Pytorch可视化与生态介绍
你还可以查看“HISTOGRAMS”选项卡来了解模型参数分布的变化,“GRAPHS”选项卡来查看计算图结构(虽然对于Keras用户来说通常不需要手动查看),以及“DISTRIBUTIONS”和“PROFILER”等其他选项卡来获取更多信息。注意:在上面的代码中,tf.summary.image的第三个参数step通常用于指示训练步骤,但在仅可视化图像时可能不是必需的。在训练脚本中,需要使用Tens
Pytorch可视化与生态介绍
一.可视化网络结构:
可以使用torchinfo开源工具包(使用其中的summary函数)。可视化网络结构需要进行一次前向传播以获得特定层的信息。
#重点是看每一层的输出维度和参数数
二.可视化CNN卷积核(kernel):
#CNN包括卷积层,卷积层包括卷积核和特征图。
#卷积核本身是一个权重的大小。
- 加载模型:首先,确保你已经加载了训练好的CNN模型。
- 访问卷积层:找到你想要可视化的卷积层。
- 提取卷积核:提取该层的卷积核权重。
- 可视化:使用matplotlib或其他可视化库显示卷积核,生成图像网格。
三.可视化CNN特征图
# CNN特征图(Feature Map)是卷积神经网络中卷积层输出的结果,它表示了输入图像在不同卷积核作用下的特征表示。
#这里要用到hook接口,除了可以使用自定义的hook外,还可以使用pytroch自带的一些方式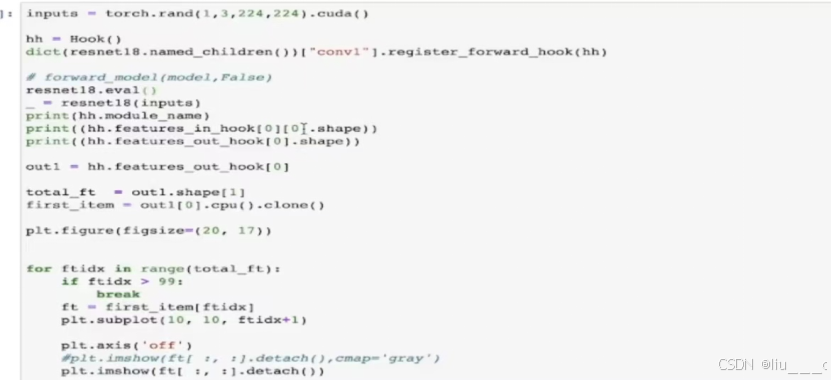
- 导入库和创建输入数据:
- inputs=torch.rand(1,3,224,224).cuda():创建一个形状为(1, 3, 224, 224)的随机输入张量,并将其移动到GPU上(通过.cuda())。这个张量模拟了一个批次的图像数据,其中1是批次大小,3是通道数(RGB),224x224是图像尺寸。
- 定义钩子对象:
- hh=Hook():创建了一个名为hh的钩子对象。这里假设Hook是一个自定义类,用于在前向传播过程中捕获某些层的输入和输出。
- 注册钩子:
- dict(resnet18.named_children())["conv1"].register_forward_hook(hh)
- 评估模型和运行前向传播:
- resnet18.eval():将模型设置为评估模式,这通常会关闭dropout和batch normalization等层的训练特定行为。
- =resnet18(inputs):。它执行了模型的前向传播,将inputs作为输入。
- 打印信息和可视化特征图:
- print(hh.module_name):打印出钩子所注册到的模块的名称(假设Hook类中有记录这个信息的属性)。
- 打印输入和输出特征图的形状:print(hh.features_in_hook[0].shape)和print(hh.features_out_hook[0].shape)(Hook类捕获了这些信息)。
- 可视化部分特征图:代码尝试可视化第一个输出特征图中的前100个特征图(
四.可视化模型某一层对输出某一类的“激活”效果(具体操作可自行搜教程参考)
#往往使用CAM的方式,可以借助grad-cam工具包快速实现
#工作原理:
- 特征提取:在CNN中,每个卷积层都会生成一组特征图,其中每个特征图对应一个卷积核。这些特征图包含了图像的不同特征信息。
- 全局平均池化(GAP):CAM技术利用全局平均池化操作来捕捉每个特征图中与目标类别相关的特征。GAP操作将每个特征图的所有像素值进行平均,得到一个平均值向量。
