【论文复现】YOLOv7论文讲解
YOLO v7论文(YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors)被收录于计算机视觉顶会CVPR2023,这也是时隔 6 年,YOLOv 系列再登顶会 CVPR!我们知道CVPR是计算机视觉方面的三大顶级会议之一,上一次被收录还是YOLO v2,这也可以看到YOL

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


论文讲解
YOLO v7论文(YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors)被收录于计算机视觉顶会CVPR2023,这也是时隔 6 年,YOLOv 系列再登顶会 CVPR!我们知道CVPR是计算机视觉方面的三大顶级会议之一,上一次被收录还是YOLO v2,这也可以看到YOLO v7很强大,也被很多人所认可。
本文所涉及的所有资源的获取方式:这里
背景介绍
目标检测(Object Detection):解决“在哪里?是什么?”的问题。找出图像中所有感兴趣的目标(物体),确定它们的类别和位置。
当前目标检测算法,共同目标更快、更好。围绕此目标,有Two stage和One stage方法。One satge的代表YOLO(You Only Look Once)系列算法。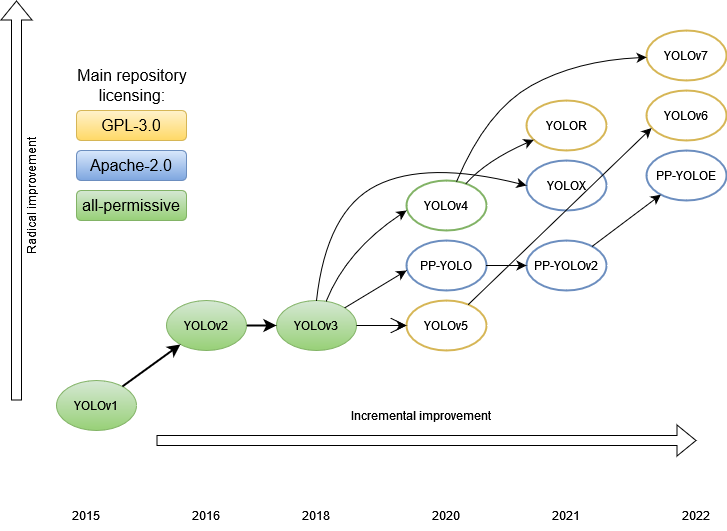
