
数据清洗中的异常值判断与处理
数据清洗中的异常值判断方法
一、什么是异常值?
异常值(Outliers)是指数据集中明显偏离其他观测值的数值,有时也称为“极端值”,“离群值”等。可以是由数据录入错误、测量误差、系统故障、自然波动或真实的极端时间引起。
如果数据中存在异常值,异常值会导致数据分布不均匀,甚至可能会扭曲数据结果,降低机器学习模型的泛化能力,导致错误的业务决策等等。
二、异常值的类型
-
单变量异常值:单个特征中的极端值(如年龄为200岁)
-
多变量异常值:多个特征组合下的异常(如身高1.5米但体重200公斤)
-
全局异常值:明显偏离整个数据集的样本
-
局部异常值:在特定子集中异常(如某地区人均收入突增)
三、异常值的判断
1.单变量异常值
单变量异常值是指某个特征(变量)中明显偏离其他值的极端值。
单个变量进行异常值判断一般有描述分析、Z-score、箱线图以及预测模型:ARIMA等。
(1)标准差
原理:计算数据点与均值的标准差距离,超出阈值的视为异常。
三倍标准差参照(3sigma原则):在数据服从正态分布时使用的较多。
公式: (其中
为均值,
为标准差)
阈值:通常取 |Z| > 3
示例:
import numpy as np
from scipy import stats
z_scores = stats.zscore(df['age']) #对age列求Z
outliers = np.where(np.abs(z_scores)>3)
#outliers是检测出来的“age”列中异常值的索引(2)四分位距法(IQR)
原理:利用四分位数定义数据范围
箱线图
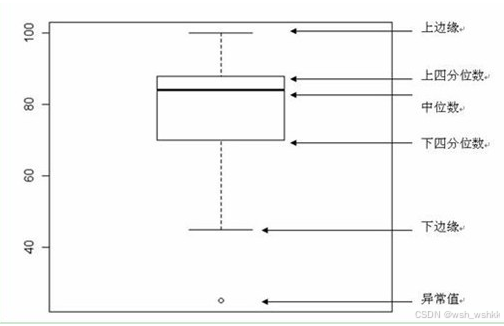
上边缘和下边缘:是异常值的边界,之间是正常值
上四分位数是75%,下四分位数是25%
步骤:1.计算第一四分位数Q1(1/4)和第三分位数Q3(3/4)
2.计算四分位距IQR=Q3-Q1
3.定义正常的范围:[ Q1-1.5*IQR , Q3+1.5*IQR ]
示例:
Q1 = df['age'].quantile(0.25)
Q3 = df['age'].quantile(0.75)
IQR = Q3 -Q1
#计算正常值的范围
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers =df[(df['age']<lower_bound) | (df['age']>upper_bound)](3)预测模型:ARIMA
ARIMA是一种用来分析时间序列数据的模型。时间序列数据就是按照时间顺序排列的数据,比如每天的气温、每月的销售额等。ARIMA模型可以帮助我们预测未来会发生什么值。
原理:假设我们有一组时间序列数据,比如每天的销售额。我们用ARIMA模型来预测每一天的销售额。然后,我们比较实际的销售额和模型预测的销售额,看看它们之间的差距。
-
如果差距很小,说明实际值和预测值差不多,这个数据点是正常的。
-
如果差距很大,说明实际值和预测值差很多,这个数据点可能就是异常值。
步骤:1.拟合ARIMA模型:先用历史数据训练ARIMA模型,让模型学会预测
2.计算预测值:用训练好的模型预测每个时间点的值
3.计算残差:用实际值-预测值,得到差值(残差)
4.判断异常值:设定一个阈值(例如差距的3倍标准差),如果某个时间节点的值超过了阈值,那么则为异常值
示例:
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
#数据示例
df = pd.Series([100, 102, 101, 103, 105, 104, 106, 107, 108, 150, 109, 110])
#拟合ARIMA模型
model=ARIMA(df,order=(1,1,1))
model_fit=model.fit()
#预测
predictions = model_fit.predict(start=0,end=len(df)-1,dynamic=False) #dynamic=False使用静态预测
#计算残差
residuals=df-predictions
#设置阈值(3倍标准差为例子)
threshold = 3*residuals.std()
#找出异常值
outliers = residuals[abs(residuals)>threshold](4)处理方法
- 删除:直接删除异常值
- 替换:用均值、中位数或上下限值替换
- 转换:对数转换或分箱处理
2.多变量异常值:多个特征组合下的异常值
(1)散点图与分布图
原理:通过可视化的方法观察多变量之间的关系,识别偏离整体分布趋势的点
示例:
import seaborn as sns
import pandas as pd
# 假设 df 是包含 'height' 和 'weight' 列的数据表
sns.scatterplot(x='height', y='weight', data=df)-
散点图可以直观地展示两个变量(如身高和体重)之间的关系。
-
如果某个点明显偏离其他点的分布趋势,它可能是异常值
(2)马氏距离
原理:计算数据点与分布中心的距离,考虑特征相关性
公式: 其中
是均值向量 ,
是协方差矩阵
示例:
from scipy.spatial.distance import mahalanobis
#求均值向量
mean = np.mean(data[['height', 'weight']], axis=0)
