TIFS2023 | TCA-GAN | 针对深度伪造换脸的受限黑盒对抗攻击
本文 “Restricted Black-Box Adversarial Attack Against DeepFake Face Swapping” 提出了一种实用的针对 DeepFake 换脸的受限黑盒对抗攻击方法,通过构建替代模型和 TCA - GAN 生成对抗扰动,并利用后正则化模块增强对抗样本的可迁移性,有效破坏 DeepFake 换脸效果,提升检测性能,还能推广到其他面部操作模型。
Restricted Black-Box Adversarial Attack Against DeepFake Face Swapping
本文 “Restricted Black-Box Adversarial Attack Against DeepFake Face Swapping” 提出了一种实用的针对 DeepFake 换脸的受限黑盒对抗攻击方法,通过构建替代模型和 TCA - GAN 生成对抗扰动,并利用后正则化模块增强对抗样本的可迁移性,有效破坏 DeepFake 换脸效果,提升检测性能,还能推广到其他面部操作模型。
摘要-Abstract
Abstract— DeepFake face swapping presents a significant threat to online security and social media, which can replace the source face in an arbitrary photo/video with the target face of an entirely different person. In order to prevent this fraud, some researchers have begun to study the adversarial methods against DeepFake or face manipulation. However, existing works mainly focus on the white-box setting or the black-box setting driven by abundant queries, which severely limits the practical application of these methods. To tackle this problem, we introduce a practical adversarial attack that does not require any queries to the facial image forgery model. Our method is built on a substitute model based on face reconstruction and then transfers adversarial examples from the substitute model directly to inaccessible blackbox DeepFake models. Specially, we propose the Transferable Cycle Adversary Generative Adversarial Network (TCA-GAN) to construct the adversarial perturbation for disrupting unknown DeepFake systems. We also present a novel post-regularization module for enhancing the transferability of generated adversarial examples. To comprehensively measure the effectiveness of our approaches, we construct a challenging baseline of DeepFake adversarial attacks for future development. Extensive experiments impressively show that the proposed adversarial attack method makes the visual quality of DeepFake face images plummet so that they are easier to be detected by humans and algorithms. Moreover, we demonstrate that the proposed algorithm can be generalized to offer face image protection against various face translation methods.
