基于Scikit-Learn的机器学习模型评估方法:准确率、均方误差与交叉验证
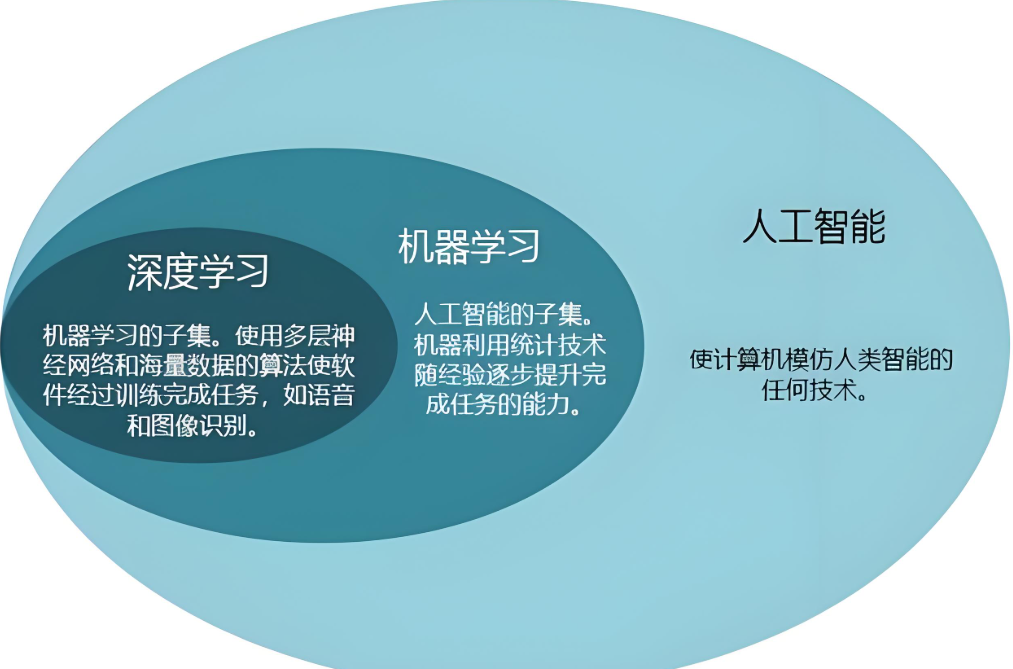
机器学习是人工智能的一个重要分支,它让计算机能够通过数据来学习并做出预测。在机器学习中,分类和回归是两种常见的任务类型。分类任务旨在将数据分为不同类别,而回归任务则预测连续值。Scikit-Learn是一个非常流行且功能强大的Python库,它提供了丰富的机器学习算法和工具,使得学习和实现机器学习变得非常简单。本文将通过一个简单的示例,介绍如何使用Scikit-Learn进行分类和回归分析,帮助你
基于Scikit-Learn的机器学习模型评估方法:准确率、均方误差与交叉验证
机器学习是人工智能的一个重要分支,它让计算机能够通过数据来学习并做出预测。在机器学习中,分类和回归是两种常见的任务类型。分类任务旨在将数据分为不同类别,而回归任务则预测连续值。Scikit-Learn是一个非常流行且功能强大的Python库,它提供了丰富的机器学习算法和工具,使得学习和实现机器学习变得非常简单。
本文将通过一个简单的示例,介绍如何使用Scikit-Learn进行分类和回归分析,帮助你更好地理解机器学习的基础。
1. 安装与导入库
首先,我们需要安装scikit-learn库。如果你还没有安装,可以通过以下命令安装:
pip install scikit-learn
然后,我们导入所需的库。我们将使用numpy进行数组操作,matplotlib进行数据可视化,scikit-learn来处理机器学习的任务。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris, make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.metrics import accuracy_score, mean_squared_error
2. 分类任务:使用逻辑回归进行鸢尾花分类
2.1 加载数据集
我们将使用经典的鸢尾花数据集(Iris Dataset),这个数据集包含了3种不同鸢尾花的样本数据,每个样本包含4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
2.2 数据集分割
我们将数据集分割为训练集和测试集,其中80%用于训练,20%用于测试。
# 数据集分割:80%用于训练,20%用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2.3 创建并训练模型
我们将使用LogisticRegression模型进行训练。逻辑回归是一种常见的分类模型,适用于二分类或多分类任务。
# 创建逻辑回归分类器
clf = LogisticRegression(max_iter=200)
# 训练模型
clf.fit(X_train, y_train)
2.4 模型评估
使用测试集评估模型的性能,并计算其准确率。
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'分类任务的准确率:{accuracy:.2f}')
2.5 可视化分类结果
通过散点图可视化分类结果,帮助我们直观理解模型的表现。
# 可视化分类结果
plt.figure(figsize=(8, 6))
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap=plt.cm.Paired, edgecolors='k', s=100)
plt.title("Iris Flower Classification")
plt.xlabel("Sepal Length")
plt.ylabel("Sepal Width")
plt.show()
3. 回归任务:使用线性回归进行房价预测
3.1 生成回归数据
我们使用make_regression生成一个简单的回归数据集,目标是预测一个连续的目标变量。
# 生成回归数据集
X_reg, y_reg = make_regression(n_samples=100, n_features=1, noise=20, random_state=42)
# 可视化回归数据
plt.scatter(X_reg, y_reg, color='blue')
plt.title("Regression Data")
plt.xlabel("Feature")
plt.ylabel("Target")
plt.show()
3.2 数据集分割
同样地,我们将数据集分为训练集和测试集。
# 数据集分割:80%用于训练,20%用于测试
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(X_reg, y_reg, test_size=0.2, random_state=42)
3.3 创建并训练模型
我们将使用LinearRegression模型进行训练。线性回归是一种常用的回归分析方法,它试图通过拟合一条直线来预测目标变量。
# 创建线性回归模型
regressor = LinearRegression()
# 训练模型
regressor.fit(X_train_reg, y_train_reg)
