10分钟快速部署ComfyUI!附超详细工作流搭建指南(建议收藏)
comfyui整合包和启动器下载安装,配置,使用,基础知识讲解及效果展示
我现在粉丝少,什么都敢教,相关资料在下方卡片获取
每天解锁一个AI新技能
本篇重点
comfyui整合包和启动器下载安装,配置,使用,基础知识讲解及效果展示
工作流搭建
包括SDXL文生图搭建及FLUX文生图搭建
效果展示(均无lora)
首先是SDXL大模型



然后是FLUX大模型



可以看出来FLUX大模型出图无论从光影到质感到图片真实度都比SDXL大模型要好
但SDXL同样也很有质量,后续我们教程所出的图片大部分都会用FLUX跑出底图,使用SDXL完成放大(因为直接使用FLUX模型放大非常消耗显存)
整合包获取
这份完整版的comfyui整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

开始正文
一:整合包安装
下载解压:comfyui整合包(能使用满血版的尽量下载满血版,不然以后使用的时候频繁报错,会打消你使用comfyui的信心)
点击整合包,根据电脑空间选择,演示的是MAX(满血版),点击右键解压,然后输入密码:铁锅炖大鹅,中文输入,如果提示密码错误,直接复制我的文本就行,到这里comfyui就部署好了,双击run_nvidia.bat文件就可以运行了
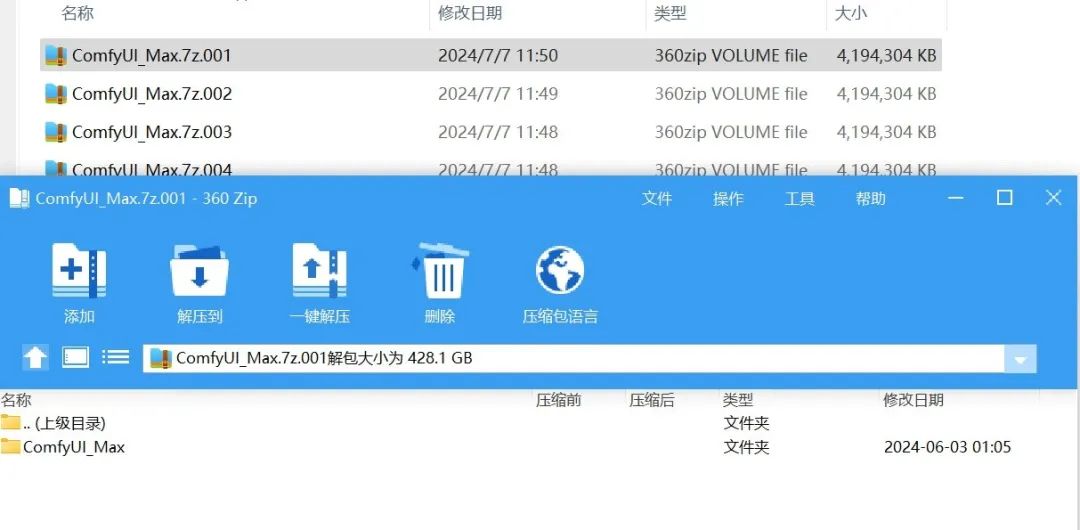
二:启动器安装
下载解压启动器,找到02-铁锅炖启动器,下载后,点击安装