DeepFake换脸技术对网络安全和社交媒体构成了重大威胁,它可以将任意照片或视频中的源面孔替换为完全不同人的目标面孔。为了防范这种欺诈行为,一些研究人员开始研究对抗DeepFake或面部操纵的方法。然而,现有工作主要集中在白盒设置或由大量查询驱动的黑盒设置上,这严重限制了这些方法的实际应用。为了解决这个问题,我们引入了一种实用的对抗攻击方法,该方法无需对人脸图像伪造模型进行任何查询。我们的方法基于一个基于面部重建的替代模型,然后将对抗样本从替代模型直接迁移到无法访问的黑盒DeepFake模型。具体而言,我们提出了可转移循环对抗生成对抗网络(TCA - GAN)来构建对抗扰动,以破坏未知的DeepFake系统。我们还提出了一种新颖的后正则化模块,用于增强生成的对抗样本的可转移性。为了全面衡量我们方法的有效性,我们构建了一个具有挑战性的DeepFake对抗攻击基线,以供未来研究参考。大量实验深刻地表明,所提出的对抗攻击方法使DeepFake人脸图像的视觉质量大幅下降,从而更容易被人和算法检测到。此外,我们证明了所提出的算法可以推广到保护人脸图像免受各种面部变换方法的影响。
引言-Introduction
这部分内容主要介绍了研究背景和动机,具体内容如下:
- DeepFake技术的威胁:DeepFake是一种结合深度学习的换脸技术,能将现有图像或视频中的源脸替换成任意身份的目标脸。其滥用会对社交媒体和网络安全造成潜在危害,比如被用于敲诈勒索或绕过认证机制。虽然存在伪造检测方法,但检测存在延迟,会对个人声誉造成损害。
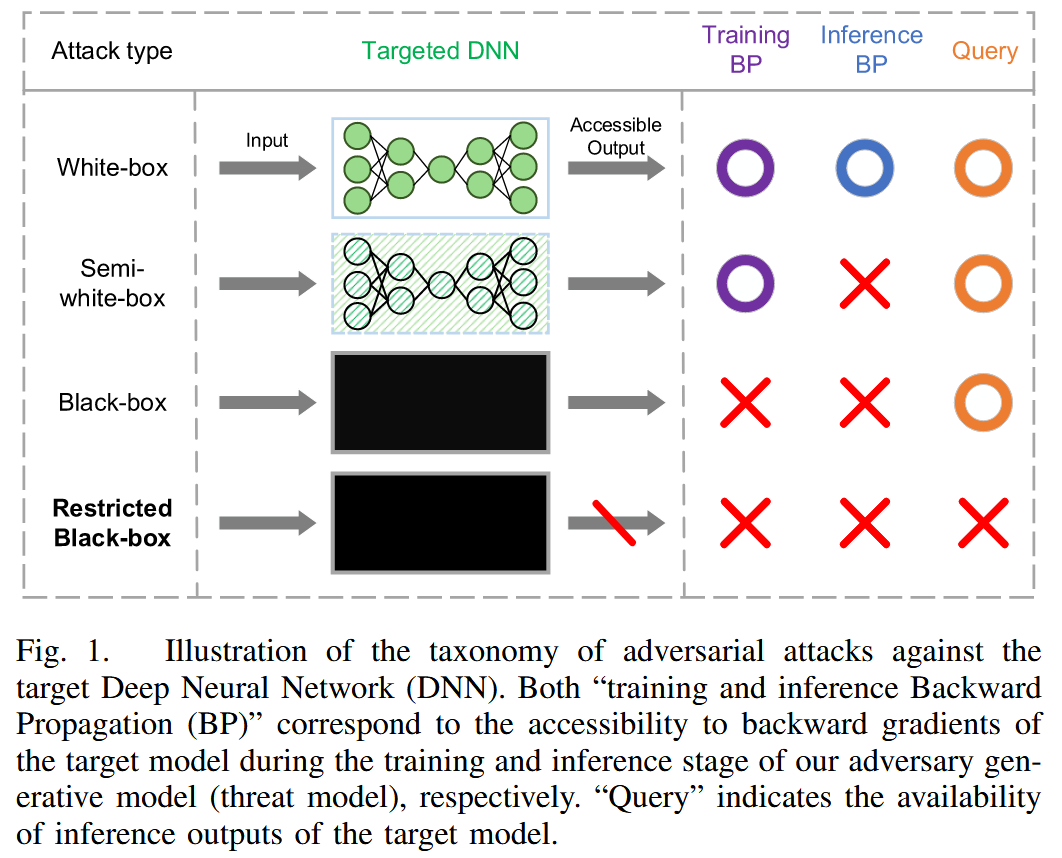
- 对抗攻击的类型及局限性:深度神经网络(DNNs)在易受对抗样本的影响,根据对目标模型的信息获取程度和输出结果,攻击场景分为白盒、半白盒、黑盒和受限黑盒对抗攻击。白盒和半白盒攻击在防御未知篡改时不切实际,黑盒对抗攻击只能获取DNN输出,而受限黑盒对抗攻击无法获取目标DNN模型的输出,甚至不能进行单次查询,更适用于现实场景。
图1. 针对目标深度神经网络(DNN)的对抗攻击分类示意图。“训练和推理反向传播(BP)”分别对应于在我们的对抗生成模型(威胁模型)的训练和推理阶段对目标模型反向梯度的可访问性。“查询”表示目标模型推理输出的可用性。 - 本文的研究方法和贡献: 构建基于深度自动编码器网络的替代模型模拟面部重建过程,对可访问的替代模型进行对抗攻击,再将对抗样本转移到其他未知的面部操纵模型。设计了可迁移循环对抗生成对抗网络(TCA-GAN)来生成针对未知 DeepFake 换脸系统的对抗扰动,并提出后正则化模块增强对抗样本的可迁移性。构建了新的数据集和基线,用于验证方法的有效性。实验表明,该方法能有效降低DeepFake人脸图像的视觉质量,便于人和算法检测,还能推广到保护人脸图像免受多种面部变换方法的影响。
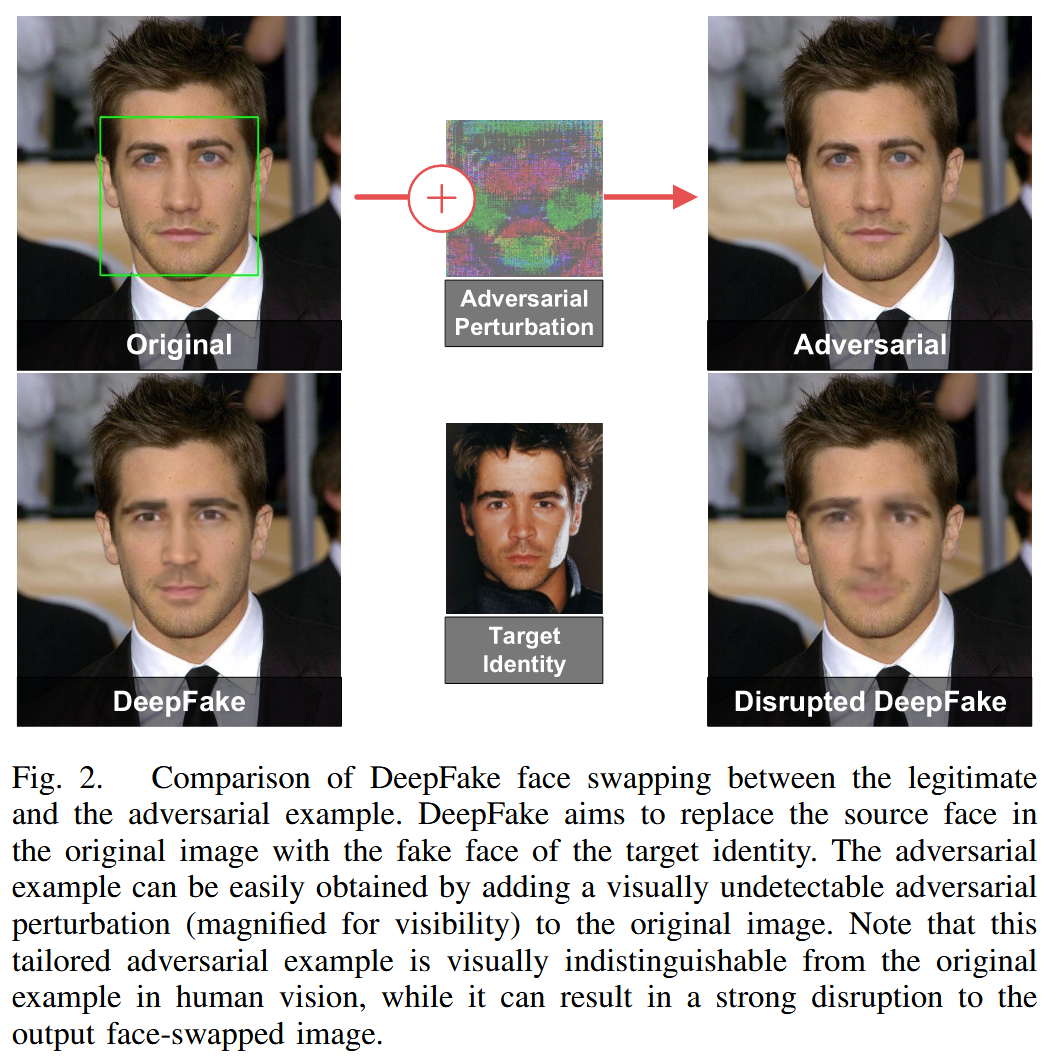
图2. 合法样本与对抗样本在DeepFake换脸效果上的对比。DeepFake旨在将原始图像中的源面孔替换为目标身份的假面孔。对抗样本可通过在原始图像上添加肉眼不可见的对抗扰动(为便于查看进行了放大处理)轻松获得。需要注意的是,这种特制的对抗样本在人类视觉中与原始样本难以区分,但它却能对换脸后的输出图像造成强烈干扰。
相关工作-Related Work
该部分主要回顾了自动换脸技术、对抗攻击分类器以及对抗攻击生成模型这三方面的相关研究,梳理了已有工作的进展与局限,为本文方法的提出提供了背景和依据。
- 自动换脸技术:早期的换脸技术需要手动标注辅助,后来发展为基于深度学习的自动换脸方法,如用候选脸替换源脸、将换脸视为风格迁移等。现代基于深度学习的换脸技术能合成逼真的人脸图像,其中DeepFake最为流行,但也引发了诸多问题,本文旨在干扰DeepFake换脸。
