近期热点论文精选速览
2.17-2.23大模型领域热点论文精选速览
最近能明显感觉到大模型发展日新月异,一周不追踪业内最新动态,自己的知识储备就已经落后了,以后每周都会将最近最新的一些热点论文进行汇总,内容涵盖论文大纲+创新点总结+实验效果,旨在快速了解最新的技术,会对其中重要的论文另外展开详细解读。
上周有好几篇大热门论文发布,值得关注哦~
1. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
第一篇来自DeepSeek的最新力作,提出了全新的注意力机制,详细解读可以看之前的文章,DeepSeek发布新的注意力机制NSA(论文详解)
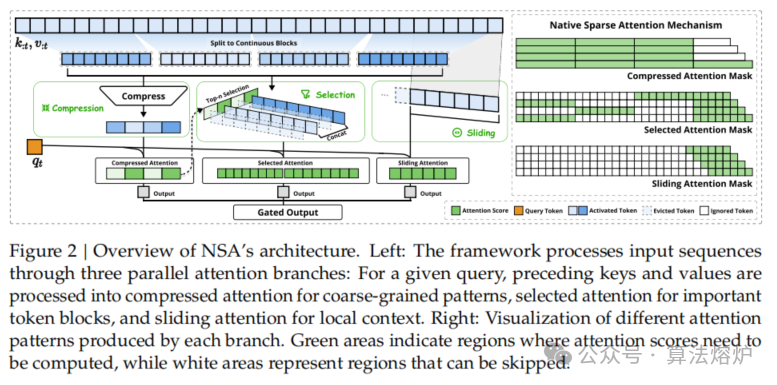
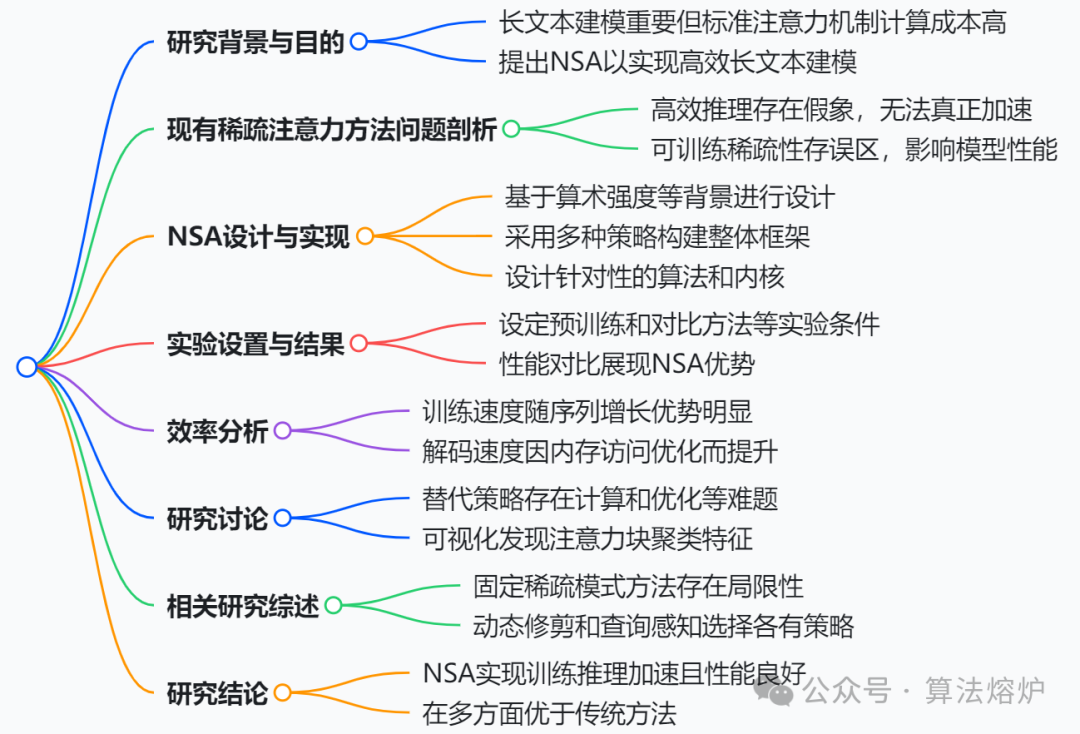
长上下文建模对于下一代语言模型至关重要,然而标准注意力机制的高计算成本带来了巨大的计算挑战。稀疏注意力为在保持模型能力的同时提高效率提供了一个有前景的方向。提出了原生可训练稀疏注意力机制(NSA),它将算法创新与硬件适配优化相结合,以实现高效的长上下文建模。NSA采用动态分层稀疏策略,将粗粒度token压缩与细粒度token选择相结合,既保留了全局上下文感知,又保证了局部精度。
通过两项关键创新推进了稀疏注意力设计:
(1)通过算术强度平衡的算法设计,并针对现代硬件进行实现优化,我们实现了显著的加速。
(2)我们实现了端到端训练,在不牺牲模型性能的情况下减少了预训练计算量。
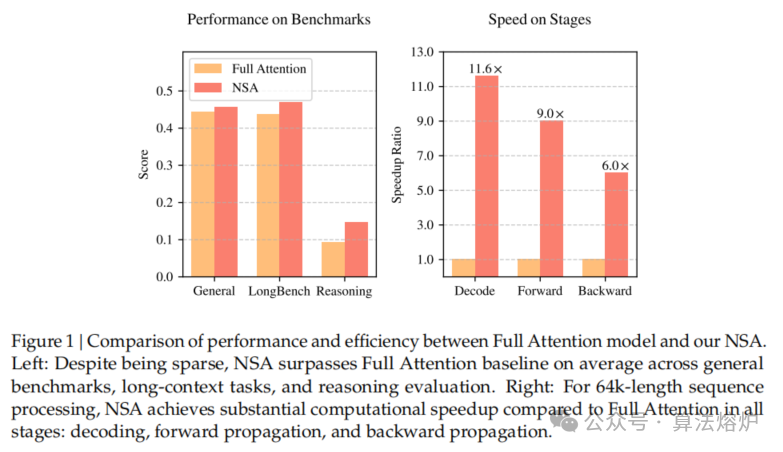
如图1所示,实验表明,使用NSA预训练的模型在通用基准测试、长上下文任务和基于指令的推理中,性能与全注意力模型相当甚至超越。同时,在处理64k长度序列时,NSA在解码、前向传播和反向传播方面比全注意力机制实现了大幅加速,验证了其在模型整个生命周期中的高效性。
模型/框架结构
论文大纲
创新点总结
论文提出了原生可训练的稀疏注意力机制 NSA,将算法创新与硬件优化相结合,实现高效长文本建模,主要贡献体现在方法改进、性能提升、效率优化等方面。