如图上图,自2015年YOLO v1发布以来,YOLO系列经历了多次更新和改进,产生众多衍生版本。YOLO系列算法,自2015年v1版本发布以来,经历了多次更新和改进,除去17年外,几乎每一年都会迭代出1到3个版本。其中v1~v3是YOLO创始人的亲笔之作。v4和v7是被YOLO官方认可的传承者。其他v5是一家美国公司维护开发的,PP出自百度,v6出自美团。也可见,YOLO v7,不是一朝一夕完成的,它是有前人的铺垫的。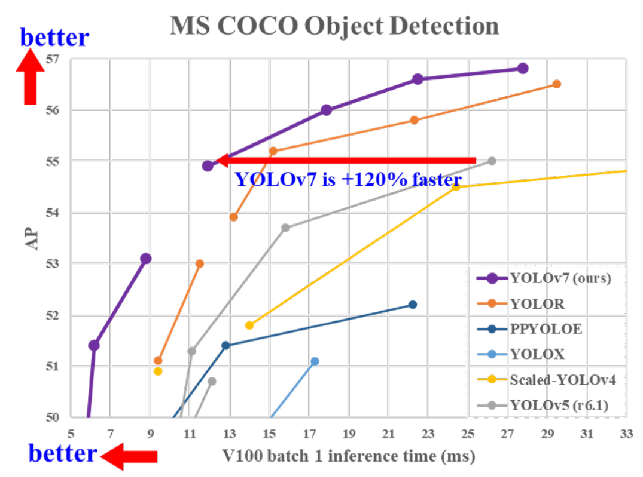
由论文中图示,在5 FPS 到 160 FPS 范围内,YOLOv7 在 speed 和 accuracy 上都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的实时目标检测器中,YOLOv7 有最高的 56.8% AP的 accuracy。
论文方法
论文聚焦如何在目标检测中取得更快的速度、更高的精度。
它为什么具备如此好的效果,论文分两个方面给出了答案。
第一个方面是YOLO v7的网络架构,它共有2点改进,第一点,是整体架构设计使用创新多分支堆叠模块和过渡模块提取特征。第二点,特殊的SPPCSPC模块,扩大感受野。