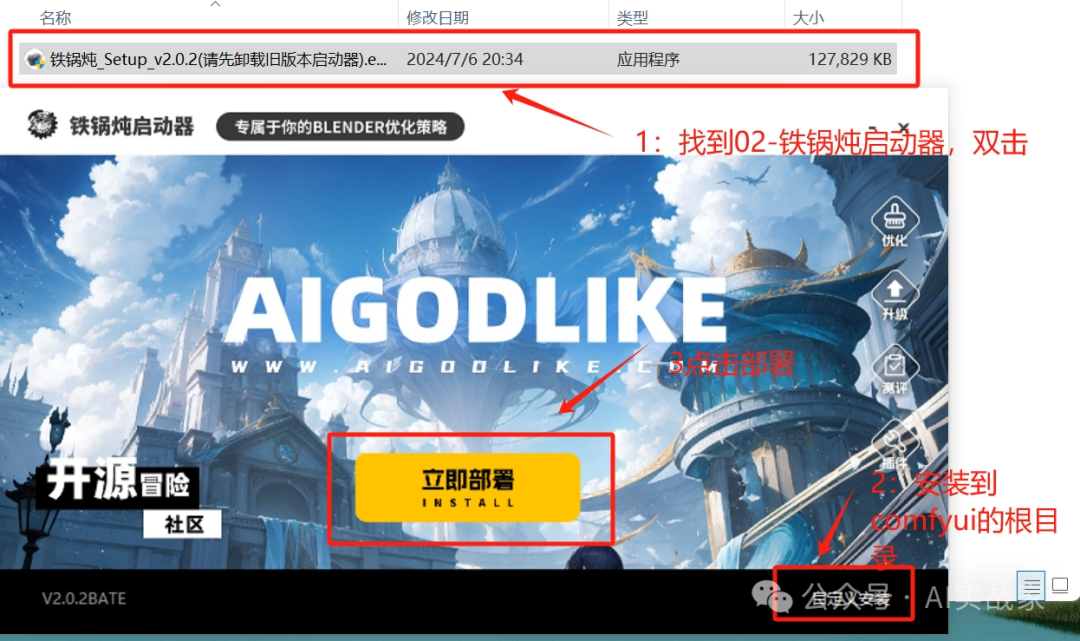
三:配置
到安装的文件夹下,双击铁锅炖启动器,在左侧菜单栏点击第二个comfyui,然后点击配置
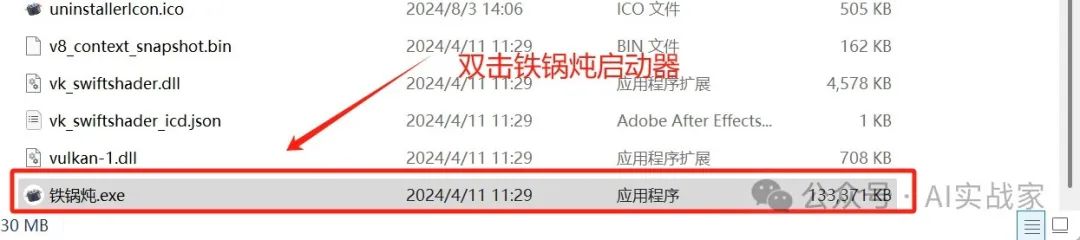
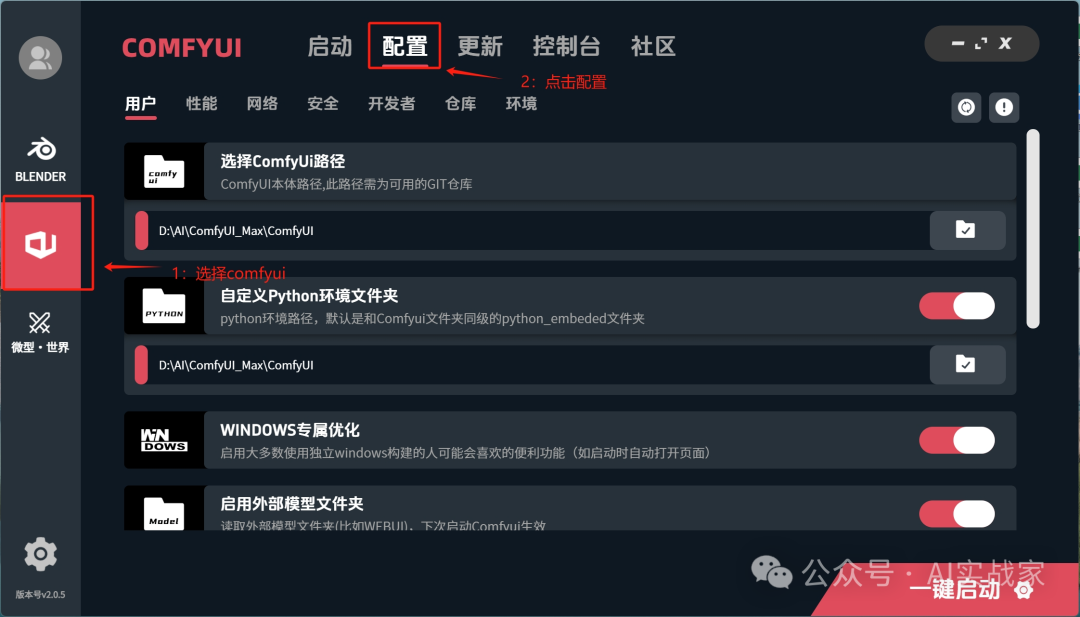
首先是【用户】子菜单下
comfyui路径和自定义python环境文件夹均选择comfyui的根目录
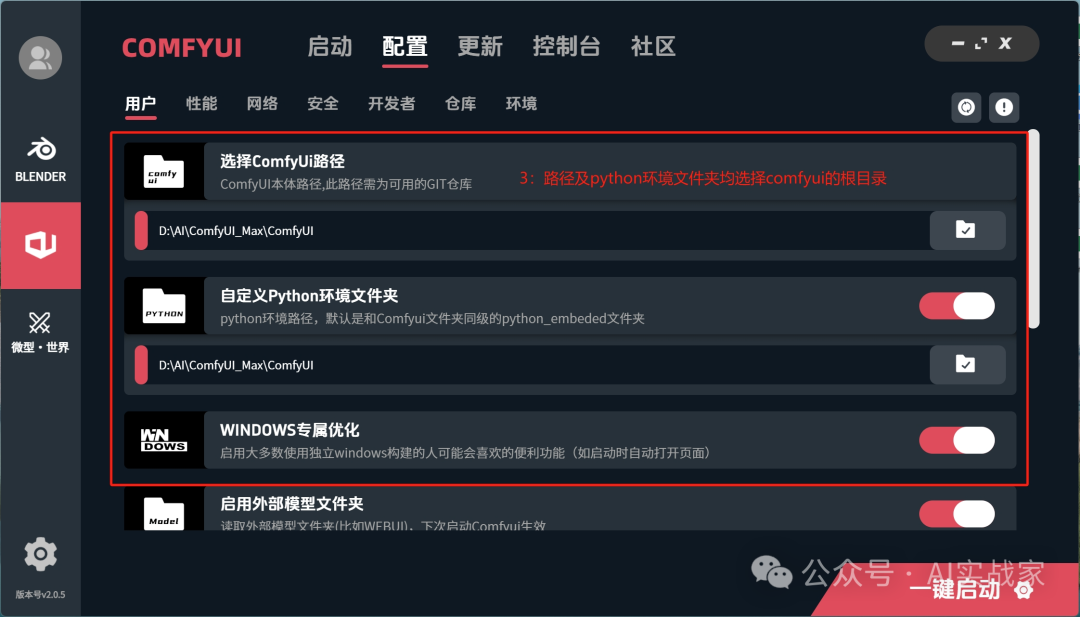
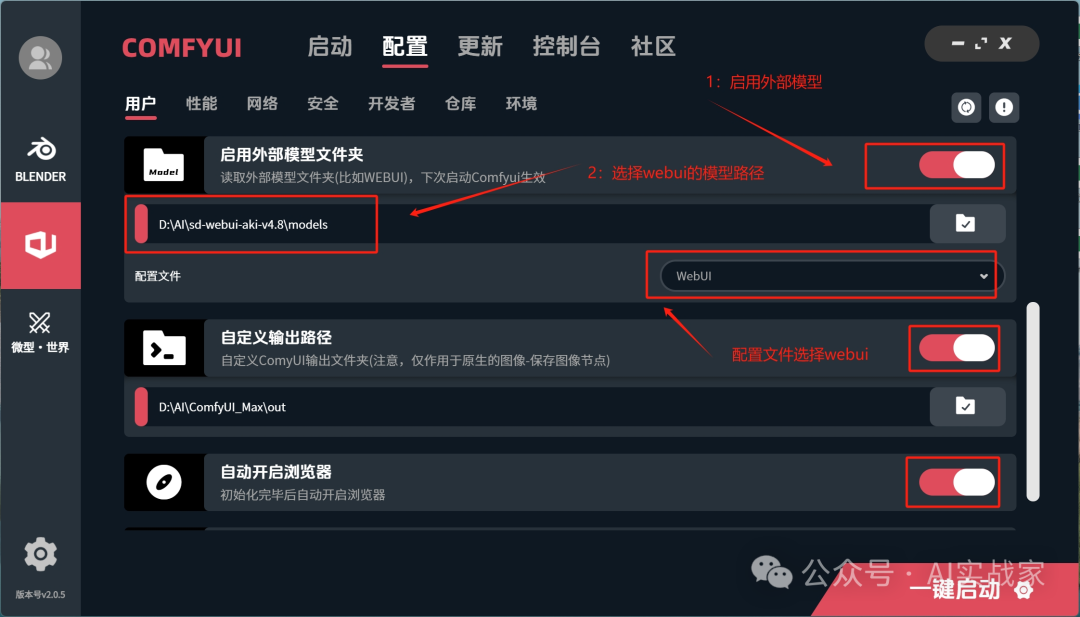
启用外部模型文件夹
如果你没有安装stable diffusion的webui,那么忽略这里
