
【人工智能】基于卷积神经网络的水果蔬菜各种食材目标检测
水果和蔬菜目标检测系统,主要应用于智能厨房、自动化采摘和食品安全监测等场景。通过自制数据集和深度学习算法(结合CNN与YOLO),实现对多种食材(如苹果、香蕉、甜椒等)的实时检测与识别。数据集的构建过程涉及数据采集、清洗、标注和预处理,确保数据的多样性和准确性。在算法模型方面,采用YOLO作为基础框架,通过结合卷积神经网络的特征提取能力,提升了检测精度和速度。
一、背景意义
随着全球人口的持续增长,食品安全与营养健康问题日益受到重视。水果和蔬菜作为日常饮食中不可或缺的组成部分,其质量和新鲜度直接影响人们的健康。然而,传统的人工检测方法不仅效率低下,而且容易受到人为因素的影响,导致检测结果的不准确。针对这一问题,自动化和智能化的检测技术显得尤为重要。通过引入深度学习算法,尤其是YOLOv5等先进的目标检测模型,可以实现对水果和蔬菜的实时、准确检测。这不仅有助于提升生产效率,减少人力成本,还能有效降低食品安全隐患,提高消费者对食品质量的信任度。
二、数据集
2.1数据采集
数据采集是构建水果和蔬菜目标检测数据集的第一步,涉及到收集与项目目标相关的图像数据。可以通过多种途径进行数据采集:
-
拍摄:可以在市场、超市或农田中使用相机拍摄各种水果和蔬菜的照片。为了保证数据的多样性,应在不同的光照条件、角度和背景下拍摄。这种方法能确保数据的真实性和代表性。
-
网络爬虫:利用网络爬虫工具从网上抓取相关的图片,特别是社交媒体、电子商务网站和专业食品网站上的图片。这种方式能迅速积累大量样本,但需要注意版权和使用权限。
-
公共数据集:查找已有的公共数据集,如Kaggle、ImageNet等,下载与项目相关的图像。这不仅节省了时间,也能为模型训练提供基础数据。
数据清洗的目的是剔除不符合要求的图像,以确保数据集的质量:
-
去重:检查采集的图像是否存在重复的样本,并将其删除。这可以通过对比图像的哈希值来实现,确保每个样本都是独一无二的。
-
格式转换:确保所有图像的格式一致,常用的格式包括JPEG和PNG。对于不合适的文件格式,需要进行转换,以便后续处理。
-
尺寸规范:统一图像的尺寸,通常选择适合模型输入的固定尺寸,如416x416或640x640。可以使用图像处理工具或编程库(如OpenCV)进行批量处理。
-
质量检查:检查图像的清晰度和可用性,剔除模糊、过暗或过亮的图像。确保每张图片都能清晰展示目标物体,以便于后续的标注和训练。
2.2数据标注
数据标注是数据集制作中至关重要的一步,主要涉及为每张图像中的目标物体添加标识:
-
选择标注工具:使用LabelImg、VOTT等标注工具来进行标注。LabelImg是一个广泛使用的开源工具,可以方便地创建XML或TXT格式的标注文件。
-
绘制边界框:逐一打开每张图像,使用矩形工具为每个目标物体绘制边界框,并标注相应的类别(如“苹果”、“香蕉”、“甜椒”等)。确保每个目标物体都被准确框选,以避免漏标或误标。
-
保存标注数据:在标注完成后,确保将所有标注数据保存到指定格式的文件中。这些标注文件将用于后续模型训练时读取目标物体的位置和类别信息。
-
验证标注质量:在标注完成后,进行质量检查,随机抽取若干图像进行复审,确保标注的准确性和一致性。