第二个方面是训练策略也就是题目中出现的bag-of-freebies,免费技巧包,这是YOLO v7最主要的改进点,也是最为精彩的部分。它共有两点,第一点,模块重参化,在不提高推理成本的情况下提高检测精度。第二点,动态标签分配,这可以加快模型的训练效率,增加正样本的数量。
网络结构
- 整体架构设计,使用创新多分支堆叠模块和过渡模块提取特征。
- 特殊的SPPCSPC,使用具有CSP结构的SPP扩大感受野。
训练策略
- (bag-of-freebies) 模块重参化,不提高推理成本的情况下提高检测精度。
- 动态标签分配,加快模型的训练效率,增加正样本的数量。
网络结构讲解
网络结构如下图所示: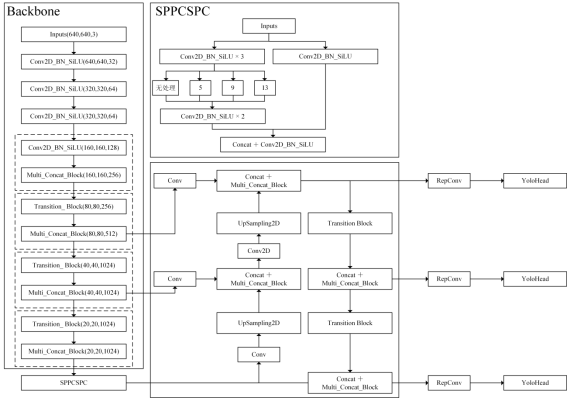
先看YOLO v7的网络结构,它是如何构建的,从整体框架来看,YOLO v7和以前的YOLO系列算法并没有太大的区别,依旧可以被分为3个部分,分别是主干特征提取网络,加强特征提取网络,以及YOLO head。
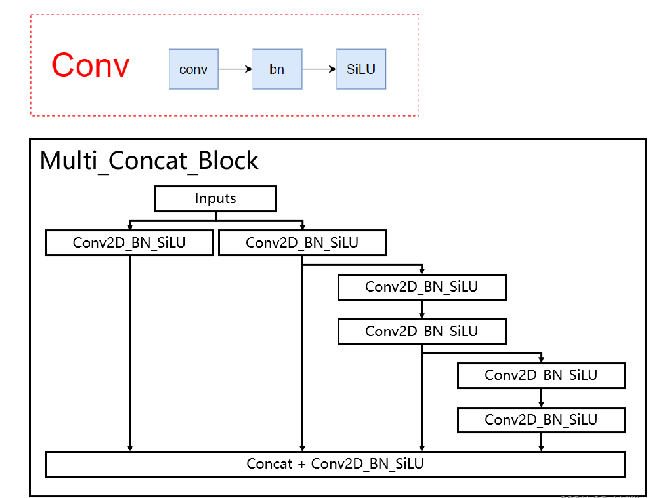
多分支堆叠模块
- 堆叠了更密集的残差结构,更好提取特征。
- 共四个特征层在堆叠后会再次 进行一个卷积标准化激活函数来特征整合。
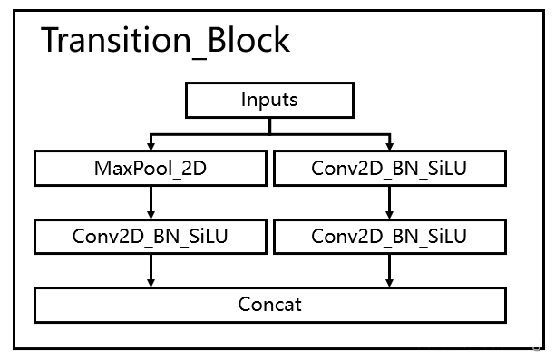
过渡模块
- 将两种常用下采样模块进行堆叠。