如果你安装了,那么点击启用,然后将路径设置成webui的文件夹路径,配置文件选择webui即可,后边的输出路径和开启浏览器和跳转控制台打开即可,如果不懂得,可以根据图片配置,这样就comfyui和stable diffusion-webui就可以共用模型了
【性能】子菜单下:硬件设备根据你的实际显卡选择,没有的选择CPU,GPU显存策略同样根据你的显卡决定

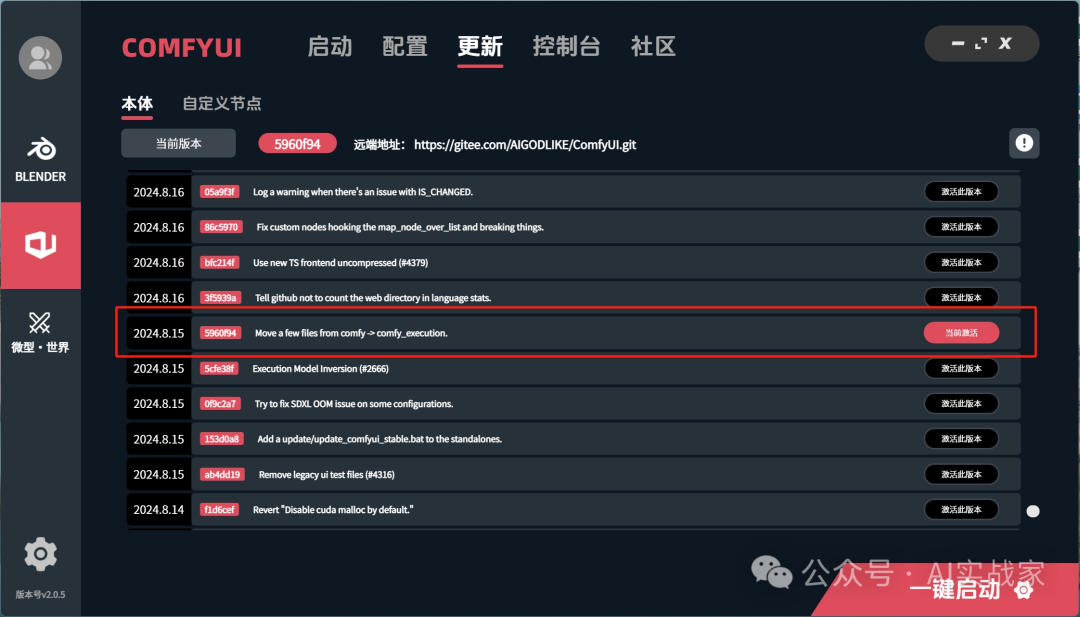
四:更新
我目前所用的版本是2024.8.15的5960F94版本,新版本我出现点击大模型,不显示模型列表,浏览器卡死,只能关掉浏览器重新启动,所以使用的旧版本,版本图片我贴在下边了
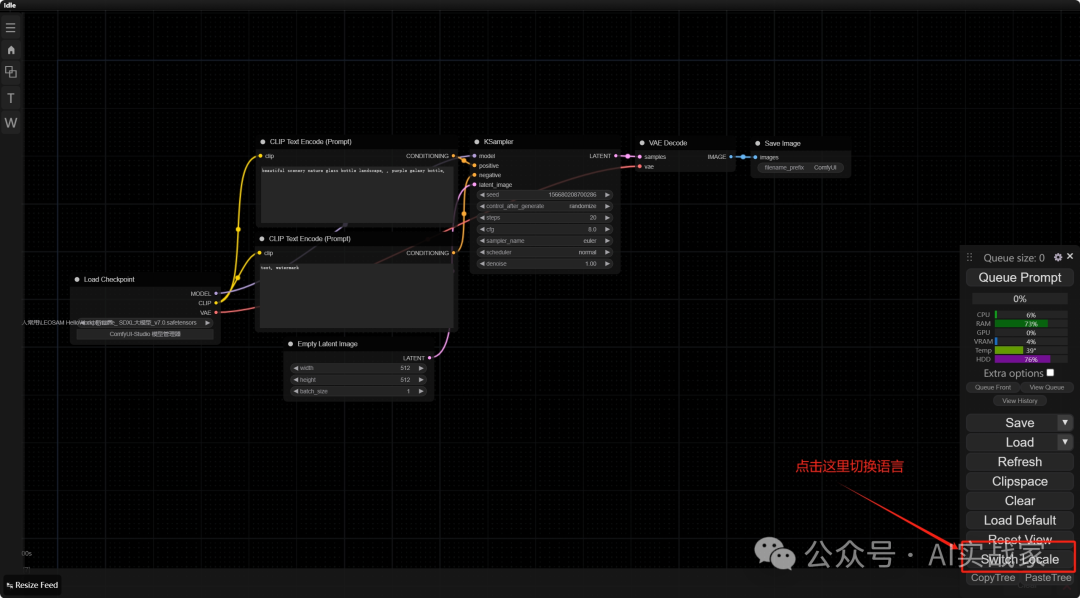
