
二维随机变量
本文深入解析二维随机变量的核心概念与机器学习实战应用,通过Python代码实现联合分布分析、条件概率建模及特征相关性可视化,结合金融风控、图像处理等案例,揭秘多维数据分析的关键技术,提供可直接复用的实战代码与协方差矩阵计算方法。
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
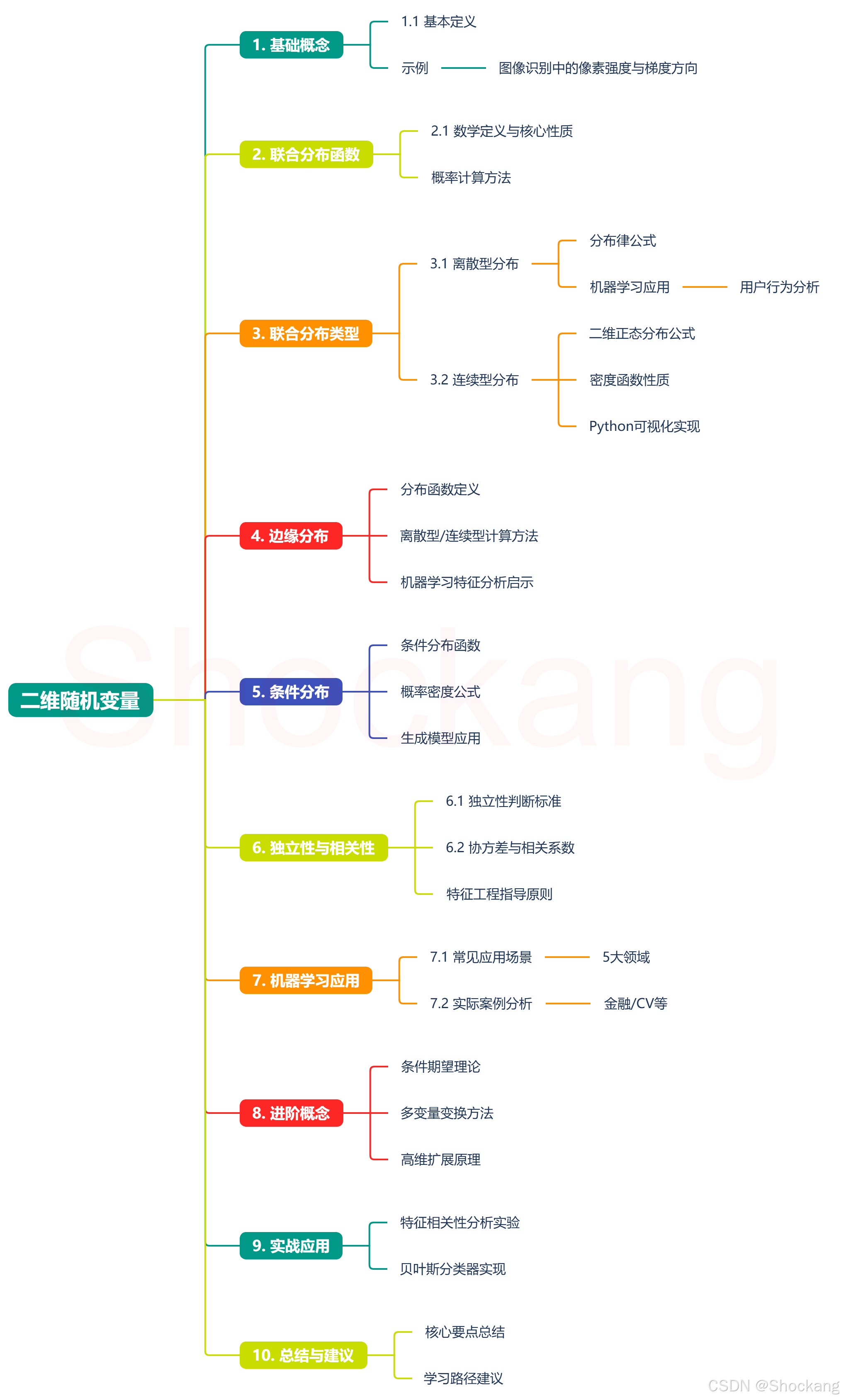
1. 二维随机变量基础 🌟
1.1 基本定义
- 二维随机变量 ( X , Y ) (X, Y) (X,Y) 是由两个定义在同一概率空间上的随机变量 X X X 和 Y Y Y 组成的向量
- 样本空间:每个试验结果 e ∈ S e \in S e∈S 对应到平面上的一个点 ( X ( e ) , Y ( e ) ) (X(e), Y(e)) (X(e),Y(e))
🔍 机器学习视角:特征向量中的任意两个特征可视为二维随机变量,了解它们的联合分布有助于特征选择与处理
示例:
在图像识别中,像素强度和梯度方向构成二维随机变量,它们的联合分布特征对图像分类至关重要
2. 联合分布函数 📊
2.1 定义与性质
-
联合分布函数:
F ( x , y ) = P { X ≤ x , Y ≤ y } F(x, y) = P\{X \leq x, Y \leq y\} F(x,y)=P{X≤x,Y≤y} -
核心性质:
- 单调非递减性: 对每个变量均单调不减
- 边界条件: F ( − ∞ , y ) = F ( x , − ∞ ) = 0 , F ( + ∞ , + ∞ ) = 1 F(-\infty, y) = F(x, -\infty) = 0, F(+\infty, +\infty) = 1 F(−∞,y)=F(x,−∞)=0,F(+∞,+∞)=1
- 右连续性
- 概率计算: P { a < X ≤ b , c < Y ≤ d } = F ( b , d ) − F ( b , c ) − F ( a , d ) + F ( a , c ) P\{a < X \leq b, c < Y \leq d\} = F(b,d) - F(b,c) - F(a,d) + F(a,c) P{a<X≤b,c<Y≤d}=F(b,d)−F(b,c)−F(a,d)+F(a,c)
3. 联合分布类型 📈
3.1 离散型二维随机变量
- 联合分布律:
P { X = x i , Y = y j } = p i j , ∑ i , j p i j = 1 P\{X = x_i, Y = y_j\} = p_{ij}, \quad \sum_{i,j} p_{ij} = 1 P{X=xi,Y=yj}=pij,∑i,jpij=1
机器学习应用:📱
离散特征(如用户类别、产品评级)间的关系分析常用离散型二维分布建模
# 模拟计算购买历史(X)与评分(Y)的联合分布表
import pandas as pd
import numpy as np
# 模拟数据
data = {
'purchase_count': np.random.poisson(lam=2, size=1000), # 0,1,2...次购买
'rating': np.random.randint(1, 6, size=1000) # 1-5星评分
}
df = pd.DataFrame(data)
# 计算联合分布
joint_prob = pd.crosstab(df['purchase_count'], df['rating'], normalize=True)
print("购买次数与评分的联合分布:")
print(joint_prob)
3.2 连续型二维随机变量 🌊
-
联合概率密度函数 f ( x , y ) f(x, y) f(x,y):
P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\{(X, Y) \in D\} = \iint_D f(x, y) \, dx dy P{(X,Y)∈D}=∬Df(x,y)dxdy -
分布函数与密度的关系:
F ( x , y ) = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v F(x, y) = \int_{-\infty}^x \int_{-\infty}^y f(u, v) \, du dv F(x,y)=∫−∞x∫−∞yf(u,v)dudv -
