Tensorrt 实现 yolov5x + dcnv2
由于固定的几何结构,CNN固有地限制了模拟几何转变。本篇论文我们引入了两个模块来加强CNN转变模拟能力,称之为可变卷积和可变Roi 池化。这些都是基于,在没有额外监督的情况下,通过额外的偏移量来增加模块中的空间采样位置,并从目标任务中学习偏移量。新模块可以替换CNN中的普通模块,并且能通过标准的反向传播进行端到端训练,得到的成为可变卷积网络。大量实验表明这个模块性能确实有提升。

由于可变形卷积在采样时可以更贴近物体的形状和尺寸,更具有鲁棒性。所以想在自己数据集尝试一波,看看是否能涨点。
Paper: Deformable Convolutional Networks

python 增加 dcnv2 🚀
-
安装
dcnv2https://github.com/jinfagang/DCNv2_latestpython3 setup.py build develop -
common.py 增加 dcn op
# --------------------------DCNv2 start-------------------------- import _ext as _backend class _DCNv2(Function): @staticmethod def forward(ctx, input, offset, mask, weight, bias, stride, padding, dilation, deformable_groups): is_convert = input.dtype != torch.float32 if is_convert: input = input.float() offset = offset.float() mask = mask.float() weight = weight.float() bias = bias.float() ctx.stride = _pair(stride) ctx.padding = _pair(padding) ctx.dilation = _pair(dilation) ctx.kernel_size = _pair(weight.shape[2:4]) ctx.deformable_groups = deformable_groups output = _backend.dcn_v2_forward( input, weight, bias, offset, mask, ctx.kernel_size[0], ctx.kernel_size[1], ctx.stride[0], ctx.stride[1], ctx.padding[0], ctx.padding[1], ctx.dilation[0], ctx.dilation[1], ctx.deformable_groups, ) ctx.save_for_backward(input, offset, mask, weight, bias) if is_convert: return output.half() return output @staticmethod @once_differentiable def backward(ctx, grad_output): is_convert = grad_output.dtype != torch.float32 if is_convert: grad_output = grad_output.float() input, offset, mask, weight, bias = ctx.saved_tensors grad_input, grad_offset, grad_mask, grad_weight, grad_bias = _backend.dcn_v2_backward( input, weight, bias, offset, mask, grad_output, ctx.kernel_size[0], ctx.kernel_size[1], ctx.stride[0], ctx.stride[1], ctx.padding[0], ctx.padding[1], ctx.dilation[0], ctx.dilation[1], ctx.deformable_groups, ) if is_convert: grad_input = grad_input.half() grad_offset = grad_offset.half() grad_mask = grad_mask.half() grad_weight = grad_weight.half() grad_bias = grad_bias.half() return grad_input, grad_offset, grad_mask, grad_weight, grad_bias, None, None, None, None @staticmethod def symbolic(g, input, offset, mask, weight, bias, stride, padding, dilation, deformable_groups): from torch.nn.modules.utils import _pair stride = _pair(stride) padding = _pair(padding) dilation = _pair(dilation) # as of trt 7, the dcn operation will be translated again by modifying the onnx file # so the exporting code is kept to resemble the forward() return g.op( "DCNv2_2", input, offset, mask, weight, bias, stride_i=stride, padding_i=padding, dilation_i=dilation, deformable_groups_i=deformable_groups, ) dcn_v2_conv = _DCNv2.apply class DCNv2(nn.Module): def __init__( self, in_channels, out_channels, kernel_size, stride, padding=1, dilation=1, deformable_groups=1, ): super(DCNv2, self).