五:启动及汉化
配置完后,点击右下角一键启动,等待加载完跳转网页,如果界面是英文,点击右下角的Switch Locale(切换语言)
六:简单使用教学
1:基础原理讲解
ComfyUI的核心原理是基于Stable Diffusion模型,该模型包括三个主要部分:Clip, VAE,和U-net。
|
|
|
|
|
|
|
|
|
操作面板各按钮功能介绍
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个工作流主要由这些部分组织:节点,连线,输入,输出和参数
(想更深入了解的同学可以在网上找到相关资料,我就不做太多赘述了,我们还是以实操为主)
下面开始实操:
SDXL文生图(comfyui的模型放置位置和stable diffusion是一样的)
|
|
|
|
|
|
|
|
|
|
|
|
1:先放置一个大模型的节点,我们右键单击,选择新建节点,然后在加载器选择Checkpoint加载器(简易);同样的在条件中选择CLIP文本编码器,在采样中选择K采样器,在Latebt中选择空Latent和VAE解码器,在图像中选择保存图像,如图所示连接起来(生成的图像我们放在最后和FLUX进行一个对比)
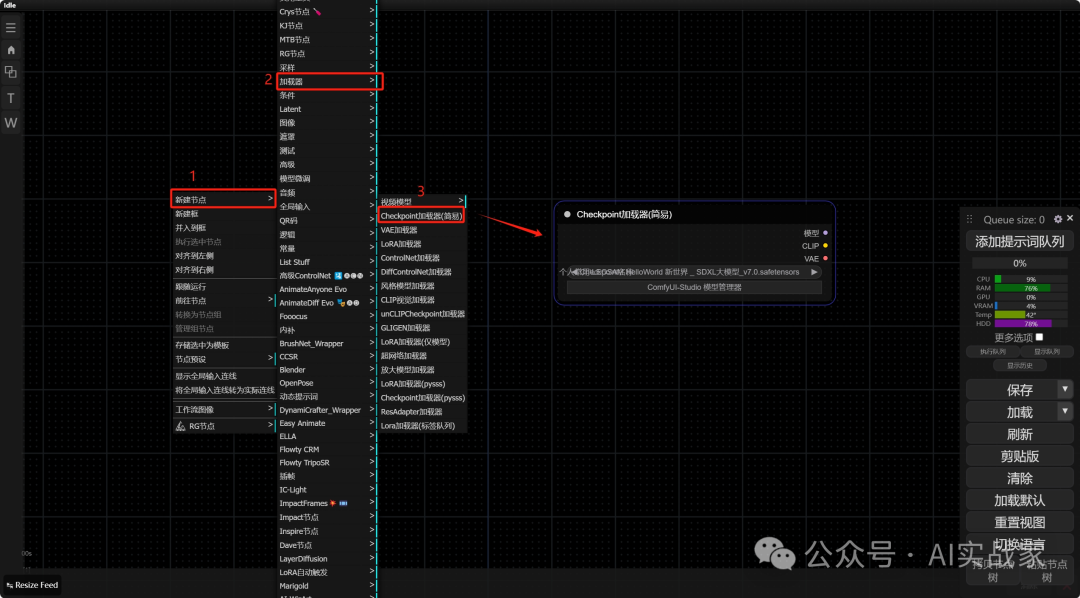
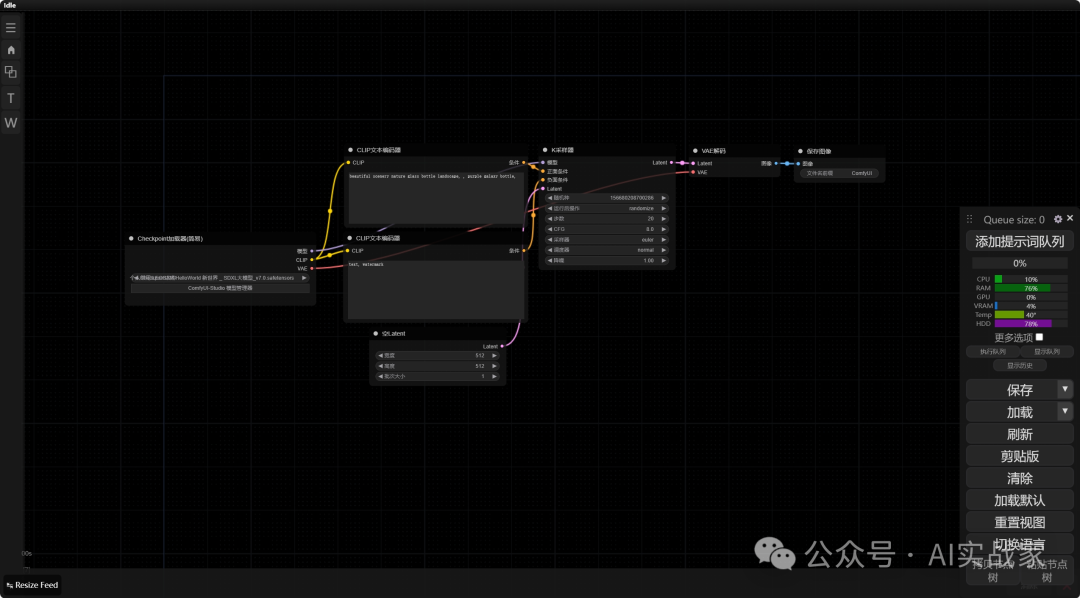
工作流原理