#求协方差矩阵
cov = np.cov(data[['height', 'weight']], rowvar=False)
#求矩阵的逆
inv_cov = np.linalg.inv(cov)
#计算每个样本点的马氏距离
distances = [mahalanobis(row, mean, inv_cov) for row in data[['height', 'weight']].values]
threshold=np.mean(distances) + 3 * np.std(distances)
outliers = np.where(distances > threshold)(3)聚类算法 (DBSCAN)
原理:使用聚类算法标记异常点。DBSCAN通过密度划分数据点,将低密度的区域点标记为异常。
示例:
from sklearn.cluster import DBSCAN
# 假设 data 是包含 'height' 和 'weight' 列的数据框
X = data[['height', 'weight']].values
dbscan = DBSCAN(eps=3, min_samples=5) # 参数需要根据数据调整
labels = dbscan.fit_predict(X)
# 标记异常点(-1 表示异常)
outliers = np.where(labels == -1)[0](4)处理方法
-
删除:删除异常记录
-
替换:用多变量均值或中位数替换
-
聚类:使用聚类算法(如DBSCAN)标记异常点
3.全局异常值:明显偏离整个数据集的样本
(1)孤独森林(Isolation Forest)
原理:通过随机分隔特征空间隔离异常点
示例:
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination=0.05) # contamination 设置异常点比例
model.fit(data)
outliers = model.predict(data) == -1 # 异常点标记为 -1(2)局部离群因子(LOF)
原理:LOF是一种基于密度的异常检测算法。通过计算每个点相对于其邻居的局部密度偏差来判断异常。如果一个点的局部密度明显低于其邻居,则被认为是异常值即。
示例:
from sklearn.neighbors import LocalOutlierFactor
# 假设 data 是包含特征的数据框
model = LocalOutlierFactor(n_neighbors=20) # n_neighbors 设置邻居数量
outliers = model.fit_predict(data) == -1 # 异常点标记为 -1(3)处理方法
-
删除:删除异常记录
-
替换:用全局均值或中位数替换
-
保留:如果异常代表真实事件(如金融欺诈),则保留
4.局部异常值:在特定子集中的异常
(1)分组检测
原理:按分组(如地区)分别检测异常值
示例:
import pandas as pd
grouped = df.groupby('region') # 按地区分组
for name, group in grouped: # 遍历每个分组
Q1 = group['income'].quantile(0.25) # 计算分组内收入的第25百分位数
Q3 = group['income'].quantile(0.75) # 计算分组内收入的第75百分位数
IQR = Q3 - Q1 # 计算四分位距
lower_bound = Q1 - 1.5 * IQR # 下界
upper_bound = Q3 + 1.5 * IQR # 上界
outliers = group[(group['income'] < lower_bound) | (group['income'] > upper_bound)] # 检测异常值
print(f"在地区 {name} 中检测到的异常值:")
print(outliers)(2)局部离群因子(LOF)
原理:LOF 是一种基于密度的异常检测算法,它通过计算每个数据点在其局部邻域中的密度偏差来判断是否为异常值。在子集中使用 LOF 可以更精准地检测局部异常。
示例:
from sklearn.neighbors import LocalOutlierFactor
# 首先将地区转换为数值(如果地区是分类变量)
df['region_code'] = df['region'].astype('category').cat.codes
# 使用 LOF 检测局部异常
model = LocalOutlierFactor(n_neighbors=20) # 设置邻居数量
outliers = model.fit_predict(data[['income', 'region_code']]) == -1 # 异常点标记为 -1
# 标记异常值
df['is_anomaly'] = outliers
print("标记为异常的记录:")
print(f[f['is_anomaly']])(3)处理办法
-
删除:删除局部异常记录
-
替换:用子集均值或中位数替换
-
保留:如果异常代表真实事件(如政策影响),则保留
四、总结
建议流程:单变量检测 → 多变量检测 →全局与局部检测 → 科学处理

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)