论文速报《端到端自动驾驶真的需要感知任务吗?》
不得不感叹的是,自动驾驶行业的技术的发展日新月异,技术热点已经从BEV迅速地转移到了端到端上。不管如何看待端到端,最近一年端到端的火热已经切实影响到了这个行业的每一个人。相比于在紧锣密鼓恶补各种模型知识的传统规划的工程师而言,大家似乎往往默认感知算法工程师在端到端时代是有优势的。
论文链接:https://arxiv.org/abs/2409.18341
代码链接:https://github.com/PeidongLi/SSR
1. 简介
不得不感叹的是,自动驾驶行业的技术的发展日新月异,技术热点已经从BEV迅速地转移到了端到端上。不管如何看待端到端,最近一年端到端的火热已经切实影响到了这个行业的每一个人。相比于在紧锣密鼓恶补各种模型知识的传统规划的工程师而言,大家似乎往往默认感知算法工程师在端到端时代是有优势的。《DOES END-TO-END AUTONOMOUS DRIVING REALLY NEED PERCEPTION TASKS》发现很多人还是做着和以前类似的工作,专注于某个感知task来提升端到端性能,忽略了端到端时代下真正的感知红利。\
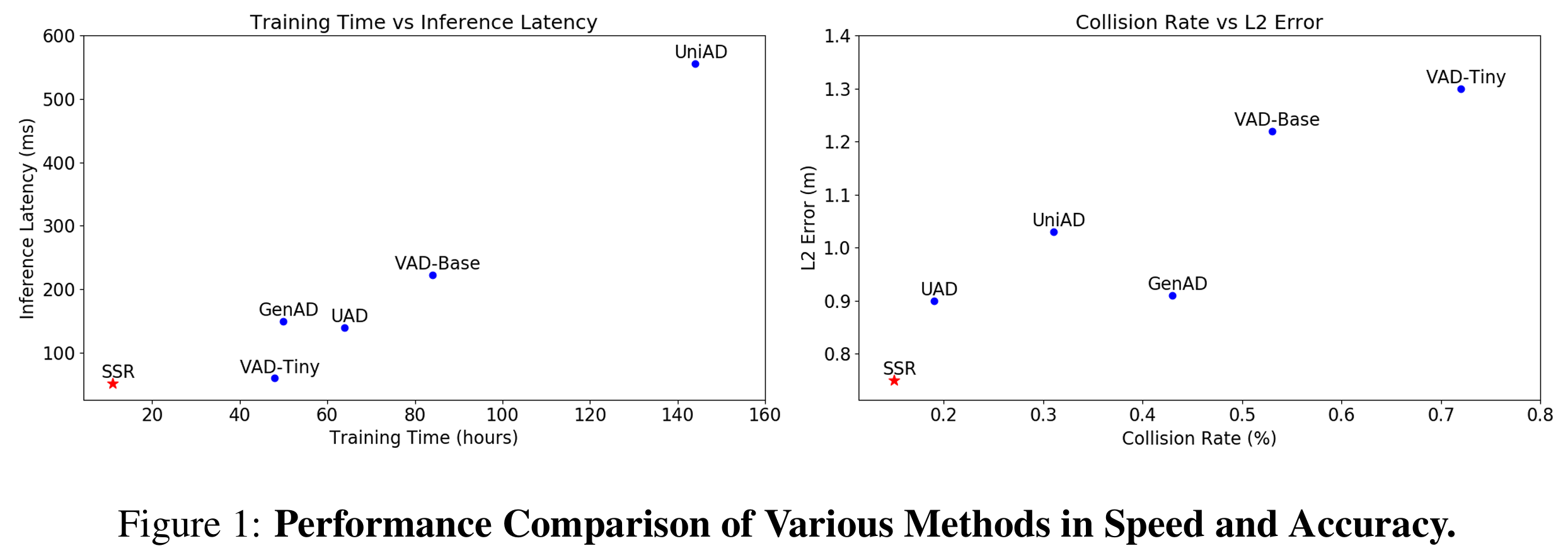
