计算机图形学三:光栅化与深度缓存
计算机图形学基础
光栅化与深度缓存
1.光栅化
光栅(Raster)在德语中就是屏幕的意思,光栅化(Rasterizer)就是把东西画在屏幕上的过程。也就是说我们如果要把摄像机所看见的三维场景最终呈现在我们的屏幕上,就需要光栅化这个过程。
在深入光栅化之前,我们先来了解一下屏幕(Screen)的概念和一些细节
1.1屏幕(Screen)
在图形学中,我们把屏幕抽象成一个二维数组,数组中每个元素称之为像素(pixel,picture element的缩写),这个数组的大小,就是分辨率(Resolution),例如我们平常说屏幕分辨率为1920*1080,就是再说有这么多个像素。
而像素等于屏幕中的一个最小单位,我们可以把它理解为一个小方块,像素内的颜色用RGBA来表示,一个像素内只存在一种颜色(注:我们这里只是对像素的一个最简单理解,实际上随着硬件的发展,不同的屏幕上的像素本身也可能是各式各样的)。颜色是三原色RGB的混合颜色。
屏幕是一个典型的光栅成像设备(Raster display)。
其他光栅设备还有: 示波器(Oscilloscope)
阴极射线管(Cathode Ray Tube,早期的显示器)
液晶显示器(Liquid CrystalDisplay,LCD,利用了光的波动性,液晶的扭曲)
发光二极管(Light Emitting Diode,LED)
墨水屏(Electrophoretic Display,刷新率很低)
1.2屏幕空间(Screen Space)
定义屏幕空间相当于在屏幕上建立一个坐标系,这里我们以屏幕的左下角为原点,向右为x轴方向,向上是y轴方向(注,定义的方法有很多种,例如我们也可以左上角为原点,在后续的操作中遵循自己的定义即可)。
在OpenGL当中屏幕空间的原点在左下角,而在DX当中,屏幕空间原点在左上角。
由于屏幕抽象为了二维数组,在经过视口变换后,物体的图像在NDC中从[-1,1]被拉伸到了[0,width],[0,height]的范围。
每个像素的中心点在(x+0.5,y+0.5),像素的坐标范围从(0,0)到(width-1,height-1)
屏幕覆盖区域范围(0,0)到(width,height)。
1.3Mesh与三角形
经过视口变换后,我们的标准立方体变成了一个xy方向上和屏幕一样大的立方体,但是空间中还是我们的三维物体,比如人,建筑,树木等。我们知道屏幕是由一个个像素组成的,也就是说我们通过屏幕看到的二维画面其实就是由无数个像素构成的,因此我们接下来要把空间中的三维物体打散成像素,这个过程就被称之为光栅化。
那么首先,我们要知道三维物体到底是什么
在生活中,不管是相机拍摄还是人眼看,我们仅仅能看到的都是物体表面,因此我们要展示在屏幕上的,也就是三维物体的表面。
对于表面而言,我们可以把它们理解成由多个不同平面组成的,例如长方体是由6个长方形组成,在计算机图形学中,我们需要把表面分解为无数个不同的小三角形(Triangle)。这些三角形像网一样被编织在一起,就可以形成任何我们想要的三维物体表面,这些由三角形构成的表面我们叫做mesh(面片)。

为什么选择三角形呢?