- 创新稀疏注意力机制设计:提出 NSA,融合动态分层稀疏策略,结合粗粒度令牌压缩和细粒度令牌选择,兼顾全局上下文感知与局部精度,改进了传统稀疏注意力设计。通过将键值对重映射,设计了令牌压缩、选择和滑动窗口三种策略,构建了完整的算法框架。
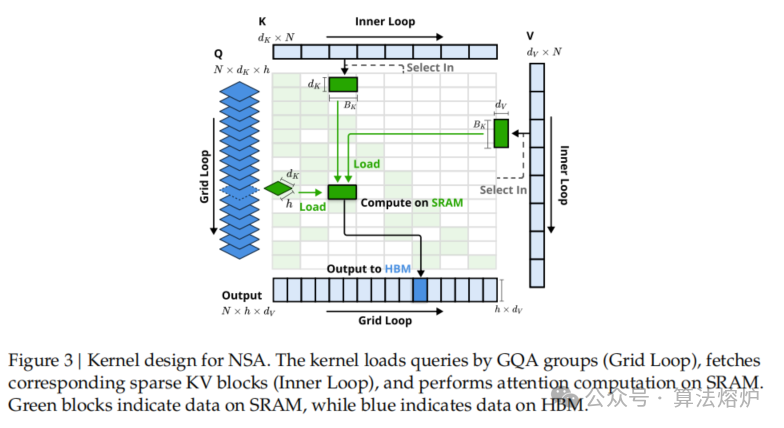
- 实现硬件对齐与训练感知优化:从硬件对齐系统和训练感知设计两方面优化。针对现代硬件优化块稀疏注意力,平衡算术强度,提高硬件利用率;设计高效算法和反向算子,实现稳定的端到端训练,减少预训练计算量且不牺牲模型性能。
- 提升模型性能表现:在多个基准测试中,NSA 预训练模型性能与全注意力模型相当甚至超越。在通用基准测试、长上下文任务和基于指令的推理任务中表现出色,尤其在推理相关基准测试中有显著提升,验证了其作为通用架构的稳健性。
- 显著提高计算效率:在处理 64k 长度序列时,NSA 在解码、前向传播和反向传播阶段均比全注意力机制有大幅加速,且序列越长加速比越高。训练阶段 64k 上下文长度下,前向加速达 9.0 倍,反向加速达 6.0 倍;解码阶段在 64k 上下文长度下,速度提升最高可达 11.6 倍。
实验效果
论文链接:https://arxiv.org/pdf/2502.11089
2. Qwen2.5-VL Technical Report
这一篇则是阿里最新最强的多模态大模型Qwen2.5-VL的技术报告。
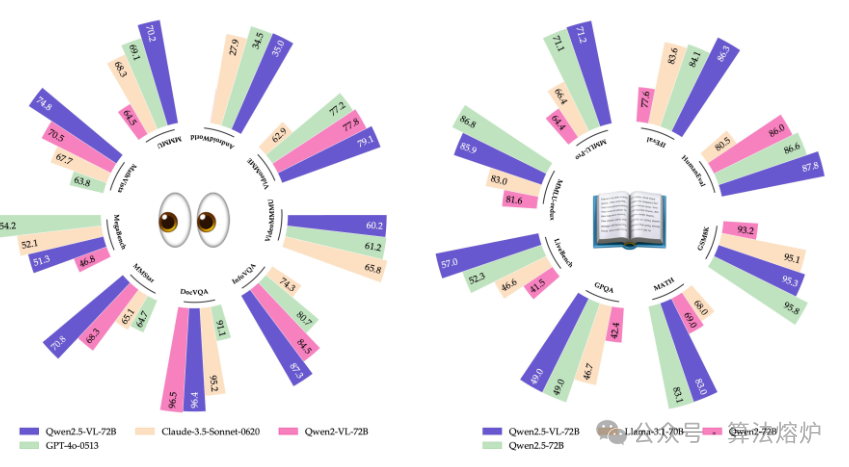
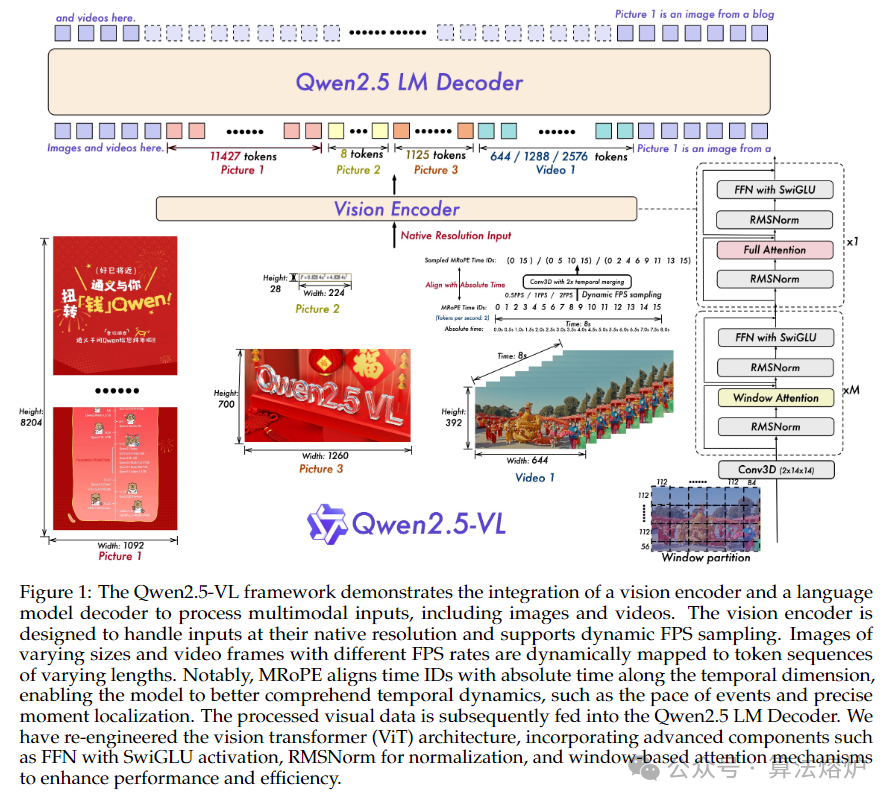
Qwen2.5-VL是通义千问视觉语言系列的最新旗舰模型,在基础能力和创新功能方面均取得了重大进展。Qwen2.5-VL通过增强视觉识别、精确目标定位、强大的文档解析和长视频理解能力,在理解世界和与世界交互方面实现了重大飞跃。Qwen2.5-VL的一个突出特点是能够使用边界框或点精确地定位物体。它可以从发票、表格中可靠地提取结构化数据,还能对图表、示意图和布局进行详细分析。为处理复杂输入,Qwen2.5-VL引入了动态分辨率处理和绝对时间编码,使其能够处理不同大小的图像和较长时长(长达数小时)的视频,并能定位到秒级别的事件。这使得该模型无需依赖传统归一化技术,就能自然地感知空间尺度和时间动态。