第二章 认知诊断评估中属性界定的方法-续(DINA模型)
DINA模型(Deterministic Inputs, Noisy “And” gate model)是一种认知诊断模型,广泛应用于教育测量和心理学领域,用于分析被试者在测验中的表现,并推断其潜在的知识状态或技能掌握情况。DINA模型属于潜在类别模型的一种,能够将被试者的作答反应与潜在的知识状态联系起来。
(概念来源于Deepseek)
确定性输入噪音与门模型(Deterministic Input Noisy AND gate model, DINA)
DINA模型(Deterministic Inputs, Noisy “And” gate model)是一种认知诊断模型,广泛应用于教育测量和心理学领域,用于分析被试者在测验中的表现,并推断其潜在的知识状态或技能掌握情况。DINA模型属于潜在类别模型的一种,能够将被试者的作答反应与潜在的知识状态联系起来。
1. DINA模型的基本概念
DINA模型是一种认知诊断模型(Cognitive Diagnosis Model, CDM),用于分析被试在测试项目上的表现,并推断其是否掌握了某些潜在的认知技能或属性。DINA模型的核心思想是:
-
每个测试项目需要掌握特定的属性组合才能正确回答。
-
被试的表现受到确定性输入和噪音的影响。
1.1 关键术语
-
项目(Item):测试中的题目或任务。
-
属性(Attribute):潜在的认知技能或知识,通常用二进制表示(0表示未掌握,1表示掌握)。
-
Q矩阵:描述项目与属性之间关系的矩阵,( q_{jk} = 1 ) 表示项目 ( j ) 需要属性 ( k ),否则为 0。
-
确定性输入:被试是否掌握了项目所需的所有属性(通过逻辑“与”门计算)。
-
噪音:即使掌握了所有属性,被试也可能答错(猜测);即使未掌握所有属性,被试也可能答对(失误)。
2. DINA模型的数学模型

3. DINA模型的参数解释

4. DINA模型的应用场景
DINA模型广泛应用于教育测量和心理学领域,例如:
-
认知诊断评估:诊断学生在特定知识或技能上的掌握情况。
-
个性化学习:根据学生的认知状态提供个性化的学习建议。
-
测试开发:优化测试设计,确保项目能够有效测量目标属性。
5. DINA模型的优缺点
5.1 优点
-
简单直观:模型结构清晰,易于理解和解释。
-
诊断能力强:能够提供详细的认知诊断信息。
-
灵活性高:可以通过调整Q矩阵适应不同的测试场景。
5.2 缺点
-
对Q矩阵依赖性强:Q矩阵的准确性直接影响模型效果。
-
参数估计复杂度高:当属性数量较多时,参数估计可能变得复杂。
-
假设较强:假设所有属性都是二元的(掌握或未掌握),可能忽略部分掌握的情况。
6. DINA模型的扩展
DINA模型有一些扩展版本,例如:
-
HO-DINA模型:考虑高阶潜在结构,假设属性之间存在层次关系。
-
G-DINA模型:广义DINA模型,允许项目对属性的依赖关系更加灵活。
# 安装和加载CDM包
install.packages("CDM") # 安装CDM包,用于认知诊断建模
library(CDM) # 加载CDM包,以便使用其中的函数和工具