- 对抗攻击分类器:研究发现深度神经网络(DNNs)的不连续性或高维空间的线性是产生对抗样本的原因,基于此提出了多种对抗攻击方法,如快速梯度符号法(FGSM)及其迭代版本、通用对抗攻击、单像素对抗扰动生成法、快速自适应边界(FAB)攻击等,也有研究利用GAN生成对抗样本。本文基于GAN扩展到受限黑盒场景下攻击生成模型,重点增强对抗样本针对DeepFake换脸的可转移性。
- 对抗攻击生成模型:针对生成模型的对抗攻击研究较少,现有研究包括对自动编码器的对抗攻击、为生成模型添加辅助分类器以进行对抗攻击、利用对抗样本干扰图像转换模型等。已有工作多在白盒或多查询黑盒场景下,而本文专注于受限黑盒场景,且主要针对原始DeepFake换脸模型,同时还能推广到保护人脸图像免受其他面部操作任务的影响。
方法-Method
预备知识-Preliminaries
该部分主要介绍了DeepFake模型的原理以及本文所涉及的符号表示,为后续理解文章的方法和实验奠定基础,具体内容如下:
- DeepFake 模型回顾:原始的 DeepFake 换脸模型包含一个共享编码器和两个分别对应不同换脸身份的解码器。在训练阶段,它使用与输入身份一致的解码器进行面部重建;在换脸时,则用另一个解码器解码潜在变量以获得换脸图像。由于输入的人脸图像已针对稳健换脸进行训练,所以干扰DeepFake换脸具有挑战性,本文主要针对这种原始的DeepFake换脸机制进行攻击。
- 符号表示:在黑盒场景下构建针对DeepFake换脸的可转移对抗样本。用 x a d v = x + r x^{adv}=x+r xadv=x+r 表示对抗样本,其中 x x x 是合法面部图像, r r r 是附加的对抗扰动; D F : X → Y DF: X \to Y DF:X→Y 代表不可访问的 DeepFake 换脸过程,它将输入面部图像 x ∈ X x \in X x∈X 映射到换脸输出 D F ( x ) ∈ Y DF(x) \in Y DF(x)∈Y , X X X 和 Y Y Y 分别对应源身份和换脸目标身份的域;引入替代模型 S ( ⋅ ) = S d ( S e ( ⋅ ) ) S(\cdot)=S_{d}(S_{e}(\cdot)) S(⋅)=Sd(Se(⋅)),由下采样编码器 S e ( ⋅ ) S_{e}(\cdot) Se(⋅) 和上采样解码器 S d ( ⋅ ) S_{d}(\cdot) Sd(⋅) 组成。主要目标是找到可迁移的对抗扰动,在无法访问 DeepFake 模型的情况下干扰其换脸过程,为此将追求的对抗扰动公式化为 m a x r F [ D F ( x ) , D F ( x + r ) ] max _{r} F[DF(x), DF(x+r)] maxrF[DF(x),DF(x+r)] ,约束条件为 ∥ r ∥ ∞ ≤ ϵ \| r\| _{\infty} \leq \epsilon ∥r∥∞≤ϵ , F F F 是衡量不同图像间距离的度量, ϵ \epsilon ϵ 表示限制对抗扰动大小的无穷范数边界。
TCA-GAN Against Substitute Model
这部分内容主要介绍了基于替代模型的TCA - GAN对抗攻击方法,具体如下:
- 方法提出的背景:基于查询的黑盒对抗攻击方法在推理阶段需要对黑盒模型进行大量查询操作,这在实际场景中难以实现,因为无法对目标黑盒模型进行多次查询或获取其输出结果。基于对抗样本的可转移性,构建替代模型来生成可泛化的对抗样本,以实现受限黑盒对抗攻击,即从替代模型获取对抗样本并期望将其转移到未知的DeepFake换脸模型。
- 替代模型的选择:受相关研究启发,将替代模型扩展为生成模型来模拟黑盒面部操作模型,因其比具有绝对分类边界的分类模型更具挑战性。考虑到DeepFake及其他面部操作模型可看作是以特殊风格重建目标面部,采用预训练的DNN自动编码器作为替代模型进行面部图像重建。通过对输入图像进行随机旋转、缩放和平移等操作,使替代模型对细微扰动具备一定鲁棒性,从而使针对替代模型产生的对抗样本在目标模型上有更好的转移性能,其优化过程通过公式 L r e c o n s = ∥ S ( x ) − x ∥ 1 + ∥ S ( x ^ ) − x ^ ∥ 1 \mathcal{L}_{recons }=\| S(x)-x\| _{1}+\| S(\hat{x})-\hat{x}\| _{1} Lrecons=∥S(x)−x∥1+∥S(x^)−x^∥1 表示 ,其中 x ^ \hat{x} x^ 是对输入图像 x x x 进行变换后的图像。