通过从头开始训练原生动态分辨率视觉Transformer(ViT)并融入窗口注意力机制,我们在保持原生分辨率的同时显著降低了计算成本。因此,Qwen2.5-VL不仅在静态图像和文档理解方面表现出色,还能作为交互式视觉智能体,在操作计算机和移动设备等现实场景中进行推理、使用工具和执行任务。该模型无需特定任务的微调,就能在不同领域实现强大的泛化能力。Qwen2.5-VL有三种规模版本,可满足从边缘人工智能到高性能计算的各种应用场景。旗舰版本Qwen2.5-VL-72B与GPT-4o和Claude 3.5 Sonnet等最先进的模型性能相当,在文档和图表理解方面尤为出色。较小的Qwen2.5-VL-7B和Qwen2.5-VL-3B模型性能优于同类竞品,即使在资源受限的环境中也能提供强大的功能。此外,Qwen2.5-VL还保持了强大的语言性能,保留了Qwen2.5大语言模型的核心语言能力。
模型/框架结构
论文大纲
创新点总结
Qwen2.5-VL 在模型架构、处理能力、数据和训练等方面进行创新,提升性能和泛化能力,在多领域任务表现出色,为视觉语言模型发展提供新方向。
1. 模型架构创新:重新设计 Vision Transformer(ViT)架构,在视觉编码器中引入窗口注意力机制,多数层使用窗口注意力,仅四层采用全自注意力,减少计算量且保持输入分辨率,提升计算效率。采用 2D-RoPE 进行位置编码,有效捕捉 2D 空间中的空间关系,并扩展到 3D 补丁分区处理视频数据。同时,采用 RMSNorm 进行归一化和 SwiGLU 作为激活函数,增强计算效率和模型组件间的兼容性。
2. 处理能力创新:提出动态分辨率处理和绝对时间编码,在空间维度直接使用输入图像实际尺寸表示空间特征,让模型学习尺度信息;在时间维度通过动态帧率(FPS)训练和绝对时间编码,适应可变帧率,将 MRoPE ID 与时间戳对齐,理解时间节奏,无需额外计算开销,实现对不同尺寸图像和长时间视频的处理,并能进行秒级事件定位。
3. 数据和训练创新:大幅扩展预训练数据规模,从 1.2 万亿 token 增加到约 4 万亿 token。精心构建多模态预训练数据集,涵盖多种数据类型,并对数据进行清洗和筛选。开发数据评分和清洗流程,提高交错图像文本数据质量;使用基于绝对位置坐标的定位数据训练,提升模型对世界的感知能力;合成多种文档数据,统一文档元素格式;收集和整理多源 OCR 数据,增强多语言能力;动态采样视频 FPS,构建长视频字幕。