首先checkpoint加载器节点会最先加载对应模型及其计算权重,其次clip编码器会依据文本框里的内容对图像的生成进行导向,随后k采样器根据当前的潜在向量进行采样,并根据设置的步数进行迭代去噪,在潜空间生成图像,最后经过vae解码将生成的潜空间的图像解码成我们像素空间的图像,最后进行输出保存。
FLUX文生图
这个模型需要独立的VAE和Clip,我已经把FLUX模型,VAE和Clip整理好了,后台发送【FLUX】获取

模型放置位置
|
|
|
|
|
|
|
|
|
|
|
|
这里我们开始使用搜索进行查找(后期你的节点会特别多,右键去找会很慢)
1:先放置一个UNET加载器来加载FLUX大模型,双击左键,输入UNET,选择第一个加载器
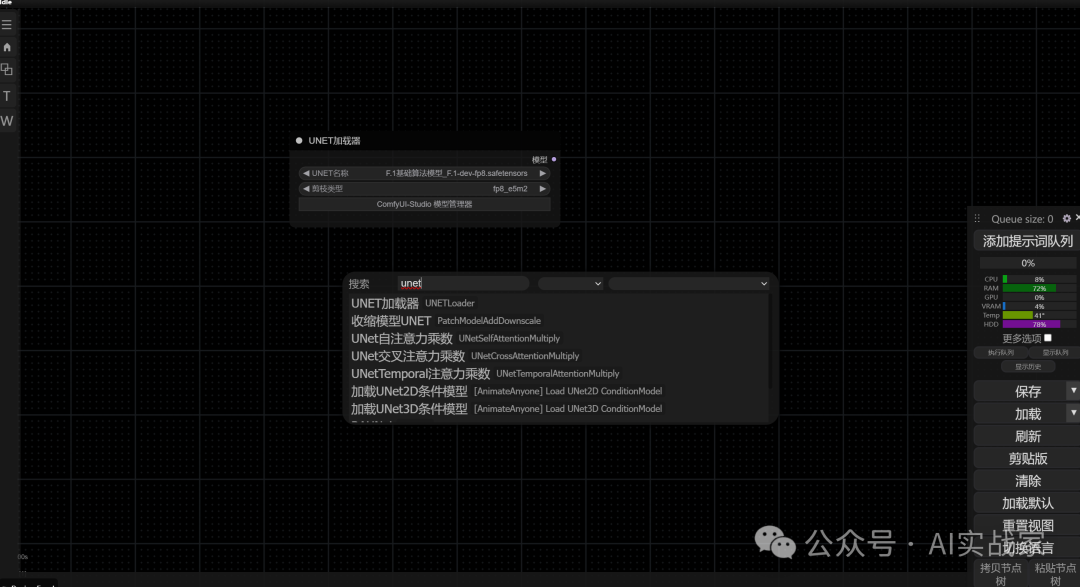
然后是双CLIP加载器