- TCA - GAN的结构与原理:构建的 TCA - GAN 是一个循环结构,由两个生成模块和两个相应的域判别器组成。两个循环一致的对抗生成器分别用于生成和消除对抗扰动,生成的对抗扰动添加到原始图像上得到对抗样本。通过构建双向对抗生成和消除机制,考虑自然域和对抗域之间的转换,两个域判别器用于区分合法样本 x x x 和对抗样本 x a d v x^{adv} xadv.
- 正向对抗生成:旨在生成对抗扰动与输入面部图像结合,干扰替代模型的重建。生成的对抗样本不仅干扰替代模型的图像级重建,还扰动其提取的潜在变量。基于对抗扰动对 DNN 的可迁移性以及 DNN 组件间的相似性,期望获得的对抗样本能迁移攻击不可访问的DeepFake模型。其损失函数为 L d i s r = e x p { − ∥ S e ( x ) − S e ( G P ( x ) + x ) ∥ 1 } + e x p { − ∥ S ( x ) − S ( G P ( x ) + x ) ∥ 1 } \mathcal{L}_{disr } =exp \left\{-\left\| S_{e}(x)-S_{e}\left(G_{P}(x)+x\right)\right\| _{1}\right\} +exp \left\{-\left\| S(x)-S\left(G_{P}(x)+x\right)\right\| _{1}\right\} Ldisr=exp{−∥Se(x)−Se(GP(x)+x)∥1}+exp{−∥S(x)−S(GP(x)+x)∥1},其中 G P ( ⋅ ) G_{P}(\cdot) GP(⋅) 是生成可转移对抗扰动的生成器。
- 反向对抗消除:目的是从对抗样本中去除附加的对抗扰动,通过建立循环一致结构,优化公式 L c y c = ∥ G R ( x + G P ( x ) ) − G P ( x ) ∥ 1 \mathcal{L}_{c y c}=\left\| G_{R}\left(x+G_{P}(x)\right)-G_{P}(x)\right\| _{1} Lcyc=∥GR(x+GP(x))−GP(x)∥1 , G R ( ⋅ ) G_{R}(\cdot) GR(⋅) 是用于去除对抗扰动的生成器。该机制使得生成和去除的对抗扰动尽可能接近,为生成强大的对抗扰动提供更丰富的监督,增强对抗样本的泛化性能。
- 域判别器与对抗损失:构建两个域判别器,分别区分对抗样本和合法样本,辅助相应生成器学习自然和对抗图像域之间的可逆变换,学习两者的判别特征,降低过拟合风险。对抗损失函数为 L a d v = D L ( x a d v ) − D L ( x ) + D A ( x a d v − G R ( x a d v ) ) − D A ( x a d v ) \mathcal{L}_{a d v} =D_{L}\left(x_{a d v}\right)-D_{L}(x)+D_{A}\left(x_{a d v}-G_{R}\left(x_{a d v}\right)\right)-D_{A}\left(x_{a d v}\right) Ladv=DL(xadv)−DL(x)+DA(xadv−GR(xadv))−DA(xadv) ,其中 D L ( ⋅ ) D_{L}(\cdot) DL(⋅) 和 D A ( ⋅ ) D_{A}(\cdot) DA(⋅) 分别是合法样本域和对抗样本域的判别器, x a d v = x + G P ( x ) x_{a d v}=x+G_{P}(x) xadv=x+GP(x) 是正向对抗生成器创建的对抗样本。
- TCA - GAN的总目标: L = L a d v + λ c y c ⋅ L c y c + λ d i s r ⋅ L d i s r \mathcal{L}=\mathcal{L}_{a d v}+\lambda_{c y c} \cdot \mathcal{L}_{c y c}+\lambda_{d i s r} \cdot \mathcal{L}_{d i s r} L=Ladv+λcyc⋅Lcyc+λdisr⋅Ldisr,通过求解极小极大博弈实现GAN机制,训练生成器时最小化目标函数,训练判别器时最大化目标函数, λ c y c \lambda_{cyc } λcyc和 λ d i s r \lambda_{disr } λdisr用于管理目标函数中各部分的相对重要性。
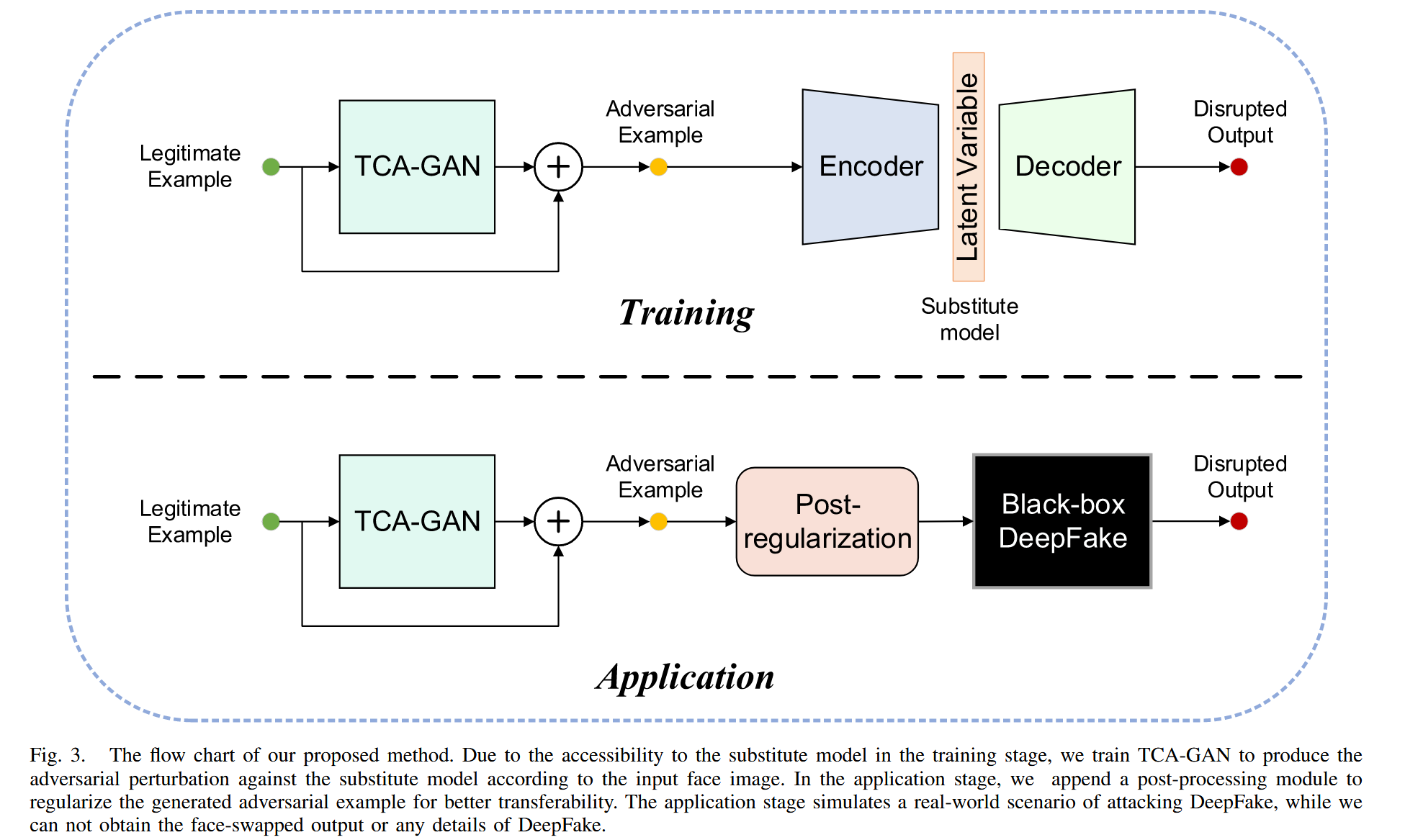
