
本地部署Deepseek R1,并利用本地知识库创建RAG
巧用 Ollama,本地部署 DeepSeek R1 构建智能聊天新体验。
巧用 Ollama,本地部署 DeepSeek R1 构建智能聊天新体验。
微信搜索关注《AI科技论谈》
1 引言
想探索大语言模型,却怕硬件限制?
本教程带你用 Ollama 在 8GB 内存笔记本上部署 Deepseek R1 模型,再结合 LlamaIndex 和 Flask,构建 RAG 聊天机器人。
跟着教程操作,你可以用最少的资源在本地打造 RAG 聊天机器人。它能稳定运行,随时给出精准答案和深刻见解,助力你轻松踏入 AI 应用开发的大门。
2 DeepSeek R1:推理模型新高度
AI飞速发展,创新的脚步从未停歇,推理模型不断打破机器理解和处理复杂查询的极限。
其中,DeepSeek 研发的 DeepSeek R1 推理模型备受行业关注。
DeepSeek R1 创新性地将思维链(Chain of Thought,CoT)推理融入工作流程,旨在提升 AI 生成回复的准确性与透明度。
2.1 DeepSeek R1是什么
DeepSeek R1,也称为deepseek-reasoner,是一款利用思维链(CoT)来提高回复质量的推理模型。
与直接生成答案的传统模型不同,DeepSeek R1在给出最终输出之前,会先生成详细的推理过程(CoT)。这个中间步骤让模型能够“思考”问题,从而得出更准确、更可靠的答案。
该模型在需要逻辑推理、解决问题或多步分析的任务中特别有用。通过让用户能够查看思维链内容,DeepSeek R1还具备了透明度,开发者和用户可以借此了解模型是如何得出结论的。
2.2 DeepSeek R1主要特性
-
思维链(CoT)推理:DeepSeek R1在生成最终答案之前,会生成一个逐步的推理过程。这个思维链内容可以通过API访问,用户能够查看和分析模型的思考过程。
-
高上下文长度支持:API支持最大64K令牌的上下文长度,这使得它适合处理冗长复杂的查询。值得注意的是,思维链输出(最长32K令牌)不计入这64K的限制内。
-
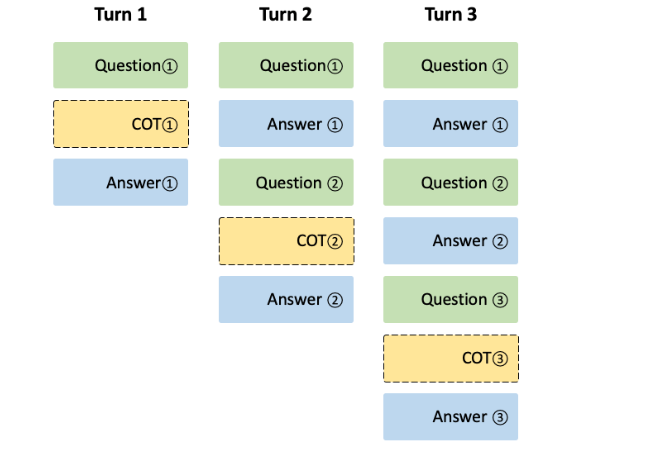
多轮对话:在多轮对话中,DeepSeek R1在每一轮都会输出思维链和最终答案。不过,前一轮的思维链不会延续到下一轮,以确保上下文保持聚焦且易于管理。
-
API集成:DeepSeek R1可通过API访问,便于集成到现有应用程序中。API支持聊天补全和聊天前缀补全(测试版)等功能,但函数调用和JSON输出等功能暂不支持。
2.3 DeepSeek R1工作原理
当你与DeepSeek R1交互时,模型会遵循以下两步流程:
-
生成思维链(CoT):模型首先会生成一个详细的推理过程(CoT),将问题分解为更小的逻辑步骤。这个中间输出会存储在
reasoning_content字段中。 -
生成最终答案:基于思维链,模型生成最终答案,并存储在
content字段中。这确保了回复是经过充分推理且准确的。
例如,如果你向模型提出一个复杂的数学问题,它会先列出解题步骤(思维链),然后再给出最终答案。
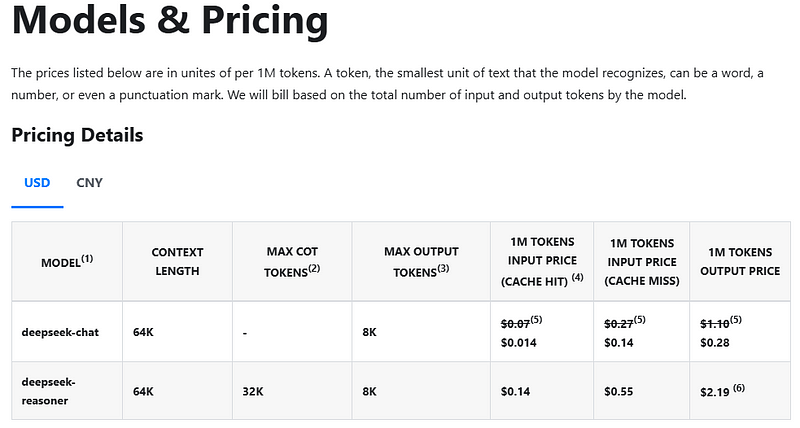
2.4 DeepSeek R1 API:参数与用法全解析
要使用DeepSeek R1,你需要与其API进行交互。下面为大家简要梳理其关键参数与使用要点:
- 输入参数:
-
max_tokens:控制最终回复的最大长度。默认值为4K令牌,最大值为8K令牌。注意,思维链输出最长可达32K令牌。 -
reasoning_effort(即将推出):这个参数将允许用户控制思维链输出的长度。
-
- 输出参数:
-
reasoning_content:模型生成的逐步推理过程。 -
content:模型生成的最终答案。
-
- 重要注意事项:
-
API不支持
temperature、top_p、presence_penalty和frequency_penalty等参数。设置这些参数不会触发错误,但对输出没有任何影响。 -
输入消息中不应包含
reasoning_content字段,否则会导致400错误。
-
2.5 功能支持清单
-
