如何通过unSloth 微调(Fine-tuning)专业大模型
微调、RAG和蒸馏的对比和区别。
学习目标:
● 理解大模型微调的基本过程
● 理解模型微调的方法和工具
● 微调、蒸馏、RAG的比较
工具及要件
● 数据集 - DataSet
● 微调工具 - unSloth 和 LLaMA-Factory
● 预训练模型和方法 - 如DeepSeek R1 & LoRA & QLoRA
● 运行环境 - GPU环境(私有&公有云)
基本概念
● 什么是微调
是指在已有的预训练模型的基础上,根据特定的任务需求,使用特定的数据集,对模型的参数进行进一步的调整和优化,从而新生成一个小模型,以便能够更好地适应这个特定任务。
● 微调有什么用
○ 更新知识:引入新的领域特定信息。
○ 自定义行为:调整模型的语气、个性或响应风格。
○ 针对任务优化:提高特定用例的准确性和相关性。
● 微调的方法
● 数据集以及数据集格式
Dataset数据集是可用于训练我们模型的集合
微调全****过程
● 准备环境和依赖
# 操作系统要求
支持 Linux 和 Windows 通过 WSL 运行
# N卡及CUDA
2018 年以后 NVIDIA GPU
CUDA 7.0 +
# 依赖及其他
必须支持 xformers 、 torch 、 BitsandBytes 和 triton
# 内存预估,看这个网址:https://docs.unsloth.ai/get-started/beginner-start-here/unsloth-requirements
● 安装微调工具和依赖
# 安装 unsloth
pip install --upgrade pip # 检查python环境,更新pip
pip install "unsloth[cu121-torch240] @ git+https://github.com/unslothai/unsloth.git" # 通过github文件安装
📢 :这里要提示的是,环境安装依据个人环境会有不同的报错,最好是搞一个新的