图3. 我们所提方法的流程图。在训练阶段,由于可以访问替代模型,我们训练 TCA - GAN 根据输入的人脸图像生成针对替代模型的对抗扰动。在应用阶段,我们添加一个后处理模块对生成的对抗样本进行正则化处理,以提高其可转移性。应用阶段模拟了攻击DeepFake的真实场景,在此场景中我们无法获取DeepFake的换脸输出或任何细节。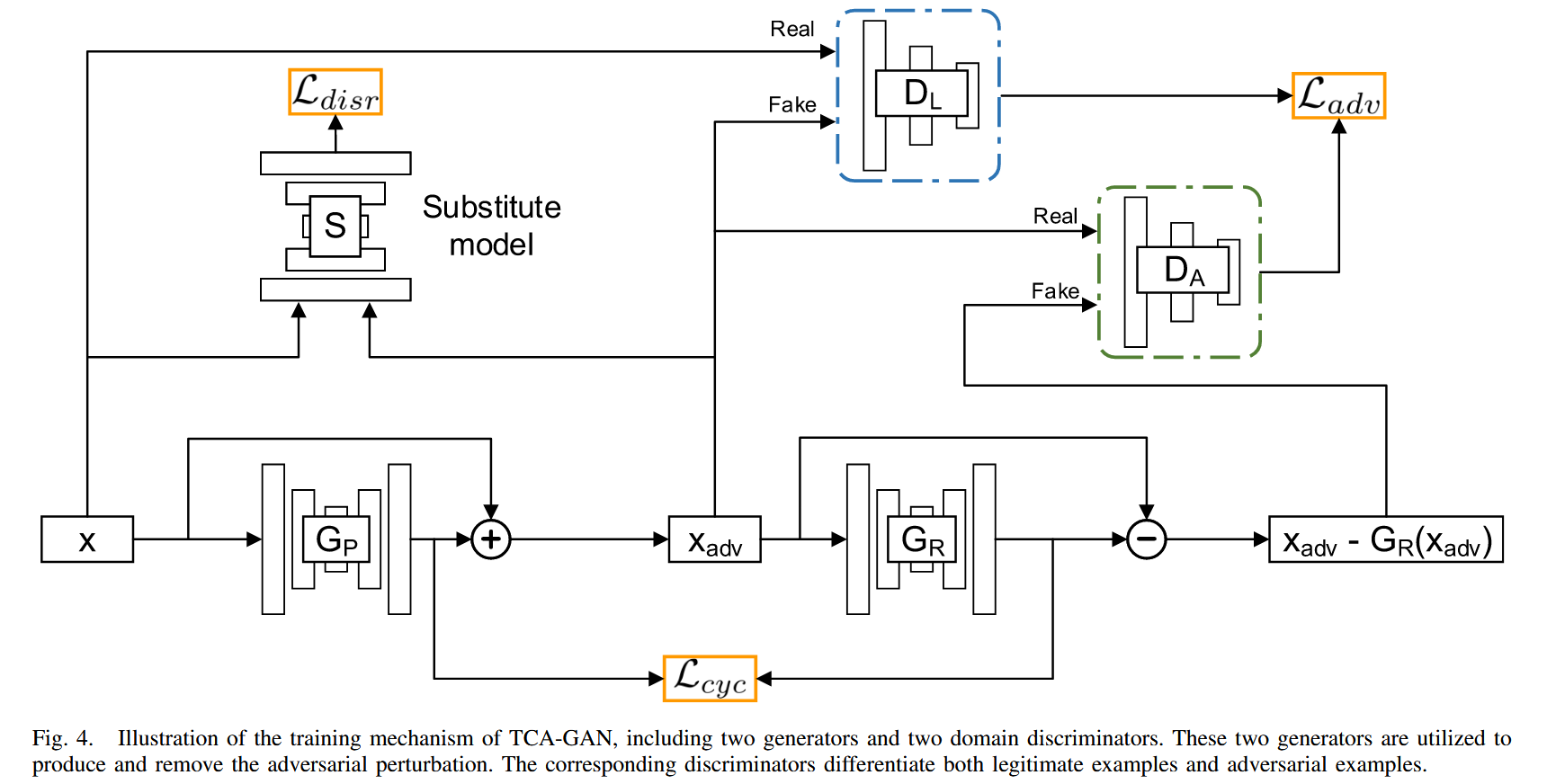
图4. TCA - GAN 训练机制示意图,包括两个生成器和两个域判别器。这两个生成器用于生成和消除对抗扰动。相应的判别器用于区分合法样本和对抗样本。
后正则化-Post-Regularization
这部分内容主要介绍了后正则化模块,该模块用于进一步增强对抗样本的可迁移性,具体内容如下:
- 后正则化的目的:根据相关研究发现,针对深度学习模型生成的对抗样本越特定,其泛化能力越差。为了让生成的对抗样本对替代模型不过于依赖,从而获得更好的泛化效果,需要对TCA - GAN生成的对抗样本进行后正则化处理,以削弱其对替代模型的特异性。
- 后正则化的方法:一种有效的正则化方法是进行蒸馏操作。受通过增加自然样本和对抗样本之间潜在变量差异来干扰替代模型的启发,在进行后正则化时,也引入特征级约束来获得更具可迁移性的对抗样本。首先给对抗样本添加随机噪声进行初始化,使其逃离对抗样本的非平滑邻域,然后引导这个新样本逼近TCA - GAN生成的对抗样本。通过公式 m a x x r a d v [ S e ( x r a d v ) − S e ( S ( x ) ) ] ∘ [ S e ( x a d v ) − S e ( S ( x ) ) ] max _{x_{r a d v}}\left[S_{e}\left(x_{r a d v}\right)-S_{e}(S(x))\right] \circ\left[S_{e}\left(x_{a d v}\right)-S_{e}(S(x))\right] maxxradv[Se(xradv)−Se(S(x))]∘[Se(xadv)−Se(S(x))] 进行优化,约束条件为 ∥ x r a d v − x ∥ ∞ < ϵ \left\| x_{r a d v}-x\right\| _{\infty}<\epsilon ∥xradv−x∥∞<ϵ ,其中 x r a d v x_{rad v} xradv 表示正则化后的对抗样本,◦ 是哈达玛积。
- 优化方法与过程:采用迭代投影梯度下降(PGD)方法来求解上述优化问题。在每次迭代中,对负目标函数进行梯度上升以增加其值,同时应用投影操作将对抗扰动约束在 ϵ \epsilon ϵ -球内。在优化过程中,选择将原始样本的重建结果作为参考,通过最大化正则化对抗样本与重建输出之间的特征级距离,而不是与原始样本的距离,因为重建样本可视为原始样本的增强版本,这样能获得更具泛化性的对抗样本。通过这种优化,正则化对抗样本对小变换更具鲁棒性,且能保持较高的潜在变量差异。整体过程通过算法1实现,算法中 C l i p Clip Clip 和 C l i p i m a g e r a n g e Clipimage_range Clipimagerange 分别表示在 ϵ \epsilon ϵ -球内的裁剪和图像范围的裁剪,初始阶段对抗样本的随机化还能进一步防止标签泄露和梯度屏蔽问题。

实验-Experiments
实验设置-Experimental Setup
该部分详细介绍了实验的设置,为后续实验结果的可靠性和有效性提供了保障,具体内容如下:
- 数据集:基于高质量面部图像数据集 Face Scrub 构建了 DeepFake 换脸数据集,包含 6274 张分辨率为 256×256 的图像,涵盖 40 名男性和 38 名女性的身份。为模拟真实应用场景,训练替代模型和 TCA - GAN 的数据库与评估对抗 DeepFake 换脸的数据库相互独立。其中,用 1439 张面部图像(随机选择 6 名男性和 6 名女性身份)训练替代模型和 TCA - GAN,其余 4835 张不同身份的面部图像用于评估生成的针对黑盒 DeepFake 换脸的可转移对抗样本。此外,还引入了第三方数据集 CelebFaces Attributes(CelebA)来评估方法在其他面部操作模型上的泛化能力,从 CelebA 中随机选择 5000 张尺寸为 128×128 的面部图像作为测试集,这些图像与 TCA - GAN 和替代模型的训练集无交集。
- 评估指标:为全面评估方法的有效性,对换脸图像进行了参考和非参考图像质量评估。使用结构相似性(SSIM)指数和特征相似性(FSIM)来衡量输入人脸图像与换脸图像在合法样本和对抗样本下的相似程度;利用盲/无参考图像空间质量评估器(BRISQUE)评估图像质量,BRISQUE分数越小表示视觉质量越好。