图1:各种方法在速度和准确性上的性能比较
2. 主要贡献
-
人机启发的端到端自适应驾驶框架:我们提出了一种人机启发的端到端自适应驾驶(E2EAD)框架,该框架利用导航指令引导的稀疏查询表示,有效地减少了计算成本。通过自适应地聚焦于场景中的关键部分,该方法显著提升了效率。
-
强调时间上下文的重要性:我们引入了一种BEV世界模型,利用自监督学习来应对动态场景变化,从而强调了时间上下文在自动驾驶中的关键作用。这一创新消除了对高成本的感知任务监督的需求,提升了模型的灵活性和适应性。
-
卓越的性能表现:在nuScenes数据集上,我们的框架达到了最先进的性能,同时保持了最低的训练和推理成本,为实时端到端自适应驾驶设立了新的基准。这一成果展示了该框架在实际应用中的巨大潜力。
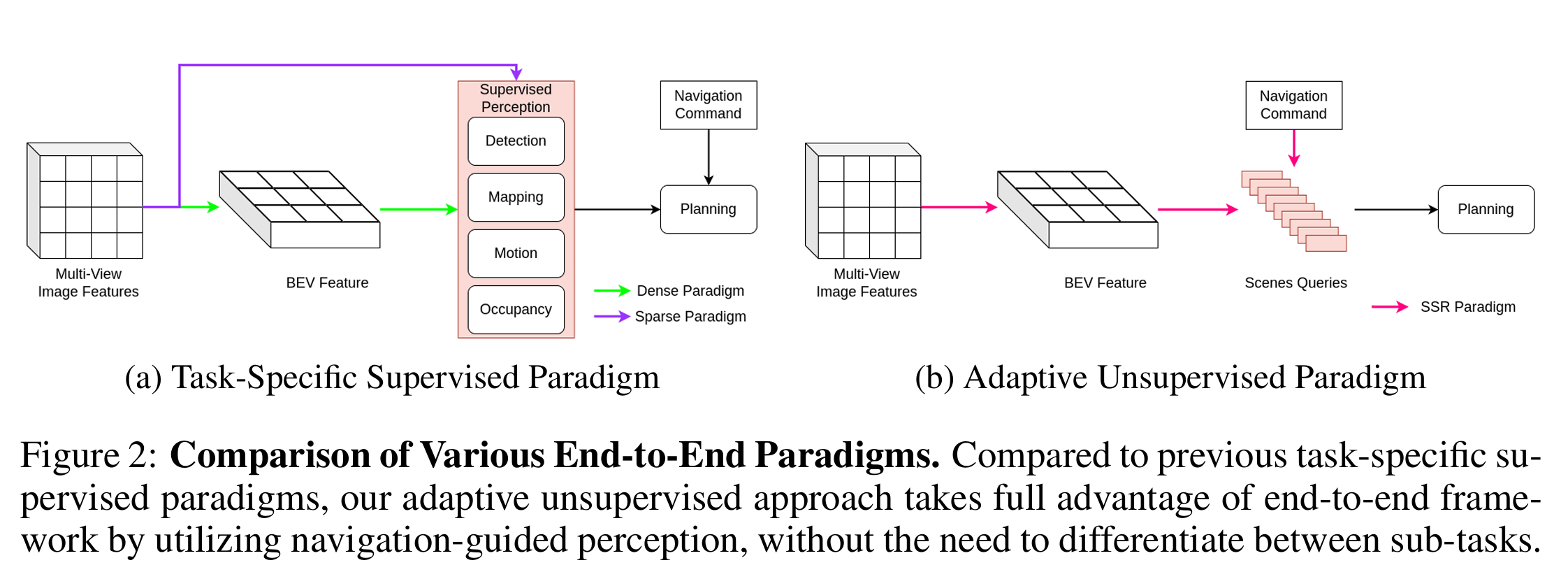
图2:各种端到端范式的比较。与以往的任务特定监督范式相比,我们的自适应无监督方法充分利用了端到端框架,通过导航引导的感知,消除了对子任务进行区分的需求
3. 核心算法
本文提出的核心算法主要由以下几个模块组成: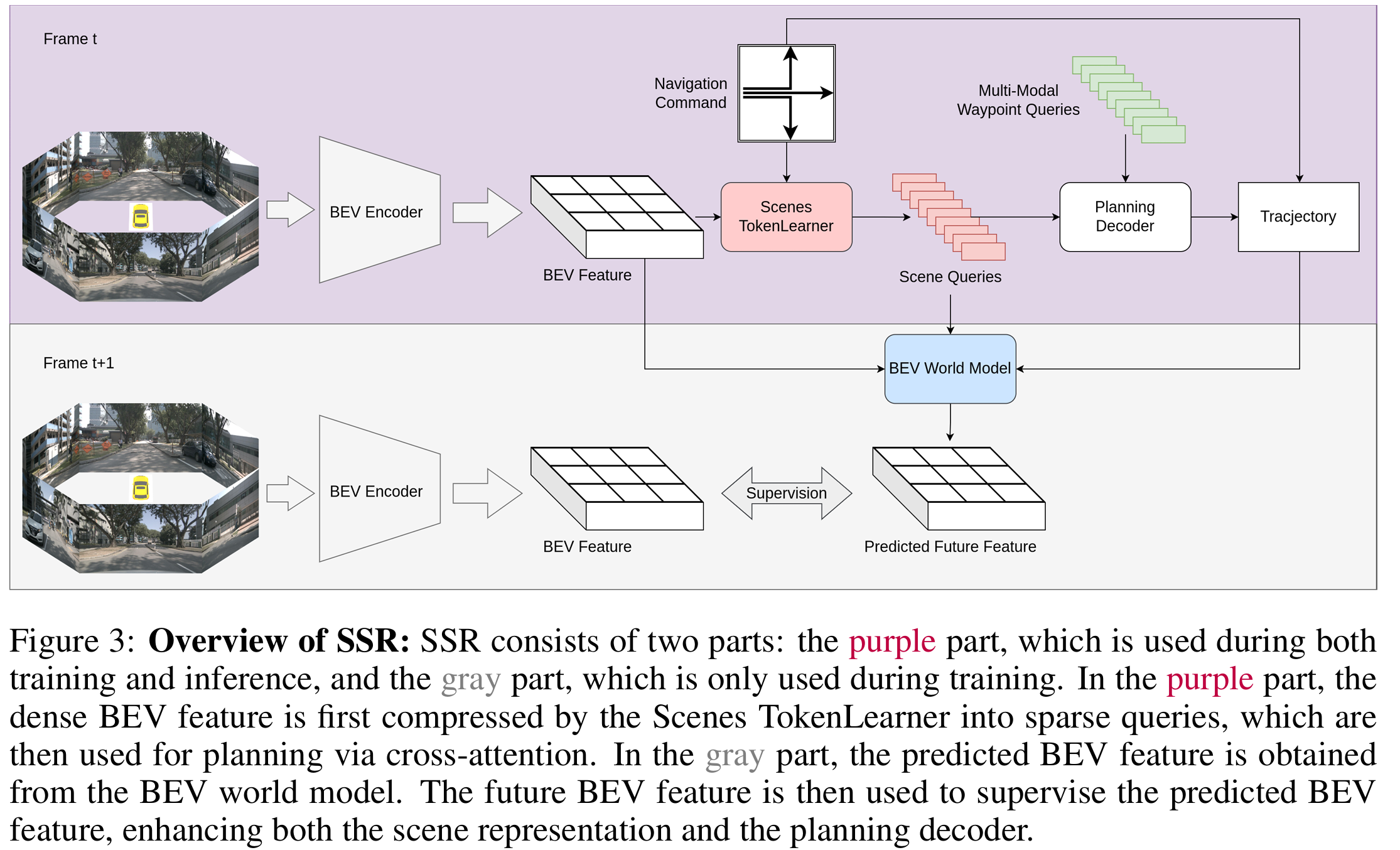