支持的功能:聊天补全、聊天前缀补全(测试版)
-
不支持的功能:函数调用、JSON输出、FIM(中间填充,测试版)
3 DeepSeek R1优势
DeepSeek R1 优势在于融合准确性与透明度,生成答案时会给出思维链,让用户既得答案,又懂推理过程。这让它在教育、客户支持、决策系统等对可解释性要求高的场景极具价值。
4 使用Ollama部署DeepSeek R1
在本地机器上部署像DeepSeek R1这样的大语言模型(LLMs)可能会让人望而却步,尤其是在硬件资源有限情况下。不过,借助 Ollama 这样的工具,即便是 8GB 内存的普通 Windows 笔记本,也能轻松运行 DeepSeek R1。接下来,就为你详细介绍具体部署步骤。
Ollama
Ollama是一款轻量级且高效的工具,专为在消费级硬件上运行大语言模型而设计。它简化了大语言模型的部署和管理流程,让那些想要试用人工智能模型,却又无需高端基础设施的开发者和爱好者也能轻松上手。
准备工作
在开始之前,请确保你的系统满足以下要求:
-
操作系统:Windows 10或更高版本。
-
内存:至少8GB(建议16GB,以获得更流畅的性能)。
-
存储空间:有足够的磁盘空间来存储模型(通常为5 - 10GB)。
-
Python:已安装在你的机器上(最好是Python 3.8或更高版本)。
-
Git:已安装,用于克隆存储库。
步骤1:安装Ollama
-
下载Ollama:访问Ollama的官方GitHub存储库,下载适用于Windows的最新版本。
-
安装Ollama:运行安装程序,并按照屏幕上的说明完成安装。
-
验证安装:打开终端(命令提示符或PowerShell),运行以下命令来验证Ollama是否安装正确:
ollama --version
如果安装成功,你应该能看到Ollama的版本号。
步骤2:下载DeepSeek R1模型
-
下载模型:Ollama支持多种模型,包括DeepSeek R1(15亿参数)。要下载该模型,使用以下命令:
ollama pull deepseek-r1:1.5b
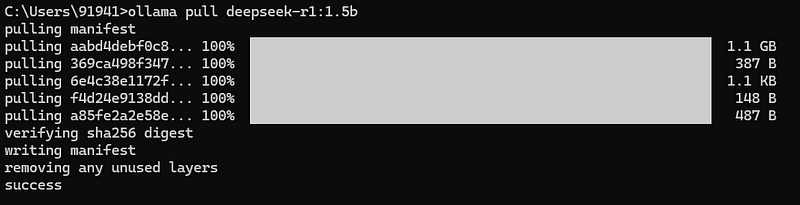
这条命令会将DeepSeek R1模型下载并存储在你本地的机器上。
2.验证模型下载:下载完成后,你可以通过列出所有可用模型来验证是否下载成功
ollama list
步骤3:在本地运行DeepSeek R1
-
启动模型:要启动DeepSeek R1模型,使用以下命令:
ollama run deepseek-r1
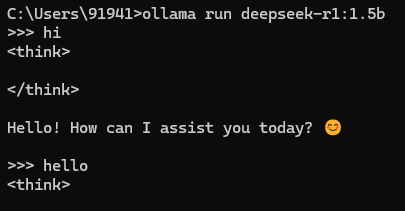
这会启动模型并打开交互式会话,你可以在其中开始与模型进行交互。
2.测试模型:模型运行起来后,你可以通过提问或输入提示来测试它。例如:
> 法国的首都是哪里?
步骤4:使用DeepSeek R1和LlamaIndex的RAG构建聊天机器人
from flask import Flask, request, render_template, jsonify
import os
from llama_index.core import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.core.indices.postprocessor import SentenceTransformerRerank
from llama_index.core import load_index_from_storage
#from gpt4all import GPT4All
#from langchain.llms import GPT4All
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
# 句子嵌入模型
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
app = Flask(__name__)
# 设置LLM和嵌入模型
llm = Ollama(model="deepseek-r1", request_timeout=120.0)
