
STM32 X-CUBE-AI生成框架源码解析:AI模型部署模板详解
在STM32上部署AI模型时,X-CUBE-AI框架提供了两个核心函数:MX_X_CUBE_AI_Init()和MX_X_CUBE_AI_Process()。本文将详细分析这两个函数的每一行代码,解释所有参数、变量和嵌套函数,帮助初学者彻底理解X-CUBE-AI的工作流程。//负责AI模型的初始化//负责AI模型的推理过程让我们深入分析这两个函数的实现细节。ai_error:结构体类型,包含两个字
·
一、概述
在STM32上部署AI模型时,X-CUBE-AI框架提供了两个核心函数:MX_X_CUBE_AI_Init()和MX_X_CUBE_AI_Process()。本文将详细分析这两个函数的每一行代码,解释所有参数、变量和嵌套函数,帮助初学者彻底理解X-CUBE-AI的工作流程。
X-CUBE-AI框架主要通过两个核心函数实现AI模型的部署:
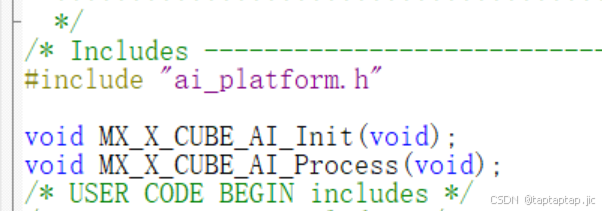
void MX_X_CUBE_AI_Init(void);//负责AI模型的初始化
void MX_X_CUBE_AI_Process(void);//负责AI模型的推理过程让我们深入分析这两个函数的实现细节。
二、初始化函数分析
1. MX_X_CUBE_AI_Init()

void MX_X_CUBE_AI_Init(void)
{
printf("\r\nTEMPLATE - initialization\r\n");
ai_boostrap(data_activations0);
}2. 调用AI引导初始化函数
ai_boostrap(data_activations0);- 调用ai_boostrap函数初始化AI模型
- 参数data_activations0:预分配的激活缓冲区,用于存储神经网络中间计算结果
- 在文件顶部通常定义为:AI_ALIGNED(32) ai_u8 data_activations0[AI_MPU6050_AI_DATA_ACTIVATIONS_SIZE];
AI_ALIGNED(32)
static uint8_t pool0[AI_MPU6050_AI_DATA_ACTIVATION_1_SIZE];
ai_handle data_activations0[] = {pool0};
- AI_ALIGNED(32):确保内存32字节对齐,优化访问速度
- ai_u8:无符号8位整数类型
- AI_MPU6050_AI_DATA_ACTIVATIONS_SIZE:激活缓冲区大小(例如384字节)
3. ai_boostrap函数详解
static int ai_boostrap(ai_handle *act_addr)
{
ai_error err;
/* Create and initialize an instance of the model */
err = ai_mpu6050_ai_create_and_init(&mpu6050_ai, act_addr, NULL);
if (err.type != AI_ERROR_NONE) {
ai_log_err(err, "ai_mpu6050_ai_create_and_init");
return -1;
}
ai_input = ai_mpu6050_ai_inputs_get(mpu6050_ai, NULL);
ai_output = ai_mpu6050_ai_outputs_get(mpu6050_ai, NULL);
#if defined(AI_MPU6050_AI_INPUTS_IN_ACTIVATIONS)
/* In the case where "--allocate-inputs" option is used, memory buffer can be
* used from the activations buffer. This is not mandatory.
*/
for (int idx=0; idx < AI_MPU6050_AI_IN_NUM; idx++) {
data_ins[idx] = ai_input[idx].data;
}
#else
for (int idx=0; idx < AI_MPU6050_AI_IN_NUM; idx++) {
ai_input[idx].data = data_ins[idx];
}
#endif
#if defined(AI_MPU6050_AI_OUTPUTS_IN_ACTIVATIONS)
/* In the case where "--allocate-outputs" option is used, memory buffer can be
* used from the activations buffer. This is no mandatory.
