
智能车之完全模型——模型训练(炼丹篇)
这个文件如下图所示,只需把数据标签改成自己需要的类就行了。
目录
我是19届完全模型的,我们小队的模型训练是我做的,今天希望三文教会你怎么训练模型!别的模型训练也可以参考吖,我感觉都很适用。(主要是自己总结一下)

本文特别感谢学长学姐,老师们,完模车友们,鼠鼠,的细心指导,谢谢大家!
一.数据集制作
我下期再讲,等待一下哦~
二.AIstudio
2.1简单创建项目
AIstudio地址:飞桨AI Studio星河社区-人工智能学习与实训社区
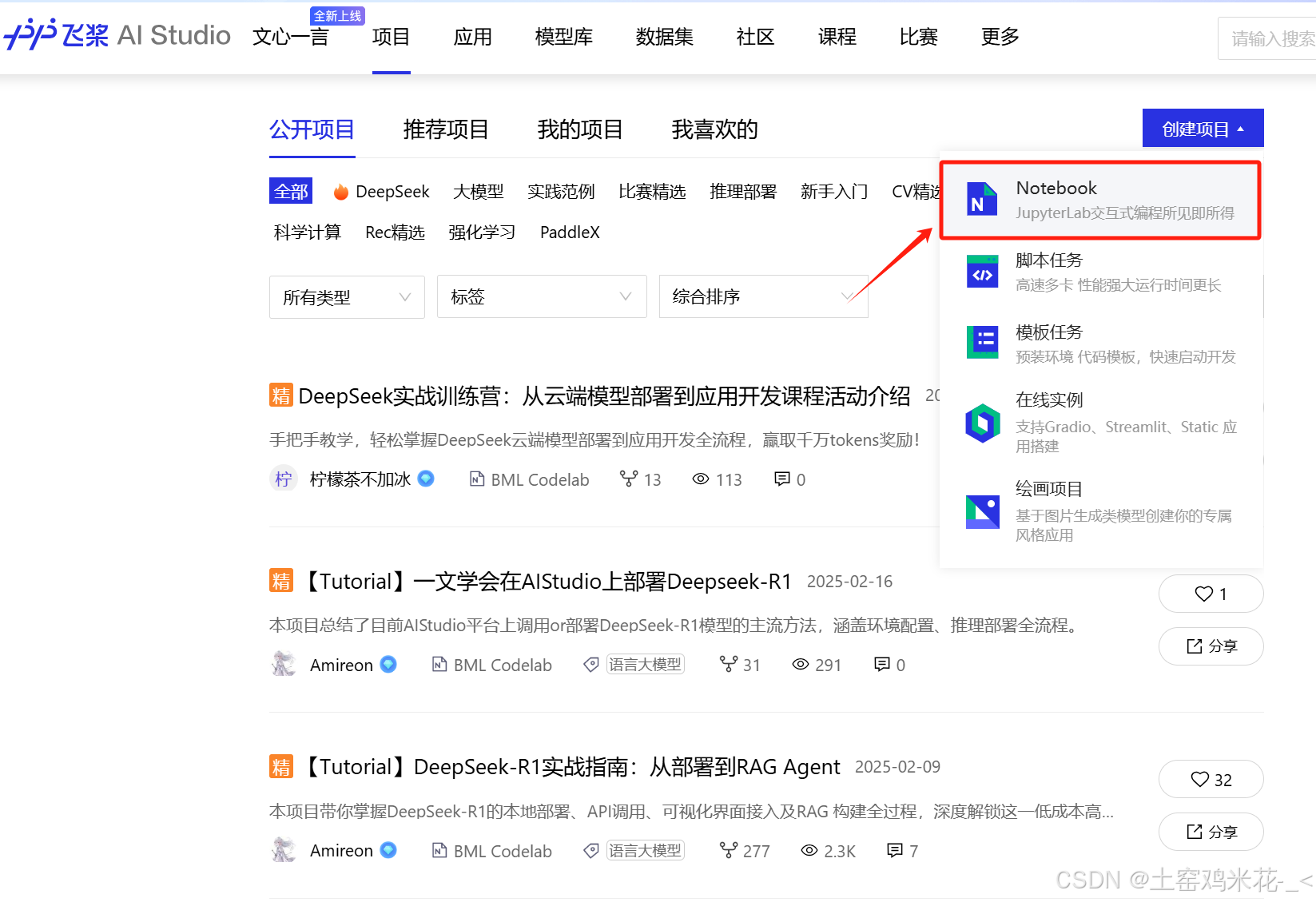
