InternVL: Scaling up Vision Foundation Models and Aligningfor Generic Visual-Linguistic Tasks
1、设计了一个大规模的视觉语言模型InternVL,将视觉模型扩展到60亿参数,并于LLM进行对齐2、采用了3个阶段进行逐步对齐,在视觉感知任务上,视觉语言和MLLMs上实现先进的性能
一、TL;DR
- 设计了一个大规模的视觉语言模型InternVL,将视觉模型扩展到60亿参数,并于LLM进行对齐
- 采用了3个阶段进行逐步对齐,在视觉感知任务上,视觉语言和MLLMs上实现先进的性能
- 本文如何做的数据质量其实也是重点,如何filter掉噪音数据是核心竞争力
二、贡献和解决的问题
现在的现有的VLLMs通常使用对齐层(Qformer或者linear层)来对齐视觉和语言模型的特征,但这种方式存在几点局限:
-
参数规模的差异。大型LLMs的参数规模已高达数千亿,sota的视觉模型或者VLM才几十亿。这种差距可能导致LLMs的能力无法得到充分利用。
-
表征不一致。视觉模型通常在纯视觉数据上训练,或者与BERT系列对齐,因此与LLMs的表示往往存在不一致性。
-
连接效率低下。这些“粘合对齐”层通常很轻量且随机初始化,无法捕捉到多模态理解与生成中丰富跨模态交互和依赖关系。
提出了InternVL来解决上述问题,提出了3个关键的设计,如下所示:
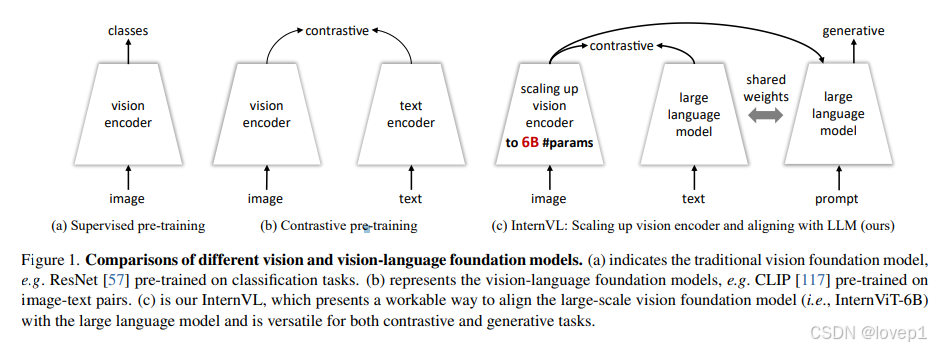
- 参数平衡的视觉和语言的组件:60亿参数的视觉编码器和80亿参数的LLms的中间件(也就是上文说的粘合对齐层),并且使用上图c中的灵活的组合作用于对比学习和生成学习任务
- 一致的表征能力:采用预训练的LLaMA来初始化中间件,然后和视觉编码器进行对齐
- 逐步图像文本对齐:首先在大规模噪声的图像-文本数据上进行对比学习,然后过渡到高质量的细粒度数据进行生成学习,这种方法确保了模型任务范围(这个很重要)和性能的持续提升