图3:SSR概述。SSR由两个部分组成:紫色部分在训练和推理过程中均使用,而灰色部分仅在训练过程中使用。在紫色部分,密集的鸟瞰视图(BEV)特征首先通过场景TokenLearner压缩为稀疏查询,然后通过交叉注意力用于规划。在灰色部分,预测的BEV特征是从BEV世界模型中获得的。随后,未来的BEV特征被用来监督预测的BEV特征,从而增强场景表示和规划解码器
3.1 问题表述
在时刻 t t t,给定周围的 N N N 个视角的摄像头图像 I t = [ I i t ] i = 1 N I_t = [I_i^t]_{i=1}^N It=[Iit]i=1N 和高层次的导航指令 c m d cmd cmd,基于视觉的端到端自适应驾驶(E2EAD)模型旨在预测规划轨迹 T T T,该轨迹由一组在鸟瞰视图(BEV)空间中的点组成。
3.2 BEV特征构建
首先,多个摄像头图像通过 BEV 编码器进行处理,以生成 BEV 特征。这一过程的第一步是使用图像特征提取网络提取图像特征 F t = [ F i t ] i = 1 N F_t = [F_i^t]_{i=1}^N Ft=[Fit]i=1N。接下来,模型使用一个 BEV 查询 Q Q Q 来从前一帧的 BEV 特征 B t − 1 B_{t-1} Bt−1 中查询时间信息,并通过交叉注意力机制与当前帧的图像特征 F t F_t Ft 进行融合,从而生成当前的 BEV 特征 B t B_t Bt。