# 设置参数
n_subjects <- 10 # 被试数量(可以根据需要调整)
n_items <- 6 # 项目数量(可以根据需要调整)
n_attributes <- 3 # 属性数量(可以根据需要调整)
# 生成Q矩阵
# Q矩阵是一个二进制矩阵,行代表项目,列代表属性
# 1表示项目需要该属性,0表示不需要
q_matrix <- matrix(c(
1, 0, 0, # 项目1需要属性1
0, 1, 0, # 项目2需要属性2
1, 1, 0, # 项目3需要属性1和属性2
0, 0, 1, # 项目4需要属性3
1, 0, 1, # 项目5需要属性1和属性3
0, 1, 1 # 项目6需要属性2和属性3
), nrow = n_items, ncol = n_attributes, byrow = TRUE)
# matrix(data, nrow, ncol, byrow) 参数说明:
# - data: 矩阵的数据(向量形式)
# - nrow: 矩阵的行数
# - ncol: 矩阵的列数
# - byrow: 是否按行填充矩阵(TRUE表示按行填充)
# 生成被试的属性掌握模式
set.seed(123) # 设置随机种子以确保结果可重复
mastery_prob <- 0.6 # 每个属性被掌握的概率(可以根据需要调整)
# 使用rbinom函数生成被试的属性掌握模式
# rbinom(n, size, prob) 生成n个二项分布随机数,size为试验次数,prob为成功概率
attribute_patterns <- matrix(rbinom(n_subjects * n_attributes, 1, mastery_prob),
nrow = n_subjects, ncol = n_attributes)
# matrix(data, nrow, ncol) 参数说明:
# - data: 矩阵的数据(向量形式)
# - nrow: 矩阵的行数
# - ncol: 矩阵的列数
# 打印被试属性掌握模式
print("被试属性掌握模式:")
print(attribute_patterns) # 打印生成的被试属性掌握模式
# 生成反应数据
# 初始化反应数据矩阵,行代表被试,列代表项目
response_data <- matrix(0, nrow = n_subjects, ncol = n_items)
# matrix(data, nrow, ncol) 参数说明:
# - data: 矩阵的数据(0表示初始值为0)
# - nrow: 矩阵的行数
# - ncol: 矩阵的列数
# 遍历每个被试和每个项目,生成反应数据
for (i in 1:n_subjects) { # 遍历每个被试
for (j in 1:n_items) { # 遍历每个项目
# 检查被试是否掌握了项目所需的所有属性
required_attributes <- q_matrix[j, ] # 项目j所需的属性
mastered_attributes <- attribute_patterns[i, ] # 被试i的属性掌握模式
