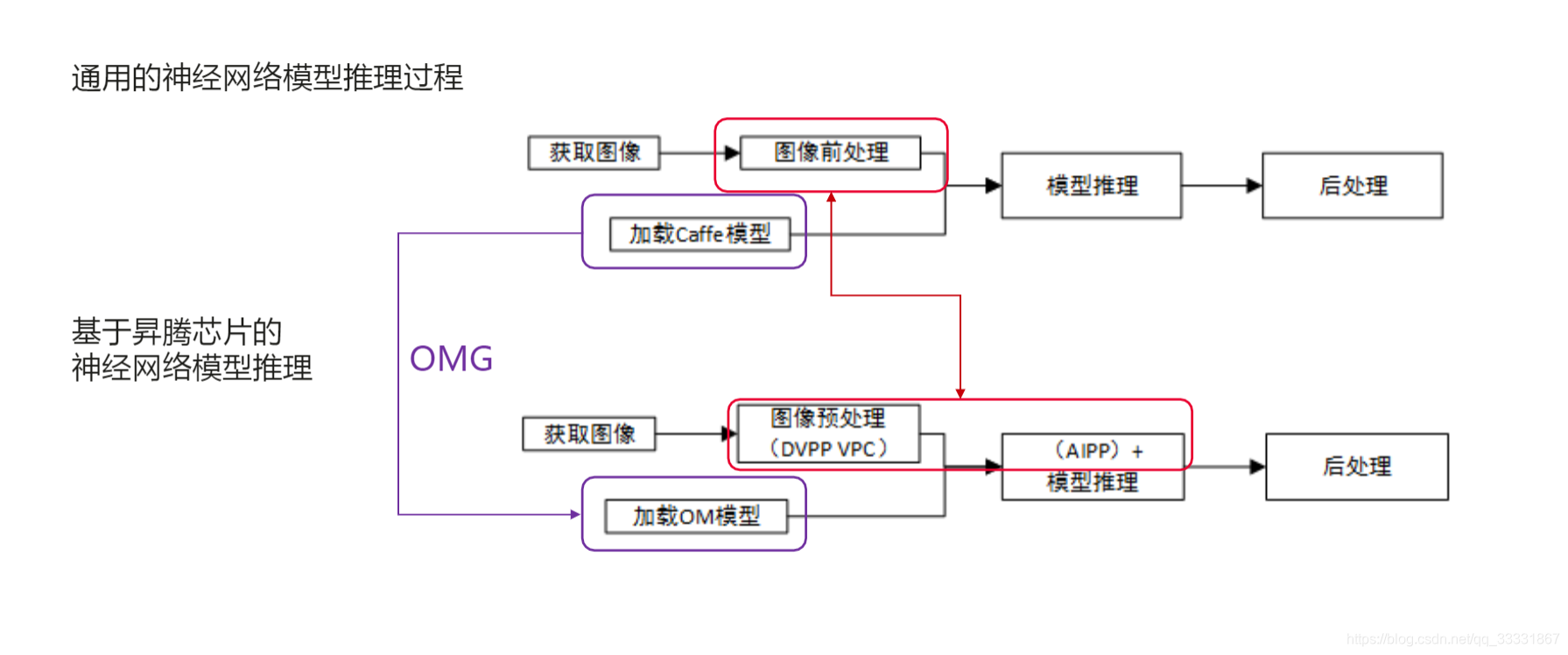
以基于caffe模型的神经网络应用开发为例,对于处理图像数据的神经网络推理,首先需要对图像前处理(阈值处理,尺寸变化等),然后加载所需的caffe模型进行模型推理,最后还要对推理的结果后处理。
而基于Ascend芯片的神经网络开发对图像的预处理在DVPP和AIPP两个模块进行,而所需的模型是经过模型转换后的OM模型。OM模型有OMG模块转换得到。
模型转换
添加所需要的的模型文件,我这里添加了示例给的resnet18的模型文件和权重文件
网络结构可以点右边小眼睛看到,右下角可以看到该网络模型的整体结构,包括左侧展示框中的算子在整体网络结构中的位置。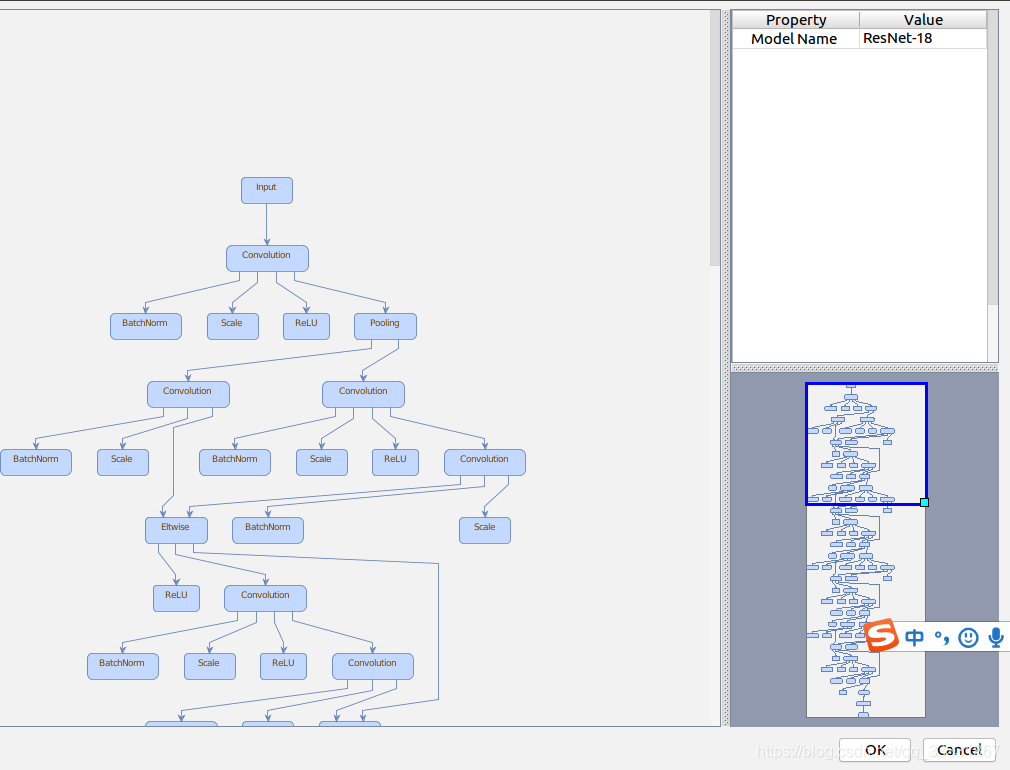
在点空白区域按Ctrl+F可以在右下角看到全部使用的算子,比如我点击了res4b_relu这个算子,就会切换到整个网络结构中使用该算子的地方,右上方会展示该算子的详细信息,包括算子名称、算子输入、输出等信息。不同网络层的算子名称不同,比如第一层的卷积层名为conv1,第二层左枝的卷积层名为res2a_branch1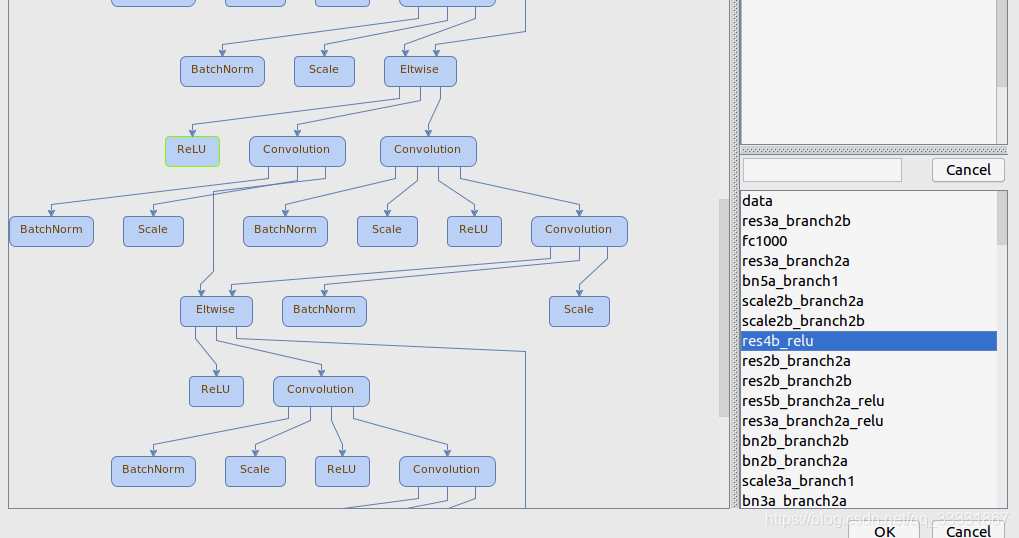
单击“Next”,进入“Nodes”节点配置页签。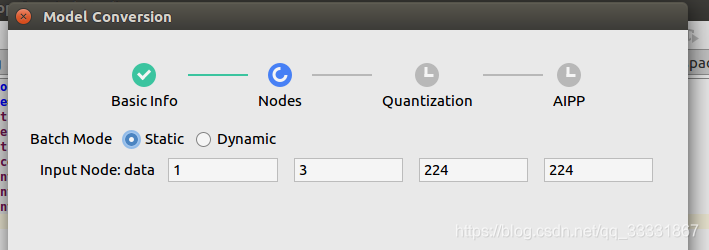