密度函数性质:
f ( x , y ) ≥ 0 , ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 f(x,y) \geq 0, \quad \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} f(x,y)dxdy = 1 f(x,y)≥0,∫−∞+∞∫−∞+∞f(x,y)dxdy=1
重要示例:二维正态分布 🔔
f ( x , y ) = 1 2 π σ X σ Y 1 − ρ 2 e − 1 2 ( 1 − ρ 2 ) [ ( x − μ X ) 2 σ X 2 − 2 ρ ( x − μ X ) ( y − μ Y ) σ X σ Y + ( y − μ Y ) 2 σ Y 2 ] f(x, y) = \frac{1}{2\pi\sigma_X\sigma_Y\sqrt{1-\rho^2}} e^{-\frac{1}{2(1-\rho^2)}\left[\frac{(x-\mu_X)^2}{\sigma_X^2} - 2\rho\frac{(x-\mu_X)(y-\mu_Y)}{\sigma_X\sigma_Y} + \frac{(y-\mu_Y)^2}{\sigma_Y^2}\right]} f(x,y)=2πσXσY1−ρ21e−2(1−ρ2)1[σX2(x−μX)2−2ρσXσY(x−μX)(y−μY)+σY2(y−μY)2]
⭐ 机器学习重要性:二维正态分布是多变量高斯分布的基础,广泛应用于贝叶斯学习、PCA分解等算法
# 二维正态分布可视化
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
def plot_bivariate_normal(mu_x=0, mu_y=0, sigma_x=1, sigma_y=1, rho=0):
# 创建网格点
x = np.linspace(mu_x-3*sigma_x, mu_x+3*sigma_x, 100)
y = np.linspace(mu_y-3*sigma_y, mu_y+3*sigma_y, 100)
X, Y = np.meshgrid(x, y)
# 构建位置矩阵
pos = np.empty(X.shape + (2,))
pos[:, :, 0] = X
pos[:, :, 1] = Y
# 定义二维正态分布
mean = [mu_x, mu_y]
cov = [[sigma_x**2, rho*sigma_x*sigma_y],
[rho*sigma_x*sigma_y, sigma_y**2]]
rv = stats.multivariate_normal(mean, cov)
# 计算PDF
Z = rv.pdf(pos)
# 绘图
fig = plt.figure(figsize=(12, 5))
# 3D表面
ax1 = fig.add_subplot(121, projection='3d')
surf = ax1.plot_surface(X, Y, Z, cmap='viridis', alpha=0.8)
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.set_zlabel('密度')
ax1.set_title(f'二维正态分布 (ρ={rho})')
# 等高线图
ax2 = fig.add_subplot(122)
contour = ax2.contourf(X, Y, Z, cmap='viridis', levels=20)
plt.colorbar(contour, ax=ax2)
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
ax2.set_title(f'等高线图 (ρ={rho})')
plt.tight_layout()
plt.show()
# 可视化不同相关系数的二维正态分布
plot_bivariate_normal(rho=0.8) # 高度正相关
4. 边缘分布 ↔️
-
边缘分布函数:
F X ( x ) = F ( x , + ∞ ) , F Y ( y ) = F ( + ∞ , y ) F_X(x) = F(x, +\infty), \quad F_Y(y) = F(+\infty, y) FX(x)=F(x,+∞),FY(y)=F(+∞,y) -