使用LabelImg进行数据集标注是一个复杂而耗时的过程,尤其是在处理大量图像时。首先,需要安装LabelImg软件并打开待标注的图像文件夹。接着,逐一选择图像,使用矩形框工具为每个目标物体绘制边界框,并在弹出的类别选择框中选择相应的食材类别。每标注完一张图像,都必须保存标注结果,确保数据的安全性。由于类别较多,标注人员需要保持高度的注意力,以避免漏标或误标。此外,在标注的过程中,可能会遇到图像质量不佳、目标物体被遮挡等情况,增加了标注的难度。因此,整个标注过程不仅需要耗费大量的时间与精力,还要求标注人员具备一定的耐心和专业知识,以保证标注数据的准确性和完整性。
水果蔬菜图片数据集中包含以下几种类别:
- 苹果:常见的水果,口感鲜甜,富含维生素。
- 香蕉:富含钾元素的水果,适合作为能量补充。
- 书:用于记录食谱或烹饪技巧的书籍。
- 甜椒:色彩丰富的蔬菜,常用于沙拉和炒菜。
- 胡萝卜:富含维生素的根茎类蔬菜,常用于烹饪或生吃。
- 麦片盒:用于包装早餐麦片的盒子。
- 大蒜:常用于调味的食材,具有独特的香味。
- 青辣椒:用作调味的蔬菜,带有一定的辣味。
- 辣椒酱:用于增添菜肴风味的调味品。
- 秋葵:富含营养的蔬菜,通常用于炖菜或炒菜。
- 洋葱:常见的调味蔬菜,具有独特的香气和味道。
- 橙子:富含维生素C的水果,通常用于饮料或生吃。
- 土豆:多用途的根茎类蔬菜,可以用来制作各种菜肴。
- 红辣椒:用于增添菜肴色彩和辣味的蔬菜。
- 海绵葫芦:常用的蔬菜,适合炖汤和煮菜。
- 西红柿:广泛使用的蔬菜,营养丰富,适合多种烹饪方式。
- 牛油果:富含健康脂肪的水果,常用于沙拉或涂抹。
- 培根:经过腌制的肉类,常用于早餐或作为配料。
- 牛肉:常见的肉类,富含蛋白质,适合多种烹饪方式。
- 面包:基本的主食,适合搭配各种食材。
- 牛蒡:营养丰富的根茎类蔬菜,常用于炖菜。
- 黄油:常用于烹饪和烘焙的乳制品。
- 卷心菜:富含纤维的蔬菜,适合生吃或熟食。
- 罐装玉米:方便的食材,适合用于沙拉或汤中。
- 罐装金枪鱼:便捷的鱼类食品,适合沙拉或三明治。
- 胡萝卜:富含维生素的根茎类蔬菜,常用于烹饪或生吃。
- 奶酪:多用途的乳制品,适合搭配多种食材。
- 鸡肉:常见的肉类,富含蛋白质,适合多种烹饪方式。
- 辣椒粉:用于增添菜肴辣味的调味品。
- 巧克力面包:甜点,适合早餐或小吃。
- 肉桂:常用于烘焙和调味的香料。
- 食用油:用于烹饪和调味的基础材料。
- 玉米:多用途的谷物,适合用于多种料理。
- 玉米片:早餐谷物,适合搭配牛奶或酸奶。
- 蟹肉:富含蛋白质的海鲜,适合制作多种菜肴。
- 黄瓜:清爽的蔬菜,适合做沙拉或生吃。
- 咖喱粉:用于增添菜肴风味的调味品。
- 饺子:常见的传统食品,适合蒸、煮或煎。
- 鸡蛋:富含蛋白质的食材,适合多种烹饪方式。
- 鱼饼:用鱼制成的食品,适合炸或煮。
- 薯条:常见的小吃,适合搭配各种调味品。
- 大蒜:常用于调味的食材,具有独特的香味。
- 姜:常用于调味和药用的根茎类植物。
- 青葱:用于增添菜肴香气的调味蔬菜。
- 火腿:经过腌制的肉类,常用于三明治或早餐。
- 哈希棕:用土豆制成的早餐食品,常见于西式早餐。
- 热狗:常见的小吃,适合户外烧烤或快餐。
- 冰块:用于饮料和食品保存的冷冻物。
- 番茄酱:常用于汉堡和薯条的调味品。
- 泡菜:发酵的蔬菜,常用于韩国料理。
- 柠檬:酸味水果,常用于饮料和调味。
- 柠檬汁:用于增添酸味的液体调味品。
- 橘子:小型水果,口感鲜甜,富含维生素C。
- 棉花糖:甜点,适合烧烤或作为零食。