采用多阶段预训练策略,分阶段使用不同数据配置和训练策略,逐步提升模型能力。设计双阶段优化的后训练对齐框架,通过监督微调(SFT)和直接偏好优化(DPO),使模型更好地适应下游任务和符合人类偏好。
实验效果
论文链接:https://arxiv.org/pdf/2502.13923
3. Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
这一篇则是阶跃最新发布的Step-Video-T2V技术报告,目前业内最强大的视频生成大模型。
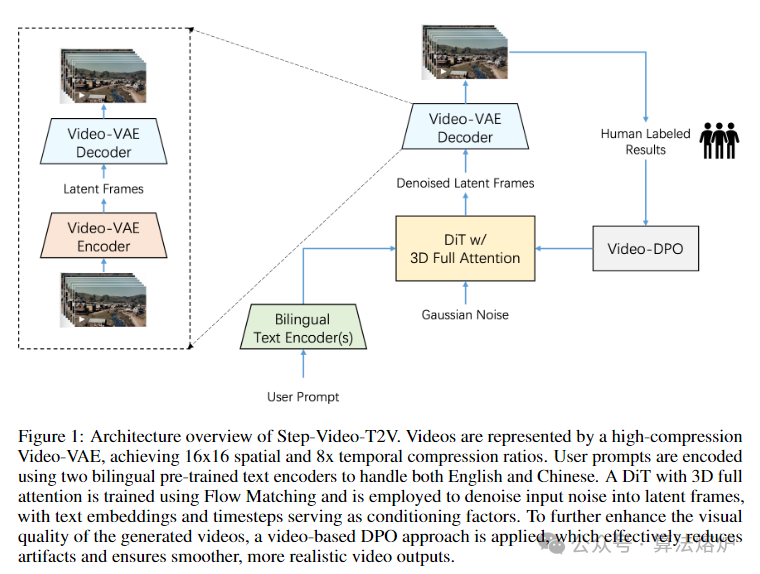
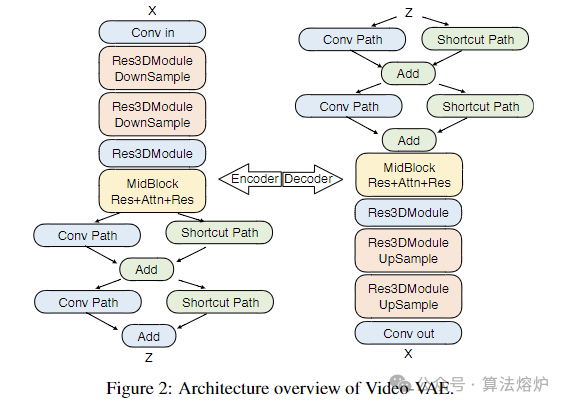
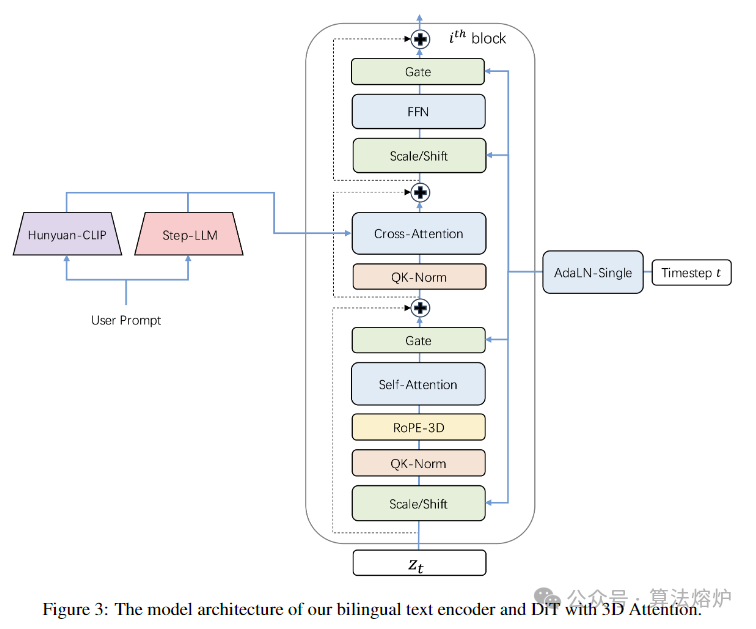
Step-Video-T2V是一款先进的文本转视频预训练模型,拥有 300 亿参数,能够生成长达 204 帧的视频。为视频生成任务专门设计的深度压缩变分自编码器 Video-VAE,实现了 16×16 的空间压缩比和 8 倍的时间压缩比,同时保持了出色的视频重建质量。用户输入的提示词由两个双语文本编码器进行编码,以便处理英文和中文内容。通过流匹配(Flow Matching)训练具有 3D 全注意力机制的扩散 Transformer(DiT),将输入噪声转换为潜在帧以实现去噪。基于视频的直接偏好优化方法 Video-DPO 被应用于减少生成视频中的伪影,提升视觉质量。还详细介绍了训练策略,并分享了关键的观察结果和见解。
Step-Video-T2V 的性能在一个全新的视频生成基准测试 Step-Video-T2VEval 上进行评估。与开源和商业模型相比,它展现出了顶尖的文本转视频质量。此外还探讨了当前基于扩散模型范式的局限性,并勾勒出视频基础模型未来的发展方向。
模型在https://github.com/stepfun-ai/Step-Video-T2V上开源,线版本可以通过https://yuewen.cn/videos访问。
模型/框架结构
论文大纲

创新点总结