版本,比如unbantu升级到版本和补丁,否则很容易浪费很多时间
● 准备好数据集
如下示
"Instruction": "Task we want the model to perform."
"Input": "Optional, but useful, it will essentially be the user's query."
"Output": "The expected result of the task and the output of the model."
{
"conversations": [
{
"from": "human",
"value": "Can you help me make pasta carbonara?"
},
{
"from": "assistant",
"value": "Would you like the traditional Roman recipe, or a simpler version?"
},
{
"from": "human",
"value": "The traditional version please"
},
{
"from": "assistant",
"value": "The authentic Roman carbonara uses just a few ingredients: pasta, guanciale, eggs, Pecorino Romano, and black pepper. Would you like the detailed recipe?"
}
]
}
● 数据格式及Token化

● 选择模型和微调方法
○ 选择模型
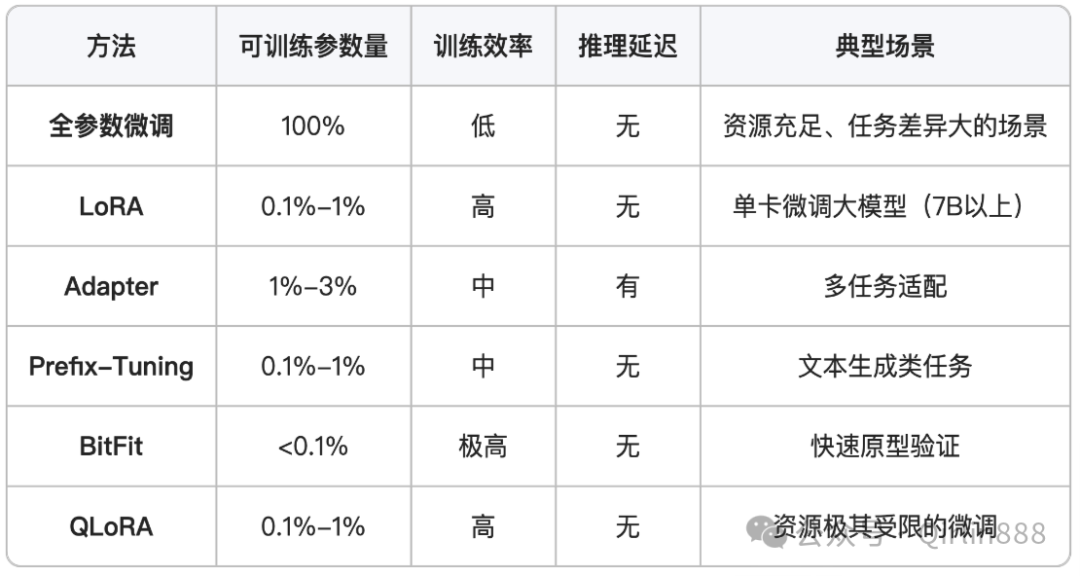
官方首推llama3.1的指令模型,这个其实在魔搭和抱脸上很多,可以自己选择。从具体来说这个要方向(图像、文本)、数据量、资源配置情况来看,但这个肯定很啰嗦,这里梳理了一个表格,大家自己对照来看吧。