3.4 模型评估
使用测试集评估模型的性能,并计算其均方误差(MSE)来衡量预测误差。
# 预测测试集
y_pred_reg = regressor.predict(X_test_reg)
# 计算均方误差
mse = mean_squared_error(y_test_reg, y_pred_reg)
print(f'回归任务的均方误差:{mse:.2f}')
3.5 可视化回归结果
通过散点图和回归线可视化模型的拟合效果。
# 可视化回归结果
plt.scatter(X_test_reg, y_test_reg, color='blue', label="Actual")
plt.plot(X_test_reg, y_pred_reg, color='red', label="Predicted")
plt.title("Linear Regression")
plt.xlabel("Feature")
plt.ylabel("Target")
plt.legend()
plt.show()
4. 超参数调优与模型选择
在机器学习中,模型的性能不仅取决于数据本身,还取决于模型的超参数。超参数是模型训练过程中需要手动设置的参数,如逻辑回归的正则化参数、支持向量机的核函数类型等。不同的超参数组合可能会对模型的表现产生显著影响,因此,超参数调优是提高模型性能的一个重要步骤。
4.1 网格搜索(Grid Search)
网格搜索是一种常用的超参数调优方法,它通过在给定的参数范围内进行穷举搜索,找到最优的超参数组合。在Scikit-Learn中,可以通过GridSearchCV来实现网格搜索。
以下是使用网格搜索调优逻辑回归模型的正则化参数(C)的例子:
from sklearn.model_selection import GridSearchCV
# 定义要调优的超参数
param_grid = {'C': [0.01, 0.1, 1, 10, 100]}
# 创建逻辑回归模型
clf = LogisticRegression(max_iter=200)
# 使用GridSearchCV进行超参数调优
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 输出最优超参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最优参数训练的模型进行预测
best_clf = grid_search.best_estimator_
y_pred_best = best_clf.predict(X_test)
# 计算最优模型的准确率
accuracy_best = accuracy_score(y_test, y_pred_best)
print(f'最优模型的准确率:{accuracy_best:.2f}')
4.2 随机搜索(Random Search)
与网格搜索不同,随机搜索不是穷举所有可能的超参数组合,而是在给定的超参数范围内随机选择一些组合进行训练。这种方法通常能够更快速地找到一个较优的超参数组合,尤其是在超参数空间较大的时候。Scikit-Learn提供了RandomizedSearchCV来实现随机搜索。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# 定义要调优的超参数
param_dist = {'C': uniform(0.01, 100)}
# 创建逻辑回归模型
clf = LogisticRegression(max_iter=200)
# 使用RandomizedSearchCV进行超参数调优
random_search = RandomizedSearchCV(estimator=clf, param_distributions=param_dist, n_iter=100, cv=5)
random_search.fit(X_train, y_train)
# 输出最优超参数
print("Best parameters found: ", random_search.best_params_)
# 使用最优参数训练的模型进行预测
best_clf_random = random_search.best_estimator_
y_pred_random = best_clf_random.predict(X_test)
# 计算最优模型的准确率
accuracy_random = accuracy_score(y_test, y_pred_random)
print(f'随机搜索最优模型的准确率:{accuracy_random:.2f}')
5. 交叉验证(Cross-Validation)
交叉验证是一种验证模型性能的技术,它可以帮助我们评估模型在不同数据集上的泛化能力,避免模型过拟合。最常见的交叉验证方法是K折交叉验证。Scikit-Learn提供了cross_val_score函数,可以方便地进行K折交叉验证。
5.1 K折交叉验证
我们可以通过K折交叉验证来评估分类模型的性能。在交叉验证中,数据集被分为K个子集,模型会依次使用其中的K-1个子集进行训练,剩下的一个子集用于验证,最终输出模型的平均评分。
from sklearn.model_selection import cross_val_score