这里选择Static模型(型一次处理的图片数量为Input Node:data第一个参数的取值),下面的四个输入框根据模型:
◾对于Caffe模型:
右侧四个输入框分别代表输入数据的N(模型一次处理的图片个数),C(Channel,例如彩色RGB图像的Channel数为3),H(Height),W(Width)。
◾对于Tensorflow模型:
右侧四个输入框分别代表输入数据的N(模型一次处理的图片个数),H(Height),W(Width),C(Channel,例如彩色RGB图像的Channel数为3)。
单击“Next”,进入“Quantization”界面。
图像量化,我看新版Mindstudio无这个部分,我选择跳过。
单击“Next”,进入“AIPP”预处理界面。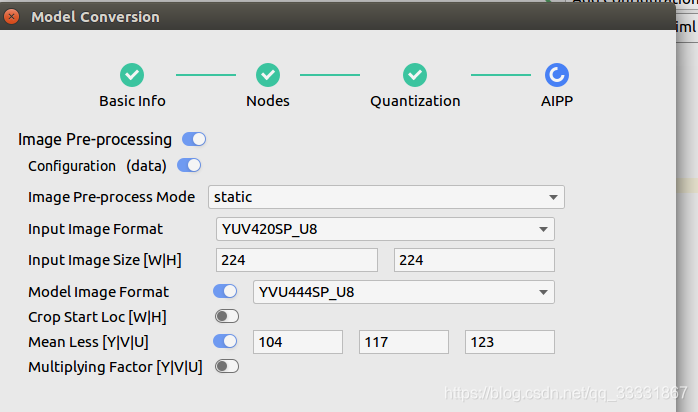
AIPP是昇腾AI处理器提供的硬件图像预处理模块,包括色域转换,图像归一化(减均值/乘系数)和抠图(指定抠图起始点,抠出神经网络需要大小的图片)等功能。DVPP模块输出的图片多为对齐后的YUV420SP类型,不支持输出RGB图片。因此,业务流需要使用AIPP模块转换对齐后YUV420SP类型图片的格式,并抠出模型需要的输入图片。