论文介绍了视频生成预训练模型Step-Video-T2V,在模型架构、训练策略、系统优化、数据处理和评估方式等方面进行创新,提升了视频生成质量和效率,推动视频基础模型发展。
1. 创新视频VAE架构:提出用于视频生成的深度压缩Video-VAE,采用独特双路径架构,在编码器后期和解码器早期实现统一时空压缩,通过3D卷积和优化像素重排操作,达到16x16空间和8x时间压缩比,在减少计算复杂度的同时,保持卓越的视频重建质量,为大规模视频生成训练奠定基础。
2. 双文本编码器协同:使用Hunyuan-CLIP和Step-LLM两个双语文本编码器处理用户提示。Hunyuan-CLIP能生成与视觉空间对齐的文本表示,Step-LLM无输入长度限制,二者结合可处理不同长度提示,生成稳健文本表示,有效引导模型在潜在空间生成视频。
3. 优化训练与评估策略:采用级联训练策略,包括文本到图像预训练、文本到视频/图像预训练、文本到视频微调以及直接偏好优化训练。各阶段逐步提升模型能力,如文本到图像预训练帮助模型获取视觉知识,为后续训练打基础。构建新的视频生成基准测试Step-Video-T2V-Eval,包含128个来自真实用户的中文提示,涵盖11个类别,并提出两个基于此基准的人工评估指标,更全面准确地评估模型性能。
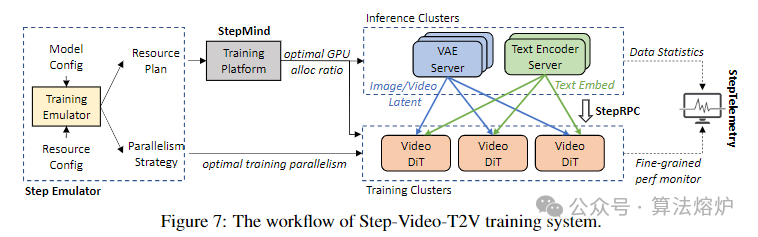
4. 系统层面优化创新:开发Step Emulator模拟器,可在不同模型架构和并行策略配置下,估计训练时的资源消耗和端到端性能,辅助设计模型参数、架构及确定资源分配和并行策略。优化分布式训练,采用8路张量并行(TP)结合序列并行(SP)和Zero1的策略,并开发StepCCL通信库实现通信计算重叠,提升训练效率。同时,提出DP重叠策略减少特定阶段的训练时间。针对VAE、DiT等模块进行计算和通信优化,如在VAE中采用通道最后原则加速卷积运算,开发自定义RoPE-3D内核优化DiT中的操作,降低内存使用和计算成本。设计混合粒度负载均衡策略,通过调整不同分辨率视频的批次大小和图像填充,平衡计算负载,减少GPU资源闲置。
