数据预处理系列:不平衡数据处理
不平衡数据是指一种情况,主要是在分类机器学习中,其中一个目标类代表了观察结果中的很大一部分。不平衡数据集是指类分布严重倾斜的数据集,例如少数类与多数类之间的比例为 1:100 或 1:1000。欺诈检测(绝大多数交易将属于“非欺诈”类别)疾病筛查(绝大多数将是健康的)订阅流失(绝大多数客户继续使用服务 - “无流失”类)广告投放(点击预测数据集没有很高的点击率)应该从知识领域获取更多来自少数类别的
文章目录
- 1.介绍
- 2.不平衡数据的度量
- 2.1 不平衡类别分布的分类准确度失败
- 2.2 不平衡数据集最常用的度量标准
- 2.3 选择指标
- 3.组织
- 3.1 导入库
- 3.2 导入数据
- 3.3 数据集特征
- 3.4 数据不平衡检查
在实施任何模型之前,准确率得分达到99.8%
- 4.数据预处理
- 4.1 删除重复值
- 4.2 在这种情况下我们为什么不应该删除异常值
- 4.2.1 检查异常值
- 4.2.2 四分位距(IQR)
- 4.2.3 结论 - 非常重要!
- 4.2 在这种情况下我们为什么不应该删除异常值
- 5.训练测试分割 - 你可能完全错误地分割了你的数据集
- 5.1 分层拆分
- 5.2 在分割数据之前或之后进行过采样/欠采样?
- 6.特征缩放
- 7.基线(无过采样)
- 7.1 交叉验证
- 7.2 分层K-fold CV(交叉验证)
- 7.3 过采样/欠采样和交叉验证
- 7.4 优化召回率
- 7.5 什么时候精确度比召回更重要?
- 7.6 使用 GridSearchCV 进行超参数调优
- 8.随机重采样不平衡数据集
- 8.1 随机过采样
- 8.1.1 不平衡学习管道
- 8.1.2 培训模式
- 8.1.3 GridSearchCV
- 8.1.4 混淆矩阵和分数
- 8.2 随机欠采样不平衡数据集
- 8.1 随机过采样
- 9.SMOTE(合成少数族裔过采样技术)
- 9.1 培训模式
- 9.2 网格搜索
- 9.3 混淆矩阵和分数
- 10.使用Tomek Links进行欠采样
- 11.将SMOTE和Tomek Links结合
- 11.1 培训模型
- 11.2 网格搜索
- 11.3 混淆矩阵和分数
- 12.模型中的类权重
- 12.1 培训模型
- 12.2 网格搜索
- 12.3 混淆矩阵和分数
- 13.性能比较
- 13.1 总结
- 14.其他指标
- 14.1 AUC-ROC曲线
- 14.2 精确率-召回率曲线(PR曲线)
- 15.我对其他笔记本的建议
1.介绍
不平衡数据是指一种情况,主要是在分类机器学习中,其中一个目标类代表了观察结果中的很大一部分。不平衡数据集是指类分布严重倾斜的数据集,例如少数类与多数类之间的比例为 1:100 或 1:1000。
第一类失衡出现在许多领域,包括:
- 欺诈检测(绝大多数交易将属于“非欺诈”类别)
- 疾病筛查(绝大多数将是健康的)
- 订阅流失(绝大多数客户继续使用服务 - “无流失”类)
- 广告投放(点击预测数据集没有很高的点击率)
在开始分类之前,有几种方法可以解决类不平衡问题,例如:
- 应该从知识领域获取更多来自少数类别的样本。
改变损失函数,使失败的少数类具有更高的成本。 - 对少数类进行过采样。
- 对大多数类进行欠采样。
- 以前方法的任意组合。
过采样方法在少数类中复制或创建新的合成示例,而过采样方法删除或合并多数类中的示例。过采样是最常用的方法(但不一定是最好的)。

2. 不均衡数据的评价指标
2. 1 不平衡类别分布的分类准确度失败
分类准确率是一个度量指标,它总结了分类模型的性能,即正确预测的数量除以预测的总数量。
准确率=正确预测数/总预测数
在不平衡分类问题中,达到 90% 的分类准确率,甚至 99% 的分类准确率,可能是微不足道的。考虑一个 1:100 类不平衡的不平衡数据集的情况。盲目猜测将为我们提供 99% 的准确率得分(通过押注多数类)。
经验法则是:在不平衡数据集中,准确性永远帮不上忙。

2.2 用于不平衡数据集的最常用指标
在处理不平衡数据集时,最常用的度量指标有:
- F1得分
- 精确率
- 召回率
- AUC得分(AUC ROC)
- 平均精确率得分(AP)
- G-Mean
在开发机器学习模型时,跟踪多个度量指标是一种良好的实践,因为每个指标都突出了模型性能的不同方面。
2.3 选择评价指标
-
你是否在预测概率?
- 你是否需要类别标签?
- 正类是否更重要?