*/
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++) {
data_outs[idx] = ai_output[idx].data;
}
#else
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++) {
ai_output[idx].data = data_outs[idx];
}
#endif
return 0;
}3.1 定义错误变量
ai_error err;- ai_error:结构体类型,包含两个字段
- type:错误类型,如AI_ERROR_NONE(无错误)
- code:具体错误码
3.2 创建并初始化AI模型
err = ai_mpu6050_ai_create_and_init(&mpu6050_ai, act_addr, NULL);- 函数作用:创建神经网络实例并初始化
- 参数1 &mpu6050_ai:
- 指向全局变量mpu6050_ai的指针(类型为ai_handle,本质是void*)
- 函数执行后,该变量将存储已初始化的AI模型实例
- 参数2 act_addr:
- 上一步传入的激活缓冲区指针(data_activations0)
- 用于存储网络运行时的中间结果
- 参数3 NULL:
- 权重缓冲区指针,为NULL表示使用内置权重
- 权重通常编译到固件中(见s_mpu6050_ai_weights_array_u64)
3.3 错误处理
if (err.type != AI_ERROR_NONE) {
ai_log_err(err, "ai_mpu6050_ai_create_and_init");
return -1;
}- 检查创建是否成功
- AI_ERROR_NONE:表示无错误(值为0)
- ai_log_err:错误日志函数,打印详细错误信息
- return -1:返回错误代码
3.4 获取输入输出缓冲区
ai_input = ai_mpu6050_ai_inputs_get(mpu6050_ai, NULL);
ai_output = ai_mpu6050_ai_outputs_get(mpu6050_ai, NULL);- 获取AI模型的输入输出缓冲区
- ai_input和ai_output:全局变量,类型为ai_buffer*
- 参数1 mpu6050_ai:前面初始化的AI模型句柄
- 参数2 NULL:用于返回缓冲区数量,不需要时设为NULL
3.5 ai_mpu6050_ai_inputs_get函数分析
ai_buffer* ai_mpu6050_ai_inputs_get(ai_handle network, ai_u16 *n_buffer)
{
if (network == AI_HANDLE_NULL) {
network = (ai_handle)&AI_NET_OBJ_INSTANCE;
AI_NETWORK_OBJ(network)->magic = AI_MAGIC_CONTEXT_TOKEN;
}
return ai_platform_inputs_get(network, n_buffer);
}- 作用:获取网络输入缓冲区
- 参数1:网络句柄,如果为NULL则使用默认实例
- 参数2:可选的输出参数,存储缓冲区数量
- 返回:指向ai_buffer结构体数组的指针
3.6 ai_buffer结构体详解
typedef struct ai_buffer_ {
ai_buffer_format format; // 数据格式,如AI_BUFFER_FORMAT_FLOAT
ai_handle data; // 指向数据的指针
ai_buffer_meta_info* meta_info; // 元数据信息
ai_flags flags; // 标志位
ai_size size; // 数据大小
ai_buffer_shape shape; // 数据维度
} ai_buffer;3.7 配置输入缓冲区
#if defined(AI_MPU6050_AI_INPUTS_IN_ACTIVATIONS)
for (int idx=0; idx < AI_MPU6050_AI_IN_NUM; idx++) {
data_ins[idx] = ai_input[idx].data;
}
#else
for (int idx=0; idx < AI_MPU6050_AI_IN_NUM; idx++) {
ai_input[idx].data = data_ins[idx];
}
#endif- AI_MPU6050_AI_INPUTS_IN_ACTIVATIONS:定义时,输入数据使用激活缓冲区
- 未定义时:输入数据使用单独分配的缓冲区
- AI_MPU6050_AI_IN_NUM:输入节点数量,通常为1
- data_ins:全局数组,用于存储输入数据
- ai_input[idx].data:输入缓冲区的数据指针
3.8 配置输出缓冲区
#if defined(AI_MPU6050_AI_OUTPUTS_IN_ACTIVATIONS)
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++) {
data_outs[idx] = ai_output[idx].data;
}
#else
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++) {
ai_output[idx].data = data_outs[idx];
}
#endif与输入缓冲区配置类似,但针对输出数据
- AI_MPU6050_AI_OUT_NUM:输出节点数量,通常为1
- data_outs:全局数组,用于存储输出数据
3.9 返回初始化结果
return 0;三、推理执行函数分析:MX_X_CUBE_AI_Process()
void MX_X_CUBE_AI_Process(void)
{
int res = -1;
printf("TEMPLATE - run - main loop\r\n");
if (mpu6050_ai) {
do {
/* 1 - acquire and pre-process input data */
res = acquire_and_process_data(data_ins);
/* 2 - process the data - call inference engine */
if (res == 0)
res = ai_run();
/* 3- post-process the predictions */
if (res == 0)
res = post_process(data_outs);
} while (res==0);
}
if (res) {
ai_error err = {AI_ERROR_INVALID_STATE, AI_ERROR_CODE_NETWORK};
ai_log_err(err, "Process has FAILED");
}
}1. 初始化结果变量
int res = -1;res:函数结果变量,初始值为-1(表示错误)
- 该变量将在执行过程中更新,0表示成功
2. 打印运行提示
printf("TEMPLATE - run - main loop\r\n");3. 检查AI模型是否初始化
if (mpu6050_ai) {
// ...