# 使用K折交叉验证评估逻辑回归模型
scores = cross_val_score(LogisticRegression(max_iter=200), X, y, cv=5)
# 输出每折的得分以及平均得分
print(f'每折的得分:{scores}')
print(f'平均得分:{scores.mean():.2f}')
5.2 留一法交叉验证(Leave-One-Out Cross-Validation)
留一法交叉验证(LOO-CV)是一种特殊的交叉验证方法,它在每一轮训练中只使用一个样本作为验证集,剩下的样本作为训练集。对于小数据集,LOO-CV可以提供非常准确的评估。
from sklearn.model_selection import LeaveOneOut
# 创建留一法交叉验证对象
loo = LeaveOneOut()
# 使用留一法进行交叉验证
scores_loo = cross_val_score(LogisticRegression(max_iter=200), X, y, cv=loo)
# 输出留一法的得分
print(f'留一法每次交叉验证的得分:{scores_loo}')
print(f'留一法平均得分:{scores_loo.mean():.2f}')
6. 模型评估指标
在机器学习中,我们通常会使用不同的评估指标来衡量模型的表现。对于分类任务,常用的评估指标有准确率(Accuracy)、精确度(Precision)、召回率(Recall)、F1分数(F1-Score)等。对于回归任务,常用的评估指标有均方误差(MSE)、均方根误差(RMSE)、决定系数(R²)等。
6.1 分类任务的评估指标
除了准确率外,我们可以使用混淆矩阵、精确度、召回率和F1分数来进一步分析分类模型的表现。
from sklearn.metrics import confusion_matrix, classification_report
# 输出混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'混淆矩阵:\n{conf_matrix}')
# 输出分类报告
class_report = classification_report(y_test, y_pred)
print(f'分类报告:\n{class_report}')
6.2 回归任务的评估指标
对于回归任务,常用的评估指标包括均方误差(MSE)、均方根误差(RMSE)和R²值。
from sklearn.metrics import mean_squared_error, r2_score
# 计算均方误差(MSE)和R²
mse_reg = mean_squared_error(y_test_reg, y_pred_reg)
r2 = r2_score(y_test_reg, y_pred_reg)
print(f'均方误差(MSE):{mse_reg:.2f}')
print(f'决定系数(R²):{r2:.2f}')
7. 其他常见机器学习模型
Scikit-Learn提供了许多机器学习模型,除了逻辑回归和线性回归之外,还有很多其他常见的分类和回归算法,如:
- 支持向量机(SVM):适用于高维数据的分类和回归。
- 决策树(Decision Trees):可以用于分类和回归任务,易于理解。
- 随机森林(Random Forests):集成学习算法,通常比单一的决策树更强大。
- K近邻(K-Nearest Neighbors, KNN):基于距离度量的简单模型,适用于分类和回归。
7.1 支持向量机(SVM)
from sklearn.svm import SVC
# 创建支持向量机分类器
svm_clf = SVC()
# 训练模型
svm_clf.fit(X_train, y_train)
# 预测测试集
y_pred_svm = svm_clf.predict(X_test)
# 计算准确率
accuracy_svm = accuracy_score(y_test, y_pred_svm)
print(f'SVM模型的准确率:{accuracy_svm:.2f}')
7.2 随机森林(Random Forest)
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rf_clf = RandomForestClassifier()
# 训练模型
rf_clf.fit(X_train, y_train)
# 预测测试集
y_pred_rf = rf_clf.predict(X_test)
# 计算准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f'随机森林模型的准确率:{accuracy_rf:.2f}')
通过本文的讲解,你已经了解了如何使用Scikit-Learn进行分类和回归分析,如何进行超参数调优、交叉验证,以及评估模型的常用指标。同时,你也初步接触了其他常见的机器学习模型。随着学习的深入,你可以逐步尝试更多复杂的数据集和算法,挑战更高级的机器学习任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)