使用上述的框架和,InternVL具备以下优势:
- 多功能:在通用的视觉语言任务上表现出色,包括视觉感知任务、视觉语言任务和多模态对话,其实就是分类、分割、检索、chat(MLLMs)、caption生成等这些功能
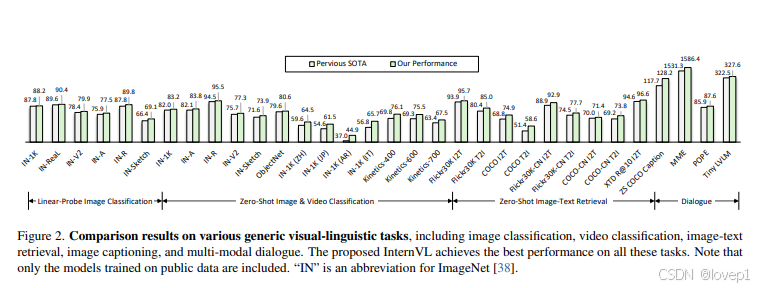
- 性能sota,benchmark如下图所示
- LLM友好,InternVL是一个基础组件,已经和LLM进行过对齐,可以直接和其他的LLM进行组合和集成
三、方法
3.1 模型结构
如下图所示,采用InternVit-6B和语言中间件LLaMA-7B(80亿参数的语言中间件,且使用QKKaMa的参数初始化)进行对比学习,注意此时训练的只有InternVit的参数
3.2 模型设计
大规模视觉编码器:InternViT-6B
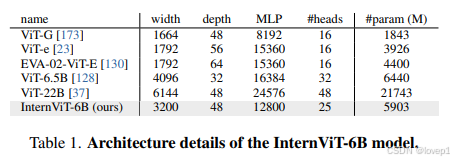
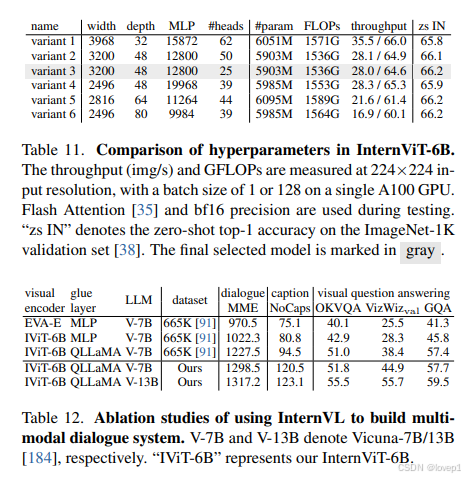
使用标准的ViT实现了InternVL的视觉编码器,为了匹配LLMs的规模,scale vit到60亿参数,为了在精度、速度和稳定性上去的平衡,对InternVL-6B进行了超参搜索,depth在32/48/64/80中间选择,head的dim在64/128中间选择,MLP的ration在4/8之间选择;使用LAION的1亿的子集进行contrasive pretraining,发现如下规律:
- 速度:较浅的模型在图像处理速度上比较快,但是当GPU被充分利用时,速度差异可以忽略
- 精度:在参数量相同的情况下,深度、head的维度和mlp的ration对性能的影响较小
基于上述标准,搜出了最稳定的结果,配置如下所示:
语言中间件:QLLaMA
如本节最开始的对齐示意图,QLLaMA基于多语言LLaMA开发,并新增96个可学习的query和cross attention层(10亿参数),与当前业界流行的轻量级粘合层(对齐)对比,具备三个优势:
- 使用LLaMa的预训练权重进行初始化,QLLaMA可以将InternVit-6B生成的图像token转换成和与LLMs对齐的表征
-
QLLaMA拥有80亿参数用于视觉语言对齐,是QFormer的42倍。因此,即使在冻结LLMs解码器的情况下,InternVL也能在多模态对话任务中实现令人满意的性能。
-
还可以应用于对比学习,为图像-文本对齐任务(如零样本图像分类和图像-文本检索)提供强大的文本表示。
“瑞士军刀”模型:InternVL
通过灵活组合InternVit-6B和QLLaMA,InternVL可以支持各种视觉或视觉语言任务:
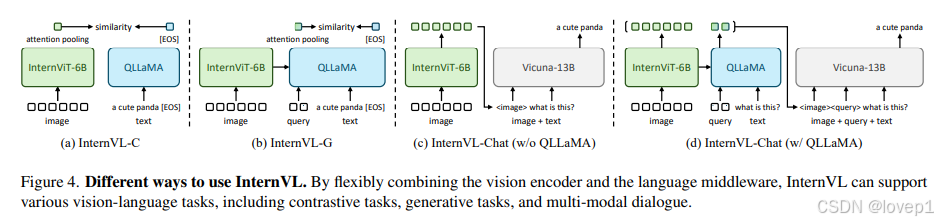
-
视觉感知任务:InternVL的视觉编码器,即InternViT-6B,可以用作视觉任务的主干网络。对于输入图像用于密集预测任务,或者通过全局平均池化和线性投影进行图像分类。
-
对比学习任务:如最开始图的(a)和(b)所示,引入了InternVL-C和InternVL-G两种推理模式,分别使用视觉编码器或InternViT和QLLaMA的组合来编码视觉特征。具体来说,我们对InternViT的视觉特征或QLLaMA的查询特征应用注意力池化,以计算全局视觉特征If。此外,我们通过提取QLLaMA的[EOS]token的特征来编码文本为Tf。通过计算If和Tf之间的相似度分数,我们支持各种对比学习任务,如图像-文本检索(就是第一种是正常的clip对比学习模式,第二种是利用vit的视觉特征,然后和QLLaMA的query进行编码然后再输出特征,再进行cos距离计算)。
-
生成任务:与QFormer不同,QLLaMA由于其扩展的参数规模,本身就具有出色的图像字幕生成能力。QLLaMA的查询重新组织了InternViT-6B的视觉表示,并作为QLLaMA的前缀文本。随后的文本标记将依次生成。
-
多模态对话:我们引入了InternVLChat,利用InternVL作为视觉组件与LLMs连接。为此,我们有两种不同的配置。一种是独立使用InternViT-6B,如上图(c)所示;另一种是同时使用完整的InternVL模型,如上图(d)所示。
