图像超分辨率模型记录:SPAN — Swift Parameter-free Attention Network for Efficient Super-Resolution
本文介绍了一种名为Swift无参数注意网络(SPAN)的高效超分辨率模型。该模型通过引入无参数自注意力机制,解决了传统注意力机制在计算复杂度和参数数量上的问题。SPAN由6个SPAB块组成,每个块通过卷积层和对称激活函数提取特征,并结合残差连接生成最终输出。该模型在保持低复杂度和参数数量的同时,实现了快速的特征提取和图像重建。实验证明,SPAN在单图像超分辨率任务中具有高效性和优越性,适用于资源受
前言
论文题目:Swift Parameter-free Attention Network for Efficient Super-Resolution —— 用于高效超分辨率的Swift无参数注意网络
论文地址:Swift Parameter-free Attention Network for Efficient Super-Resolution
论文源码:https://github.com/hongyuanyu/SPAN
论文解读:是馒头阿(部分转载)
文章目录
1. 模型介绍
单图像超分辨率(SISR)是低级计算机视觉中一个已经确立的任务,其目的是从单个低分辨率图像重构出高分辨率图像。这个任务在各个领域都有广泛的应用,例如在图像质量的提升方面。深度学习的出现带来了这个领域的显著进步。超分辨率任务的最新进展主要得益于注意力机制。
许多最新的超分辨率网络都采用了注意力机制,甚至使用了更大的视觉Transformer(ViTs)作为模型架构。这些网络通过注意力图强调关键特征和补丁之间的长程依赖关系,捕获更广泛的上下文信息以确保细节的连贯性和边缘纹理的准确性。
然而,注意力机制的计算需求,包括复杂的网络结构和大量的额外参数,导致了如大型模型大小和缓慢推理速度等挑战。这些挑战限制了这些模型的适用性,阻碍了它们在高效、高速计算场景中的应用,如资源受限的移动设备上的SISR任务。
许多现有的高效超分辨率(ESR)技术已经在提高模型效率方面取得了一定的成功。一些模型主要关注减少模型FLOPs和参数,通过诸如分组卷积和深度可分卷积等方法实现。然而,仅仅减少FLOPs或参数并不总是能够显著提高模型的推理速度,同时也有可能降低模型准确性。其他模型通过共享特征信息和缩减非注意力分支来减少模型参数大小。
但是,这些模型在其复杂计算结构中仍然包含许多参数,导致运行时间较长。为了确保快速的推理速度,保持简单的网络拓扑结构至关重要。然而,传统的注意力机制通常会导致更复杂的网络结构。
为了应对这个问题,作者的主要贡献如下:
- 设计了一种新颖的参数自注意力机制,该机制利用对称激活函数和残差连接来增强高贡献信息并抑制冗余信息,从而简化网络结构并提高推理速度,同时不牺牲准确性。
- 提出了快速无参数自注意力网络(SPAN),它利用参数自注意力机制在保持低模型复杂度和参数数量的同时,实现快速有效的特征提取从浅层到深层。
- 通过理论分析和实验验证,作者证明了SPAN在单图像超分辨率任务中的有效性和优越性,证明了在资源受限的场景中,它具有实际应用价值和潜在的应用价值。
2. 模型结构
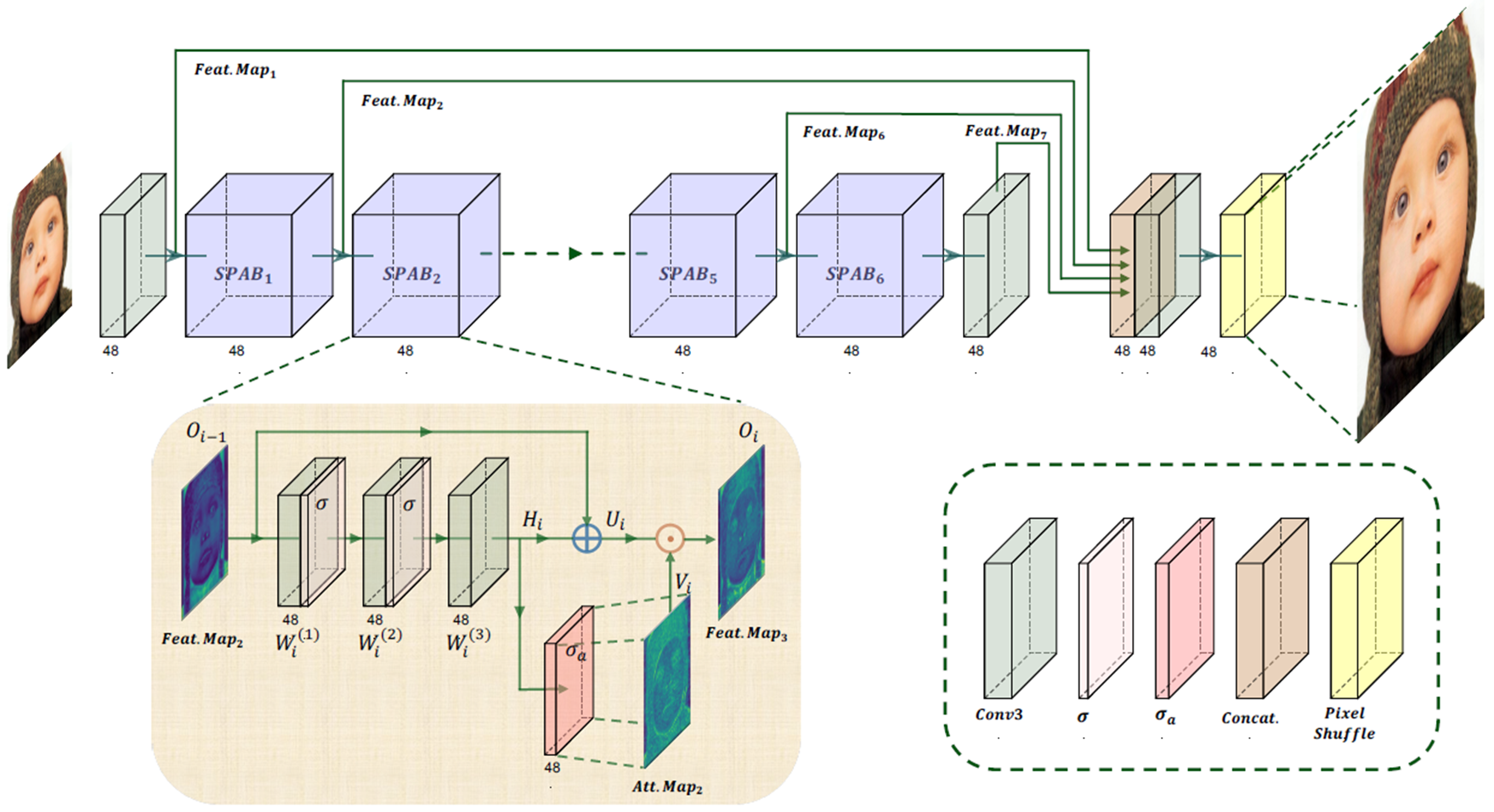
SPAN由6个连续的SPAB块组成,每个SPAB块通过三个带有C’通道、H’ × \times × W’ 尺寸核的卷积层逐步提取越来越高级的特征(在作者的模型中,作者选择H’=W’=3)。提取的特征Hi随后通过SPAB的输入进行残差连接,形成该块的预注意力特征图Ui。卷积层提取的特征通过关于原点的对称激活函数得到注意力图Vi。特征图和注意力图按元素相乘得到SPAB块的最终输出: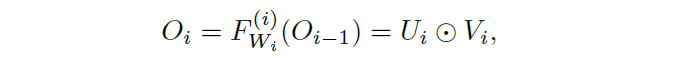
最后,这个特征图经过像素重排模块生成一个具有C个通道和尺寸 rH × \times × rW 的高分辨率图像,其中r表示超分辨率因子。
3. 无参数注意力机制
在以前的超分辨率工作中,虽然注意力图可以通过允许模型选择性地关注特征的最相关部分来提高模型准确性,但计算注意力图引入了额外的参数,这降低了模型的计算速度。