选择static模式:静态AIPP。在该模式下,模型生成后,AIPP参数值被保存在生成的.om模型中,模型推理过程采用固定的AIPP预处理(无法修改)。这里提一下输入图片格式
YUVNV12
RGB类似,YUV也是一种颜色编码方法,它将亮度信息(Y)与色彩信息(UV)分离,没有UV信息一样 可以显示完整的图像,只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。并且,YUV不像RGB那样要求三个独立的视频信号同时传 输,所以用YUV方式传送占用极少的频宽。
YUV,分为三个分量,“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
YUV格式分为YUV444, YUV422, YUV420等几种。其中YUV420又分为YUV420sp和YUV420p,而YUV420sp又分为NV12和NV21(反正是编码的方法不同具体的区别可以参考链接: https://blog.csdn.net/mydear_11000/article/details/50404084)
对于DVPP模块,输入数据既可以是图片数据(RGB),也可以是YUV(Luminance-Bandwidth-Chrominance)数据。DVPP模块会将输入图片转化为yuv420sp nv12输出。而在MDC中,摄像头输入的数据类型就是yuv420sp nv12,流程图如下: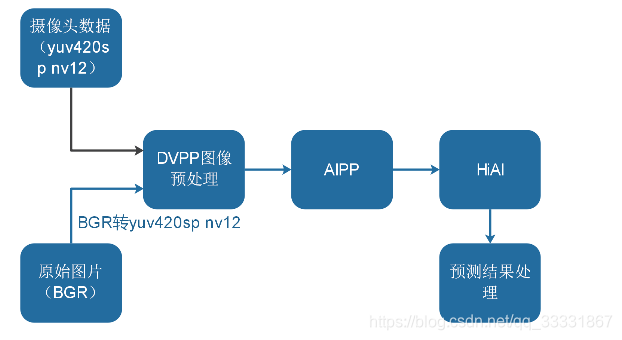