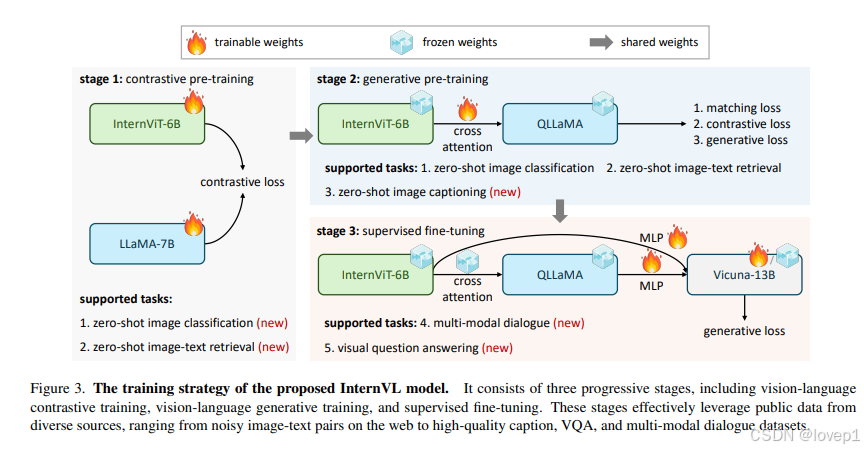
3.3 对齐策略
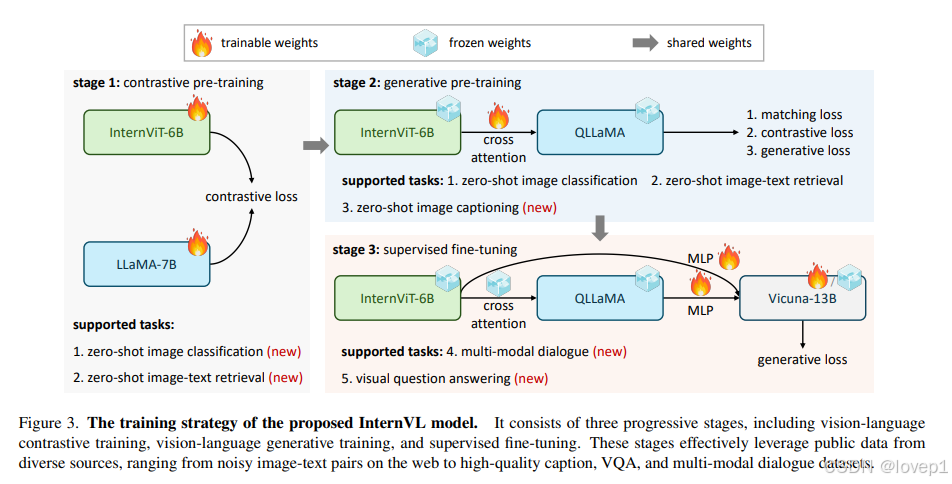
还是这张图是核心,InternVL的训练包括三个逐步进行的阶段:视觉语言对比学习、视觉语言生成学习和监督微调。
注意:第一阶段只做了对比学习,因此具备zero-shot的图像分类和模态检索的能力,第二阶段加了生成学习,具备了zero-shot的caption生成的能力,直到第三阶段,才具备MLLMs的chat能力
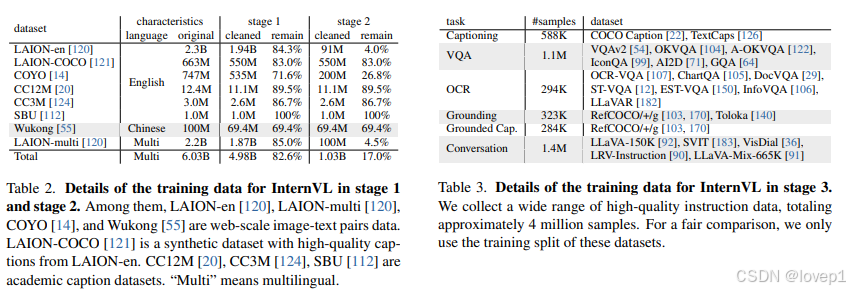
这些阶段有效地利用了来自不同来源的公开数据,从网络上的噪声图像-文本对到高质量的字幕、视觉问答(VQA)和多模态对话数据集。数据集使用如下所示:
通过一个MLP层将InternVL连接到现成的LLMs解码器(例如Vicuna或InternLM),并进行监督微调(SFT)。如上面的表3详细所示,。由于QLLaMA和LLMs的特征空间相似,即使冻结LLMs解码器,。这种方法不仅加快了SFT过程,还保留了LLMs原有的语言能力
视觉语言对比学习
训练的第一阶段,我们进行对比学习,将InternViT-6B与多语言LLaMA-7B在大规模、噪声化的网络图像-文本对上进行对齐。数据包括LAION-en、LAION-multi、LAION-COCO、COYO、悟空等数据集。我们使用这些数据集的组合,并筛选掉一些极其低质量的数据来训练我们的模型。如表2总结,原始数据集包含60.3亿图像-文本对,清理后剩下49.8亿。更多关于数据准备的细节将在补充材料中提供。
使用clip的方式进行对比学习预训练。在训练过程中,我们使用LLaMA-7B对文本进行编码,生成文本特征Tf,并使用InternViT-6B提取视觉特征If。按照CLIP的目标函数,我们在一个批次内图像-文本对的相似度分数上最小化对称交叉熵损失。这一阶段使InternVL在零样本图像分类和图像-文本检索等对比任务上表现出色,同时该阶段的视觉编码器在语义分割等视觉感知任务上也表现良好