离散型边缘分布:
P { X = x i } = ∑ j p i j , P { Y = y j } = ∑ i p i j P\{X = x_i\} = \sum_{j} p_{ij}, \quad P\{Y = y_j\} = \sum_{i} p_{ij} P{X=xi}=∑jpij,P{Y=yj}=∑ipij -
连续型边缘密度:
f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y , f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_X(x) = \int_{-\infty}^{+\infty} f(x, y) \, dy, \quad f_Y(y) = \int_{-\infty}^{+\infty} f(x, y) \, dx fX(x)=∫−∞+∞f(x,y)dy,fY(y)=∫−∞+∞f(x,y)dx
🔑 机器学习启示:特征的边缘分布帮助我们理解单个特征的行为,但无法完全反映特征间的相互作用,因此需要联合分析
5. 条件分布 🎯
-
条件分布函数:
F X ∣ Y ( x ∣ y ) = P { X ≤ x ∣ Y = y } = ∂ ∂ y F ( x , y ) f Y ( y ) F_{X|Y}(x|y) = P\{X \leq x | Y = y\} = \frac{\frac{\partial}{\partial y}F(x,y)}{f_Y(y)} FX∣Y(x∣y)=P{X≤x∣Y=y}=fY(y)∂y∂F(x,y) -
条件概率密度:
f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) f_{X|Y}(x|y) = \frac{f(x,y)}{f_Y(y)} fX∣Y(x∣y)=fY(y)f(x,y)
机器学习应用: 🤖
- 条件分布是朴素贝叶斯分类器的理论基础: P ( X ∣ Y = c ) P(X|Y=c) P(X∣Y=c)
- 条件生成模型(如条件VAE、条件GAN)利用条件分布实现"控制生成"
# 二维正态分布的条件分布示例
def conditional_gaussian(mu_x, mu_y, sigma_x, sigma_y, rho, y_value):
"""返回Y=y_value条件下X的条件分布参数"""
cond_mean = mu_x + rho * (sigma_x/sigma_y) * (y_value - mu_y)
cond_var = (1 - rho**2) * sigma_x**2
return cond_mean, np.sqrt(cond_var)
6. 独立性与相关性 🔗
6.1 独立性
- 定义:若对任意 x , y x, y x,y:
F ( x , y ) = F X ( x ) F Y ( y ) F(x, y) = F_X(x) F_Y(y) F(x,y)=FX(x)FY(y) 或 f ( x , y ) = f X ( x ) f Y ( y ) f(x, y) = f_X(x) f_Y(y) f(x,y)=fX(x)fY(y)
💡 特征工程启示:若两特征独立,则联合使用它们可以提供更多信息;若高度相关,可考虑降维
6.2 协方差与相关系数
-
协方差:
Cov ( X , Y ) = E [ ( X − μ X ) ( Y − μ Y ) ] = E [ X Y ] − E [ X ] E [ Y ] \text{Cov}(X, Y) = E[(X - \mu_X)(Y - \mu_Y)] = E[XY] - E[X]E[Y] Cov(X,Y)=E[(X−μX)(Y−μY)]=E[XY]−E[X]E[Y] -
Pearson相关系数:
ρ X Y = Cov ( X , Y ) σ X σ Y , ∣ ρ X Y ∣ ≤ 1 \rho_{XY} = \frac{\text{Cov}(X, Y)}{\sigma_X \sigma_Y}, \quad |\rho_{XY}| \leq 1 ρXY=σXσYCov(X,Y),∣ρXY∣≤1
相关性分析要点:
- ρ X Y = 0 \rho_{XY} = 0 ρXY=0 表示不相关,但不一定独立
- ∣ ρ X Y ∣ = 1 |\rho_{XY}| = 1 ∣ρXY∣=1 表示完全线性相关: Y = a X + b Y = aX + b Y=aX+b