- 使用精确率-召回率AUC
- 两个类别都重要吗?
- 使用ROC AUC
- 你是否需要概率?
- 使用Brier得分和Brier技能得分
- 正类是否更重要?
- 你是否需要类别标签?
-
你是否在预测类别标签?
- 正类是否更重要?
- 假阴性和假阳性同等重要吗?
- 使用F1度量
- 假阴性更重要吗?
使用F2度量 - 假阳性更重要吗?
- 使用F0.5度量
- 两个类别都重要吗?
- 对于大多数类别,你是否有80%-90%的示例?
- 使用准确率
- 对于大多数类别,你是否有超过80%-90%的示例?
- 使用G-Mean
- 对于大多数类别,你是否有80%-90%的示例?
- 假阴性和假阳性同等重要吗?
- 正类是否更重要?
Source: https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/

3. 初始化
3. 1导入工具包
import numpy as np
import pandas as pd
import seaborn as sns
import plotly.express as px
from matplotlib import pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from collections import Counter
3.2 导入数据
try:
raw_df = pd.read_csv('../input/creditcardfraud/creditcard.csv')
except:
raw_df = pd.read_csv('creditcard.csv')
3.3 数据集特征
背景
信用卡公司能够识别欺诈信用卡交易非常重要,这样客户就不会被收取他们没有购买的物品的费用。
内容
该数据集包含2013年9月欧洲持卡人使用信用卡进行的交易。
该数据集展示了在两天内发生的交易,其中有492起欺诈交易,总共有284,807起交易。该数据集非常不平衡,正类(欺诈)占所有交易的0.172%。
该数据集只包含数值型输入变量,这些变量是通过PCA转换得到的结果。不幸的是,由于保密问题,我们无法提供原始特征和更多关于数据的背景信息。特征V1、V2、…、V28是通过PCA获得的主要成分,唯一没有经过PCA转换的特征是’Time’和’Amount’。特征’Time’包含每个交易与数据集中第一笔交易之间经过的秒数。特征’Amount’是交易金额,该特征可以用于依赖于示例的成本敏感学习。特征’Class’是响应变量,如果是欺诈则取值为1,否则为0。
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
3.4 数据不均衡检测
labels=["Genuine","Fraud"]
fraud_or_not = raw_df["Class"].value_counts().tolist()
values = [fraud_or_not[0], fraud_or_not[1]]
fig = px.pie(values=raw_df['Class'].value_counts(), names=labels , width=700, height=400, color_discrete_sequence=["skyblue","black"]
,title="Fraud vs Genuine transactions")
fig.show()
plt.figure(figsize=(3,4))
ax = sns.countplot(x='Class',data=raw_df,palette="pastel")
for i in ax.containers:
ax.bar_label(i,)

print('Genuine:', round(raw_df['Class'].value_counts()[0]/len(raw_df) * 100,2), '% of the dataset')
print('Frauds:', round(raw_df['Class'].value_counts()[1]/len(raw_df) * 100,2), '% of the dataset')
Genuine: 99.83 % of the dataset
Frauds: 0.17 % of the dataset
3.5 在实施任何模型之前,准确率为99.8%
在不平衡的数据集中,不要使用准确率作为度量标准,因为它通常会很高并且具有误导性。在这个数据集中:
-
我们有99.8%的真实交易和仅有0.173%(492个)的欺诈交易;
-
这意味着盲目猜测(押注真实交易)将给我们99.8%的准确率。
4. 数据预处理
数据的描述称,除了’time’和’Amount’之外,所有特征都经过了PCA转换(降维技术)。
对于PCA,特征需要事先进行缩放,所以我们可以假设它们已经被缩放了(除了’time’和’Amount’)。
4.1 删除重复值
df = raw_df.copy()
df.drop_duplicates(inplace=True)
print("Duplicated values dropped succesfully")
print("*" * 100)
Duplicated values dropped succesfully
****************************************************************************************************
df = df.drop('Time', axis=1)
4.2 为什么在这种情况下我们不应该删除异常值
4.2.1 检查异常值
numeric_columns = (list(df.loc[:, 'V1':'Amount']))
# checking boxplots
def boxplots_custom(dataset, columns_list, rows, cols, suptitle):
fig, axs = plt.subplots(rows, cols, sharey=True, figsize=(16,25))
fig.suptitle(suptitle,y=1, size=25)
axs = axs.flatten()
for i, data in enumerate(columns_list):
sns.boxplot(data=dataset[data], orient='h', ax=axs[i])
axs[i].set_title(data + ', skewness is: '+str(round(dataset[data].skew(axis = 0, skipna = True),2)))
boxplots_custom(dataset=df, columns_list=numeric_columns, rows=10, cols=3, suptitle='Boxplots for each variable')
plt.tight_layout()

4.2.2 四分位距(IQR)
我们遇到了一些重要的异常值问题:
- 极大的异常值;