- 实验细节:为模拟实际对抗攻击场景,生成的对抗样本会被调整为原始大小,并在进入目标 DeepFake 模型前进行随机变换。实验中图像值归一化到 [0, 1],为获得肉眼不可见的对抗扰动,将扰动边界 ϵ \epsilon ϵ 限制为0.03。训练 TCA - GAN 时,超参数设置为 λ c y c = 1.0 \lambda_{cyc } = 1.0 λcyc=1.0 和 λ d i s r = 10.0 \lambda_{disr } = 10.0 λdisr=10.0,后正则化运行 10 次迭代,步长为 0.006.
实验结果-Experimental Results
该部分主要展示了针对DeepFake换脸的受限黑盒对抗攻击实验结果,验证了本文所提方法的有效性,具体内容如下:
-
换脸示例展示:通过图5展示了基于合法图像和对抗图像输入的换脸示例,直观呈现了 DeepFake 换脸在正常和对抗情况下的差异,为后续实验结果的理解提供了直观参考。
-
与其他方法对比实验
- 参考图像质量评估:在黑盒设置下,通过对比不同对抗攻击方法对 DeepFake 换脸的干扰效果,评估指标包括 SSIM 和 FSIM。实验结果(如表I所示)表明,在保持对抗扰动视觉不可见的同时,本文方法能对 DeepFake 换脸产生有效扰动。例如,在比较不同方法的 SSIM 和 FSIM 值时,虽然各方法在合法样本下的指标相近,但在对抗样本下,本文方法使得换脸图像的这些指标值明显降低,意味着生成的换脸图像与原始图像差异增大,证明了方法的有效性。
表I 黑盒设置下干扰 DeepFake 换脸的参考图像质量评估。最佳性能以粗体显示。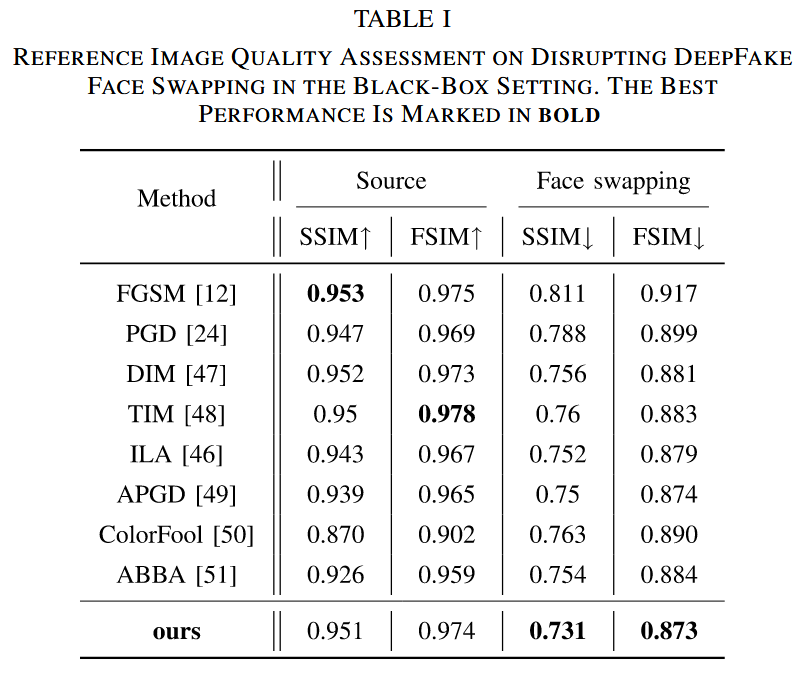
- 非参考图像质量评估:使用BRISQUE指标评估相关图像的质量(如表II所示)。目标是在保持输入对抗图像质量较高的同时,使对抗样本诱导的换脸图像质量变差。实验结果显示,本文方法得到的对抗样本诱导的换脸图像 BRISQUE 得分更高,表明其视觉质量更差,进一步证明了本文方法能有效导致 DeepFake 换脸图像的面部失真。
表II 相关图像的非参考图像质量评估(使用 BRISQUE 指标)。最佳性能以粗体显示。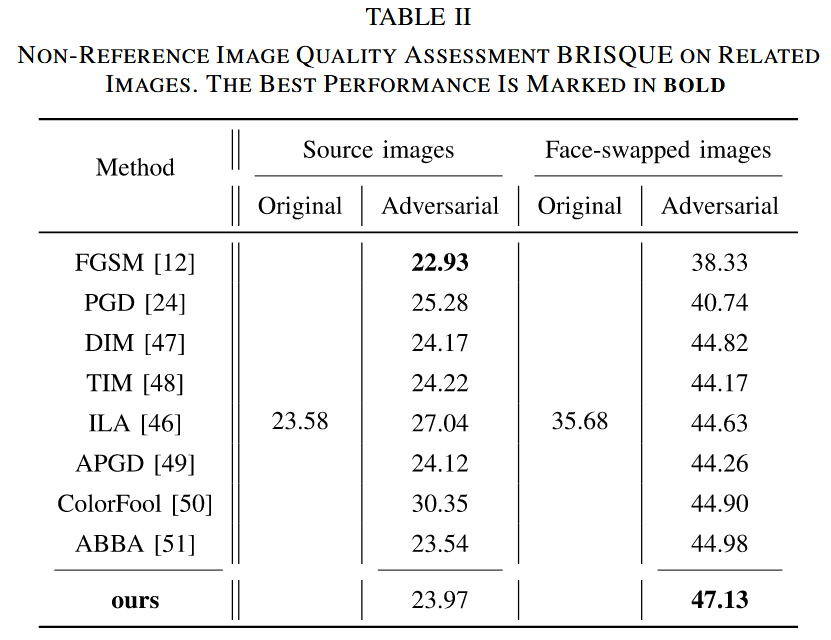
- 参考图像质量评估:在黑盒设置下,通过对比不同对抗攻击方法对 DeepFake 换脸的干扰效果,评估指标包括 SSIM 和 FSIM。实验结果(如表I所示)表明,在保持对抗扰动视觉不可见的同时,本文方法能对 DeepFake 换脸产生有效扰动。例如,在比较不同方法的 SSIM 和 FSIM 值时,虽然各方法在合法样本下的指标相近,但在对抗样本下,本文方法使得换脸图像的这些指标值明显降低,意味着生成的换脸图像与原始图像差异增大,证明了方法的有效性。
-
实验结论:综合参考和非参考图像质量评估结果,充分证明了本文所提方法能够有效干扰 DeepFake 换脸,在不影响原始图像视觉效果的前提下,显著降低换脸图像的质量,从而验证了该方法在受限黑盒场景下对抗 DeepFake 换脸的有效性。
时间消耗比较-Time Cost Comparison
这部分内容主要对本文方法在生成对抗样本时的时间成本进行了评估,并与其他攻击方法对比,具体如下:
-
评估目的:除了评估方法对 DeepFake 换脸的干扰效果,还对在应用阶段生成对抗样本的效率进行评估,以全面衡量方法的实用性。
-
实验设置与结果:在单个 NVIDIA Tesla A100 上,针对不同批量大小,测试了包括本文方法在内的多种攻击方法生成对抗面部图像的计算成本,结果见表III。从表中数据可知,在不同批量大小下,本文方法生成对抗样本的时间成本相对较低。例如,批量大小为 16 时,本文方法耗时 716 秒,明显低于 APGD 的 3544 秒;批量大小为 64 时,本文方法耗时 284 秒,优于多数对比方法。
表III 针对不同批量大小,生成针对黑盒 DeepFake 换脸系统的可转移对抗样本 10 次运行的平均时间成本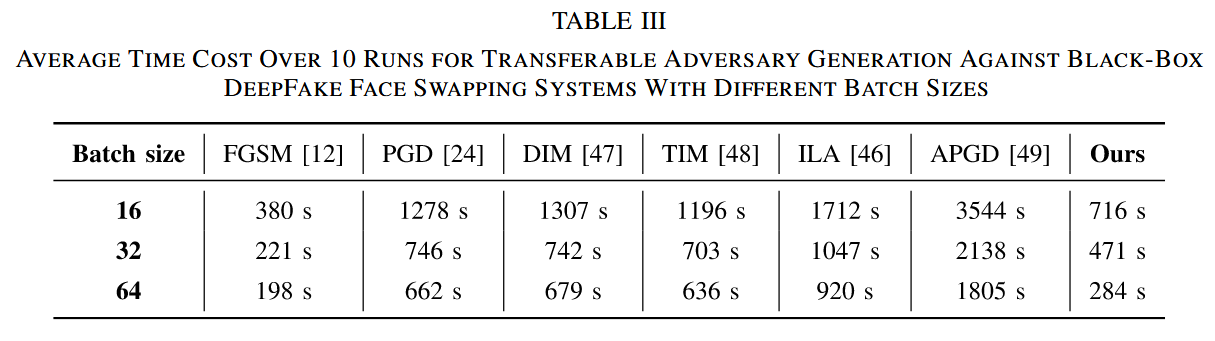
-
综合分析:虽然与基于优化的对抗样本生成方法相比,本文方法训练 TCA - GAN 生成对抗样本需要额外计算成本,但在应用阶段,相比多迭代的对抗样本生成方法,利用生成模型生成对抗样本能节省更多时间。未来研究将进一步探索加速本文对抗样本生成方法的途径。
消融研究-Ablation Study