这个过程通过交叉注意力的迭代计算实现,为获取更精准的场景信息打下基础。
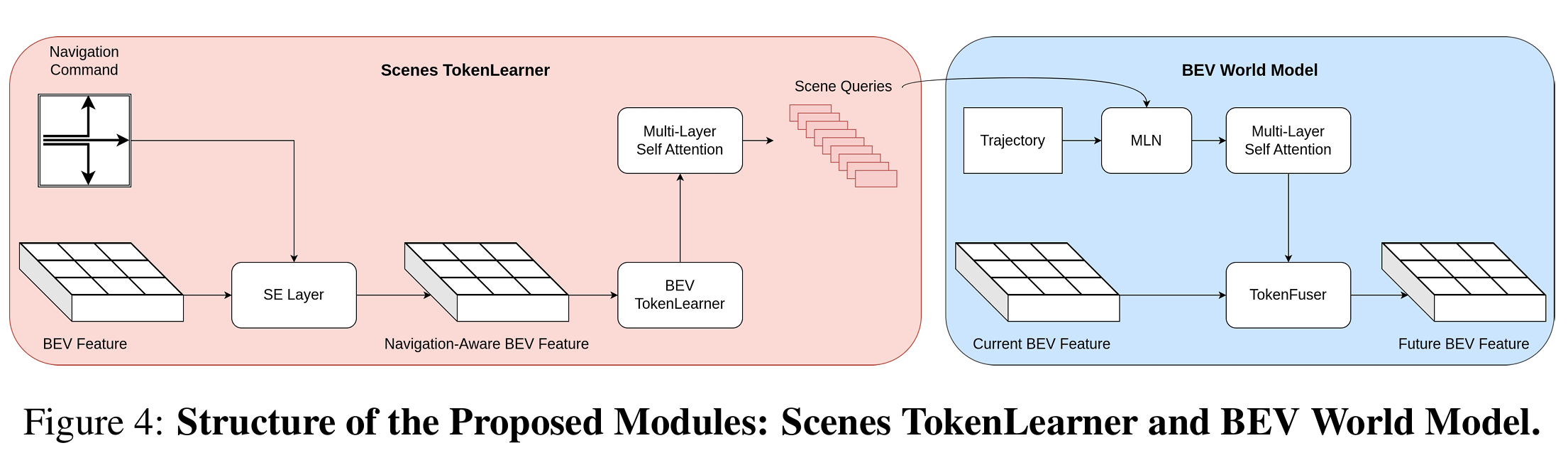
图4:所提模块的结构:场景TokenLearner和BEV世界模型
3.3 导航引导场景令牌学习器
为了有效提取场景信息,我们引入了场景令牌学习器(Scenes TokenLearner, STL)模块。该模块使用自适应空间注意力机制,构建稀疏的场景表示,显著减少计算负载,同时保持高保真度的场景理解。具体来说,STL 模块从 BEV 特征中提取场景查询,通过编码导航指令 c m d cmd cmd 来生成导航感知的 BEV 特征。接着,将这些特征传递给 BEV 令牌学习器(BEV TokenLearner),该模块通过空间注意力机制聚焦于最重要的信息,最终生成稀疏的场景表示。
3.4 基于稀疏场景表示的规划
利用提取的稀疏场景表示 S t S_t St,模型使用一组路径点查询 W t W_t Wt 来提取多模态的规划轨迹。通过交叉注意力机制,模型结合场景信息和路径点查询,生成预测的轨迹。最终,利用多层感知机(MLP)从中选择出符合导航指令的输出轨迹。