- 左分支是一个步长为2×2的最大池化和一个1×1卷积。
- 右分支是一个1×1卷积+一个卷积核大小为3×3、步长为2×2的卷积。
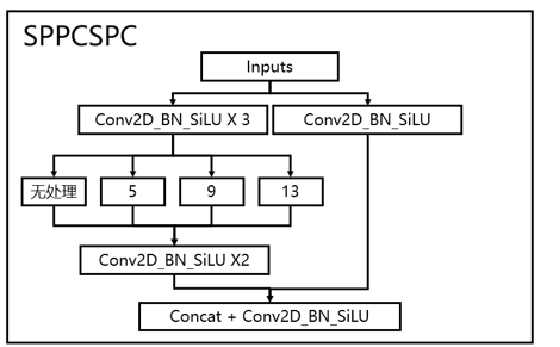
SPPCSPC模块
- SPPCSPC进行特征提取,该结构可以提高的感受野。
- 左分支,先3次卷积,使用不同池化核来最大池化,目的是扩大感受野,再来2次卷积。
- 右分支,直接卷积标准化激活函数
训练策略讲解
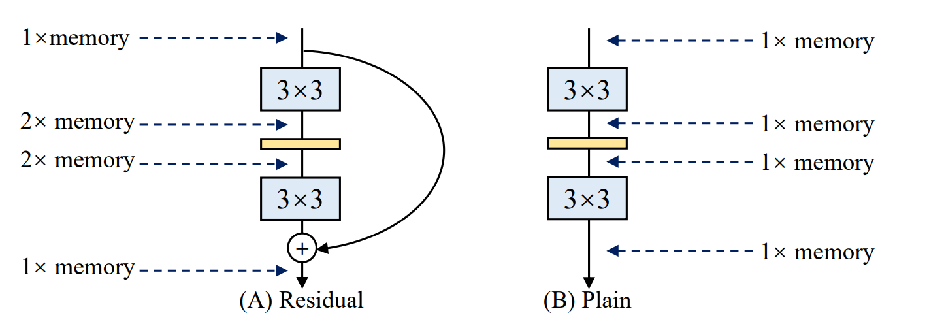
如下图ResNet,它也是有分支的,还有刚才介绍的YOLO v7它就是使用非常多的分支结构,再堆叠。
根据现有的经验来看,利用分支,是可以有效增加模型表征学习能力,来提升精度的。
但是做分支的时候,存在一个问题,多分支结构能显著提高模型性能,但是又会最终导致模型在推理时速度变慢且还非常耗内存,这非常不利于实际场景的应用。
速度变慢好理解的,因为结构复杂运算多了,就慢了。
这时就出现模块重参数化解决这个问题。
就是将训练和推理分开,训练是一件事情,推理又是一件事情,训练的网络结构和测试的网络结构不一样,就常识来说,训练和推理它网络结构得相同。要不然网络结构怎样去走呢。
模块重参数化
下图B单路卷积就一条路,走自己的路谁都不用管,就一倍显存。下图A多分支结构,将导致模型推理时速度变慢且还非常耗内存。
-