- 高度偏斜的数据;
- 大量的异常值。
Tukey(1977)的技术用于检测偏斜或非钟形数据中的异常值,因为它不做分布假设。然而,Tukey的方法可能不适用于小样本量。一般规则是,不在(Q1 - 1.5 IQR)和(Q3 + 1.5 IQR)范围内的任何值都是异常值,可以被删除。
四分位距(IQR)是最常用的异常值检测和删除程序之一。
步骤:
- 找到第一四分位数,Q1。
- 找到第三四分位数,Q3。
- 计算IQR。IQR = Q3-Q1。
- 以Q1-1.5 IQR为下限,以Q3+1.5 IQR为上限定义正常数据范围。
有关异常值检测方法,请参见此处:https://www.kaggle.com/code/marcinrutecki/outlier-detection-methods
def IQR_method (df,n,features):
"""
接受一个数据框,并返回一个索引列表,该列表对应于根据Tukey IQR方法包含超过n个异常值的观测。
"""
outlier_list = []
for column in features:
# 1st quartile (25%)
Q1 = np.percentile(df[column], 25)
# 3rd quartile (75%)
Q3 = np.percentile(df[column],75)
# Interquartile range (IQR)
IQR = Q3 - Q1
# outlier step
outlier_step = 1.5 * IQR
# Determining a list of indices of outliers
outlier_list_column = df[(df[column] < Q1 - outlier_step) | (df[column] > Q3 + outlier_step )].index
# appending the list of outliers
outlier_list.extend(outlier_list_column)
# selecting observations containing more than x outliers
outlier_list = Counter(outlier_list)
multiple_outliers = list( k for k, v in outlier_list.items() if v > n )
# Calculate the number of records below and above lower and above bound value respectively
out1 = df[df[column] < Q1 - outlier_step]
out2 = df[df[column] > Q3 + outlier_step]
print('Total number of deleted outliers is:', out1.shape[0]+out2.shape[0])
return multiple_outliers
# detecting outliers
Outliers_IQR = IQR_method(df,1,numeric_columns)
# dropping outliers
df_out = df.drop(Outliers_IQR, axis = 0).reset_index(drop=True)
Total number of deleted outliers is: 31685
4.2.3 结论 - 非常重要!
plt.figure(figsize=(3,4))
ax = sns.countplot(x='Class',data=df_out,palette="pastel")
for i in ax.containers:
ax.bar_label(i,)

我们在整个数据框中只保留了26个欺诈交易!
我们从数据框中删除了几乎所有的欺诈交易!
我们有几个选择,但为了这个研究,我们将回到删除异常值之前的阶段。
这里非常有趣的选择是创建一个只包含异常值的新数据框。您可以在这里检查这种方法的结果:
https://www.kaggle.com/code/marcinrutecki/credit-card-fraud-detection-tensorflow
5. 训练测试分割 - 您可能一直在错误地分割数据集
5.1 分层分割
分层分割意味着当您生成训练/验证数据集分割时,它将尝试保持每个分割中类别的相同比例。
这些数据集分割通常是根据目标变量随机生成的。然而,在这样做时,不同分割中目标变量的比例可能会有所不同,特别是在小数据集的情况下。
X = df.drop('Class', axis=1)
y = df['Class']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size = 0.3, random_state = 42)
5.2 在分割数据之前或之后过采样/欠采样?
经验法则是:不要破坏测试集。在尝试过采样/欠采样技术之前,始终先将数据分割为测试集和训练集!
在分割数据之前过采样可以使得相同的观测结果同时出现在测试集和训练集中。这可能导致模型简单地记忆特定数据点,从而导致过拟合和对测试数据的泛化能力差。数据泄漏可能会导致创建过于乐观甚至完全无效的预测模型。
6. 特征缩放
from sklearn.preprocessing import StandardScaler
# Creating function for scaling
def Standard_Scaler (df, col_names):
features = df[col_names]
scaler = StandardScaler().fit(features.values)
features = scaler.transform(features.values)
df[col_names] = features
return df
col_names = ['Amount']
X_train = Standard_Scaler (X_train, col_names)
X_test = Standard_Scaler (X_test, col_names)
7. 基准线(无过采样)
7.1 交叉验证
最佳模型不是在训练数据上给出准确预测的模型,而是在新数据上给出良好预测并避免过拟合和欠拟合的模型。
交叉验证是一种用于评估机器学习模型的重采样过程,用于有限数据样本。该过程有一个称为k的参数,指的是将给定数据样本分成的组数。因此,该过程通常被称为k折交叉验证。
交叉验证的目的是测试机器学习模型预测新数据的能力。

7.2 分层K折交叉验证
当数据集包含不平衡的类别时,我们使用分层抽样。因此,如果我们使用普通的技术进行交叉验证,可能会产生具有不同类别分布的子样本。一些不平衡的样本可能会产生异常高的分数,从而导致整体交叉验证得分较高,这是不可取的。因此,我们创建分层子样本,以保持各个折叠中的类别频率,以确保我们能够清楚地了解模型的性能。
7.3 过采样/欠采样和交叉验证
如果您想对数据进行欠采样或过采样,您不应该在交叉验证之前进行,因为这样会直接影响验证集,从而导致“数据泄漏”问题。