- 独立 ⇒ \Rightarrow ⇒ 不相关,但逆命题不成立
- 特例:对于二维正态分布,不相关 ⇔ \Leftrightarrow ⇔ 独立
# 相关系数与协方差矩阵计算
import numpy as np
from sklearn.datasets import make_classification
# 生成具有不同相关性的特征
X, _ = make_classification(n_samples=1000, n_features=2,
n_informative=2, n_redundant=0,
random_state=42)
# 计算协方差矩阵
cov_matrix = np.cov(X, rowvar=False)
print("协方差矩阵:\n", cov_matrix)
# 计算相关系数矩阵
corr_matrix = np.corrcoef(X, rowvar=False)
print("\n相关系数矩阵:\n", corr_matrix)
7. 机器学习中的应用 🚀
7.1 常见应用场景
| 应用领域 | 二维随机变量的作用 |
|---|---|
| 特征选择 | 通过相关性分析筛选冗余特征 |
| 降维技术 | PCA依赖特征间的协方差结构 |
| 贝叶斯网络 | 利用条件概率和条件独立性建模 |
| 生成模型 | 模拟多维数据的联合分布 |
| 异常检测 | 基于联合分布识别异常点 |
7.2 实际案例分析 📊
-
客户行为分析:购买频率与消费金额构成二维随机变量,可用于客户分群
-
金融风控:
- 收入水平与信用评分的联合分布帮助评估贷款风险
- 强相关性表明特征可能存在信息冗余
-
计算机视觉:
- 图像处理中相邻像素间的联合分布是纹理特征的基础
- 条件概率分布用于图像生成和超分辨率重建
# 可视化金融数据中的二维分布
import seaborn as sns
import pandas as pd
import numpy as np
# 模拟收入和信用评分数据
np.random.seed(42)
n = 1000
income = np.random.lognormal(mean=10, sigma=0.5, size=n)
# 模拟相关性:信用评分与收入相关但有随机波动
credit_score = 300 + 0.0003 * income + np.random.normal(0, 50, n)
credit_score = np.clip(credit_score, 300, 850) # 信用分数范围
# 创建数据框
df = pd.DataFrame({
'Income': income,
'Credit_Score': credit_score
})
# 可视化联合分布
plt.figure(figsize=(10, 8))
sns.jointplot(data=df, x='Income', y='Credit_Score', kind='scatter',
joint_kws={'alpha': 0.5}, height=7)
plt.suptitle('收入与信用评分的联合分布', y=1.05, fontsize=16)
# 计算相关系数
correlation = df['Income'].corr(df['Credit_Score'])
print(f"收入与信用评分的Pearson相关系数: {correlation:.4f}")
8. 进阶概念与技术 🔬
8.1 条件期望 E[X|Y]
-
定义:给定 Y = y 条件下 X 的平均值
E [ X ∣ Y = y ] = ∫ − ∞ ∞ x f X ∣ Y ( x ∣ y ) d x E[X|Y=y] = \int_{-\infty}^{\infty} x f_{X|Y}(x|y) dx E[X∣Y=y]=∫−∞∞xfX∣Y(x∣y)dx -
性质:
E [ X ] = E [ E [ X ∣ Y ] ] E[X] = E[E[X|Y]] E[X]=E[E[X∣Y]] (全期望公式)
🧠 机器学习应用:条件期望是回归问题的理论最优解,即 f ( x ) = E [ Y ∣ X = x ] f(x) = E[Y|X=x] f(x)=E[Y∣X=x]
8.2 多变量变换