__init__() self.in_channels = in_channels self.out_channels = out_channels self.kernel_size = _pair(kernel_size) self.stride = _pair(stride) self.padding = _pair(padding) self.dilation = _pair(dilation) self.deformable_groups = deformable_groups self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels, *self.kernel_size)) self.bias = nn.Parameter(torch.Tensor(out_channels)) self.reset_parameters() def reset_parameters(self): n = self.in_channels for k in self.kernel_size: n *= k stdv = 1.0 / math.sqrt(n) self.weight.data.uniform_(-stdv, stdv) self.bias.data.zero_() def forward(self, input, offset, mask): assert ( 2 * self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == offset.shape[1] ) assert self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == mask.shape[1] return dcn_v2_conv( input, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation, self.deformable_groups, ) class DCN(DCNv2): def __init__( self, in_channels, out_channels, kernel_size, stride, padding=1, dilation=1, deformable_groups=1, ): super(DCN, self).__init__( in_channels, out_channels, kernel_size, stride, padding, dilation, deformable_groups ) channels_ = self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1] self.conv_offset_mask = nn.Conv2d( self.in_channels, channels_, kernel_size=self.kernel_size, stride=self.stride, padding=self.padding, bias=True, ) self.init_offset() set_amp(self.training) def init_offset(self): self.conv_offset_mask.weight.data.zero_() self.conv_offset_mask.bias.data.zero_() def forward(self, input): out = self.conv_offset_mask(input) o1, o2, mask = torch.chunk(out, 3, dim=1) offset = torch.cat((o1, o2), dim=1) mask = torch.sigmoid(mask) return dcn_v2_conv( input, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation, self.deformable_groups, ) # ---------------------------DCNv2 end--------------------------- -
yolo.py 增加 dcnv2 , parse_model 函数
# 增加 DCNV2 if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, C3HB, C3RFEM, MultiSEAM, SEAM, C3STR, MobileOneBlock, DCN]: -
编辑 训练 config ,增加 DCN 模块, 这里增加3层DCN, 如果增加4层的话,在我训练集上训练, 几个 epoch 后 ,梯度会消失,原因未知.
# Parameters nc: 6 # number of classes depth_multiple: 1.33 # model depth multiple width_multiple: 1.25 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, DCN, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, DCN, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, DCN, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ] -
expected scalar type Float but found Half
当训练时,会发生如上错误。大概意思就是输入input 不支持半精度, 只支持单精度的。参考了下这位兄弟的代码 https://github.com/CharlesShang/DCNv2/issues/43#issuecomment-648127833,稍微改动了一下。就是如果输入的数据不是单精度,会将数据先转换成单精度32位的,然后最后再把输出的数据转换成半精度16位的。
使用 tensorrt 编写 DCN plugins 🤖
-
dcnv2.h 参考: https://github.com/SsisyphusTao/Pytorch-TensorRT-Plugins
dcnv2Plugin.h -
dcnv2.cpp 参考: https://github.com/SsisyphusTao/Pytorch-TensorRT-Plugins
dcnv2Plugin.cpp -
这里改动了几个地方, 参考如下.