这部分内容通过消融实验,深入分析了本文所提方法中各组件模块的有效性,具体如下:
-
替代模型选择的影响:为探究采用面部重建模型作为替代模型的有效性,对比了以不同(生成式)图像恢复模型(包括去噪和去模糊模型)作为替代模型时的实验结果。通过对输出换脸图像进行参考和非参考图像质量评估(结果见表IV),发现面部重建模型更有利于生成针对未知黑盒 DeepFake 模型的可转移对抗样本。这是因为面部重建与面部操作的生成过程相似度高,使得针对面部重建模型生成的对抗样本更易转移到其他面部操作模型,从而更显著地破坏换脸效果。
表IV 关于替代模型选择的消融研究。最佳性能以粗体显示。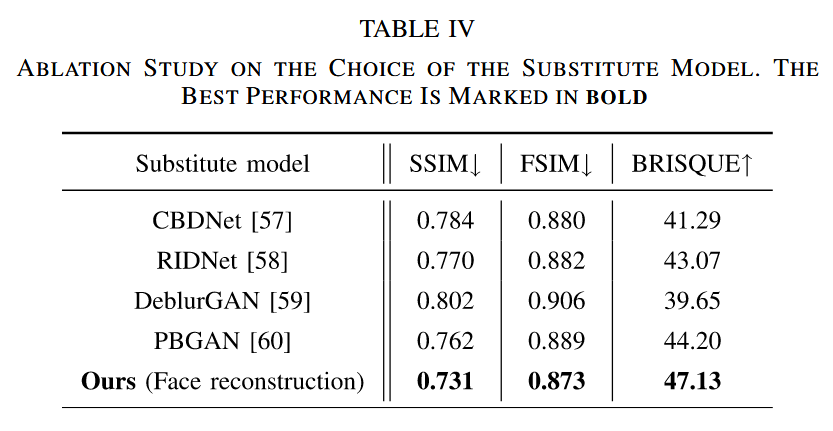
-
TCA - GAN中循环一致性类型的影响:研究了 TCA - GAN 中不同循环一致性类型对实验结果的影响。单向循环一致性保持了合法样本与通过两个生成器分别生成的重建图像之间的一致性,双向循环一致性则在此基础上考虑了对抗样本的循环重建。实验对比了无循环一致性、单向循环一致性和双向循环一致性三种情况下的实验结果(见表V)。结果表明,具有单向循环一致性的 TCA - GAN 表现更优。因为双向循环一致性使获得的对抗样本过度偏向替代模型,难以转移到其他 DNN 模型,而本文旨在获取次优对抗样本并将其推广到其他面部操作模型,过度强大的对抗样本可能会对样本转移产生负面影响。
表V TCA - GAN中循环一致性类型的消融研究。最佳性能以粗体显示。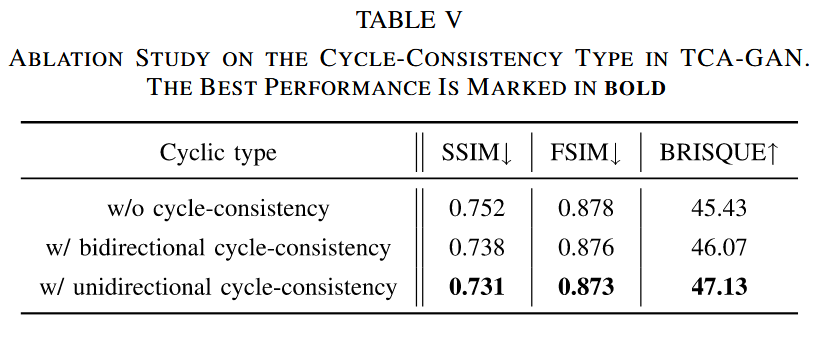
-
组件模块的综合影响:评估了循环一致性、潜在变量扰动和后正则化模块对方法的影响(结果见表VI)。潜在变量扰动指在训练 TCA - GAN 时对替代模型的潜在变量进行干扰,实验发现它对增强转移的对抗干扰有积极作用,能使 SSIM 性能提升 3.1%,这表明对潜在表示的扰动更易推广到其他 DNN 模型。后正则化模块对 TCA - GAN 生成的对抗样本进行进一步提炼,使 SSIM 性能提升 3.9%,且能保持合法样本和正则化对抗样本在潜在变量上的较大差异,验证了次优对抗样本比最优对抗样本具有更稳健的泛化性能。综合来看,本文提出的各模块及其集成对破坏 DeepFake 换脸机制是有效的。
表VI 组件模块的消融实验结果。每列中的最佳结果以粗体显示。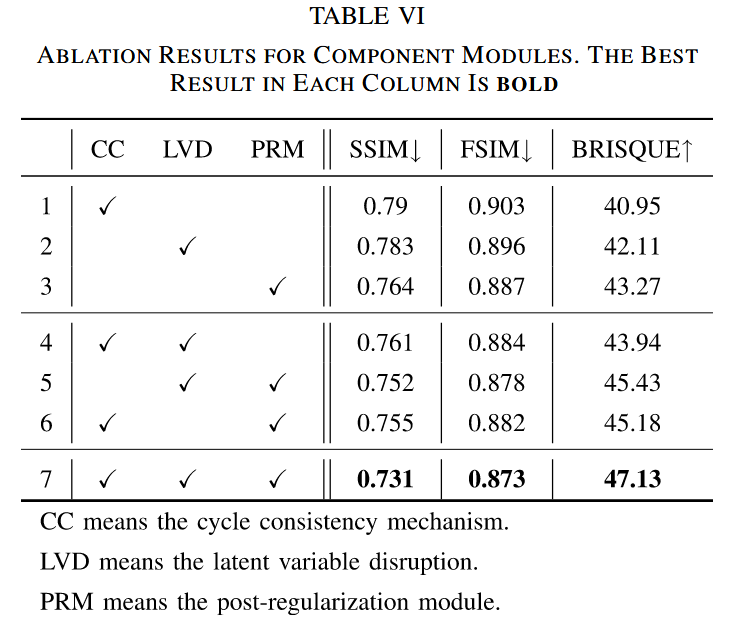
-
超参数敏感性分析:通过调整目标损失的组件加权因子,系统评估各组件的贡献,并对方法进行超参数敏感性分析(见图6)。结果显示,增大干扰加权因子 λ d i s r \lambda_{disr } λdisr 可进一步提高输出换脸图像的面部失真程度;选择合适的循环一致性加权因子有助于提高生成的对抗面部图像的泛化能力。
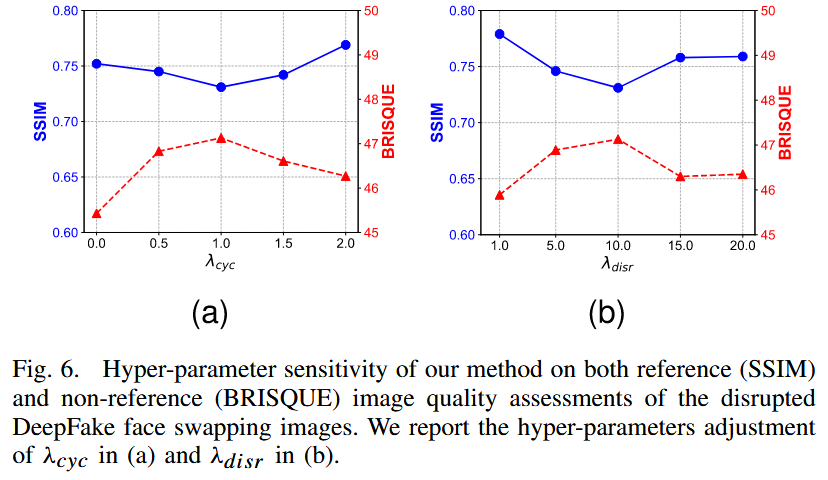
图6. 我们的方法在对受干扰的DeepFake换脸图像进行参考(结构相似性指数,SSIM)和非参考(盲/无参考图像空间质量评估器,BRISQUE)图像质量评估方面的超参数敏感性。我们在(a)中给出了循环一致性加权因子 λ c y c \lambda_{cyc } λcyc 的超参数调整情况,在(b)中给出了干扰加权因子 λ d i s r \lambda_{disr } λdisr 的超参数调整情况。
对 DeepFake 检测的增强-Enhancement on DeepFake Detection
这部分内容主要阐述了本文方法对 DeepFake 检测的增强作用,具体内容如下:
-
研究背景与目的:目前 DeepFake 检测方法虽能检测出伪造的面部图像,但对于检测由微小扰动引起的质量下降(如本文所生成的对抗样本导致的换脸图像质量下降)效果不佳。因此,研究本文方法生成的对抗样本对 DeepFake 检测的增强作用,以提高检测效率。
-
实验设置:使用 FaceForensics++ 数据集进行实验,该数据集包含多种 DeepFake 技术生成的换脸图像。采用卷积神经网络(CNN)作为检测模型,将其训练为二分类器,用于区分真实和伪造的面部图像。实验分为两组,一组使用合法样本(原始图像)进行训练和测试,另一组使用本文方法生成的对抗样本(经过后正则化)进行训练和测试。
-