对于二维随机变量 ( X , Y ) (X, Y) (X,Y),若进行变量变换 U = g 1 ( X , Y ) , V = g 2 ( X , Y ) U = g_1(X, Y), V = g_2(X, Y) U=g1(X,Y),V=g2(X,Y),则新的随机变量 ( U , V ) (U, V) (U,V) 的分布可通过雅可比行列式计算:
f U , V ( u , v ) = f X , Y ( x , y ) ⋅ ∣ ∂ ( x , y ) ∂ ( u , v ) ∣ f_{U,V}(u,v) = f_{X,Y}(x,y) \cdot \left| \frac{\partial(x,y)}{\partial(u,v)} \right| fU,V(u,v)=fX,Y(x,y)⋅ ∂(u,v)∂(x,y)
应用场景:✨
- 特征工程中的非线性变换
- 主成分分析中的坐标旋转
- 核方法中隐空间映射的理论基础
8.3 高维扩展
二维随机变量的概念可自然扩展到多维随机向量 X = ( X 1 , X 2 , . . . , X n ) \mathbf{X} = (X_1, X_2, ..., X_n) X=(X1,X2,...,Xn):
- 联合分布函数: F X ( x 1 , x 2 , . . . , x n ) = P { X 1 ≤ x 1 , X 2 ≤ x 2 , . . . , X n ≤ x n } F_{\mathbf{X}}(x_1, x_2, ..., x_n) = P\{X_1 \leq x_1, X_2 \leq x_2, ..., X_n \leq x_n\} FX(x1,x2,...,xn)=P{X1≤x1,X2≤x2,...,Xn≤xn}
- 协方差矩阵: Σ = [ σ i j ] \Sigma = [\sigma_{ij}] Σ=[σij],其中 σ i j = Cov ( X i , X j ) \sigma_{ij} = \text{Cov}(X_i, X_j) σij=Cov(Xi,Xj)
# 高维数据的协方差分析与可视化
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
feature_names = iris.feature_names
# 计算协方差矩阵
cov_matrix = np.cov(X, rowvar=False)
# 可视化协方差矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(cov_matrix, annot=True, fmt=".3f",
xticklabels=feature_names, yticklabels=feature_names,
cmap="coolwarm", cbar_kws={"label": "协方差"})
plt.title("鸢尾花数据集特征的协方差矩阵", fontsize=15)
plt.tight_layout()
9. 实战应用与代码示例 💻
9.1 分类问题中的特征相关性分析
# 分析特征相关性对分类性能的影响
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
results = []
correlations = np.linspace(-0.9, 0.9, 10)
for corr in correlations:
accuracies = []
for i in range(20): # 多次实验取平均
# 创建具有指定相关性的两个特征
X, y = make_classification(n_samples=1000, n_features=2,
n_informative=2, n_redundant=0,
n_clusters_per_class=1, random_state=i,
weights=[0.5, 0.5])
# 调整特征相关性
X[:, 1] = corr * X[:, 0] + np.sqrt(1 - corr**2) * X[:, 1]
# 拆分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=i)
# 分类器训练与评估
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
results.append(np.mean(accuracies))
plt.figure(figsize=(10, 6))
plt.plot(correlations, results, 'o-', linewidth=2)