在训练过程中将一个整体模块分割为多个相同或不同的模块分支。
-
在推理过程中将多个分支集成到完全等价的模块(RepConv)。
-
减少参数数量,加快推理速度,更加省内存。
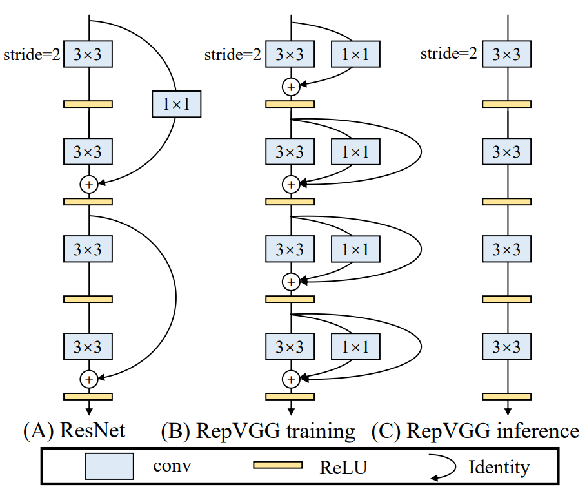
多分支合并为一个3×3卷积 -
卷积和BN的合并(数学方式)
-
全部转成3×3的卷积。
-
根据卷积可加性,多个卷积核再合并。
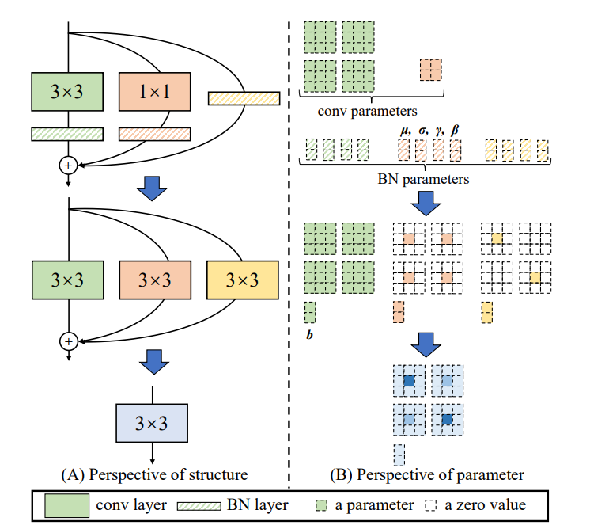
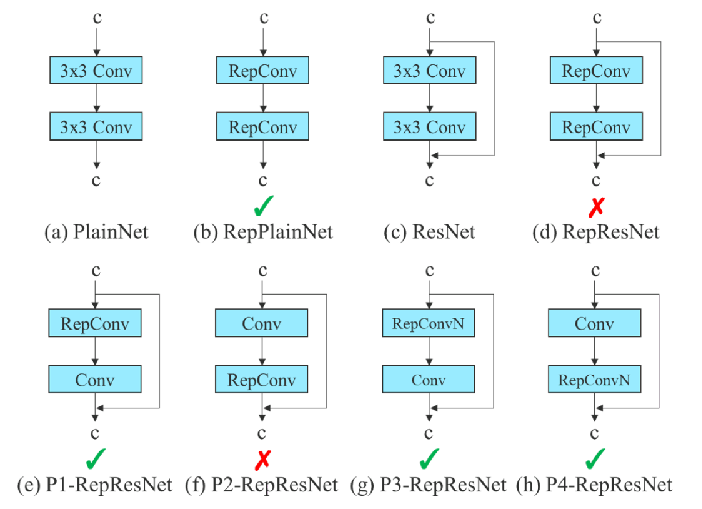
模块重参数化的问题
RepConv中的 identity 连接破坏了ResNet中的残差和DenseNet中的拼接。
使用无 identity 连接的 RepConv (RepConvN)来设计规划的重参数卷积的架构
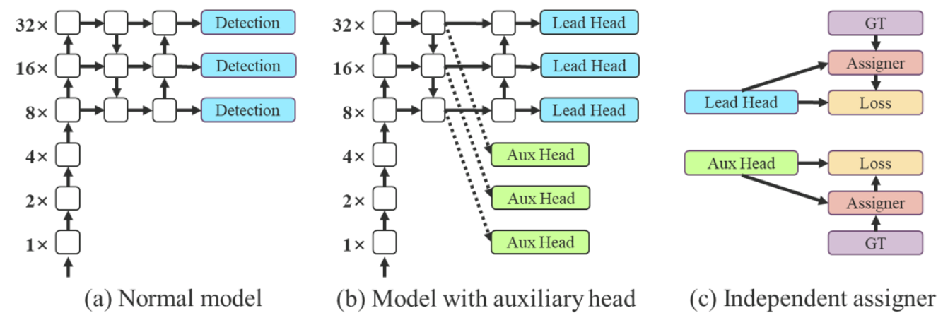
动态标签分配
深度监督是一种常用于训练深度网络的技术,是指在模型训练过程中,除了最终的检测头外,再额外增加一些辅助检测头,辅助检测头也会参与损失函数的计算,并且会反向传播,协助前面的层更新参数,帮助深度神经网络更好地训练和泛化。
为了区分辅助头和原来的头,给他们分别命名为lead head和AUX head,这种使用辅助头,深度监督训练模型的方式在其他论文中也都已经使用过。