在SPAB中,作者直接通过一个关于原点对称的激活函数从卷积层提取的高层次特征信息获得注意力图。因为在计算注意力图的分支中,除了激活函数之外没有可训练参数的模块,所以作者的自注意力机制是无参数的。
直接计算注意力图而不需要额外的参数的想法,导致了作者神经网络的两个设计考虑:计算注意力图的激活函数的选择和使用残差连接。
4. 模型实现
- SPAN网络结构:浅层特征提取3 × \times × 3Conv,深层特征提取6个SPAB块,重建层3 × \times × 3Conv + Pixel Shufle。浅层特征输出、SPAB1、SPAB2、SPAB3、SPAB4、SPAB5、SPAB6、Conv的输出在重建层之前Concat。
- SPAB块:包含3个卷积层 + 原点对称的激活函数,对称激活后的输出与激活前的输出 + 残差链接逐元素乘获得特征映射。
- 激活函数: σ α \sigma_\alpha σα(x) = Sigmoid(x) - 0.5
具体实现代码如下:
# SPAB (Swifter Parameter-free Attention Block) 模块
class SPAB(nn.Module):
def __init__(self,
in_channels, # 输入通道数
mid_channels=None, # 中间层通道数,默认为输入通道数
out_channels=None, # 输出通道数,默认为输入通道数
bias=False): # 是否使用偏置
super(SPAB, self).__init__()
if mid_channels is None:
mid_channels = in_channels # 默认中间层通道数等于输入通道数
if out_channels is None:
out_channels = in_channels # 默认输出通道数等于输入通道数
self.in_channels = in_channels # 保存输入通道数
# 三个3x3卷积层
self.c1_r = Conv3XC(in_channels, mid_channels, gain1=2, s=1) # 第一层卷积
self.c2_r = Conv3XC(mid_channels, mid_channels, gain1=2, s=1) # 第二层卷积
self.c3_r = Conv3XC(mid_channels, out_channels, gain1=2, s=1) # 第三层卷积
self.act1 = torch.nn.SiLU(inplace=True) # SiLU激活函数 (也称为Swish)
self.act2 = activation('lrelu', neg_slope=0.1, inplace=True) # LeakyReLU激活函数
def forward(self, x):
# 第一层卷积 + 激活
out1 = (self.c1_r(x))
out1_act = self.act1(out1)
# 第二层卷积 + 激活
out2 = (self.c2_r(out1_act))
out2_act = self.act1(out2)
# 第三层卷积
out3 = (self.c3_r(out2_act))
# 计算注意力权重: sigmoid(out3) - 0.5 (范围从-0.5到0.5)
sim_att = torch.sigmoid(out3) - 0.5 # sigma_a
# 应用注意力权重并添加残差连接
out = (out3 + x) * sim_att
return out, out1, sim_att # 返回输出、中间特征和注意力权重
# SPAN (Swift Parameter-free Attention Network) 主网络
@ARCH_REGISTRY.register()
class SPAN(nn.Module):
"""
用于高效超分辨率的轻量级无参数注意力网络
论文: Swift Parameter-free Attention Network for Efficient Super-Resolution
"""
def __init__(self,