}4. 主处理循环
do {
/* 1 - acquire and pre-process input data */
res = acquire_and_process_data(data_ins);
/* 2 - process the data - call inference engine */
if (res == 0)
res = ai_run();
/* 3- post-process the predictions */
if (res == 0)
res = post_process(data_outs);
} while (res==0);- 循环执行三个主要步骤,直到某一步骤返回非零值
- 注意:这里设计成循环是为了支持连续处理多帧数据
5. 数据采集和预处理
res = acquire_and_process_data(data_ins);- 调用用户自定义的acquire_and_process_data函数
- 参数data_ins:全局数组,用于存储输入数据
- 返回值res:0表示成功,非0表示错误
5.1 acquire_and_process_data函数模板
int acquire_and_process_data(ai_i8* data[])
{
/* fill the inputs of the c-model
for (int idx=0; idx < AI_MPU6050_AI_IN_NUM; idx++ )
{
data[idx] = ....
}
*/
return 0;
}- 用户需要实现此函数:
- 从传感器(如MPU6050)读取数据
- 进行数据预处理(如归一化)
- 将处理后的数据存入data数组
- 参数data:指向输入数据缓冲区的指针数组
- 返回值:0表示成功,非0表示错误
6. 执行AI推理
if (res == 0)
res = ai_run();仅当前一步成功时执行AI推理
- 调用ai_run()函数,执行实际推理计算
6.1 ai_run函数分析
static int ai_run(void)
{
ai_i32 batch;
batch = ai_mpu6050_ai_run(mpu6050_ai, ai_input, ai_output);
if (batch != 1) {
ai_log_err(ai_mpu6050_ai_get_error(mpu6050_ai),
"ai_mpu6050_ai_run");
return -1;
}
return 0;
}- 作用:执行神经网络推理
- 流程:调用底层API、检查结果、处理错误
6.1.1 变量定义
ai_i32 batch;ai_i32:32位有符号整数类型
- batch:将存储处理的批次数量,通常为1
6.1.2 执行推理计算
batch = ai_mpu6050_ai_run(mpu6050_ai, ai_input, ai_output);- 调用实际执行推理的底层函数
- 参数1 mpu6050_ai:AI模型句柄
- 参数2 ai_input:输入数据缓冲区
- 参数3 ai_output:输出数据缓冲区
- 返回值:处理的批次数量,成功时为1
6.1.3 错误检查
if (batch != 1) {
ai_log_err(ai_mpu6050_ai_get_error(mpu6050_ai),
"ai_mpu6050_ai_run");
return -1;
}检查处理批次是否为1
- 如果不是1,获取详细错误信息并打印
- ai_mpu6050_ai_get_error:获取错误信息的函数
- return -1:返回错误标志
6.1.4 返回成功标志
return 0;7. 后处理结果
int post_process(ai_i8* data[])
{
/* process the predictions
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++ )
{
data[idx] = ....
}
*/
return 0;
}仅当前一步成功时执行后处理
- 调用用户自定义的post_process函数处理推理结果
7.1 post_process函数模板
int post_process(ai_i8* data[])
{
/* process the predictions
for (int idx=0; idx < AI_MPU6050_AI_OUT_NUM; idx++ )
{
data[idx] = ....