Input Image Format选项:YUV420SP_U8、XRGB8888_U8、RGB888_U8、YUV400_U8,模型转换完毕后,在对应的*.om模型文件中,上述四个参数分别以1、2、3、4参数呈现。这里我选择YUV420SP_U8,与摄像头输入一致。
Model Image Format选项:是色域转换配置,当输入图片格式与模型处理文件格式不一致时需要开启。
其余配置参考《Ascend 310 OMG模型转换工具使用指导》,然后点击finish。
在modelzoo目录下生成转化的模型
创建AI应用
新建一个分类网络应用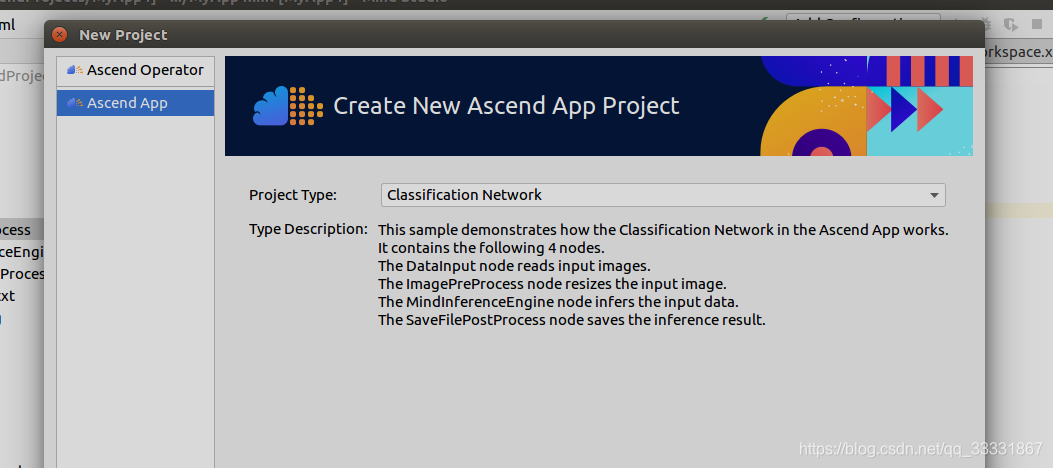
在graph.config配置模型目录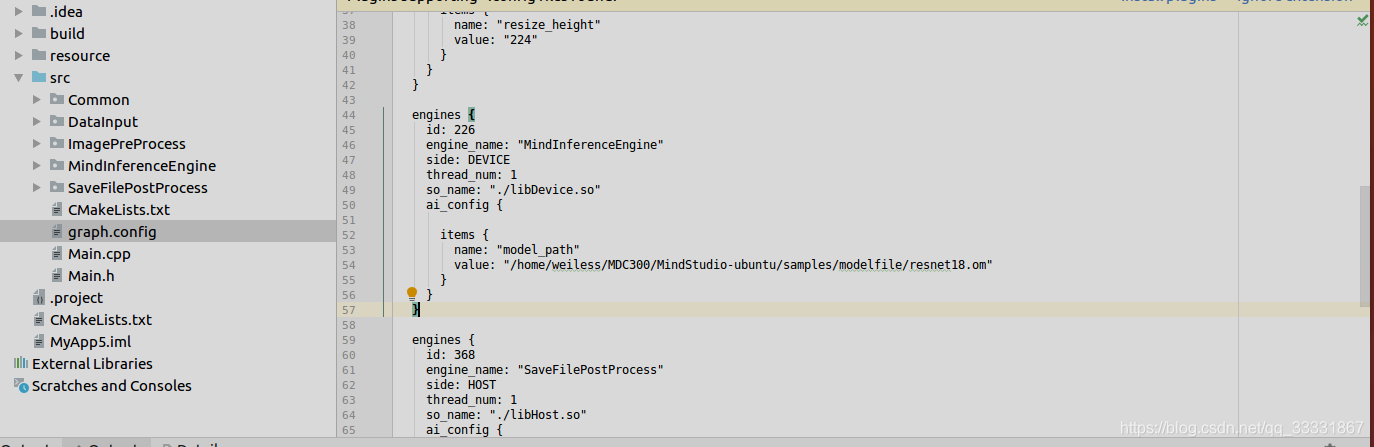
然后编译运行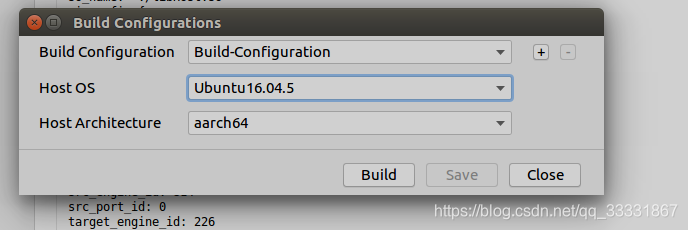
运行结果如下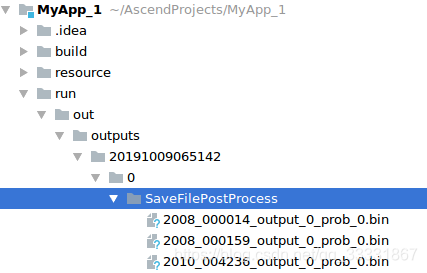

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)