就像我们应该在交叉验证循环中进行特征选择一样,我们也应该在循环中进行过采样。
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
#我们将确保每次数据的划分都相同。我们可以通过创建一个KFold对象kf,并将cv=kf传递给cv=5来确保这一点。
kf = StratifiedKFold(n_splits=5, shuffle=False)
rf = RandomForestClassifier(n_estimators=100, random_state=13)
#cross_val_score(rf, X_train, y_train, cv=kf, scoring='recall')
7.4 优化召回率
召回率:模型在数据集中找到所有相关案例的能力。真正例数除以真正例数加上假负例数。
在大多数高风险检测案例(如癌症)中,召回率比精确度更重要作为评估指标。
在信用卡欺诈检测的情况下,我们希望尽量避免假负例。欺诈交易给我们带来了很大的损失,因此我们希望采取适当的措施来防止它们。假负例意味着将欺诈正例交易评估为真实交易,这是有害的。在这种用例中,假正例(将真实交易作为欺诈正例)不如防止欺诈重要。

score = cross_val_score(rf, X_train, y_train, cv=kf, scoring='recall')
print("Cross Validation Recall scores are: {}".format(score))
print("Average Cross Validation Recall score: {}".format(score.mean()))
Cross Validation Recall scores are: [0.8030303 0.74242424 0.76119403 0.87878788 0.65151515]
Average Cross Validation Recall score: 0.7673903211216644
7.5 何时精确度比召回率更重要?
当你希望在减少假阳性的同时增加假阴性时,精确度比召回率更重要。也就是说,得到一个假阳性的代价非常高,而得到一个假阴性的代价不那么高。
想象一下僵尸启示录。你会尽量接纳尽可能多的健康人进入安全区,但你真的不想错误地让一个僵尸通过。在这种情况下,真阳性是一个健康人,假阳性是一个僵尸。避免僵尸比接纳更多的健康人更重要。因此,你创建了一种方法,导致一些健康人错误地无法进入安全区,但这是不让僵尸进入的代价。
7.6 使用GridSearchCV进行超参数调优
超参数调优是在构建机器学习模型时调优元组中存在的参数的过程。这些参数由我们定义。机器学习算法从不学习这些参数。可以通过不同的步骤对这些参数进行调优。
GridSearchCV是一种从给定的参数网格中找到最佳超参数值的技术。它本质上是一种交叉验证技术。必须输入模型以及参数。在提取最佳参数值之后,进行预测。
GridSearchCV识别的“最佳”参数在技术上是在你的参数网格中包含的参数的情况下可能产生的最佳参数,但只限于这些参数。
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators': [50, 100, 200],
'max_depth': [4, 6, 10, 12],
'random_state': [13]
}
grid_rf = GridSearchCV(rf, param_grid=params, cv=kf,
scoring='recall').fit(X_train, y_train)
print('Best parameters:', grid_rf.best_params_)
print('Best score:', grid_rf.best_score_)
Best parameters: {'max_depth': 12, 'n_estimators': 100, 'random_state': 13}
Best score: 0.7734509271822705
我们在过采样之前的一个模型上的召回率约为77%。让我们检查一下测试集的得分。
y_pred = grid_rf.predict(X_test)
from sklearn.metrics import confusion_matrix, recall_score, precision_score, f1_score, accuracy_score
cm = confusion_matrix(y_test, y_pred)
rf_Recall = recall_score(y_test, y_pred)
rf_Precision = precision_score(y_test, y_pred)
rf_f1 = f1_score(y_test, y_pred)
rf_accuracy = accuracy_score(y_test, y_pred)
print(cm)
[[84972 4]
[ 33 109]]
ndf = [(rf_Recall, rf_Precision, rf_f1, rf_accuracy)]
rf_score = pd.DataFrame(data = ndf, columns=['Recall','Precision','F1 Score', 'Accuracy'])
rf_score.insert(0, 'Random Forest with', 'No Under/Oversampling')
rf_score
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 0 | No Under/Oversampling | 0.767606 | 0.964602 | 0.854902 | 0.999565 |
测试集的结果召回率为77%。我们将努力超过这个分数。
8. 随机重采样不平衡数据集
重采样是指创建训练数据集的新转换版本,其中所选示例具有不同的类分布。
对于不平衡分类问题,有两种主要的随机重采样方法,它们是过采样和欠采样。
- 随机过采样:随机复制少数类别的示例。
- 随机欠采样:随机删除多数类别的示例。
它们被称为“朴素重采样”方法,因为它们对数据不做任何假设,也不使用任何启发式方法。这使得它们易于实现和快速执行,这对于非常大和复杂的数据集来说是可取的。
重要提示
类分布的改变应仅应用于训练数据集。目的是影响模型的拟合。重采样不应用于用于评估模型性能的测试或保留数据集。
8.1 随机过采样
随机过采样可能会增加过拟合的可能性,因为它会复制少数类别示例的精确副本。假设在进行拆分之前,每个少数类别的数据点都被复制了6次。如果我们进行3折交叉验证,每个折叠平均上会有每个数据点的2个副本!这样,分类器可能会构建看似准确但实际上覆盖了一个复制示例的规则。
from imblearn.over_sampling import RandomOverSampler
# define oversampling strategy
ros = RandomOverSampler(random_state=42)