num_in_ch, # 输入通道数(如RGB图像为3)
num_out_ch, # 输出通道数(如RGB图像为3)
feature_channels=48, # 特征通道数,默认为48
upscale=4, # 上采样比例
bias=True, # 是否使用偏置
img_range=255., # 图像值范围(用于归一化)
rgb_mean=(0.4488, 0.4371, 0.4040) # RGB通道均值(用于归一化)
):
super(SPAN, self).__init__()
in_channels = num_in_ch
out_channels = num_out_ch
self.img_range = img_range # 保存图像范围
self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1) # 将均值转换为(1,3,1,1)形状的张量
# 浅层特征提取
self.conv_1 = Conv3XC(in_channels, feature_channels, gain1=2, s=1) # 输入到特征空间的卷积
# 6个SPAB模块
self.block_1 = SPAB(feature_channels, bias=bias)
self.block_2 = SPAB(feature_channels, bias=bias)
self.block_3 = SPAB(feature_channels, bias=bias)
self.block_4 = SPAB(feature_channels, bias=bias)
self.block_5 = SPAB(feature_channels, bias=bias)
self.block_6 = SPAB(feature_channels, bias=bias)
# 特征融合层
self.conv_cat = conv_layer(feature_channels * 4, feature_channels, kernel_size=1, bias=True) # 1x1卷积用于融合特征
# 上采样部分
self.conv_2 = Conv3XC(feature_channels, feature_channels, gain1=2, s=1) # 上采样前的卷积
self.upsampler = pixelshuffle_block(feature_channels, out_channels, upscale_factor=upscale) # PixelShuffle上采样
def forward(self, x):
# 将均值转换为与输入x相同类型
self.mean = self.mean.type_as(x)
# 输入归一化: (x - mean) * range
x = (x - self.mean) * self.img_range
# 浅层特征提取
out_feature = self.conv_1(x)
# 通过6个SPAB模块
out_b1, _, att1 = self.block_1(out_feature)
out_b2, _, att2 = self.block_2(out_b1)
out_b3, _, att3 = self.block_3(out_b2)
out_b4, _, att4 = self.block_4(out_b3)
out_b5, _, att5 = self.block_5(out_b4)
out_b6, out_b5_2, att6 = self.block_6(out_b5)
# 上采样前的卷积
out_b6 = self.conv_2(out_b6)
# 特征融合: 连接浅层特征、最后一个SPAB输出和中间SPAB输出
out = self.conv_cat(torch.cat([out_feature, out_b6, out_b1, out_b5_2], 1))
# 上采样得到最终输出
output = self.upsampler(out)
return output

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)