plt.axhline(y=results[len(correlations)//2], color='r', linestyle='--',
alpha=0.5, label=f'无相关性准确率: {results[len(correlations)//2]:.4f}')
plt.xlabel('特征相关系数')
plt.ylabel('分类准确率')
plt.title('特征相关性与分类性能关系')
plt.grid(True, alpha=0.3)
plt.legend()
9.2 贝叶斯分类器中的条件概率
# 实现朴素贝叶斯分类器理解条件概率的应用
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import numpy as np
# 加载葡萄酒数据集
wine = load_wine()
X = wine.data
y = wine.target
# 数据预处理
X_scaled = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 训练朴素贝叶斯分类器
nb_classifier = GaussianNB()
nb_classifier.fit(X_train, y_train)
y_pred = nb_classifier.predict(X_test)
# 输出分类报告
print("朴素贝叶斯分类性能(利用条件概率):")
print(classification_report(y_test, y_pred))
# 可视化条件概率分布 (两个特征示例)
plt.figure(figsize=(12, 5))
for i, cls in enumerate(np.unique(y_train)):
plt.subplot(1, 3, i+1)
class_indices = y_train == cls
plt.scatter(X_train[class_indices, 0], X_train[class_indices, 1],
alpha=0.5, label=f'类别 {cls}')
# 计算每个类别下特征的条件均值和标准差
mean = np.mean(X_train[class_indices, :2], axis=0)
std = np.std(X_train[class_indices, :2], axis=0)
plt.title(f'类别 {cls} 的条件分布\n均值=({mean[0]:.2f}, {mean:.2f})\nσ=({std[0]:.2f}, {std:.2f})')
plt.xlabel(wine.feature_names[0])
plt.ylabel(wine.feature_names)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.suptitle('各类别下的二维特征条件分布', y=1.05, fontsize=15)
10. 总结与学习建议 📝
10.1 核心要点总结
- 二维随机变量是机器学习中特征关系的数学基础,描述了两个特征的联合统计行为
- 联合分布揭示特征交互模式,是特征工程与模型选择的重要依据
- 条件分布是预测与分类任务的理论支撑,形式化了"给定某特征值预测目标"的过程
- 相关性与独立性帮助我们理解特征间的关系,指导降维与特征选择
- 二维正态分布是最常用的连续型分布,许多算法隐式假设数据服从此分布
10.2 学习路径建议 🛣️
- 基础阶段:掌握分布函数、概率密度、边缘分布等基本概念
- 进阶阶段:深入理解条件分布、条件期望和变量变换
- 实践阶段:
- 使用真实数据分析特征间关系
- 实现简单的二维数据生成模型
- 比较不同相关性对机器学习算法性能的影响
结语 🌈
二维随机变量看似是概率论的基础概念,却是贯穿机器学习各领域的重要工具。从特征工程到模型设计,从数据分析到结果解释,二维随机变量的理论为我们提供了理解和操作高维数据的基础框架。通过掌握这些概念,你将能更深入地理解机器学习模型的工作原理,设计更有效的算法,并从数据中提取更多价值。
如果您对本文有任何疑问或建议,欢迎在评论区留言讨论! 💬

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 71
71 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)