- 权重计算:将这个平均值向量输入到一个全连接层(或softmax层之前的层)中,得到每个类别的分数。同时,可以获取到每个特征图对于目标类别的权重。
- 类激活图生成:将每个特征图的权重与其对应的特征图相乘,并对结果进行求和,得到对应于目标类别的类激活图(CAM)。这个CAM就是一个热力图,表示了输入图像中哪些区域对于目标类别的分类决策起到了重要作用。
- 归一化与可视化:对生成的CAM进行归一化处理,以便更好地进行可视化。通常会将归一化后的CAM与原始图像叠加在一起,以更直观地展示模型关注的区域。
五.使用TensorBoard可视化模型结构
1. 安装 TensorFlow 和 TensorBoard
首先,确保你已经安装了 TensorFlow 和 TensorBoard。你可以使用以下命令来安装它们:pip install tensorflow tensorboard
2. 构建一个简单的 TensorFlow 模型
接下来,我们将构建一个简单的 TensorFlow 模型。例如,一个基本的卷积神经网络(CNN)。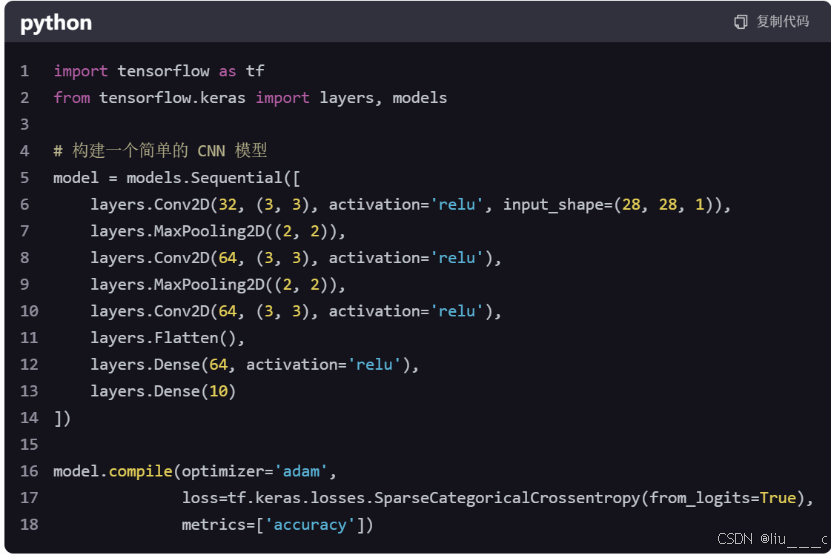
3. 创建 TensorBoard 日志目录
你需要一个目录来保存 TensorBoard 的日志文件。通常,你可以创建一个名为 logs 的目录。
4. 使用 tf.keras.callbacks.TensorBoard 回调
在训练模型时,使用 tf.keras.callbacks.TensorBoard 回调来记录模型的结构和训练过程中的其他信息。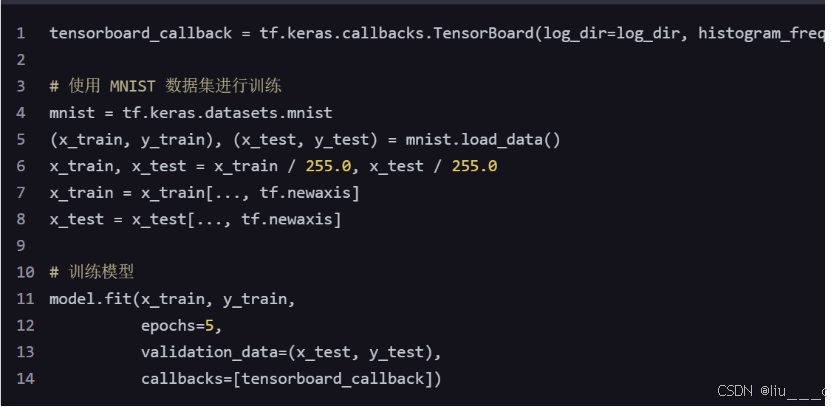
5. 启动 TensorBoard
在终端中,使用以下命令启动 TensorBoard:
TensorBoard 默认会在 http://localhost:6006 上运行。你可以在你的浏览器中打开这个 URL 来查看 TensorBoard 界面。
6. 查看模型结构
在 TensorBoard 界面中,点击左侧导航栏中的 “GRAPHS” 选项卡。你会看到一个下拉菜单,选择 “Graph” 来查看模型的结构图。你还可以选择 “OPS” 和 “COMPUTATION” 选项卡来获取更详细的信息
六.使用TensorBoard可视化图像
1.准备图像数据
你需要准备好要可视化的图像数据。这些图像可以是训练数据、测试数据或模型生成的图像(如GAN生成的图像)。
2.编写代码以记录图像到TensorBoard
在TensorFlow代码中,你可以使用tf.summary.image函数来记录图像。这里有一个简单的例子,演示如何记录图像数据: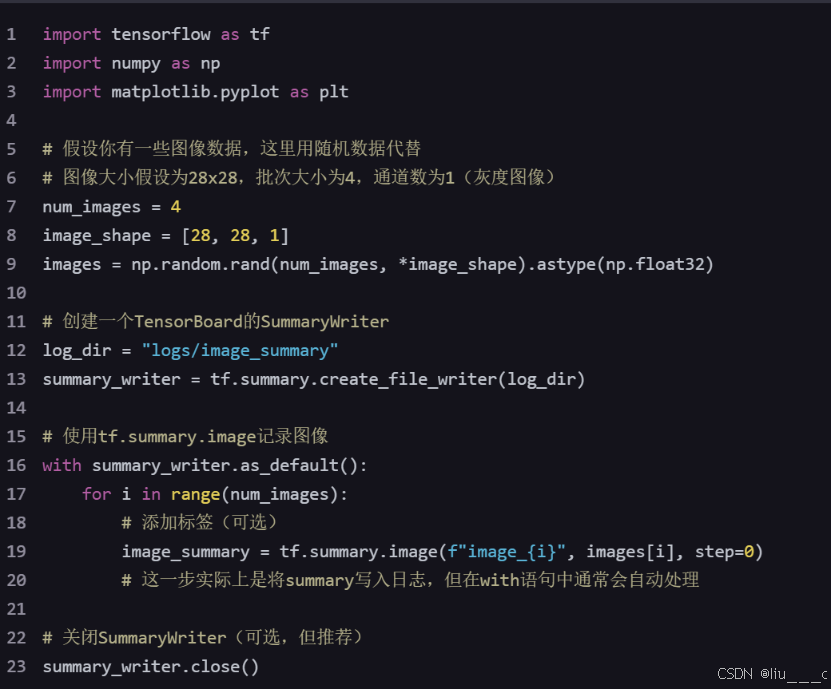
注意:在上面的代码中,tf.summary.image的第三个参数step通常用于指示训练步骤,但在仅可视化图像时可能不是必需的。此外,上面的代码片段实际上并没有立即写入任何内容到磁盘,因为TensorFlow的写操作通常是延迟的。在实际应用中,你可能希望在训练循环中定期调用这些记录操作。
3. 启动TensorBoard
在终端中,使用以下命令启动TensorBoard:
TensorBoard默认会在http://localhost:6006上运行。
4. 查看图像
在浏览器中打开http://localhost:6006,然后导航到“IMAGES”选项卡。你应该能看到你记录的图像。如果记录了多个图像(如上面的例子中的4个图像),它们将作为不同的子图显示。
七.使用TensorBoard可视化参数分布
1.编写代码以记录参数到TensorBoard