- 1.三角形是最基础的多边形,其他任何的多边形都可以拆分成三角形
- 2.我们可以通过向量的叉积来判断点在三角形内或者外,但是对于有凹凸的多边形则不行。
- 3.我们给定三个顶点不同的属性,在三角形内作出渐变效果,即可根据插值算出三角形内任意一点的属性。主要利用重心坐标。
光栅化过程,输入是三角形投影到屏幕上的顶点位置,输出是像素值。
1.4单个三角形光栅化
通过上面的解释,我们又把问题进行了简化,也就是三维物体光栅化是把
无数三角形进行光栅化。那么我么先来看看如何把空间中一个三角形进行光栅化。
如下图,背景中的黑色实线所围成的小格子即是我们的像素,灰色虚线为辅助线,方便看像素的中心点:
注:在图中我们可以看见显示的是一个二维空间中的三角形,我们可以理解为把三维空间中的三角形投影到了xy屏幕上,因为光栅化是在MVP变换后做的,视图变换后,摄像机看向-Z轴,投影变换后,无论是正交投影的长方体还是透视投影的视椎体都变成标准立方体,因此可以无视z轴的值。(这里的值并没有被丢掉,我们将其保存在zbuffer中,为了后续进行深度测试时使用)。
首先可以肯定的是,光栅化后,肯定不是像上图那样的显示了。因为前面我们说过一个像素中只会存在一个颜色,而上图明显不符合这个要求,例如我们看下标为(1, 2)的像素点,里面只有一部分是红色的。那么这个像素到底应该是没有颜色还是全部红色呢?
在图形学中,我们定义若一个像素的中心点在三角形的内部,那么这个像素就属于该三角形。例如例子中下标为(1, 2)的像素点,我们可以从图中明确的看出其中心点在三角形内部,那么这个像素就应该全部显示红色。
当然了,我们肯定不可能通过肉眼来观察是否在三角形内部,因此光栅化过程中很重要的一步便是:判断像素的中心点与三角形的内外关系。这里也就体现了使用三角形的好处,因为前面我们说了使用叉积的方法可以判断点和三角形的内外关系。那么我们就可以定义一个函数用来判断.
如下:
bool isInside(Triangle triangle,x,y)
形参triangle的类型是三角形类。包含了三角形的信息的集合(三个顶点的坐标x,y),形参x,y即采样点的位置信息。
函数体内用叉积来进行判断是否在体内。
假设我们点正好在三角形的边上,那么我们应该如何考虑,到底是算还是不算在三角形内部呢。至于这个问题,就全看使用者自己的定义了,我们可以定义算在也可以不算(像在OpenGL里还有更严格的定义方式),后续的操作只需要遵从自己的定义即可。
在本章中,我们认为这种情况不在三角形内。
Opengl认定,当点在top边或者left边上时,算在三角形内部。
OpenGL认为,当点在上左边上的时候,算是在三角形的内部。
知道了屏幕中任何一个点和三角形的关系后,我们只需要遍历屏幕中每个像素的中心点,带入isInside函数中,即可知道哪些像素属于在这个三角形内部的。其中遍历屏幕中每个像素的中心点的操作,我们称之为采样。
前面我们说了屏幕是由 width * height 个像素点组成的,那么即可得到下面代码:
for(int x = 0; x < width; x++){
for(int y = 0; y < height; y++){
pixel[x][y] = isInside(triangle, x + 0.5, y + 0.5);//前面提到像素中心点是像素坐标x,y的值+0.5
}
}

把上述的光栅化代码做一个简单的修改,变成下面的样子。
for(int x = 0; x < width; x++){
for(int y = 0; y < height; y++){
pixel1[x][y] = isInside(triangle, x + 0.25, y + 0.25);
pixel2[x][y] = isInside(triangle, x + 0.25, y + 0.75);
pixel3[x][y] = isInside(triangle, x + 0.75, y + 0.25);
pixel4[x][y] = isInside(triangle, x + 0.75, y + 0.75);
}
}
其实很简单,做的就不再是采样每个像素的中心点,而是讲一个像素分成了如下图的四块,然后采样每个像素这四块的中心点。
这就是MSAA抗锯齿的核心思想。
1.5包围盒(Bounding Box)
在上面的代码中,我们需要判断一个三角形就要采样屏幕中的所有像素中心点,若是采样整个网格的所有三角形,那计算量就会变得很巨大。性能消耗会很大。
因此我们可以采用Bounding box来缩小采样范围,进行加速。
例如下图:可能在三角形内的像素肯定是在蓝色区域的范围内,而这个蓝色区域我们称之为Bounding Box、也可称之为轴向包围盒(AABB),是一种加速结构。类似的加速结构还有KD-Tree。BVH等

因此,给定一个三角形,我们只需要求出三个顶点在x轴上的最大值最小值,在y轴上的最大值最小值,即可定义出一个Bounding Box。然后只需要在轴向包围盒(AABB)的范围内进行采样即可,大大减少了计算量。
for(int x = xmin; x <= xmax; x++)
{
for(int y = ymin; y <= ymax; y++)
{
pixel[x][y] = isInside(t, x + 0.5, y + 0.5);
}
}
有些特殊情况,导致三角形本身不大,但是bounding box 特别大,例如下图。
针对此情况,可以做特殊处理。例如每行去做一个Bounding Box,然后从左往后进行遍历。
至于怎么判断每一行的Bounding box的左右边界,以及怎么判断这个三角形属不属于这种情况,有大佬的想法如下:
- 1.从图中可以看出,只有在三角形瘦长并且倾斜的时候才会导致这样的情况发生,那么我们需要去判断一个三角形是否瘦长且倾斜?