5. 数据处理创新:构建大规模视频数据集,包含20亿视频-文本对和38亿图像-文本对,并通过视频分割、质量评估、运动评估、字幕标注、概念平衡和视频-文本对齐等一系列处理,为模型训练提供高质量数据。在数据处理过程中,采用多种评估指标和方法,如使用LAION CLIP-based审美预测器计算审美分数、利用光流算法计算运动分数等,全面评估视频质量和内容。
实验效果

论文链接:https://arxiv.org/pdf/2502.10248
4. MLGym: A New Framework and Benchmark for Advancing AI Research Agents
这篇论文来自meta发布的AI Agent领域的全新框架和基准测试平台。
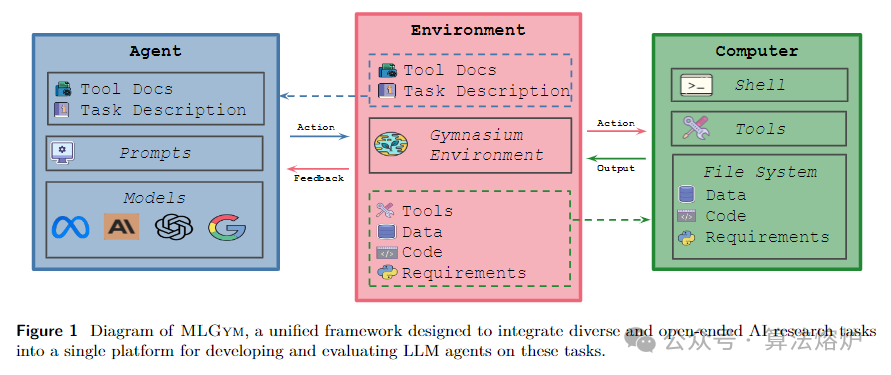
推出了Meta MLGym和MLGym-Bench,这是一个用于在人工智能研究任务上评估和开发大语言模型(LLM)智能体的全新框架和基准测试平台。这是首个面向机器学习(ML)任务的Gym环境,有助于开展用于训练此类智能体的强化学习(RL)算法的相关研究。MLGym-Bench包含13个丰富多样且开放式的人工智能研究任务,这些任务来自计算机视觉、自然语言处理、强化学习和博弈论等不同领域。解决这些任务需要具备实际的人工智能研究技能,比如提出新想法和假设、创建和处理数据、实施机器学习方法、训练模型、进行实验、分析结果,以及通过迭代这个过程来改进给定的任务。 我们在自己的基准测试中评估了多个前沿大语言模型,如Claude-3.5-Sonnet、Llama-3.1 405B、GPT-4o、o1-preview和Gemini-1.5 Pro。MLGym框架便于添加新任务、集成和评估模型或智能体、大规模生成合成数据,以及开发用于在人工智能研究任务上训练智能体的新学习算法。当前的前沿模型通常可以通过找到更好的超参数来改进给定的基线,但它们无法提出新颖的假设、算法、架构,也没有带来实质性的改进。 开源这个框架和基准测试平台以推动未来在提升大语言模型智能体的人工智能研究能力方面的相关研究。
模型/框架结构
论文大纲

创新点总结
这篇论文聚焦于AI研究中LLM智能体的评估与开发,核心创新围绕框架、基准测试、评估方法展开,为该领域提供了新的研究工具与思路,推动LLM智能体在AI研究中的发展,具体如下:
1. 创新框架设计:提出Meta MLGym,作为首个针对AI研究任务的Gym环境,为训练LLM智能体的强化学习算法研究提供便利。其模块化设计,使研究人员能便捷地添加新任务、集成和评估模型或智能体、大规模生成合成数据,以及开发新的学习算法。通过统一框架整合多样AI研究任务,将LLM智能体与环境交互抽象为Gym标准接口,降低研究门槛,提高实验效率与可重复性,为相关研究提供了通用、灵活的基础平台。
2. 构建新型基准测试:创建MLGym-Bench基准测试集,包含13个来自计算机视觉、自然语言处理、强化学习和博弈论等多领域的开放式研究任务。这些任务模拟真实AI研究场景,要求模型具备生成想法、处理数据、实施方法、训练模型、分析结果等实际科研技能,拓展了LLM智能体框架和基准测试所涉及的问题范围,能更全面地评估智能体在复杂、开放任务中的表现。
3. 引入新评估指标:提出基于性能轮廓曲线(Performance Profiles)和AUP分数的评估指标。该指标改进了传统简单聚合分数或排名的方式,能有效处理不同任务具有不同性能指标的情况,更公平地比较LLM智能体在多种任务上的相对性能提升,从多个维度评估模型的能力,包括最佳提交能力和最佳尝试能力,为模型性能评估提供了更全面、准确的依据。
实验效果

论文链接:https://arxiv.org/pdf/2502.14499
5. MoBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMs
这篇论文则是来自月之暗面的,同样提出了一种针对长文本大模型的注意力机制,与DeepSeek的NSA在同一天发表,热度少了些许。
扩大大语言模型(LLMs)的有效上下文长度对于推动其向通用人工智能(AGI)发展至关重要。然而,传统注意力机制固有的计算复杂度呈二次方增长,这带来了过高的计算开销。现有方法要么采用强偏向性的结构,如针对特定任务的汇聚式(sink)或窗口注意力机制,要么将注意力机制彻底修改为线性近似,但其在复杂推理任务中的性能仍有待充分探索。 在这项工作中,我们提出了一种遵循 “少结构 ”原则的解决方案,让模型自主决定关注的重点,而不是引入预定义的偏差。我们引入了块注意力混合(MoBA)机制,这是一种创新方法,将专家混合(MoE)原理应用于注意力机制。这种新颖的架构在长上下文任务中表现出色,并且具有一个关键优势:能够在全注意力和稀疏注意力之间无缝切换,在不牺牲性能的前提下提高效率。MoBA已经应用于支持Kimi的长上下文请求,展现出在大语言模型高效注意力计算方面的重大进展。代码在https://github.com/MoonshotAI/MoBA上开源。