# fit and apply the transform
X_over, y_over = ros.fit_resample(X_train, y_train)
print('Genuine:', y_over.value_counts()[0], '/', round(y_over.value_counts()[0]/len(y_over) * 100,2), '% of the dataset')
print('Frauds:', y_over.value_counts()[1], '/',round(y_over.value_counts()[1]/len(y_over) * 100,2), '% of the dataset')
Genuine: 198277 / 50.0 % of the dataset
Frauds: 198277 / 50.0 % of the dataset
8.1.1 不平衡学习流程
流程的目的是将几个步骤组合在一起,可以在设置不同参数的同时进行交叉验证。
在交叉验证过程中,我们应该将数据集划分为训练集和验证集。然后,在每个数据集上,我们应该:
- 对少数类进行过采样。
- 在训练集上训练分类器。
- 在剩余的数据集上验证分类器。
流程是以一种智能的方式完成这些操作的好方法。
imblearn包包含许多不同的过采样和欠采样的采样器。这些采样器不能放置在标准的sklearn流程中。
为了能够在这些采样器中使用流程,imblearn包还实现了一个扩展流程,其中包含一些额外的函数来进行转换和采样。
8.1.2 训练模型
from imblearn.pipeline import Pipeline, make_pipeline
random_overs_pipeline = make_pipeline(RandomOverSampler(random_state=42),
RandomForestClassifier(n_estimators=100, random_state=13))
#cross_val_score(random_overs_pipeline, X_train, y_train, scoring='recall', cv=kf)
score2 = cross_val_score(random_overs_pipeline, X_train, y_train, scoring='recall', cv=kf)
print("Cross Validation Recall Scores are: {}".format(score2))
print("Average Cross Validation Recall score: {}".format(score2.mean()))
Cross Validation Recall Scores are: [0.83333333 0.72727273 0.74626866 0.86363636 0.65151515]
Average Cross Validation Recall score: 0.7644052464947987
8.1.3 GridSearchCV
new_params = {'randomforestclassifier__' + key: params[key] for key in params}
grid_over_rf = GridSearchCV(random_overs_pipeline, param_grid=new_params, cv=kf, scoring='recall',
return_train_score=True)
grid_over_rf.fit(X_train, y_train)
GridSearchCV(cv=StratifiedKFold(n_splits=5, random_state=None, shuffle=False),
estimator=Pipeline(steps=[('randomoversampler',
RandomOverSampler(random_state=42)),
('randomforestclassifier',
RandomForestClassifier(random_state=13))]),
param_grid={'randomforestclassifier__max_depth': [4, 6, 10, 12],
'randomforestclassifier__n_estimators': [50, 100, 200],
'randomforestclassifier__random_state': [13]},
return_train_score=True, scoring='recall')
print('Best parameters:', grid_over_rf.best_params_)
print('Best score:', grid_over_rf.best_score_)
Best parameters: {'randomforestclassifier__max_depth': 4, 'randomforestclassifier__n_estimators': 50, 'randomforestclassifier__random_state': 13}
Best score: 0.8701040253279059
8.1.4 混淆矩阵和评分
y_pred = grid_over_rf.best_estimator_.named_steps['randomforestclassifier'].predict(X_test)
cm = confusion_matrix(y_test, y_pred)
over_rf_Recall = recall_score(y_test, y_pred)
over_rf_Precision = precision_score(y_test, y_pred)
over_rf_f1 = f1_score(y_test, y_pred)
over_rf_accuracy = accuracy_score(y_test, y_pred)
print(cm)
[[84593 383]
[ 23 119]]
ndf = [(over_rf_Recall, over_rf_Precision, over_rf_f1, over_rf_accuracy)]
over_rf_score = pd.DataFrame(data = ndf, columns=['Recall','Precision','F1 Score', 'Accuracy'])
over_rf_score.insert(0, 'Random Forest with', 'Random Oversampling')
over_rf_score
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 0 | Random Oversampling | 0.838028 | 0.237052 | 0.369565 | 0.99523 |
8.2 随机欠采样不平衡数据集