标签分配指的是将输出图片的标注框,也叫做真实框,和最终预测的预测值给对应起来,便于进一步求损失值。
常用的方法辅助头和引导头,各自的预测结果和GT执行标签分配。
作者认为这方式都不好,所以又提出了两种方式,改进深度学习中的标签分配问题。这两种方法都是通过引入额外的辅助头来指导标签分配,从而提高模型的性能。
- 深度监督是一种常用于训练深度网络的技术,其主要概念是在网络的中间层增加额外的辅助头,帮助深度神经网络更好地训练和泛化。
- 常用的方法辅助头和引导头,各自的预测结果和GT执行标签分配。
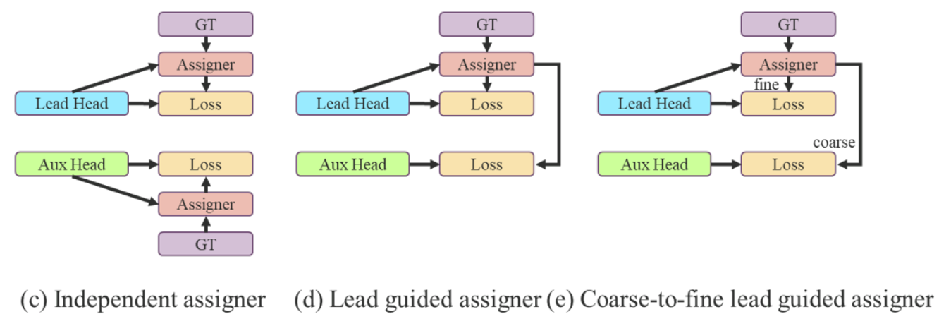
- Lead head guided 标签分配器,根据 the lead head 的软标签将作为辅助头和引导头的目标训练模型。
- Coarse-to-fine Lead head 指导标签分配器,生成从粗到细的层次标签,分别用于辅助头和引导头的学习。
其他改进策略
这是作者在文章最后罗列的3种方法,YOLO v7还直接借鉴使用了别的算法具备很好效果的模块和思想,虽然我们通过上面的讲解我们知道YOLO v7还是创新很多东西的,但是借鉴的是更多的东西。
- BN层融合:将 BN 层直接连接到卷积层。目的是在推理阶段将批归一化的均值和方差整合到卷积层的偏差和权重中。