其实不需要那么麻烦,只需要计算三角形的面积与其所占的bounding box的面积占比即可。因为需要特殊处理的情况,肯定是面积比比较小的情况(假设小于0.3需要特殊处理)。 - 2.轴向包围盒的面积直接长乘宽即可,对于三角形的面积,可以使用海伦公式,因为我们知道三角形三个顶点的位置,也就可以求出三条边的边长,通过海伦公式即可求出三角形的面积。设三条边的边长分别为a,b,c,则

其中p为半周长,P=(a+b+c)/2; - 3.接下来就是怎么定义每一行的xmin,和xmax,因为对于每一行的ymin和ymax我们都很清楚。
- 4.我们来看单独的一行,如下图:

想要确定该行的bounding box宽度,我们只需要求出图中标记的四个点的x值(y值已经可以确定),然后求出最大和最小的x即可。
从图中我们可以看出,这四个点分别在三角形的某两边上。
(若是像上图中的最下面一行的特殊情况,看着只有三个点,我们可以想象成最下面的点是两个点重合即可),那么我们就要确定这两条边是三角形的哪两条边。由于四个点的y值是确定的,那么肯定是一个y值大于ymin,ymax和y值小于ymin,ymax的点的连线。(不可能三角形三个顶点都大于或者小于ymin和ymax)。
确定了四个点所在的两条边之后,我们的问题就变成了求解直线上的一点,知道两个顶点的值,和直线中一点的y值,可以很轻松求出该点的x的值。
例如上图中标记的左下角点,其y值为ymin,舍弃所在边的两个顶点为(x1,y1)和(x2,y2),其中 x1<x2,y1<ymin<y2,那么该点的x值为:
其他点同理。
结果
通过上面的知识,我们可以找到屏幕中在三角形内部的像素,接着对这些像素进行着色,就可以得到下面的结果。
上图也就是我们单个三角形进行光栅化后的结果,也就是屏幕中真正显示的样子。
很显然,这个效果看着和原本的三角形差距很大,三角形的边缘处都是凹凸不平的,也就是所谓的锯齿。因此我们要通过抗锯齿,使其看起来更像三角形一些。
1.6直线的光栅化算法
1.6.1 DDA数值微分算法
DDA数值微分算法比较直观。
首先当任何一条直线知道任意两点时都可以用y=kx+b来表示,其中k为斜率。如果-1<k<1,那么k的主要行进方向就是x轴,即x轴的变化要比y轴快。反过来就是y轴变化率比x轴快。
如下图所示:
- 1.当-1<k<1时,从起点开始画起每次x = x+1, y = y+k, 并将y四舍五入,得到新的x,y就是像素点应该画的地方
- 2.当k<-1或k>1时,从起点开始画起每次y = y+1, x = x+1/k, 并将x四舍五入,得到新的x,y就是像素点应该画的地方
1.6.2 中点Bresenham(布雷森汉姆直线算法)算法
布雷森汉姆提出的直线生成算法的基本原理是,每次在最大位移方向上走一步,另一个方向上走还是不走取决于误差项的判断。
给出0<k<1时的情况,其他情况可以进行类推,除却终点和起点,每次画点只会考虑右边和右上点两种可能性。怎么确定呢?