随机欠采样是指从训练数据集中随机选择来自多数类的示例进行删除。尽管在少数类中有足够数量的示例,但这种方法可能更适用于存在类别不平衡的数据集,可以拟合出一个有用的模型。
from imblearn.under_sampling import RandomUnderSampler
# define oversampling strategy
rus = RandomUnderSampler(random_state=42)
# fit and apply the transform
X_under, y_under = rus.fit_resample(X_train, y_train)
print('Genuine:', y_under.value_counts()[0], '/', round(y_under.value_counts()[0]/len(y_under) * 100,2), '% of the dataset')
print('Frauds:', y_under.value_counts()[1], '/',round(y_under.value_counts()[1]/len(y_under) * 100,2), '% of the dataset')
Genuine: 331 / 50.0 % of the dataset
Frauds: 331 / 50.0 % of the dataset
在我们进行欠采样后的数据集中,只有662条记录,所以利用这种技术可能不是最好的主意。
9. SMOTE(合成少数类过采样技术)
SMOTE(合成少数类过采样技术)为少数类合成元素。SMOTE通过选择在特征空间中接近的示例,在特征空间中的示例之间画一条线,并在该线上的某一点上绘制一个新样本。
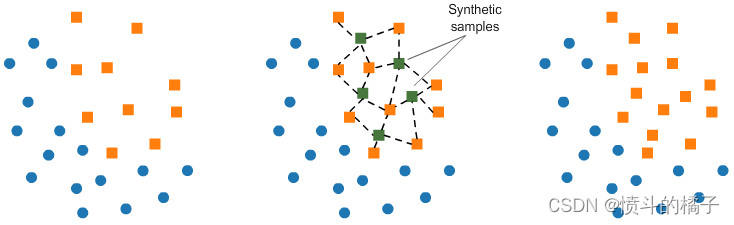
9.1 训练模型
from imblearn.over_sampling import SMOTE
smote_pipeline = make_pipeline(SMOTE(random_state=42),
RandomForestClassifier(n_estimators=100, random_state=13))
#cross_val_score(smote_pipeline, X_train, y_train, scoring='recall', cv=kf)
score3 = cross_val_score(smote_pipeline, X_train, y_train, scoring='recall', cv=kf)
print("Cross Validation Recall Scores are: {}".format(score3))
print("Average Cross Validation Recall score: {}".format(score3.mean()))
Cross Validation Recall Scores are: [0.86363636 0.83333333 0.76119403 0.87878788 0.72727273]
Average Cross Validation Recall score: 0.8128448665762098
9.2 GridSearchCV
new_params = {'randomforestclassifier__' + key: params[key] for key in params}
smote_rf = GridSearchCV(smote_pipeline, param_grid=new_params, cv=kf, scoring='recall',
return_train_score=True)
smote_rf.fit(X_train, y_train)
GridSearchCV(cv=StratifiedKFold(n_splits=5, random_state=None, shuffle=False),
estimator=Pipeline(steps=[('smote', SMOTE(random_state=42)),
('randomforestclassifier',
RandomForestClassifier(random_state=13))]),
param_grid={'randomforestclassifier__max_depth': [4, 6, 10, 12],
'randomforestclassifier__n_estimators': [50, 100, 200],
'randomforestclassifier__random_state': [13]},
return_train_score=True, scoring='recall')
print('Best parameters:', smote_rf.best_params_)
print('Best score:', smote_rf.best_score_)
Best parameters: {'randomforestclassifier__max_depth': 6, 'randomforestclassifier__n_estimators': 50, 'randomforestclassifier__random_state': 13}
Best score: 0.873134328358209
9.3 混淆矩阵和评分
y_pred = smote_rf.best_estimator_.named_steps['randomforestclassifier'].predict(X_test)
cm = confusion_matrix(y_test, y_pred)
smote_rf_Recall = recall_score(y_test, y_pred)
smote_rf_Precision = precision_score(y_test, y_pred)
smote_rf_f1 = f1_score(y_test, y_pred)
smote_rf_accuracy = accuracy_score(y_test, y_pred)
print(cm)
[[84621 355]
[ 21 121]]
ndf = [(smote_rf_Recall, smote_rf_Precision, smote_rf_f1, smote_rf_accuracy)]
smote_rf_score = pd.DataFrame(data = ndf, columns=['Recall','Precision','F1 Score', 'Accuracy'])
smote_rf_score.insert(0, 'Random Forest with', 'SMOTE Oversampling')
smote_rf_score
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 0 | SMOTE Oversampling | 0.852113 | 0.254202 | 0.391586 | 0.995583 |
10. 使用Tomek Links进行欠采样