// enqueue 函数 // 屏蔽 mask // const float* mask = offset_mask + deformable_group * 2 * kernel_size * kernel_size * height * width; // mask 改成 offset_mask modulated_deformable_im2col_cuda(stream, input, offset, offset_mask, 1, in_channels, height, width, height_out, width_out, kernel_size, kernel_size, padding, padding, stride, stride, dilation, dilation, deformable_group, mColumn); // createPlugin 函数 感觉原来的参数传的太费劲 IPluginV2Ext* DCNv2PluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc) TRT_NOEXCEPT { assert(fc->nbFields == 3); std::vector<float> weight; std::vector<float> bias; int in_channel, out_channel, kernel, deformable_group, groups, padding, stride, dilation; const PluginField* fields = fc->fields; for (int i = 0; i < fc->nbFields; ++i) { const char* attrName = fields[i].name; if (!strcmp(attrName, "netinfo")) { int* p_netinfo = (int*)(fields[i].data); in_channel = p_netinfo[0]; out_channel = p_netinfo[1]; kernel = p_netinfo[2]; deformable_group = p_netinfo[3]; dilation = p_netinfo[4]; stride = p_netinfo[5]; padding = p_netinfo[6]; groups = p_netinfo[7]; } else if (!strcmp(attrName, "weight")) { assert(fields[i].type == PluginFieldType::kFLOAT32); int size = fields[i].length; weight.reserve(size); const auto* w = static_cast<const float*>(fields[i].data); for (int j = 0; j < size; j++) { weight.push_back(*w); w++; } } else if (!strcmp(attrName, "bias")) { assert(fields[i].type == PluginFieldType::kFLOAT32); int size = fields[i].length; bias.reserve(size); const auto* w = static_cast<const float*>(fields[i].data); for (int j = 0; j < size; j++) { bias.push_back(*w); w++; } } } Weights mWeight{ DataType::kFLOAT, weight.data(), (int64_t)weight.size() }; Weights mBias{ DataType::kFLOAT, bias.data(), (int64_t)bias.size() }; DCNv2Plugin* obj = new DCNv2Plugin(out_channel, kernel, deformable_group, dilation, padding, stride, &mWeight, &mBias); obj->setPluginNamespace(mNamespace.c_str()); return obj; } -
dcn_v2_im2col_cuda.h 和 dcn_v2_im2col_cuda.cu 参考: https://github.com/jinfagang/DCNv2_latest/tree/master/src/cuda
-
使用
gen_wts.py生成 wts.import sys import argparse import os import struct import torch from utils.torch_utils import select_device def parse_args(): parser = argparse.ArgumentParser(description='Convert .pt file to .wts') parser.add_argument('-w', '--weights', default="weights/test_dcn.pt", help='Input weights (.pt) file path (required)') parser.add_argument( '-o', '--output', default='weights', help='Output (.wts) file path (optional)') parser.add_argument( '-t', '--type', type=str, default='detect', choices=['detect', 'cls'], help='determines the model is detection/classification') args = parser.parse_args() if not os.path.isfile(args.weights): raise SystemExit('Invalid input file') if not args.output: args.output = os.path.splitext(args.weights)[0] + '.wts' elif os.path.isdir(args.output): args.output = os.path.join( args.output, os.path.splitext(os.path.basename(args.weights))[0] + '.wts') return args.weights, args.output, args.type pt_file, wts_file, m_type = parse_args() # Initialize device = select_device('cpu') # Load model model = torch.load(pt_file, map_location=device) # load to FP32 model = model['ema' if model.get('ema') else 'model'].float() if m_type == "detect": # update anchor_grid info anchor_grid = model.model[-1].anchors * \ model.model[-1].stride[..., None, None] # model.model[-1].anchor_grid = anchor_grid delattr(model.model[-1], 'anchor_grid') # model.model[-1] is detect layer # The parameters are saved in the OrderDict through the "register_buffer" method, and then saved to the weight. model.model[-1].register_buffer("anchor_grid", anchor_grid) model.to(device).eval() with open(wts_file, 'w') as f: f.write('{}\n'.format(len(model.state_dict().keys()))) for k, v in model.state_dict().items(): vr = v.reshape(-1).cpu().numpy() f.write('{} {} '.format(k, len(vr))) for vv in vr: f.write(' ') f.write(struct.pack('>f', float(vv)).hex()) f.write('\n') -
查看网络模型结构, 可以看到只需将
conv层 改成dcnv2层 就行,其他的不用变. 参考 : https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5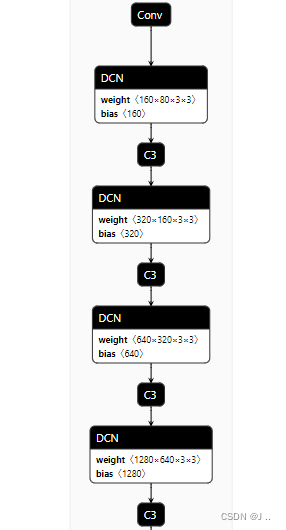
-
实现 DCN 层
nvinfer1::ILayer* convDcn(nvinfer1::INetworkDefinition* network, std::map<std::string, nvinfer1::Weights>& weightMap, nvinfer1::ITensor& input, std::string lname, int outch, int inChannel, int outChannel, int kernelSize = 3, int stride = 2, int padding = 1) { IConvolutionLayer* conv_offset_mask = network->addConvolutionNd(input, outch, DimsHW{ kernelSize, kernelSize }, weightMap[lname + ".conv_offset_mask.weight"], weightMap[lname + ".conv_offset_mask.bias"]); conv_offset_mask->setPaddingNd(DimsHW{ padding, padding }); conv_offset_mask->setStrideNd(DimsHW{ stride, stride }); assert(conv_offset_mask); Dims conv_offset_mask_dim = conv_offset_mask->getOutput(0)->getDimensions(); ISliceLayer* o1 = network->addSlice(*conv_offset_mask->getOutput(0), Dims3{ 0, 0, 0 }, Dims3{ conv_offset_mask_dim.d[0] / 3 , conv_offset_mask_dim.d[1], conv_offset_mask_dim.d[2] }, Dims3{ 1, 1, 1 }); ISliceLayer* o2 = network->addSlice(*conv_offset_mask->getOutput(0), Dims3{ conv_offset_mask_dim.d[0] / 3, 0, 0 }, Dims3{ conv_offset_mask_dim.d[0] / 3 , conv_offset_mask_dim.d[1], conv_offset_mask_dim.d[2] }, Dims3{ 1, 1, 1 }); ISliceLayer* mask = network->addSlice(*conv_offset_mask->getOutput(0), Dims3{ conv_offset_mask_dim.d[0] / 3 * 2, 0, 0 }, Dims3{ conv_offset_mask_dim.d[0] / 3 , conv_offset_mask_dim.d[1], conv_offset_mask_dim.d[2] }, Dims3{ 1, 1, 1 }); ITensor* concatTensors[] = { o1->getOutput(0),o2->getOutput(0) }; IConcatenationLayer* offset = network->addConcatenation(concatTensors, 2); assert(offset); auto sigmoid_conv_offset_mask = network->addActivation(*mask->getOutput(0), ActivationType::kSIGMOID); auto creator = getPluginRegistry()->getPluginCreator("DCNv2", "1"); PluginField plugin_fields[3]; plugin_fields[0].data = weightMap[lname + ".weight"].values; plugin_fields[0].length = weightMap[lname + ".weight"].count; plugin_fields[0].name = "weight"; plugin_fields[0].type = PluginFieldType::kFLOAT32; plugin_fields[1].data = weightMap[lname + ".bias"].values; plugin_fields[1].length = weightMap[lname + ".bias"].count; plugin_fields[1].name = "bias"; plugin_fields[1].type = PluginFieldType::kFLOAT32; int dilation = 1; int groups = 1; int deformable_group = 1; int netinfo[8] = { inChannel, outChannel, kernelSize, deformable_group, dilation, stride, padding, groups }; plugin_fields[2].data = netinfo; plugin_fields[2].length = 8; plugin_fields[2].name = "netinfo"; plugin_fields[2].type = PluginFieldType::kINT32; PluginFieldCollection plugin_data; plugin_data.nbFields = 3; plugin_data.fields = plugin_fields; IPluginV2* plugin_obj = creator->createPlugin("dcnlayer", &plugin_data); std::vector<ITensor*> input_tensors; input_tensors.push_back(&input); input_tensors.push_back(offset->getOutput(0)); input_tensors.push_back(sigmoid_conv_offset_mask->getOutput(0)); auto dcn = network->addPluginV2(&input_tensors[0], input_tensors.size(), *plugin_obj); return dcn; } -