新建项目后会出现以下页面,添加自己需要训练的数据集
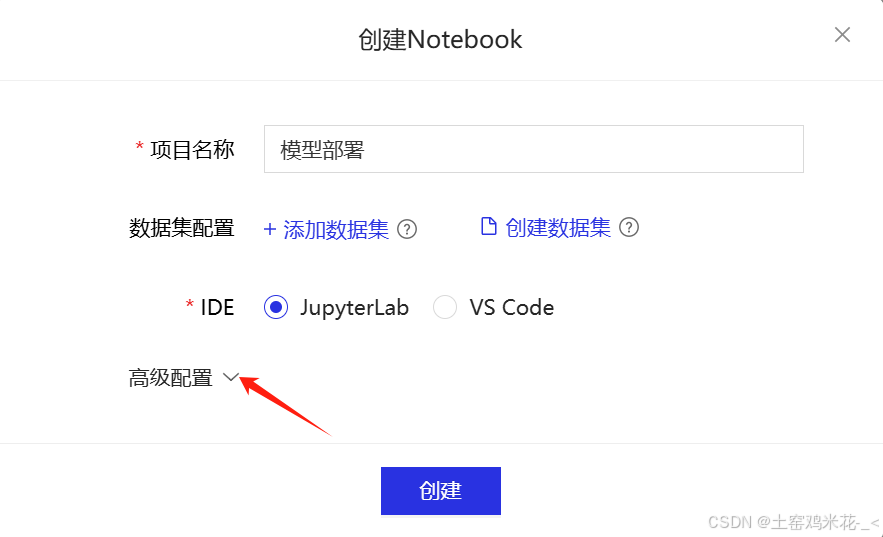
可以根据自己的习惯选择IDE,点击高级配置后,更改项目框架如图所示(一定要改哦~不然货不对板啦)
好了之后直接创建就行。
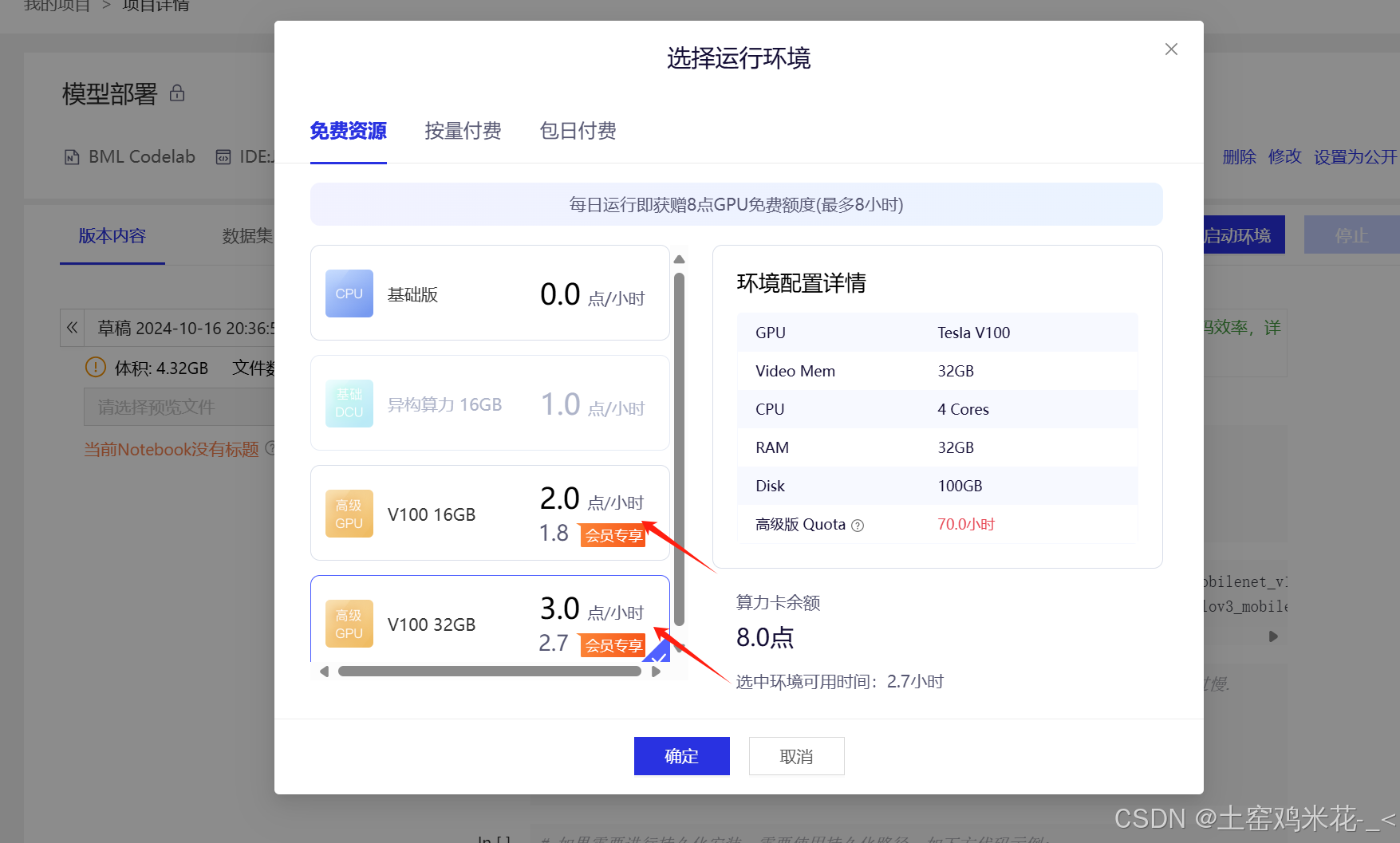
启动环境后,如果不训练可以选择基础版,但要训练必须选择浪费算力的!!!
2.2为训练准备基础工作
进入之后下载套件,下载的版本是PaddleDectection-v2.4.0
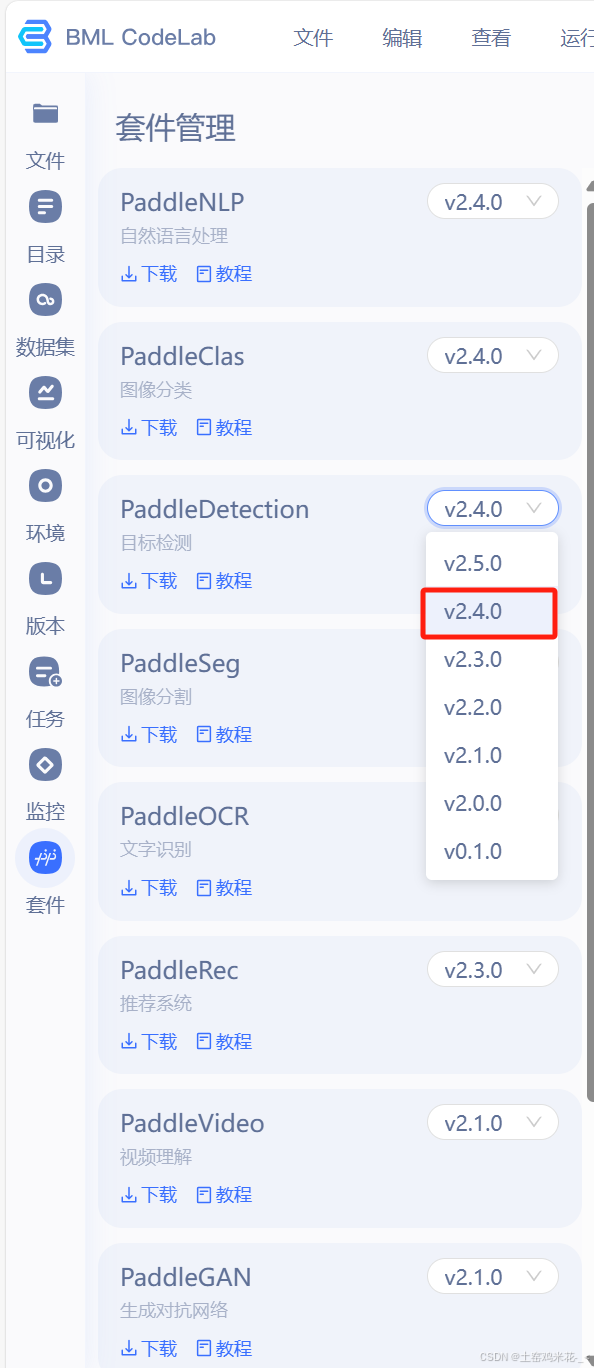