模型/框架结构
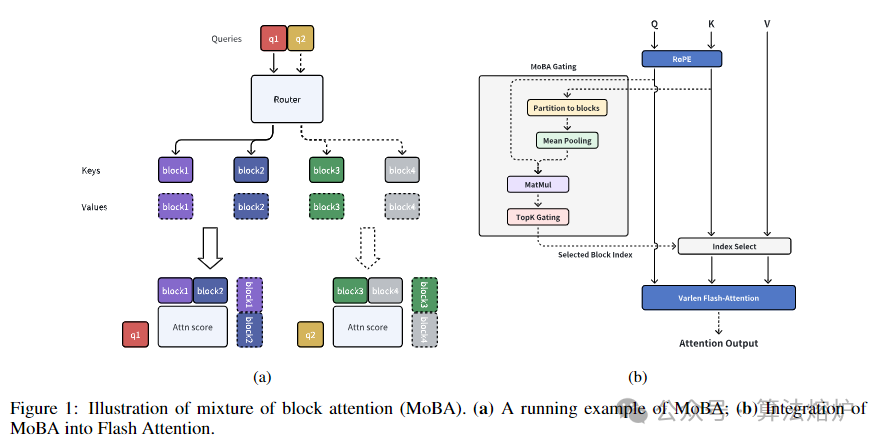

论文大纲
创新点总结
论文旨在解决大语言模型处理长上下文时传统注意力机制计算复杂度过高的问题。其核心创新在于设计了MoBA注意力架构,为提升大语言模型在长文本处理方面的效率和性能提供了新的思路和方法。
1. 创新的块注意力混合机制:提出MoBA,将MoE原理应用于注意力机制,把上下文划分为块,让查询令牌动态选择相关的键值块。与传统注意力机制不同,它允许模型自主确定关注重点,而非依赖预定义结构,使模型能更高效地处理长序列,减少计算负担。
2. 无参数门控机制:引入无参数的top-k门控机制,为每个查询令牌选择最相关的块。该机制能让模型聚焦于最具信息的块,避免无效计算,在不增加额外参数的情况下提高模型性能,增强了模型的适应性和效率。
3. 全注意力和稀疏注意力无缝切换:可在全注意力和稀疏注意力模式间灵活切换。在初始化或训练过程中,各注意力层能根据需求选择注意力模式,这种灵活性在长上下文预训练和微调阶段优势显著,能平衡训练效率和模型性能,提升模型整体表现。
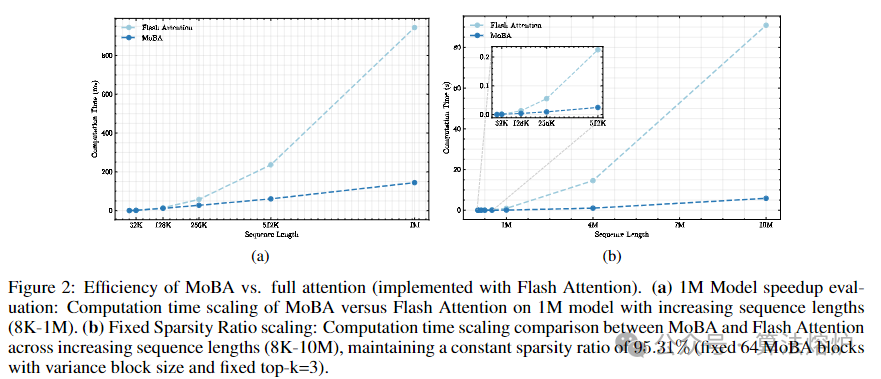
4. 计算效率提升显著:在多个实验中展现出优异的计算效率。如在与Llama - 8B - 1M - Full模型对比时,MoBA在不同上下文长度下都更高效,处理1M令牌时加速比可达6.5倍,处理10M令牌时注意力计算时间减少16倍,且随着序列增长,优势更明显。
实验效果
论文链接:https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
上周新鲜出炉了很多精彩论文,本周又迎来了DeepSeek的开源周,精彩继续~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 59
59 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)