视觉语言生成学习
训练的第二阶段,我们将InternViT-6B与QLLaMA连接,并采用生成学习策略。具体来说,QLLaMA继承了第一阶段的LLaMA-7B权重。我们保持InternViT-6B和QLLaMA冻结,仅用筛选后的高质量数据训练新添加的可学习查询和交叉注意力层。表2总结了第二阶段的数据集,可以看出,筛选掉了带有低质量字幕的数据,从第一阶段的49.8亿减少到10.3亿。
按照BLIP-2的损失函数,这一阶段的损失由三个部分组成:图像-文本对比(ITC)损失、图像-文本匹配(ITM)损失和基于图像的文本生成(ITG)损失。这使得查询能够提取强大的视觉表示,并进一步与LLMs对齐特征空间,这归功于有效的训练目标和我们大规模、LLM初始化的QLLaMA的利用。
监督微调(多模态chat系统)
训练的第三阶段,我们收集了400万高质量指令数据,对于非对话数据集,我们按照文献[91]中描述的方法进行转换,我们通过一个MLP层将其连接到现成的LLMs解码器(例如Vicuna或InternLM),并进行监督微调(SFT)。仅训练MLP层或同时训练MLP层和QLLaMA,也能实现强大的性能。这种方法不仅加快了SFT过程,还保留了LLMs原有的语言能力。
四、experiments
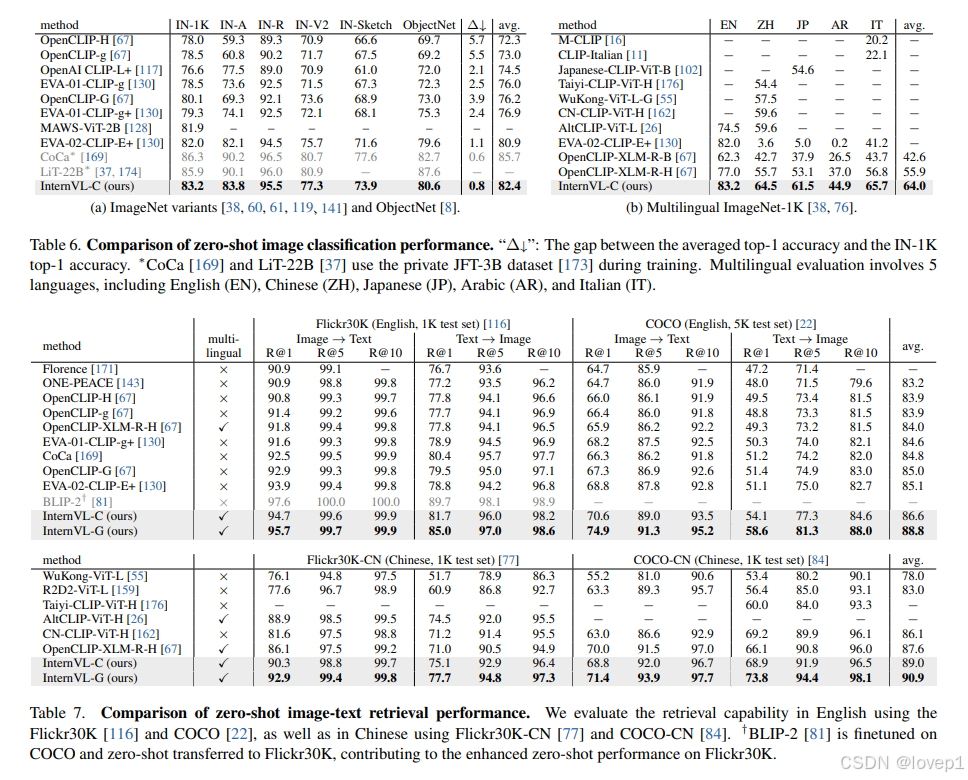
4.1 zero-shot的图像分类和retrival的benchmark
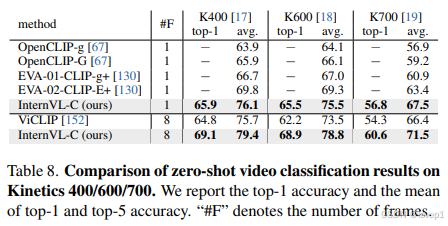
4.2 zero-shot的视频分类/理解benchmark
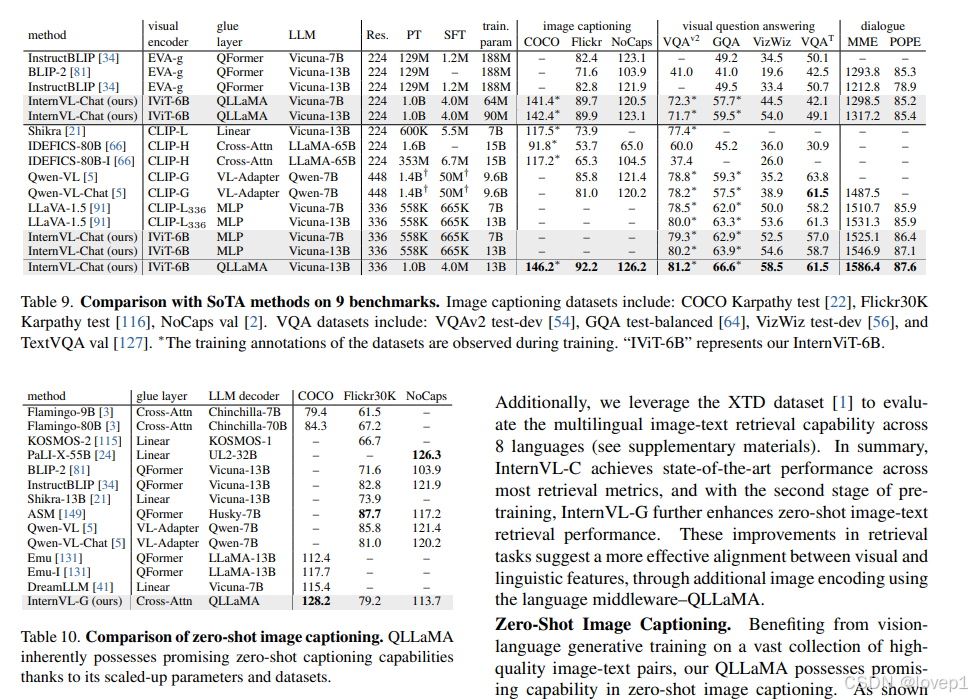
4.3 图像生成和问答等benchmark

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)