在TensorFlow中,你可以使用tf.summary.histogram函数来记录模型参数的分布。这通常是在训练循环中进行的,以便在每个epoch或一定的训练步骤后更新直方图。
2. 启动TensorBoard
3. 查看参数分布
在浏览器中打开http://localhost:6006,然后导航到“HISTOGRAMS”选项卡。你应该能看到你记录的参数分布的直方图。每个参数(如权重和偏置)都会有一个对应的直方图,显示其在不同训练步骤中的变化情况。
八.使用TensorBoard可视化训练过程
1. 安装TensorBoard
2. 编写代码以记录训练过程中的信息
在训练脚本中,需要使用TensorFlow的摘要(summary)API来记录标量(如损失和准确率)、直方图(如权重和偏置的分布)、图像等。
3. 使用TensorBoard回调(推荐方法)
TensorFlow提供了tf.keras.callbacks.TensorBoard回调,可以更方便地在训练过程中记录信息。
4. 启动TensorBoard
5. 查看训练过程
在浏览器中打开http://localhost:6006,然后导航到“SCALARS”选项卡来查看损失和准确率等标量信息的变化情况。你还可以查看“HISTOGRAMS”选项卡来了解模型参数分布的变化,“GRAPHS”选项卡来查看计算图结构(虽然对于Keras用户来说通常不需要手动查看),以及“DISTRIBUTIONS”和“PROFILER”等其他选项卡来获取更多信息。
九.pytorch生态介绍
PyTorch生态是一个围绕PyTorch框架构建的丰富工具和库的集合,这些工具和库共同支持并扩展了PyTorch的功能,使其成为一个强大且灵活的深度学习平台。
生态工具包
- TorchVision:PyTorch官方提供的图像处理工具包,包含了各种图像数据集加载、图像变换、以及预训练的图像模型等功能,方便用户进行图像相关任务的开发和研究。
- torchvision.datasets:主要包含计算机视觉常见的数据集。
- torchvision.models:提供预训练好的模型。
- torchvision.transforms:提供数据预处理功能。
- torchvision.io:提供视频、图片、文件的IO操作。
- torchvision.ops:提供计算机视觉的特定操作。
- torchvision.utils:提供可视化方法。
- PyTorchVideo:一个专注于视频理解工作的深度学习库,提供了加速视频理解研究所需的可重用、模块化和高效的组件。它支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换,并提供了model zoo,使得人们可以使用各种先进的预训练视频模型及其评判基准。
- TorchText:PyTorch官方提供的自然语言处理工具包,提供了数据集加载、文本预处理、词嵌入等功能,使得用户能够更方便地处理文本数据并构建文本处理模型。
- Ignite:一个轻量级的高级工具包,用于训练和评估PyTorch模型。它提供了模型训练的各种组件,如训练循环、评估指标、事件管理等,可以帮助用户更高效地管理和监控模型训练过程。
- TorchSummary:一个用于查看PyTorch模型结构摘要的工具包。通过简单的调用,用户可以快速查看模型的层次结构、参数数量以及每一层的输入输出形状,有助于更好地理解和调试模型。
#make works easier

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)