}
*/
return 0;
}- 用户需要实现此函数:
- 处理AI模型的输出结果
- 可以进行结果解释、阈值判断等
- 参数data:包含输出数据的指针数组
- 返回值:0表示成功,非0表示停止循环
8. 错误处理
if (res) {
ai_error err = {AI_ERROR_INVALID_STATE, AI_ERROR_CODE_NETWORK};
ai_log_err(err, "Process has FAILED");
}检查是否有错误发生(res非0)
- 创建错误信息结构体:
- AI_ERROR_INVALID_STATE:错误类型,表示无效状态
- AI_ERROR_CODE_NETWORK:错误码,表示网络错误
- 打印错误信息到日志
四、用户自定义函数详解
在使用X-CUBE-AI框架时,用户需要自己实现以下两个关键函数:
1. 数据采集函数
int acquire_and_process_data(ai_i8* data[])
{
// 例如:从MPU6050读取数据
float acc_x, acc_y, acc_z;
float gyro_x, gyro_y, gyro_z;
// 读取传感器数据
MPU6050_ReadAccelerometer(&acc_x, &acc_y, &acc_z);
MPU6050_ReadGyroscope(&gyro_x, &gyro_y, &gyro_z);
// 数据归一化
acc_x = acc_x / 16384.0f;
acc_y = acc_y / 16384.0f;
acc_z = acc_z / 16384.0f;
gyro_x = gyro_x / 131.0f;
gyro_y = gyro_y / 131.0f;
gyro_z = gyro_z / 131.0f;
// 填充数据到AI输入缓冲区
float* input_data = (float*)data[0];
input_data[0] = acc_x;
input_data[1] = acc_y;
input_data[2] = acc_z;
input_data[3] = gyro_x;
input_data[4] = gyro_y;
input_data[5] = gyro_z;
return 0;
}2. 结果处理函数
int post_process(ai_i8* data[])
{
float* output_data = (float*)data[0];
// 获取四种姿态的概率
float prob_standing = output_data[0];
float prob_walking = output_data[1];
float prob_running = output_data[2];
float prob_falling = output_data[3];
// 找出最大概率对应的姿态
float max_prob = prob_standing;
int max_idx = 0;
if (prob_walking > max_prob) {
max_prob = prob_walking;
max_idx = 1;
}
if (prob_running > max_prob) {
max_prob = prob_running;
max_idx = 2;
}
if (prob_falling > max_prob) {
max_prob = prob_falling;
max_idx = 3;
}
// 打印结果
printf("检测到的姿态: ");
switch (max_idx) {
case 0: printf("站立 (%.2f%%)\n", max_prob * 100); break;
case 1: printf("行走 (%.2f%%)\n", max_prob * 100); break;
case 2: printf("跑步 (%.2f%%)\n", max_prob * 100); break;
case 3: printf("跌倒 (%.2f%%)\n", max_prob * 100); break;
}
// 检测到跌倒时触发警报
if (max_idx == 3 && max_prob > 0.8f) {
printf("警报:检测到跌倒事件!\n");
// 可以在这里添加蜂鸣器或其他提醒
}
return 0; // 返回0继续循环,返回非0停止
}五、完整使用示例
int main(void)
{
// 系统初始化
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
MX_USART1_UART_Init();
// 初始化MPU6050
MPU6050_Init();
// 初始化AI模型
MX_X_CUBE_AI_Init();
printf("系统初始化完成,开始姿态检测...\n");
// 主循环
while (1) {
// 执行AI处理
MX_X_CUBE_AI_Process();
// 延时100ms
HAL_Delay(100);
}
}六、总结
STM32 X-CUBE-AI框架通过两个核心函数实现了AI模型从初始化到运行的全过程:
- MX_X_CUBE_AI_Init():
- 创建并初始化AI模型实例
- 配置输入输出缓冲区
- 准备模型运行环境
- MX_X_CUBE_AI_Process():
- 执行数据采集和预处理
- 调用神经网络推理引擎
- 处理AI模型的输出结果
用户只需要关注实现自己的数据采集和结果处理函数,而不必深入了解神经网络的底层实现细节,大大简化了在STM32上部署AI模型的难度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 59
59 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)