- YOLOR中的隐式知识结合卷积特征映射的加乘方式:在推断阶段通过预计算,可以将YOLOR中的隐式知识简化为一个向量。该向量可以与前一层或后续卷积层的偏差和权值相结合。
- EMA模型:EMA是mean teacher中使用的一种技术,在本文的系统中,纯粹使用EMA模型作为最终的推理模型。
总结
这个时候可以回答,v7为什么好,因为借鉴融合的多,通过这种巧妙的融合,取得了最先进的检测结果。
所以我们也可以理解为什么作者用bag-of-freebies,免费礼包这个词,不是自己,就是白拿过来用的嘛。
代码复现
环境配置
1、克隆代码库,这里使用bubbliiiing的YOLO v7仓库,该仓库代码注释多,易于使用
git clone https://github.com/bubbliiiing/yolov7-pytorch
2、创建环境,以conda下环境为例
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
数据集准备
根据代码仓库要求,准备VOC2007格式数据集
VOC2007数据集目录结构如下图,Annotations文件夹包含每张图像的标准框信息,每个文件是一个XML格式的文件,描述该图像中每个目标的位置、类别等信息。ImageSets文件夹用于指定训练、测试、验证数据集中哪些图像会被使用。JPEGImages文件夹存放每个图像的JPEG格式文件。

训练过程