def build_sentence_window_index(documents,llm, embed_model=OpenAIEmbedding(),sentence_window_size=3,
save_dir="sentence_index",):
# 创建句子窗口节点解析器,默认设置
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=sentence_window_size,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
Settings.llm = llm
Settings.embed_model = embed_model
Settings.node_parser = node_parser
if not os.path.exists(save_dir):
sentence_index = VectorStoreIndex.from_documents(
documents, embed_model = embed_model
)
sentence_index.storage_context.persist(persist_dir=save_dir)
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
embed_model = embed_model
)
return sentence_index
def get_sentence_window_query_engine(sentence_index, similarity_top_k=6, rerank_top_n=2):
# 定义后处理程序
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return sentence_window_engine
from llama_index.llms.openai import OpenAI
from data.dataprovider import key
from llama_index.core import SimpleDirectoryReader
#OpenAI.api_key = key
documents = SimpleDirectoryReader(
input_files=[r"data/eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
from llama_index.core import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
index = build_sentence_window_index(
[document],
#llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1,api_key=key),
llm = llm, #替换为你的模型路径
save_dir="./sentence_index",
)
query_engine = get_sentence_window_query_engine(index, similarity_top_k=6)
def chat_bot_rag(query):
window_response = query_engine.query(
query
)
return window_response
# 定义Flask路由
@app.route('/')
def home():
return render_template('bot_1.html')
@app.route('/chat', methods=['POST'])
def chat():
user_message = request.form['user_input']
bot_message = chat_bot_rag(user_message)
return jsonify({'response': str(bot_message)})
if __name__ == '__main__':
app.run()
代码解释