修改 yolov5 backbone
/* ------ yolov5 backbone------ */ auto conv0 = convBlock(network, weightMap, *data, get_width(64, gw), 6, 2, 1, "model.0"); assert(conv0); // 160 * 160 * 160 auto dcnconv1 = convDcn(network, weightMap, *conv0->getOutput(0), "model.1", 27, get_width(64, gw), get_width(128, gw)); assert(dcnconv1); auto bottleneck_csp2 = C3(network, weightMap, *dcnconv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2"); // 320 * 80 * 80 auto dcnconv3 = convDcn(network, weightMap, *bottleneck_csp2->getOutput(0), "model.3", 27, get_width(128, gw), get_width(256, gw)); assert(dcnconv3); auto bottleneck_csp4 = C3(network, weightMap, *dcnconv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(6, gd), true, 1, 0.5, "model.4"); // 640 * 40 * 40 auto dcnconv5 = convDcn(network, weightMap, *bottleneck_csp4->getOutput(0), "model.5", 27, get_width(256, gw), get_width(512, gw)); assert(dcnconv5); auto bottleneck_csp6 = C3(network, weightMap, *dcnconv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6"); auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7"); auto bottleneck_csp8 = C3(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), true, 1, 0.5, "model.8"); auto spp9 = SPPF(network, weightMap, *bottleneck_csp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, "model.9"); -
增加模型 这里我增加 x_dcn
bool parse_args(int argc, char** argv, std::string& wts, std::string& engine, bool& is_p6, float& gd, float& gw, std::string& img_dir) { if (argc < 4) return false; if (std::string(argv[1]) == "-s" && (argc == 5 || argc == 7)) { wts = std::string(argv[2]); engine = std::string(argv[3]); auto net = std::string(argv[4]); if (net[0] == 'n') { gd = 0.33; gw = 0.25; } else if (net[0] == 's') { gd = 0.33; gw = 0.50; } else if (net[0] == 'm') { gd = 0.67; gw = 0.75; } else if (net[0] == 'l') { gd = 1.0; gw = 1.0; } else if (net[0] == 'x') { gd = 1.33; gw = 1.25; } else if (net[0] == 'x_dcn') { gd = 1.33; gw = 1.25; } else if (net[0] == 'c' && argc == 7) { gd = atof(argv[5]); gw = atof(argv[6]); } else { return false; } if (net.size() == 2 && net[1] == '6') { is_p6 = true; } } else if (std::string(argv[1]) == "-d" && argc == 4) { engine = std::string(argv[2]); img_dir = std::string(argv[3]); } else { return false; } return true; } -
序列化模型和推理
// serialize model to plan file ./yolov5_det -s [.wts] [.engine] [n/s/m/l/x/x_dcn/n6/s6/m6/l6/x6 or c/c6 gd gw] // deserialize and run inference, the images in [image folder] will be processed. ./yolov5_det -d [.engine] [image folder]
关于验证结论 👉
在自己数据集上验证,ap 提高了 0.5. 感觉效果不是太大。有的作者反馈提升了5个ap, 感觉没有那么邪乎,反正仁者见仁智者见智,可能针对我的数据集不是太适合,大家有啥好的想法欢迎讨论。

DEMO 🔊
参考 tensorrtx yolov5 , 实现 yolov5 + dcnv2
参考 👀
- https://github.com/SsisyphusTao/Pytorch-TensorRT-Plugins
- https://github.com/lesliejackson/TensorRT-DCNv2-Plugin
- https://github.com/xingyizhou/CenterNet/tree/master/src/lib
- https://github.com/jinfagang/DCNv2_latest
- https://github.com/wang-xinyu/tensorrtx
- https://zhuanlan.zhihu.com/p/361327540
END 🎭
- 以上记录了实现全部过程,有需要小伙伴可以参考下。
- 学习过程难免有差错,有不对的地方欢迎大佬指正.
- 最后码字不易,欢迎三连。
If I have seen further, it is by standing on the shoulders of giants.


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)