生成训练所需的标签,运行voc_annotation.py文件生成训练所需的2007_train.txt和2007_val.txt两个文件
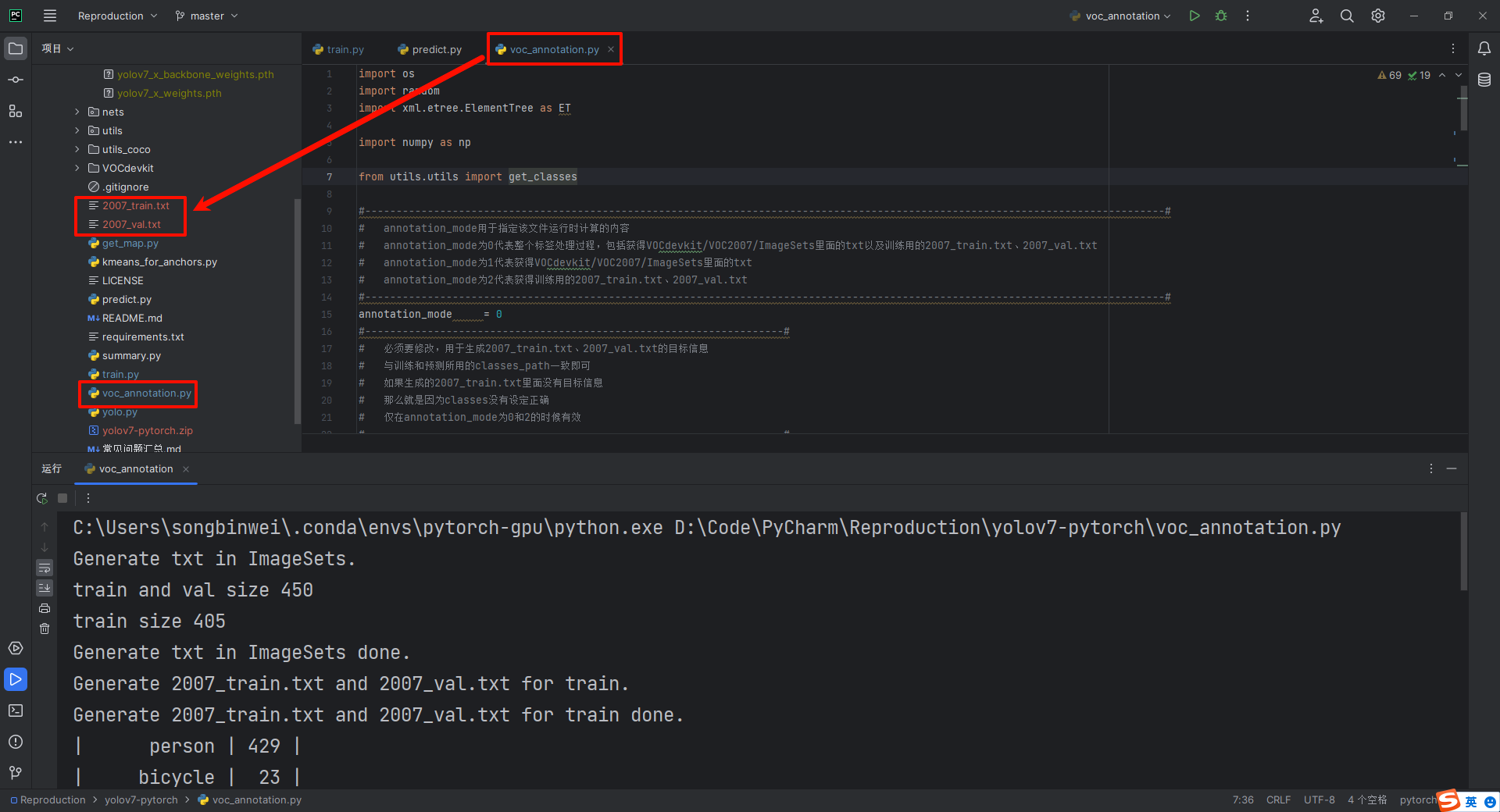
YOLO v7的训练代码如下图所示,可以按照代码注释要求修改配置后,可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。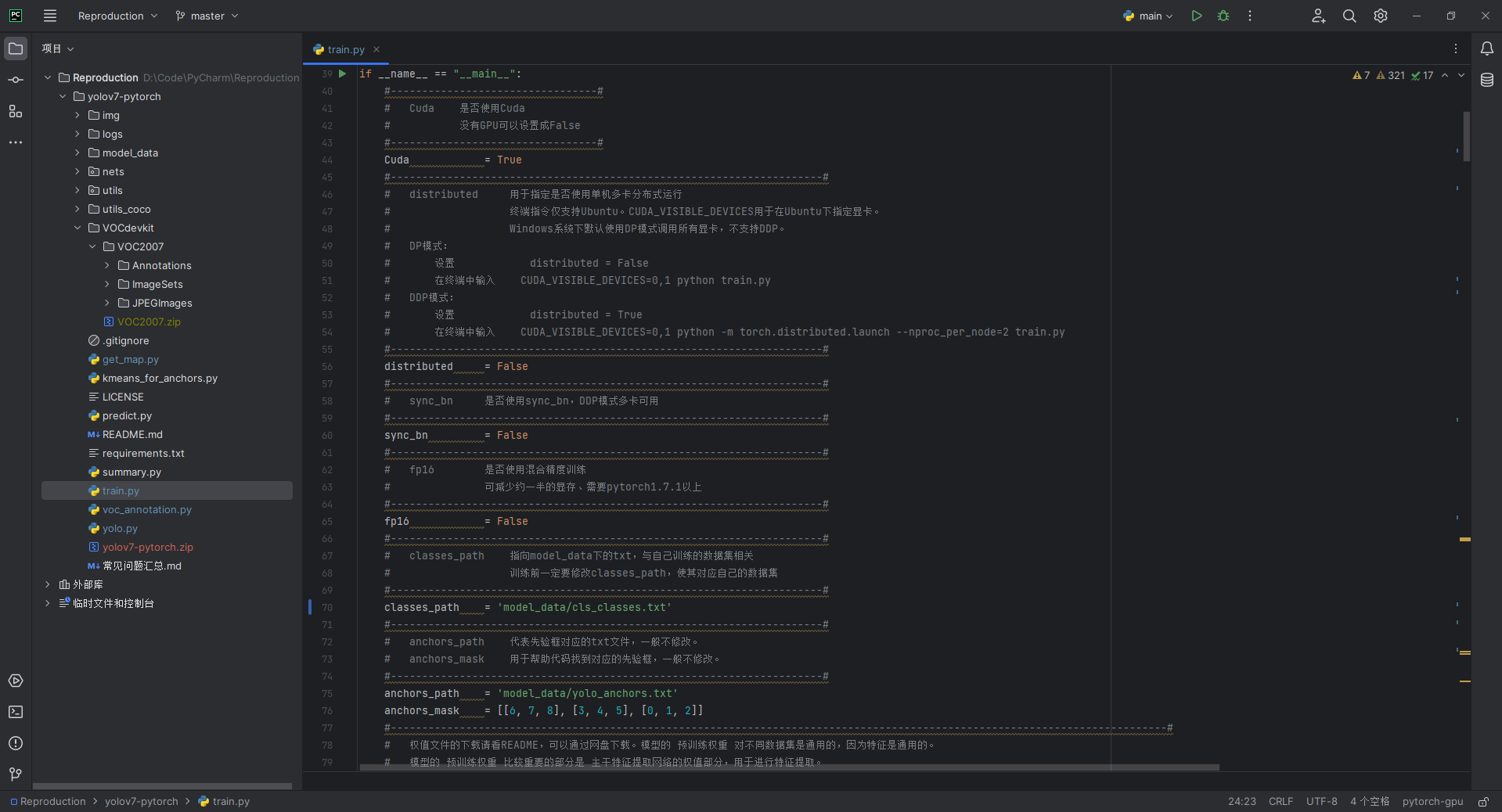
测试和评估
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。
首先修改yolo.py中的权值路径和分类的文件
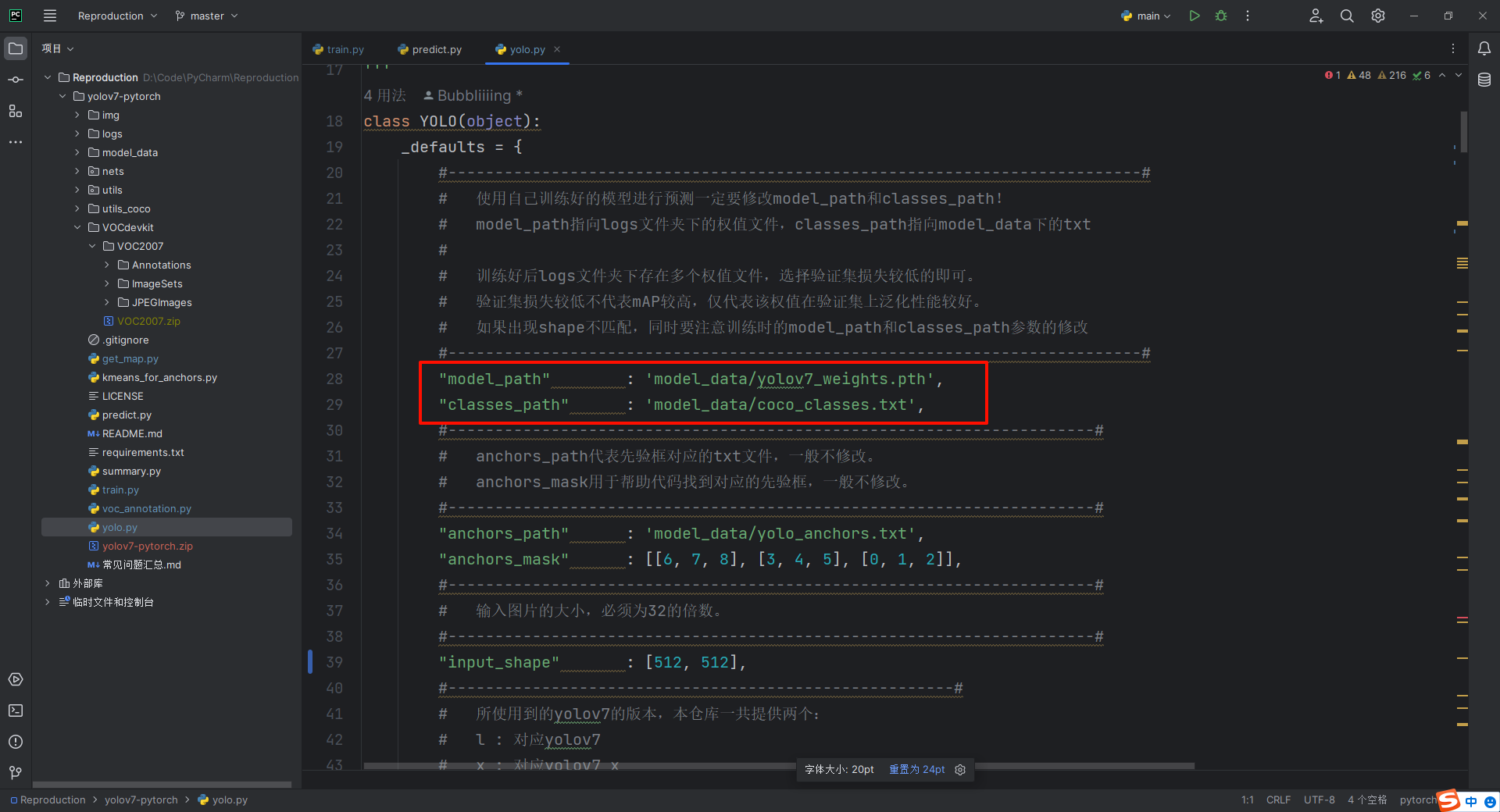
修改完成后,可以根据需要运行predict.py文件进行预测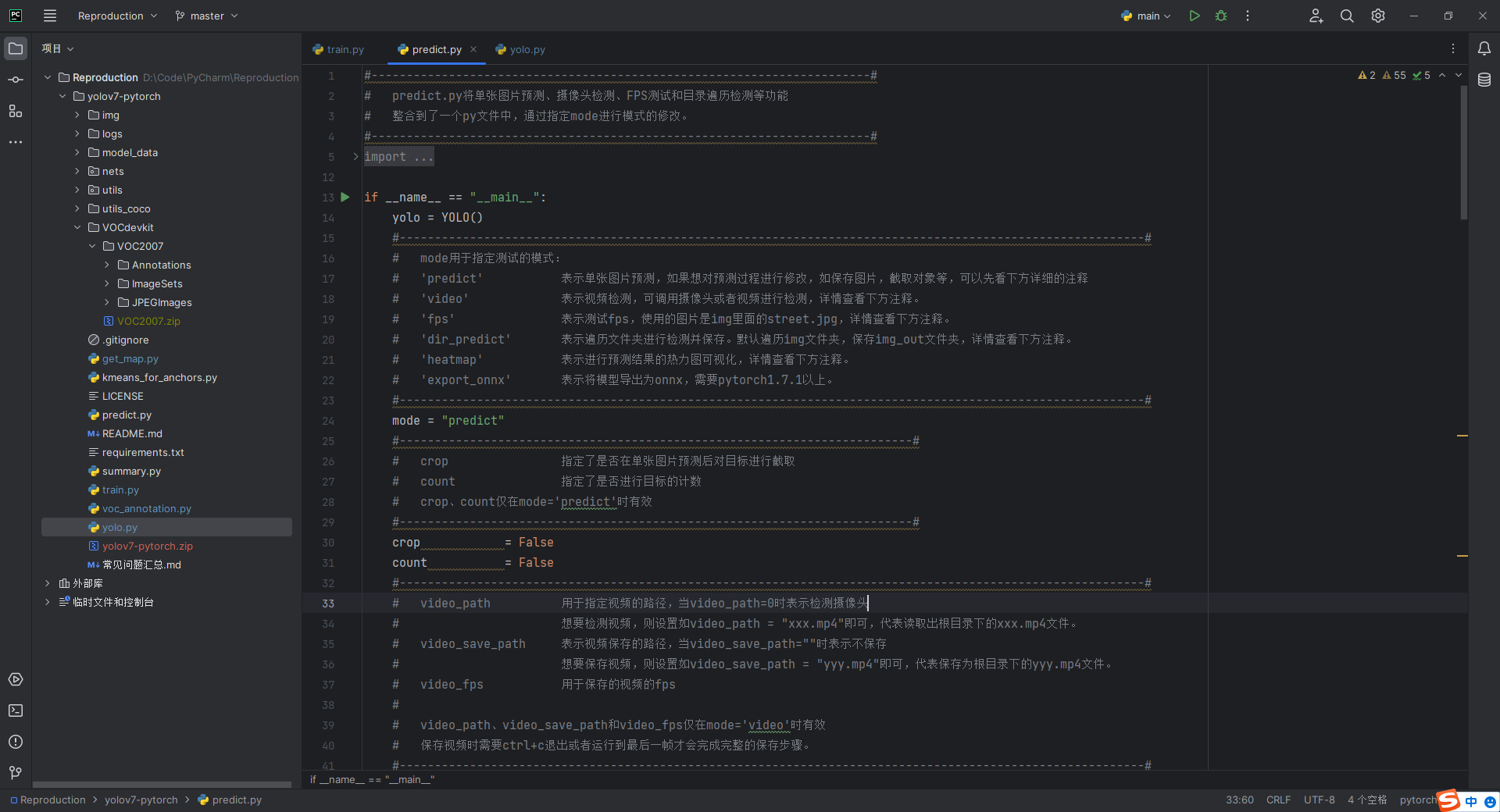
实践应用
预测效果如下所示:
参考链接
YOLO v7 GitHub仓库 链接
YOLO v7论文 链接
YOLO v7博客
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 44
44 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)