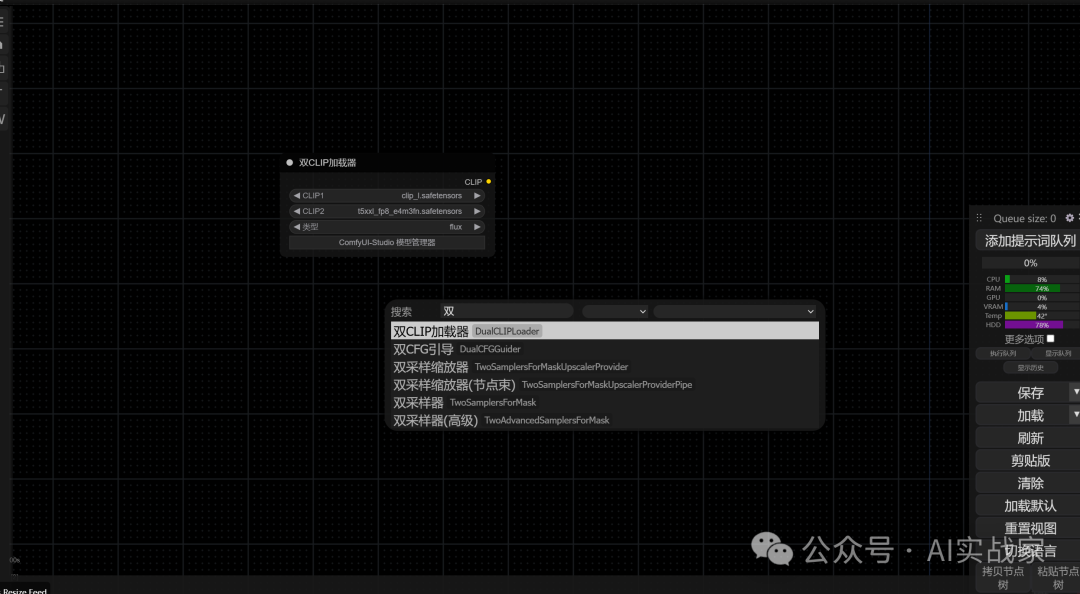
CLIP文本编码器
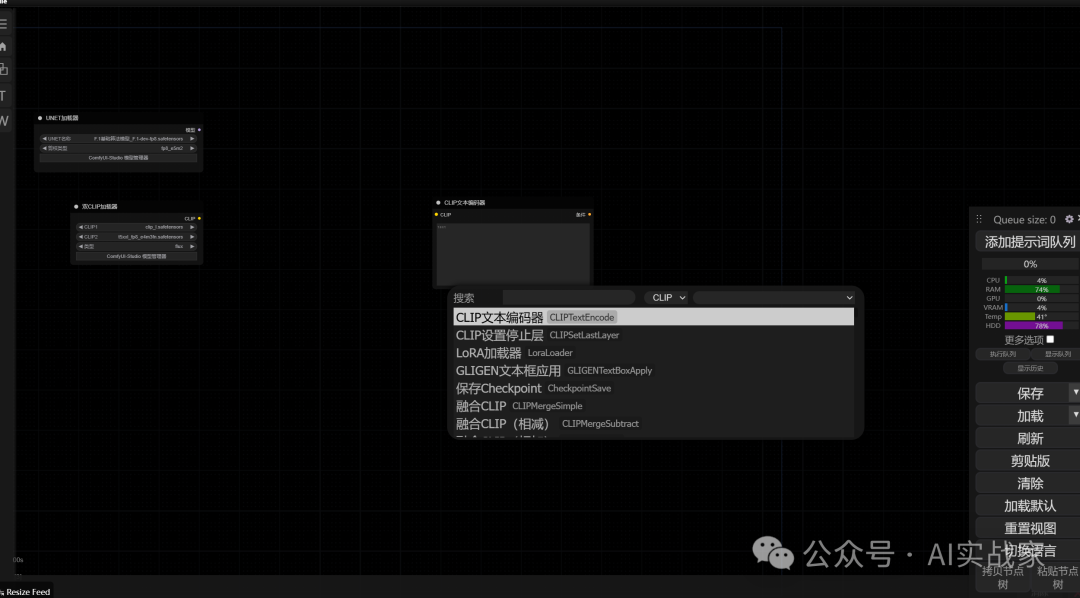
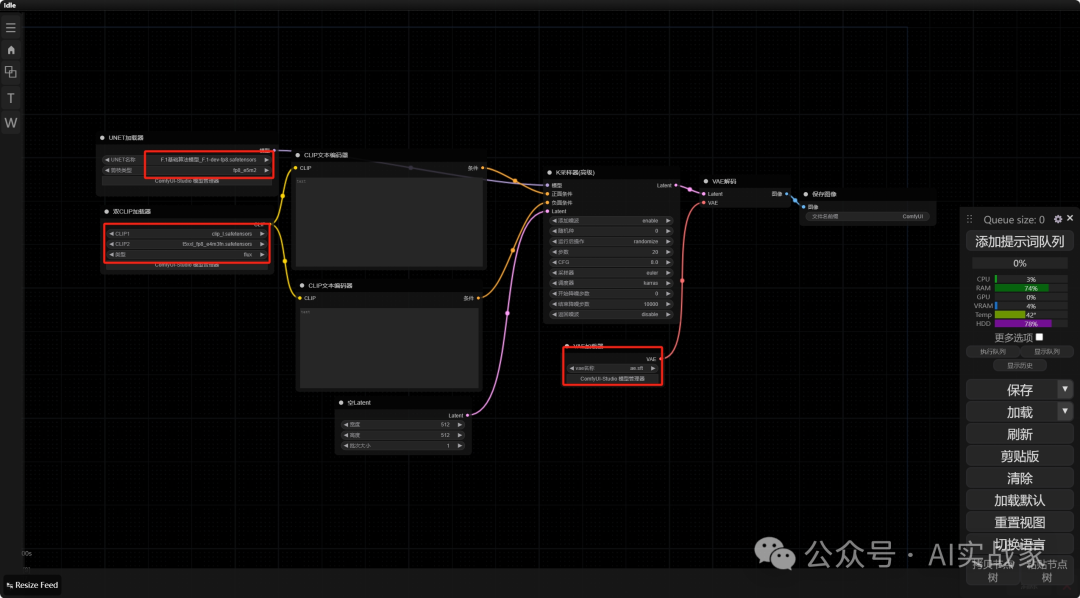
后边以此类推,空Latent,vae解码器,vae加载器(用来加载Flux的VAE),最后还是保存图像,最后串联起来如图所示(红圈的地方就是刚才下载的文件)
最后一步参数设置,一定要注意CFG设置在1~3.5之间,具体参照下图
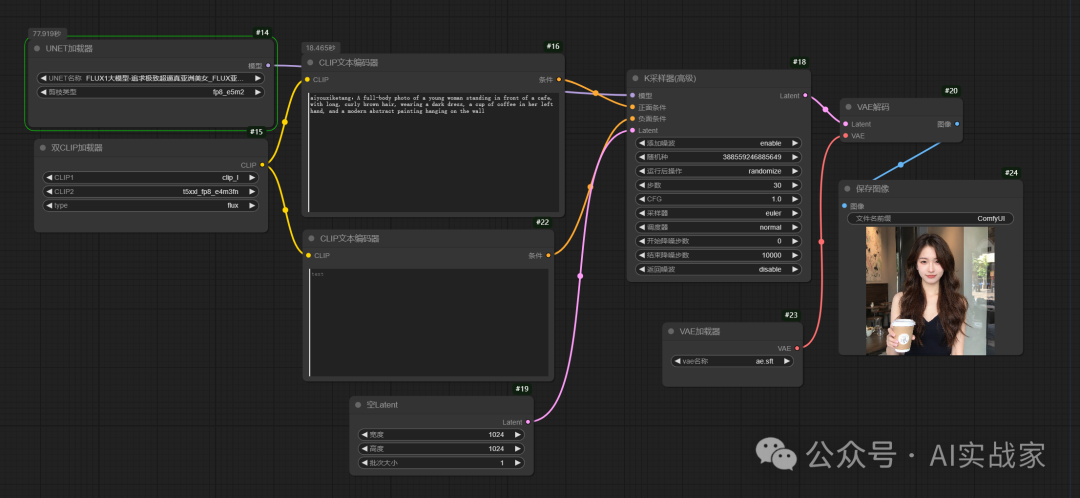

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)