if (all(required_attributes <= mastered_attributes)) {
# 如果掌握了所有属性,正确回答的概率较高(1 - slip)
slip <- 0.1 # 失误参数(可以根据需要调整)
# rbinom(1, 1, 1 - slip) 生成一个二项分布随机数,1表示正确,0表示错误
response_data[i, j] <- rbinom(1, 1, 1 - slip)
} else {
# 如果未掌握所有属性,正确回答的概率较低(guess)
guess <- 0.2 # 猜测参数(可以根据需要调整)
# rbinom(1, 1, guess) 生成一个二项分布随机数,1表示正确,0表示错误
response_data[i, j] <- rbinom(1, 1, guess)
}
}
}
# 打印反应数据
print("反应数据:")
print(response_data) # 打印生成的反应数据
# 拟合DINA模型
# 使用CDM包中的din函数拟合DINA模型
# din(data, q.matrix, ...) 参数说明:
# - data: 反应数据矩阵(被试 × 项目)
# - q.matrix: Q矩阵(项目 × 属性)
dina_model <- din(data = response_data, q.matrix = q_matrix)
# 查看模型结果
# summary函数输出模型的详细信息,包括项目参数和被试属性掌握模式
summary(dina_model)
# 提取项目参数
# dina_model$item包含每个项目的失误参数(slip)和猜测参数(guess)
item_parameters <- dina_model$item
print("项目参数:")
print(item_parameters) # 打印项目参数
# 提取被试属性掌握模式
# dina_model$attribute.pattern包含每个被试的属性掌握模式
# 如果attribute.pattern不存在,尝试使用pattern或attribute字段
if (!is.null(dina_model$attribute.pattern)) {
attribute_patterns <- dina_model$attribute.pattern
} else if (!is.null(dina_model$pattern)) {
attribute_patterns <- dina_model$pattern
} else {
attribute_patterns <- dina_model$attribute
}
print("被试属性掌握模式:")
print(attribute_patterns) # 打印被试属性掌握模式
# 可视化项目参数
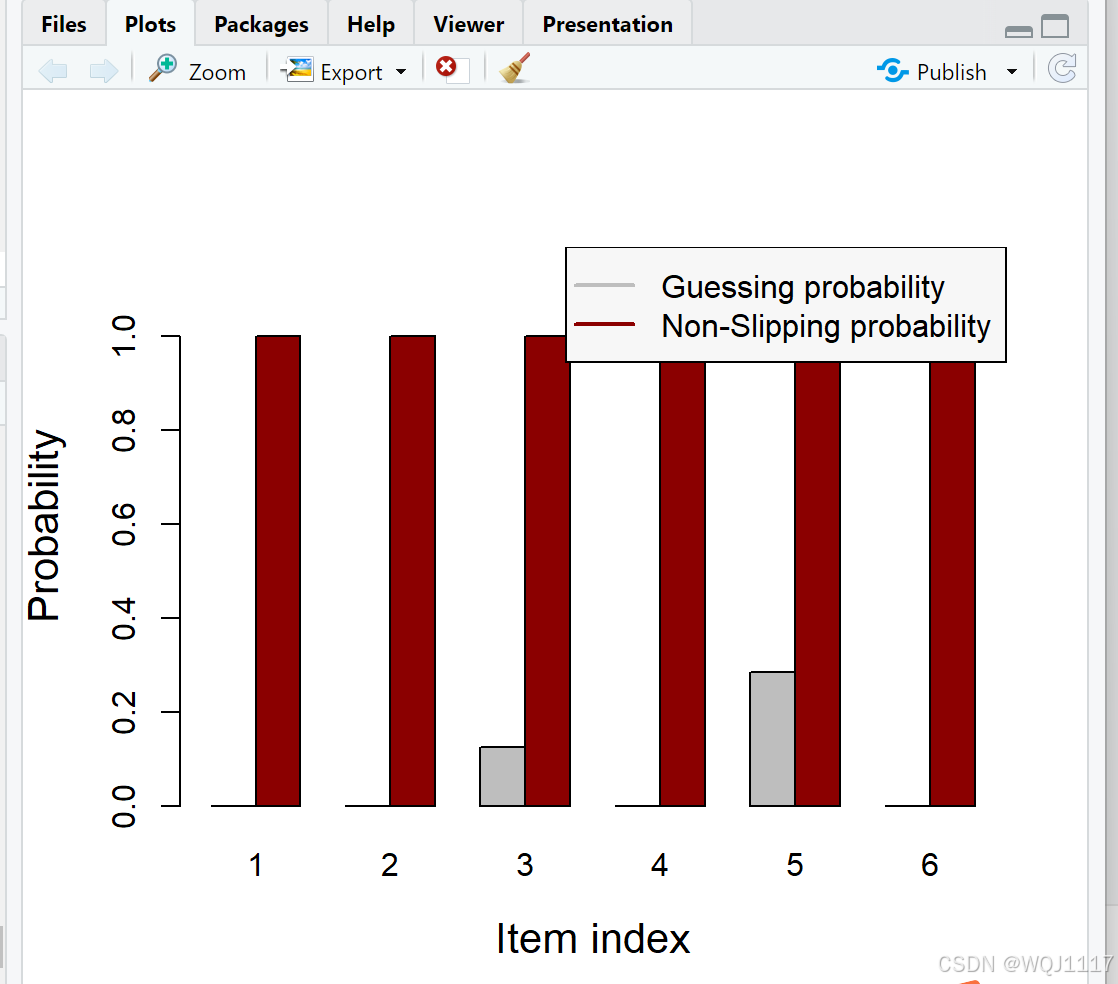
# plot函数绘制项目参数(失误参数和猜测参数)的图形
plot(dina_model)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)