- 美乃滋:用于三明治和沙拉的调味品。
- 牛奶:常见的乳制品,富含营养。
- 马苏里拉奶酪:用于比萨和意大利菜的乳制品。
- 蘑菇:富含营养的食材,适合多种烹饪方式。
- 芥末:用于增添辛辣味的调味品。
- 玉米片:小吃,适合搭配酱料或直接食用。
- 面条:常见的主食,适合制作各类面食。
- 巧克力酱:甜点酱,常用于冰淇淋或面包。
- 橄榄油:健康的食用油,适合烹饪和调味。
- 洋葱:用于增添菜肴风味的常见蔬菜。
- 奥利奥饼干:甜点,适合作为零食或搭配牛奶。
- 帕尔马干酪:用于意大利料理的硬质奶酪。
- 香菜:用于调味的草本植物,适合多种菜肴。
- 意大利面:常见的主食,适合搭配各种酱料。
- 花生酱:用于涂抹或制作甜点的调味酱。
- 梨:多汁的水果,适合生吃或制作甜点。
- 胡椒:常见的调味品,适合增添菜肴风味。
- 辣椒粉:用于增添菜肴辣味的调味品。
- 腌菜:经过腌制的蔬菜,适合搭配主食。
- 泡菜:发酵的蔬菜,常用于韩国料理。
- 红辣椒:用于增添菜肴色彩和辣味的蔬菜。
- 菠萝:热带水果,口感甜美,常用于甜点和沙拉。
- 猪肉:常见的肉类,适合多种烹饪方式。
- 土豆:多用途的根茎类蔬菜,可以用来制作各种菜肴。
- 拉面:传统的面食,适合搭配汤汁。
- 红酒:用于烹饪和饮用的酒类,具有丰富的风味。
- 米饭:常见的主食,适合搭配各种菜肴。
- 盐:基本调味品,适合增添菜肴风味。
- 香肠:经过腌制的肉类,适合烧烤或煮食。
- 海藻:富含营养的海产品,常用于汤和寿司。
- 芝麻:用于增添香气的种子,常用于调味。
- 芝麻油:用于调味和烹饪的油类。
- 虾酱:用于增添海鲜风味的调味品。
- 酱油:常见的调味品,适合用于炒菜和腌制。
- 午餐肉:便捷的肉类食品,适合炒菜或三明治。
- 鱿鱼:海鲜,适合多种烹饪方式。
- 草莓:甜美的水果,适合生吃或制作甜点。
- 糖:基本调味品,常用于烘焙和饮料。
- 红薯:营养丰富的根茎类蔬菜,适合蒸、煮或烤。
- 豆腐:富含蛋白质的植物性食材,适合多种烹饪方式。
- 西红柿:广泛使用的蔬菜,营养丰富,适合多种烹饪方式。
- 芥末:用于增添辛辣味的调味品。
- 西瓜:清爽的水果,适合夏季消暑。
2.3数据预处理
数据预处理是为模型训练做好准备的最后一步,旨在提高模型的训练效果:
-
数据增强:通过旋转、翻转、缩放、亮度调整等方法对图像进行数据增强。这可以增加数据集的多样性,帮助模型更好地适应不同的场景和条件,提高泛化能力。
-
归一化处理:对图像数据进行归一化处理,将像素值缩放到[0, 1]或[-1, 1]的范围内。这可以加速模型的收敛,提高训练效率。
-
划分数据集:将处理后的数据集划分为训练集、验证集和测试集,通常按照70%训练、20%验证和10%测试的比例分配。确保每个子集中的类别分布一致,以便模型的训练和评估。
-
格式转换:根据所使用的深度学习框架的要求,将图像和标注数据转换为适合模型输入的格式。对于YOLO模型,通常需要生成对应的TXT文件,记录每张图像中的目标信息。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是一种专门设计用于处理图像数据的深度学习算法。其结构主要由卷积层、池化层和全连接层组成。卷积层通过多个卷积核(滤波器)对输入图像进行局部特征提取,生成特征图。这些卷积核能够识别图像中的基本特征,比如边缘、角点和纹理。池化层通常采用最大池化或平均池化操作,旨在减少特征图的尺寸,从而降低计算复杂性并保留主要特征信息。最终,全连接层将高层特征展平后传递到输出层,完成分类任务。