这两个表格统计来自于unsloth官方,但实际测试我们目前都采用DeepSeek V3 & R1 ,当然你也可以使用llama及其Qwen的版本,所以这个就看你具体要做什么方向的训练了,社区上面比较多,自己查询接口。
○ 选择方法
unsloth官方推荐QLoRA和LoRA ,当然这个看数据量和知识库的方向了
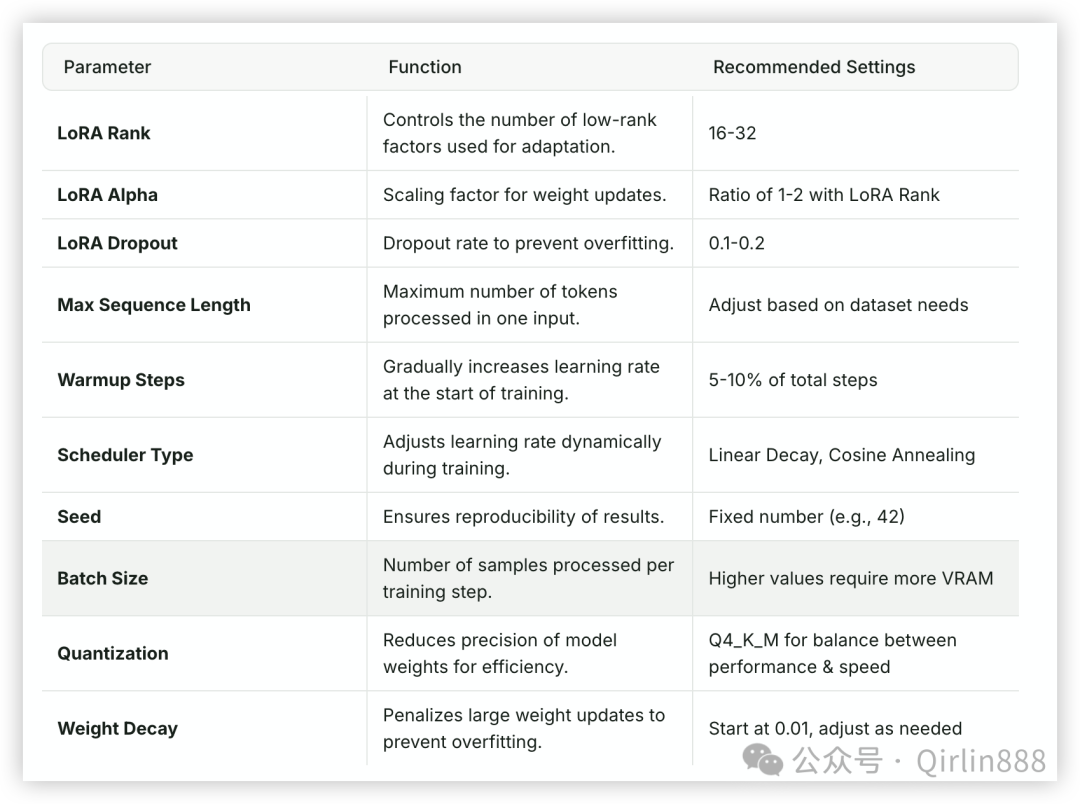
● 配置对应参数
LoRA参数配置如下,原文link如下 :
https://docs.unsloth.ai/get-started/beginner-start-here/lora-parameters-encyclopedia
● 进行微调动作及评估
准备好数据和环境,设置好参数,运行程序,开启微调程序运行过程,通过查看Training Loss 来观察
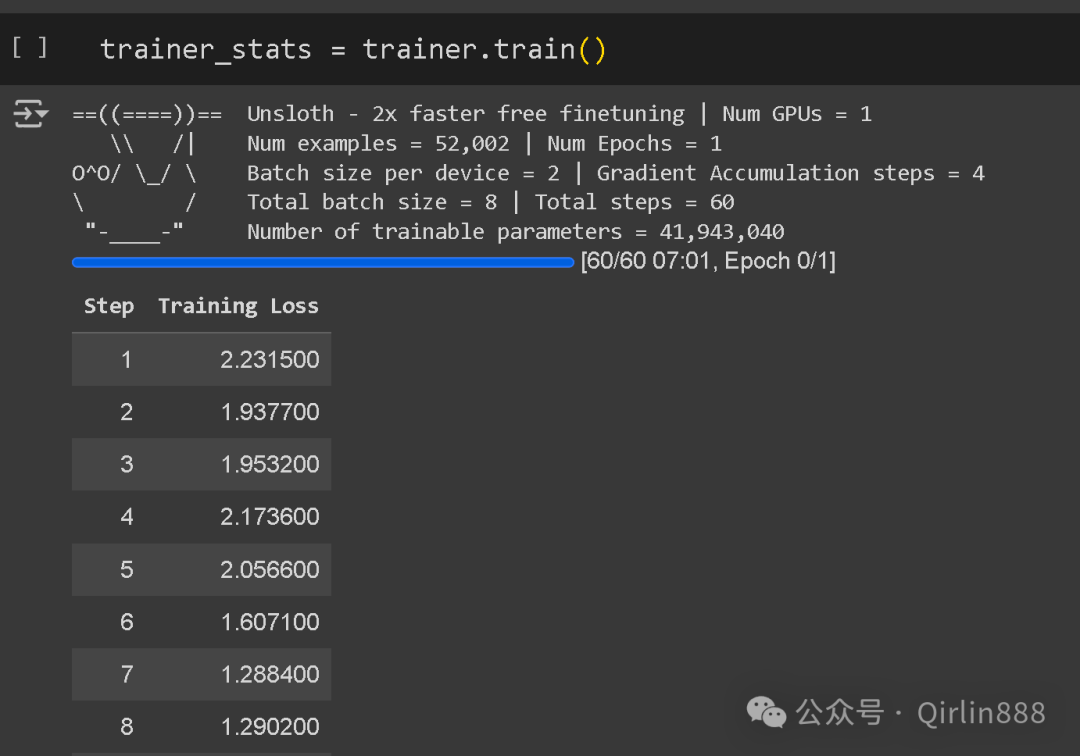
# 什么Training Loss
是指在模型训练过程中,模型在训练数据集上的损失值,用于衡量模型预测结果与实际标签之间的差异
Evaluation 评估
● 导出及合并微调模型
模型保存本地
model.save_pretrained_merged("merged_model", tokenizer, save_method = "merged_16bit",) # 16位格式保存
使用终端执行
git clone --recursive https://github.com/ggerganov/llama.cpp
make clean -C llama.cpp
make all -j -C llama.cpp
pip install gguf protobuf
python llama.cpp/convert-hf-to-gguf.py FOLDER --outfile OUTPUT --outtype f16
总结和对比
微调、RAG和蒸馏的对比和区别

如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)