Tomek Links是一种欠采样技术,由Ivan Tomek于1976年开发。它是从Condensed Nearest Neighbors (CNN)中修改而来的一种方法。它可以用来找到与少数类数据具有最低欧氏距离的多数类数据的所需样本,然后将其移除。

from imblearn.under_sampling import TomekLinks
# define the undersampling method
#tomekU = TomekLinks(sampling_strategy='auto', n_jobs=-1)
tomekU = TomekLinks()
# fit and apply the transform
X_underT, y_underT = tomekU.fit_resample(X_train, y_train)
print('Genuine:', y_underT.value_counts()[0], '/', round(y_underT.value_counts()[0]/len(y_underT) * 100,2), '% of the dataset')
print('Frauds:', y_underT.value_counts()[1], '/',round(y_underT.value_counts()[1]/len(y_underT) * 100,2), '% of the dataset')
Genuine: 198259 / 99.83 % of the dataset
Frauds: 331 / 0.17 % of the dataset
11. 结合SMOTE和Tomek Links
通过对少数类(异常)进行过采样和对多数类(正常)进行欠采样的组合,可以比仅对多数类进行欠采样的方法获得更好的分类器性能。这种方法最早由Batista等人(2003年)提出。
SMOTE-Tomek Links的过程如下。
- 开始SMOTE:从少数类中选择随机数据。
- 计算随机数据与其k个最近邻之间的距离。
- 将差值乘以0到1之间的随机数,然后将结果添加到少数类作为合成样本。
- 重复步骤2-3,直到满足少数类的所需比例(结束SMOTE)。
- 开始Tomek Links:从多数类中选择随机数据。
- 如果随机数据的最近邻是来自少数类的数据(即创建Tomek Link),则移除Tomek Link。
11.1 训练模型
from imblearn.combine import SMOTETomek
SMOTETomek_pipeline = make_pipeline(SMOTETomek(tomek=TomekLinks(sampling_strategy='majority')),
RandomForestClassifier(n_estimators=100, random_state=13))
#cross_val_score(smote_pipeline, X_train, y_train, scoring='recall', cv=kf)
score4 = cross_val_score(SMOTETomek_pipeline, X_train, y_train, scoring=‘recall’, cv=kf)
print(“Cross Validation Recall Scores are: {}”.format(score4))
print(“Average Cross Validation Recall score: {}”.format(score4.mean()))
11.2 GridSearchCV
GridSearchCV与SMOTE-Tomek和k-fold交叉验证结合在计算上非常耗时。它需要超过12个小时,这对于Kaggle来说是不可能的。这就是为什么我在本地的Yupyter Notebook上进行计算,并使用最佳的GridSearchCV参数来拟合模型。
你可以在下面找到GridSearchCV的公式。
SMOTETomek_rf = SMOTETomek_pipeline
SMOTETomek_rf.fit(X_train, y_train)
Pipeline(steps=[('smotetomek',
SMOTETomek(tomek=TomekLinks(sampling_strategy='majority'))),
('randomforestclassifier',
RandomForestClassifier(random_state=13))])
new_params = {‘randomforestclassifier__’ + key: params[key] for key in params}
SMOTETomek_rf = GridSearchCV(SMOTETomek_pipeline, param_grid=new_params, cv=kf, scoring=‘recall’,
return_train_score=True)
SMOTETomek_rf.fit(X_train, y_train)
11.3 混淆矩阵和评分
y_pred = SMOTETomek_rf.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
SMOTETomek_rf_Recall = recall_score(y_test, y_pred)
SMOTETomek_rf_Precision = precision_score(y_test, y_pred)
SMOTETomek_rf_f1 = f1_score(y_test, y_pred)
SMOTETomek_rf_accuracy = accuracy_score(y_test, y_pred)
print(cm)
[[84967 9]
[ 34 108]]
ndf = [(SMOTETomek_rf_Recall, SMOTETomek_rf_Precision, SMOTETomek_rf_f1, SMOTETomek_rf_accuracy)]
SMOTETomek_rf_score = pd.DataFrame(data = ndf, columns=['Recall','Precision','F1 Score', 'Accuracy'])
SMOTETomek_rf_score.insert(0, 'Random Forest with', 'SMOTE + Tomek')
SMOTETomek_rf_score
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 0 | SMOTE + Tomek | 0.760563 | 0.923077 | 0.833977 | 0.999495 |
12. 模型中的类别权重
大多数机器学习模型都提供了一个名为class_weights的参数。例如,在使用随机森林分类器时,我们可以使用一个字典来指定少数类别的较高权重。
如果没有设置权重,模型会将每个点视为同等重要。权重会缩放损失函数。当模型对每个点进行训练时,错误会乘以该点的权重。估计器将尝试在权重较大的类别上最小化错误,因为它们对错误的影响更大,发送更强的信号。