用终点的横坐标的值带入上述的隐函数,如果得到的值>0,说明,该点(中点)在直线的上方,所以我们要取右边的点。反之我们取右上的点。
所有物体光栅化
前面我们讨论了对于一个三角形的光栅化,那么对于空间中所有的物体,也就是所有的mesh光栅化,即把这些所有的三角形遍历一下即可。通过一个个三角形的光栅化,我们就可以将视口变换后的整个空间绘制到屏幕上了。
那么有个问题了,我们在看向不同的物体的时候,他们之间可能存在前后重叠/遮挡的关系,例如背着书包的人,正面看去任何书包是重叠的。并且对于单个三维物体而言,不同的面之间也是存在重叠关系的,例如书包的背面和正面,换句话说,所有要绘制的三角形,可能存在着重叠的关系,对于这些重叠的三角形,应该把谁显示在像素上呢?
2. 深度
物体能够重叠,说明他们间存在着前后关系。对于空间中物体的前后位置,更专业的属于称之为深度,我们用depth来表示,范围为0.00-1.00.depth值越大,即深度越深,代表离摄像机越远。
2.1画家算法
油画家画东西时,先画远处的,后画近处的,并用近处的覆盖远处的。
对上面的操作,我们称之为画家算法。因为需要深度排序,因此对于n个三角形,快排时间复杂度nlogn。
但是有一类情况,无法使用画家算法。
之所以不行是因为画家算法是定义了每个物体的深度,认为对于每个三角形来说,深度是一样的,但实际上,深度关系可以相互叠搭,更加复杂。
所以我们要使用深度缓存depth buffer,也称zbuffer。
zbuffer算法,是将距离照相机最近的片元(以片元为单位)的深度保存起来。在绘制时,只绘制最近的深度。
zbuffer算法主要有两步:
- 1.zbuffer算法需要为每个像素点维持一个深度数组记为zbuffer,且数组初始化为无穷大(即与相机的距离为无穷大)。
- 2.随后遍历每个三角面上的每一个像素点,当该像素点的深度值z(距离相机的距离)小于zbuffer当中的值时,更新zbuffer的值,同时更新该像素点的值为该三角形面上该点的值的颜色。
其实本质上,zbuffer也是画家算法的思想,只不过是细粒度更小了,从三角形到了像素级。
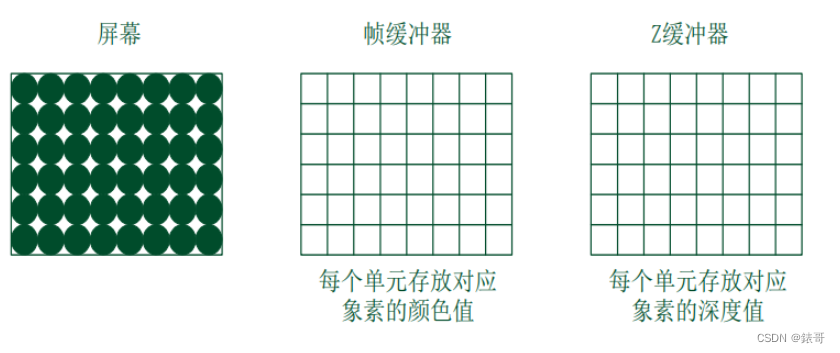
在深度缓存算法中,我们会有两个buffer,如下:
frame buffer:也叫帧缓冲器,对应intensity(x,y)——属性数组(帧缓冲器),存储图像空间每个可见像素的光强或颜色。
z-buffer(depth-buffer):用来存储每个像素所对应的深度值,只保存最小的那一个,默认值为正无穷(depth正无穷,即为深到无穷,离摄像机最远)。
zbuffer伪代码:
Z-Buffer算法(){
帧缓存全置为背景色
深度缓存全置为最小z值
for(每一个多边形){
扫描转换该多边形
for(该多边形所覆盖的每个象素(x,y)){
计算该多边形在该象素的深度值Z(x,y);
if(z(x,y)大于z缓存在(x,y)的值){
把z(x,y)存入z缓存中(x,y)处
把多边形在(x,y)处的颜色值存入帧缓存的(x,y)处
}
}
}
}
简单逻辑代码
float* frameBuffer = new float[width*height];//存储每个像素的最终颜色
float* zBuffer = new float[width*height];//存储每个像素的深度值
for (int x = 0; x < width; x++)
{
for (int y = 0; y < height; y++)
{
//设默认值为正无穷