CNN在水果和蔬菜目标检测模型中的优势在于其强大的自动特征提取能力和高准确率。由于卷积操作的局部连接特性,CNN能够有效捕捉图像中的空间特征,而不需要手动设计特征。这种能力使得CNN在识别不同种类的水果和蔬菜时表现优异,尤其是在处理多样化的食材背景时。此外,CNN的参数共享机制显著减少了模型的参数数量,从而降低了过拟合的风险,提高了模型在未见数据上的泛化能力。这些优势使得CNN成为水果和蔬菜目标检测的首选算法。

YOLO(You Only Look Once)是一种实时目标检测算法,其主要结构包括卷积神经网络、全连接层和输出层。YOLO将目标检测问题视为回归问题,通过一个单一的神经网络直接预测边界框和类别概率。具体而言,YOLO将输入图像划分为S x S的网格,每个网格预测固定数量的边界框及其对应的置信度。特征图的生成通过多个卷积层实现,网络的输出则包含了多个边界框及其类别概率。YOLO通过非极大值抑制(NMS)方法过滤掉重复的检测结果,从而实现高效的目标检测。
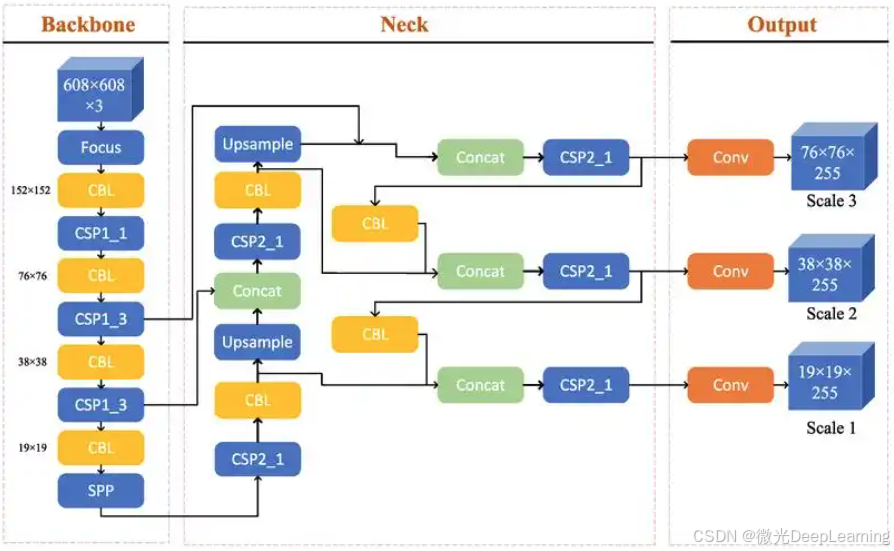
YOLO算法在水果和蔬菜目标检测中的优势在于其高效性和实时性。由于YOLO仅需对图像进行一次前向传播,显著提高了检测速度,使其能够在视频流等实时应用中表现出色。这种快速检测能力特别适合于智能厨房、自动化采摘等场景。此外,YOLO的全局信息处理能力使其能够对不同尺寸和颜色的食材进行有效检测,适应性强。YOLO的高效率与准确性,使其成为水果和蔬菜目标检测的有效算法。
结合CNN与YOLO构建一个改进的检测模型,例如YOLOv4。该模型在YOLO的基础上引入了更深的网络结构和先进的特征提取方法,如CSPDarknet作为骨干网络,以增强特征提取能力。同时,YOLOv4采用了多种数据增强技术(如Mosaic、MixUp等),以增加训练数据的多样性,从而提高模型的鲁棒性。通过引入注意力机制,YOLOv4能够更加聚焦于图像中的重要特征,从而提高水果和蔬菜的检测精度。这种改进后的模型不仅保留了YOLO的实时性,还通过增强特征学习和数据处理能力,进一步提升了检测的准确性和适应性。结合多种先进技术后,YOLOv4在水果和蔬菜目标检测中能够有效应对复杂环境和多样化场景,为食品安全和智能农业提供可靠的技术支持。
3.2模型训练
1. 数据集预处理
在进行YOLO项目开发之前,首先需要准备和划分数据集。数据集应包含多种类水果和蔬菜的图像(如苹果、香蕉、甜椒等),并确保样本的多样性和代表性。可以通过人工拍摄或网络爬虫等方式收集样本。随后,将数据集随机划分为训练集、验证集和测试集,通常推荐的比例为70%训练、20%验证、10%测试。数据标注是YOLO项目中的关键环节,准确标注直接影响模型的训练效果。使用LabelImg等标注工具为每张图像中的水果和蔬菜进行标注,通常采用矩形框的方式。为每个框选择相应的类别,并记录位置信息。以下是数据集划分的示例代码:
import os
import random
import shutil
# 定义数据集路径
dataset_path = 'path/to/dataset'
images = os.listdir(dataset_path)
# 随机划分数据集
random.shuffle(images)