这段 Python 代码基于 Flask 框架搭建网络应用,核心是创建聊天机器人。该聊天机器人使用llama_index库中的多个组件来执行信息检索和文本生成任务。以下是对代码的详细解释:
-
配置:
-
embed_model = OpenAIEmbedding()初始化OpenAI嵌入模型,用于将文本转换为向量表示。 -
app = Flask(__name__)设置Flask应用程序。 -
llm = Ollama(…)初始化名为Ollama的语言模型,大概基于DeepSeek R1架构。这将用于语言任务,并设置了请求超时时间。
-
-
函数定义:
build_sentence_window_index():此函数通过处理给定文档为聊天机器人创建索引。它:-
初始化
SentenceWindowNodeParser,用于将文本解析为句子窗口(一种滑动窗口方法)。 -
设置语言模型和嵌入模型的全局设置。
- 检查指定目录(
save_dir)是否存在:-
如果不存在,则从文档创建一个新的
VectorStoreIndex并保存索引。 -
如果存在,则从存储中加载现有索引。
-
返回构建或加载的索引。
-
-
get_sentence_window_query_engine():此函数为聊天机器人设置查询引擎:- 定义两个后处理器:
-
MetadataReplacementPostProcessor用于在查询结果处理过程中替换元数据。 -
SentenceTransformerRerank用于使用预训练的句子变压器模型对检索结果进行重新排序。
-
-
根据索引创建查询引擎,并使用指定的相似度阈值和重新排序设置。
-
返回配置好的查询引擎。
- 定义两个后处理器:
-
加载文档:代码使用
SimpleDirectoryReader从位于data目录下的PDF文件加载数据。加载的文本被合并成一个Document对象,然后用于创建索引。 -
构建索引和设置查询引擎:调用
build_sentence_window_index()从文档构建索引,调用get_sentence_window_query_engine()设置用于查询索引的查询引擎。 -
查询函数:
chat_bot_rag()函数使用查询引擎查询索引。它根据用户输入进行相似度搜索,并返回检索到的响应。 -
Flask路由:Flask应用程序有两条路由:
-
’/’:渲染主聊天界面(bot_1.html)。 -
’/chat’:处理聊天请求。它从POST请求中获取用户输入,通过聊天机器人进行处理,并将机器人的响应以JSON格式返回。
-
-
运行应用程序:
if __name__ == ‘__main__’: app.run()启动Flask开发服务器,允许通过Web浏览器访问应用程序。
5 结语
对渴望试用强大语言模型,却受限于高端硬件的开发者和 AI 爱好者来说,通过 Ollama 在本地 Windows 机器部署 DeepSeek R1 是个好消息。按照分步指南,你已学会安装 Ollama、运行 DeepSeek R1,还能用 Ollama API 集成到应用,探索思维链(CoT)推理等特性。
现在 DeepSeek R1 已在本地运行,后续你可以搭建智能聊天机器人、决策支持系统或教育工具。祝编码愉快~
推荐书单
《基于大模型的RAG应用开发与优化——构建企业级LLM应用》
本书是一本全面介绍基于大语言模型的RAG应用开发的专业图书。本书共分为3篇:预备篇、基础篇和高级篇。预备篇旨在帮助你建立起对大模型与RAG的基本认识,并引导你搭建起RAG应用开发的基础环境;基础篇聚焦于经典RAG应用开发的核心要素与阶段,介绍关键模块的开发过程,剖析相关的技术原理,为后面的深入学习打下坚实的基础;高级篇聚焦于RAG应用开发的高阶模块与技巧,特别是在企业级RAG应用开发中的优化策略与技术实现,并探索了一些新型的RAG工作流与范式,旨在帮助你了解新的RAG应用技术发展,掌握RAG应用的全方位开发能力。
购买链接:https://item.jd.com/14317749.html

精彩回顾
VSCode本地部署DeepSeek R1,打造专属AI编程助手

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)