zBuffer[x, y] = float.PositiveInfinity;
}
}
//遍历所有三角形
foreach (Triangle t in allTriangle)
{
//光栅化每个三角形
for (int x = xmin; x < xmax; x++)
{
for (int y = ymin; y < ymax; y++)
{
//如果该像素在该三角形里
if (isInside(t, x + 0.5, y + 0.5))
{
//比较该三角形在这个像素的深度和已经保存了的深度
if (t.z < zBuffer[x, y])
{
//如果新的深度值更小,则更新颜色和深度值
frameBuffer[x, y] = t.color;
zBuffer[x, y] = t.z;
}
else
;//反之不用任何操作
}
}
}
}
对于深度缓存算法,其时间复杂度只有O(N),因为他并不是一个排序操作,它仅仅求一个最小值。
图中每个格子代表一个像素,先后光栅化了一红一蓝两个三角形,根据不同的深度值得到的最终结果。
深度图
因为两个buffer的大小都是像素在屏幕上的宽和高的数量,因此这两个buffer我们都可以得到一幅图像,例如下图:
frame buffer对应的自然就是最终渲染出来的图像,而depth buffer对应的图像我们称之为深度图。
在深度图中越黑的代表越近,因为越近就是深度越小,即越接近于0,而在RGB颜色中,0即代表着黑色。反之越远,即深度越接近于1,即白色。这样就很容易看懂右边这幅深度图了。
其他一些问题
-
问题一,虽然我们深度值是浮点型,但是还是可能存在相等的情况,那么若碰见深度值相同的情况,该如何显示?
这里就需要我们特殊处理了。玩游戏中常见的闪烁效果可能就是这种情况所导致的。 -
问题二,对于带有透明度的物体,深度缓存的方法是无法处理的。
需要在透明测试过程中进行处理后,在进入深度测试进行处理。
Z-Fighting问题
z-fighting 就是深度冲突,当两个带渲染物体的三角形网格比较接近,几乎平行排列在一起时会发生深度冲突,其本质是深度缓冲没有足够的精度来决定哪个三角形在前面显示,于是两个三角形不断地切换前后顺序导致闪烁。
深度冲突目前并没有很好的解决方法,基本是根据业务情况选择相应的规避措施,规避的方法主要有:
-
1.使用更高精度的深度缓存,比如使用FORMAT_D32_FLOAT,大多数情况下我们使用的是24bits的浮点数才进行存储的,有效位数只有8位。所以可能会因为精度不够导致变成同一深度值。
-
2.选择合适的近平面和远平面的值,避免相差过大,同时近平面设置的最好远一点,因为靠近近平面时的精度比较大。
在MVP矩阵过后,要对深度值进行归一化,这个过程不是线性的,会将靠近远平面的大部分深度值集中映射到归一化区间中一个很小的区域里。当n=1,f=100时,在50到100的相机深度值被映射到了0.98到1.0的范围内,而0到50的相机深度值占据了0.0到0.98范围)。 -
3.距离摄像机过远的物体比较深度上相距较近。
-
4.加一个offset偏移量,对发生冲突的两个面如果前后关系确定的话,人为的加一个offset,使得远的更远,近的更近。
https://zhuanlan.zhihu.com/p/438812552#:~:text=Z-Fighti,%E5%90%8E%E9%A1%BA%E5%BA%8F%E5%AF%BC%E8%87%B4%E9%97%AA%E7%83%81%E3%80%82

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)