3.5 基于BEV世界模型的时间增强
为了进一步提升场景表示,模型引入了 BEV 世界模型(BEV World Model)。该模块的核心思想是,若预测的动作与实际动作相符,则预测的未来场景应与实际未来场景相似。通过运动感知层归一化(MLN),将当前场景查询转换为未来帧的查询。随后,应用多层自注意力机制预测未来的场景查询。为了恢复从预测场景查询中生成的稠密 BEV 特征,采用令牌融合(TokenFuser)模块,增强模型的自监督学习能力。
4. 实验结果
我们设计的SSR框架,最终仅用16个自监督可学习的query来作为场景的高效稀疏表征,代替了传统端到端方案里成百上千个人为定义并标注监督的query,使得感知模块终于从handcrafted perception task解脱出来。在nuScenes和Carla上我们分别进行了开环和闭环实验, 对比了大量SOTA方案甚至包括arxiv上还未正式发表的工作,都实现了效率和性能上的大幅超越。
图5:场景查询的BEV注意力图可视化。展示了16个学习到的token中8个的注意力图。自我车辆位于中心位置,向上方向表示自我车辆的前方。较亮的区域代表更高的注意力权重。完整的集合见附录A.1。
图6:不同场景中的SumAttention图。FR:帧编号。
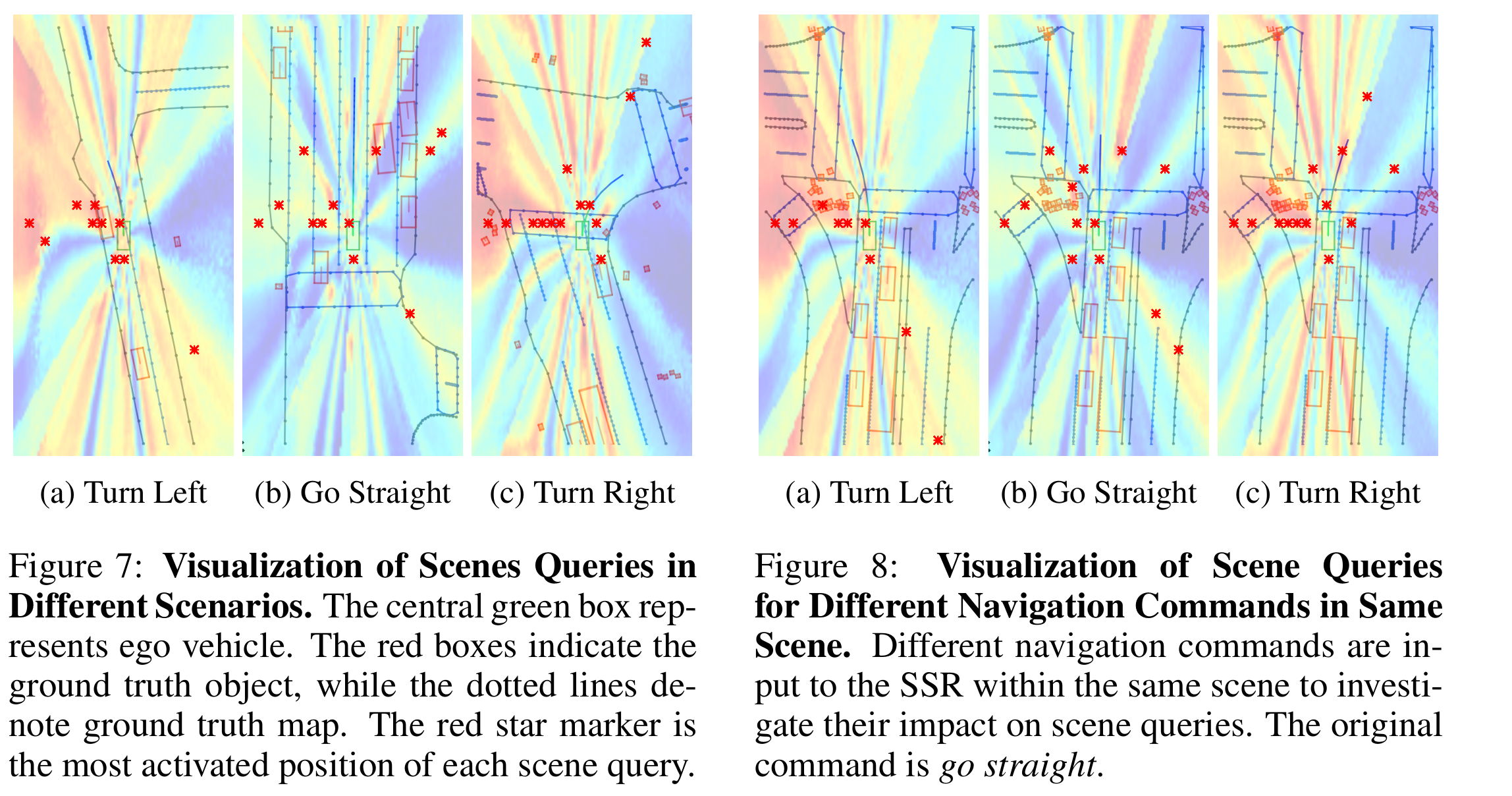
图7:不同场景中场景查询的可视化。中央的绿色框代表自我车辆。红色框表示真实物体,而虚线则表示真实地图。红色星形标记是每个场景查询的最活跃位置。
图8:同一场景中不同导航命令的场景查询可视化。不同的导航命令被输入到同一场景中的SSR,以研究它们对场景查询的影响。原始命令为“直行”。

图9:规划结果的可视化。感知结果是根据标注渲染而成的。
5. 参考链接
https://zhuanlan.zhihu.com/p/14173403896
为了充分利用公众号的碎片化时间,我们精心整理了经典博客文章、面试经验和一线开源项目等优质内容,并进行系统化的分享。这些资源不仅涵盖了前沿技术和行业动态,还提供了实用的学习和实战经验,使读者能够在短时间内快速获取有价值的信息。通过这种方式,我们希望帮助大家在忙碌的生活中有效利用零散时间,持续补充和深化知识,提升自身的专业素养和竞争力。无论是在通勤途中还是闲暇时光,都能轻松获取知识,助力个人成长。可以点击下面的图标关注公众号↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)