12.1 训练模型
# If you choose class_weight = "balanced",
# the classes will be weighted inversely proportional to how frequently they appear in the data.
rfb = RandomForestClassifier(n_estimators=100, random_state=13, class_weight="balanced")
score5 = cross_val_score(rfb, X_train, y_train, cv=kf, scoring='recall')
print("Cross Validation Recall scores are: {}".format(score5))
print("Average Cross Validation Recall score: {}".format(score5.mean()))
Cross Validation Recall scores are: [0.77272727 0.74242424 0.74626866 0.84848485 0.63636364]
Average Cross Validation Recall score: 0.7492537313432835
12.2 GridSearchCV
grid_rfb = GridSearchCV(rfb, param_grid=params, cv=kf,
scoring='recall').fit(X_train, y_train)
12.3 混淆矩阵和评分
y_pred = grid_rfb.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
grid_rfb_Recall = recall_score(y_test, y_pred)
grid_rfb_Precision = precision_score(y_test, y_pred)
grid_rfb_f1 = f1_score(y_test, y_pred)
grid_rfb_accuracy = accuracy_score(y_test, y_pred)
print(cm)
[[84721 255]
[ 25 117]]
ndf = [(grid_rfb_Recall, grid_rfb_Precision, grid_rfb_f1, grid_rfb_accuracy)]
grid_rfb_score = pd.DataFrame(data = ndf, columns=['Recall','Precision','F1 Score', 'Accuracy'])
grid_rfb_score.insert(0, 'Random Forest with', 'Class weights')
grid_rfb_score
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 0 | Class weights | 0.823944 | 0.314516 | 0.455253 | 0.99671 |
13. 表现对比
predictions = pd.concat([rf_score, over_rf_score, smote_rf_score, SMOTETomek_rf_score, grid_rfb_score], ignore_index=True, sort=False)
predictions.sort_values(by=['Recall'], ascending=False)
| Random Forest with | Recall | Precision | F1 Score | Accuracy | |
|---|---|---|---|---|---|
| 2 | SMOTE Oversampling | 0.852113 | 0.254202 | 0.391586 | 0.995583 |
| 1 | Random Oversampling | 0.838028 | 0.237052 | 0.369565 | 0.995230 |
| 4 | Class weights | 0.823944 | 0.314516 | 0.455253 | 0.996710 |
| 0 | No Under/Oversampling | 0.767606 | 0.964602 | 0.854902 | 0.999565 |
| 3 | SMOTE + Tomek | 0.760563 | 0.923077 | 0.833977 | 0.999495 |
13.1 总结
- SMOTE过采样实现了最佳的召回率得分,但代价很高:精确度为0.25,F1得分为0.39。
- 没有欠采样/过采样的参考模型获得了0.77%的召回率得分。
- 最先进的模型“SMOTE和Tomek”在召回率得分上并不是最好的。
- 哪个模型是最好的?这取决于业务决策。
我们能取得更好的结果吗?
可能可以 - 在K折交叉验证和调整超参数方面还有很多工作要做。
14. 其他指标
14.1 AUC-ROC 曲线
AUC(曲线下面积)ROC(接收者操作特征)曲线。
ROC 是一个概率曲线,AUC 代表可分离性的程度或度量。它告诉我们模型能够多大程度地区分不同的类别。AUC 越高,模型在将 0 类预测为 0,1 类预测为 1 方面就越好。
ROC 曲线是以 TPR(真正例率)为纵轴,FPR(假正例率)为横轴绘制的。
一个优秀的模型的 AUC 接近于 1,这意味着它具有良好的可分离性度量。一个糟糕的模型的 AUC 接近于 0,这意味着它具有最差的可分离性度量。
- 当 AUC 为 0.7 时,意味着模型能够有 70% 的机会区分正类和负类。
- 当 AUC 约为 0.5 时,模型没有区分正类和负类的能力。
- 当 AUC 约为 0 时,模型将负类预测为正类,反之亦然。
from sklearn.metrics import roc_auc_score
ROCAUCscore = roc_auc_score(y_test, y_pred)
print(f"AUC-ROC Curve for Random Forest with Class weights: {ROCAUCscore:.4f}")
AUC-ROC Curve for Random Forest with Class weights: 0.9105
y_proba = grid_rfb.predict_proba(X_test)
from sklearn.metrics import roc_curve
from sklearn.metrics import RocCurveDisplay
def plot_auc_roc_curve(y_test, y_pred):
fpr, tpr, _ = roc_curve(y_test, y_pred)
roc_display = RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
roc_display.figure_.set_size_inches(5,5)
plt.plot([0, 1], [0, 1], color = 'g')
# Plots the ROC curve using the sklearn methods - Good plot
plot_auc_roc_curve(y_test, y_proba[:, 1])
# Plots the ROC curve using the sklearn methods - Bad plot
#plot_sklearn_roc_curve(y_test, y_pred)

14.2 精确率-召回率曲线(PR曲线)
精确率-召回率曲线显示了不同阈值下精确率和召回率之间的权衡。
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import PrecisionRecallDisplay
display = PrecisionRecallDisplay.from_estimator(
grid_rfb, X_test, y_test, name="Average precision")
_ = display.ax_.set_title("Random Forest with Class weights")

我们可以清楚地看到,在为了获得更好的召回率得分而牺牲大量精确率的点!
平均精确率(AP)将每个阈值下达到的精确率的加权平均值作为这种图的总结,并考虑到与上一个阈值相比召回率的增加。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)