实验结果:实验结果表明,使用对抗样本训练的检测模型在检测 DeepFake 换脸图像时表现更优。在检测真实和伪造图像的准确率上,使用对抗样本训练的模型比使用合法样本训练的模型有显著提高。具体来说,使用对抗样本训练的模型在检测不同 DeepFake 技术生成的伪造图像时,准确率提升范围在 5% - 10% 之间。这说明本文方法生成的对抗样本不仅能干扰 DeepFake 换脸过程,还能为 DeepFake 检测提供更具判别性的特征,从而提高检测模型的性能。
表VII 几种深度伪造检测方法在原始换脸图像和失真换脸图像上的平均准确率(%)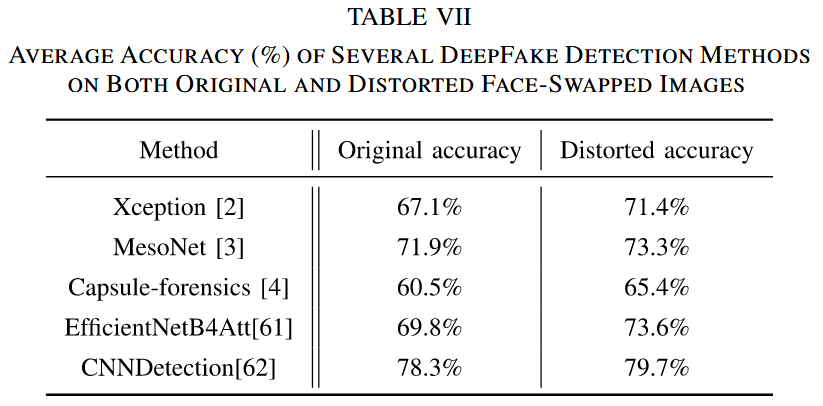
-
结论:本文方法生成的对抗样本可以有效增强 DeepFake 检测能力,为 DeepFake 检测提供了一种新的思路和方法,有助于提高在实际应用中对 DeepFake 伪造图像的检测效率和准确性。
面部风格迁移的泛化能力-Generalization to Facial Style Translation
这部分内容主要探讨了本文方法在面部风格迁移任务上的泛化能力,具体如下:
-
研究背景与目的:在验证了本文方法对 DeepFake 换脸的有效性后,为进一步评估其泛化性,将其应用于面部风格迁移任务。面部风格迁移旨在将输入面部图像的风格转换为目标风格,本文关注该任务中生成图像的视觉质量和保真度。
-
实验设置:使用 CelebA 数据集进行实验,选择基于深度学习的面部风格迁移模型作为目标模型。实验中,将本文方法生成的对抗样本输入到面部风格迁移模型中,观察其对输出图像的影响,并与合法样本的输出进行对比。
-
实验结果:通过对输出图像进行参考和非参考图像质量评估,结果表明本文方法生成的对抗样本能够有效干扰面部风格迁移过程。具体表现为,对抗样本输入下生成的风格迁移图像在结构相似性(SSIM)和特征相似性(FSIM)等指标上明显低于合法样本输入的情况,同时盲/无参考图像空间质量评估器(BRISQUE)分数更高,说明图像质量更差,视觉失真更严重。这意味着对抗样本能够显著降低风格迁移图像的质量,验证了本文方法在面部风格迁移任务上的有效性和泛化能力。

图7. StarGAN 在输入合法人脸图像和对抗性人脸图像时的示例结果。所生成的对抗样本适用于任意风格迁移(包括头发颜色、性别和年龄方面的风格迁移)。
图8. AttGAN 在输入合法人脸图像和对抗性人脸图像时的示例结果。所生成的对抗样本适用于任意风格迁移(包括头发颜色、性别和眼镜相关的风格迁移)。
表VIII 对受干扰的面部风格迁移图像进行图像质量评估的定量结果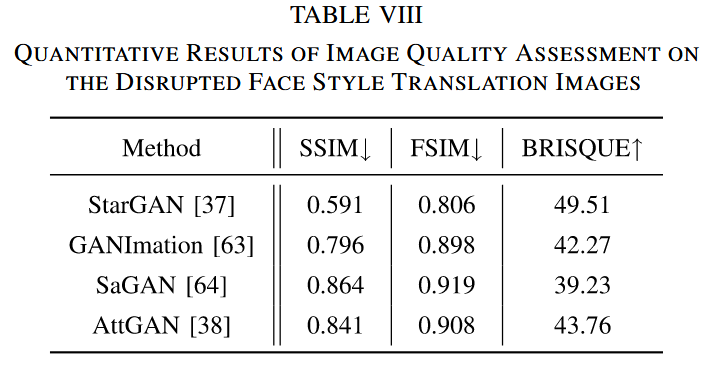
-
结论:本文方法不仅能够有效干扰 DeepFake 换脸,还能成功推广到面部风格迁移任务中,对其他面部操作模型具有良好的泛化性。这表明本文提出的对抗攻击方法具有一定的通用性,为保护面部图像免受各种面部操作的潜在威胁提供了更广泛的应用前景。
结论-Conclusion
这部分内容主要是对文章的总结和展望,阐述了所提方法的成果、优势、贡献以及未来研究方向,具体如下:
- 提出方法及成果:提出了一种基于生成对抗网络(GAN)的受限黑盒对抗攻击方法(TCA - GAN),用于对抗DeepFake换脸技术。该方法通过构建循环一致的GAN结构,包含两个生成器和两个域判别器,能够生成可转移的对抗样本,有效干扰 DeepFake 换脸过程。在实验中,生成的对抗样本在不影响原始图像视觉质量的前提下,显著降低了换脸图像的质量,验证了方法的有效性。
- 方法优势:
- 高效性:在应用阶段,相比基于优化的多迭代对抗样本生成方法,利用生成模型生成对抗样本节省了更多时间,尽管训练 TCA - GAN 时需要额外计算成本,但综合来看效率较高。
- 泛化性:通过消融实验证明,采用面部重建模型作为替代模型更有利于生成可转移的对抗样本,且方法不仅对 DeepFake 换脸有效,还能成功推广到面部风格迁移任务中,对不同的面部操作模型具有良好的泛化能力。
- 对检测的增强作用:生成的对抗样本为 DeepFake 检测提供了更具判别性的特征,使用对抗样本训练的检测模型在检测DeepFake换脸图像时准确率有显著提升,增强了 DeepFake 检测能力。
- 研究贡献:本文为保护面部图像免受 DeepFake 和其他面部操作的威胁提供了新的有效方法,对相关领域的研究和实际应用具有重要意义。
- 未来研究方向:未来将进一步探索加速对抗样本生成的方法,以提高方法的实用性和效率。同时,还将研究如何更好地利用对抗样本提升 DeepFake 检测的性能,以及拓展方法在其他面部相关任务中的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)