train_images = images[:int(len(images) * 0.7)]
val_images = images[int(len(images) * 0.7):int(len(images) * 0.9)]
test_images = images[int(len(images) * 0.9):]
# 创建新的目录以存放划分后的数据集
os.makedirs('train', exist_ok=True)
os.makedirs('val', exist_ok=True)
os.makedirs('test', exist_ok=True)
for image in train_images:
shutil.copy(os.path.join(dataset_path, image), 'train/')
for image in val_images:
shutil.copy(os.path.join(dataset_path, image), 'val/')
for image in test_images:
shutil.copy(os.path.join(dataset_path, image), 'test/')2. 模型训练
准备模型的配置文件(如yolov4.cfg),设置网络参数、学习率和批量大小等。创建数据描述文件(如obj.data),指定训练和验证数据集路径及类别数。模型配置完成后,可以开始训练YOLO模型。使用命令行运行YOLO训练命令,模型将开始处理训练数据。训练过程中监控损失值和准确率,以确保模型逐步收敛。以下是训练的示例命令:
./darknet detector train cfg/voc.data cfg/yolov4.cfg yolov4.weights3. 模型评估
完成训练后,对模型进行测试和评估是检验其性能的关键步骤。使用测试集中的图像,利用训练好的YOLO模型进行目标检测,生成检测结果并进行可视化。可以使用OpenCV对检测结果进行绘制,显示边界框和类别标签。以下是测试和可视化的示例代码:
import cv2
import matplotlib.pyplot as plt
# 读取测试图像
image = cv2.imread('test.jpg')
# 显示图像
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title('Predictions')
plt.axis('off') # 不显示坐标轴
plt.show()四、总结
通过自制数据集和深度学习算法构建一个高效的水果和蔬菜目标检测系统。在数据集方面,首先通过精准的标注和合理的划分,为模型训练提供了丰富的样本支持。结合卷积神经网络(CNN)与YOLO算法的优点,构建了改进的YOLO模型,以提升检测的准确率和实时性。YOLOv5由于其结构轻量化和高效处理能力,尤其适合在移动设备和边缘计算环境中运行。最终,通过对测试结果的深入分析,验证了所构建模型的有效性和实用性。此项目不仅为智能厨房和自动化采摘提供了技术支持,还为未来的研究提供了可行的方向,有助于推动农业的现代化进程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 44
44 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)