下载完后的PaddleDectection-v2.4.0我一般会重命名简单点,然后移到work
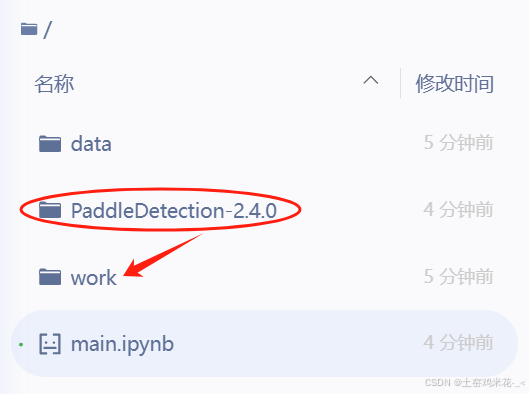
一个充满好奇的车友会注意到,刚刚上传的数据集就位于data文件夹中。

main.ipynb的话,如果你有一些要用的代码可以直接放进去,稍微修改格式就可以用特别方便。
PaddleDectection的文件夹里以下是我比较常用的:
config——里面的好东西很多,当然要训练的模型in it too-_<
config/datasets/voc.yml——修改文件所在地址,标签数量等。。。
tools——会用到的train.py和x2coco.py就在这里面
dataset/voc/label_list.txt——数据标签
不过具体的下面也会详细讲滴~
2.3讲讲上面讲到的常用文件
(不需要的可以直接跳转2.4)
* 这个就是config文件里的模型,都可以用到
**下面以yolov3模型为例吧,因为这是我最熟悉的模型
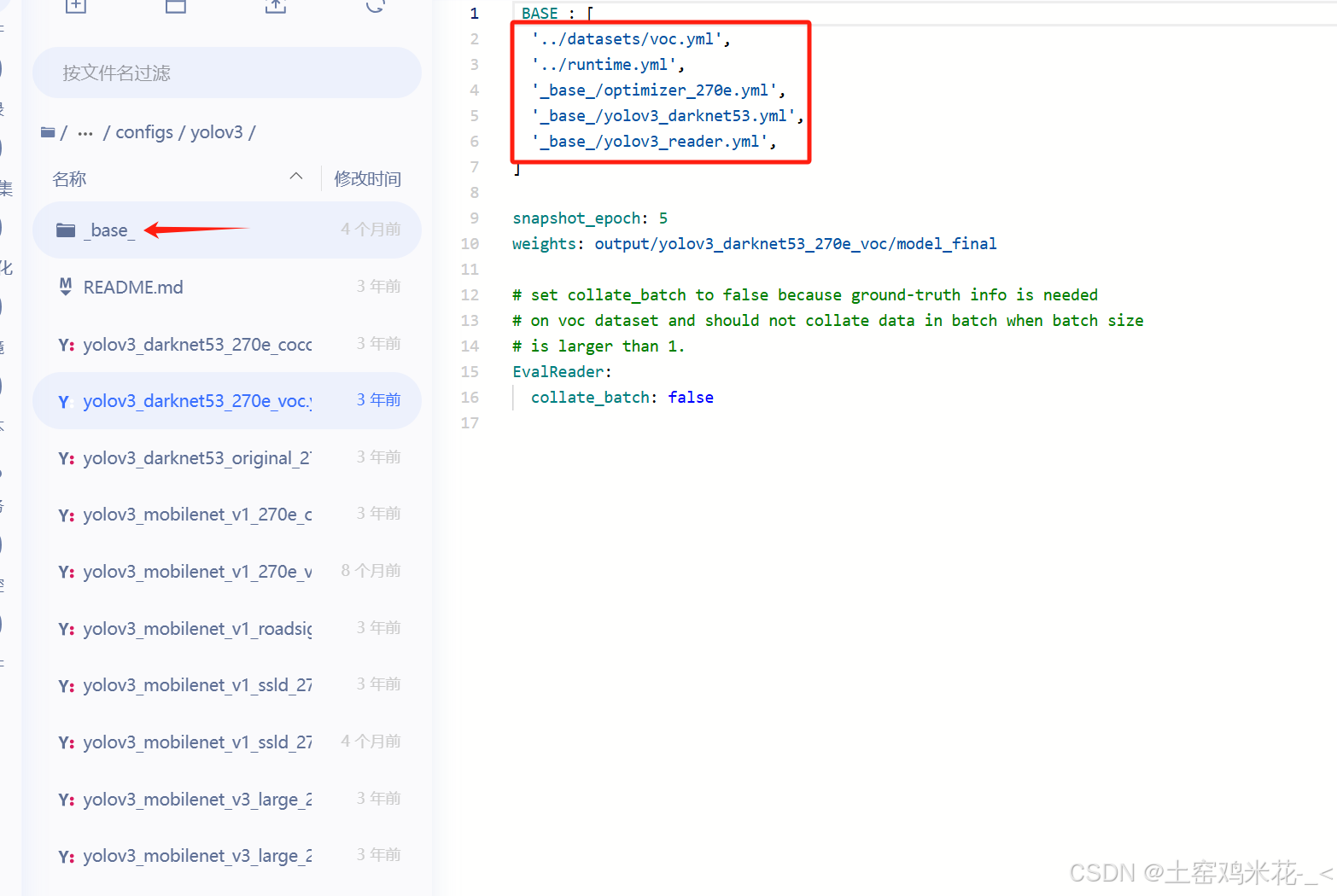
yolov3是一大类,要训练就要挑选其中的模型训练,比如我现在选择的是v3的第二个模型,双击打开模型后就能看到这个模型的基础配置(就是框出来的),这些基础配置就要在箭头指的文件夹中找,并修改你想要的参数。
**圈中后面三个文件就是在base文件夹中,上图所需的optimizer_270e.yml',yolov3_darknet53.yml',yolov3_reader.yml',只需在文件夹中对应打开即可。我经常改动的就是第一个和第三个文件。
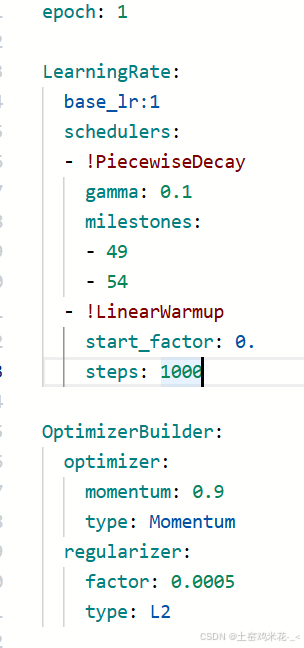
这是optimizer_270e.yml的部分,epoch就是轮数是很重要的,需要根据自己的数据集大小来改变,不同的轮数会炼出不同的丹。milestones包含的两个数是指从第几轮开始进行改变到第几轮结束。不同的优化器,处理方式也不同。优化器也有很多,可以多试几次,选择最适合处理的。
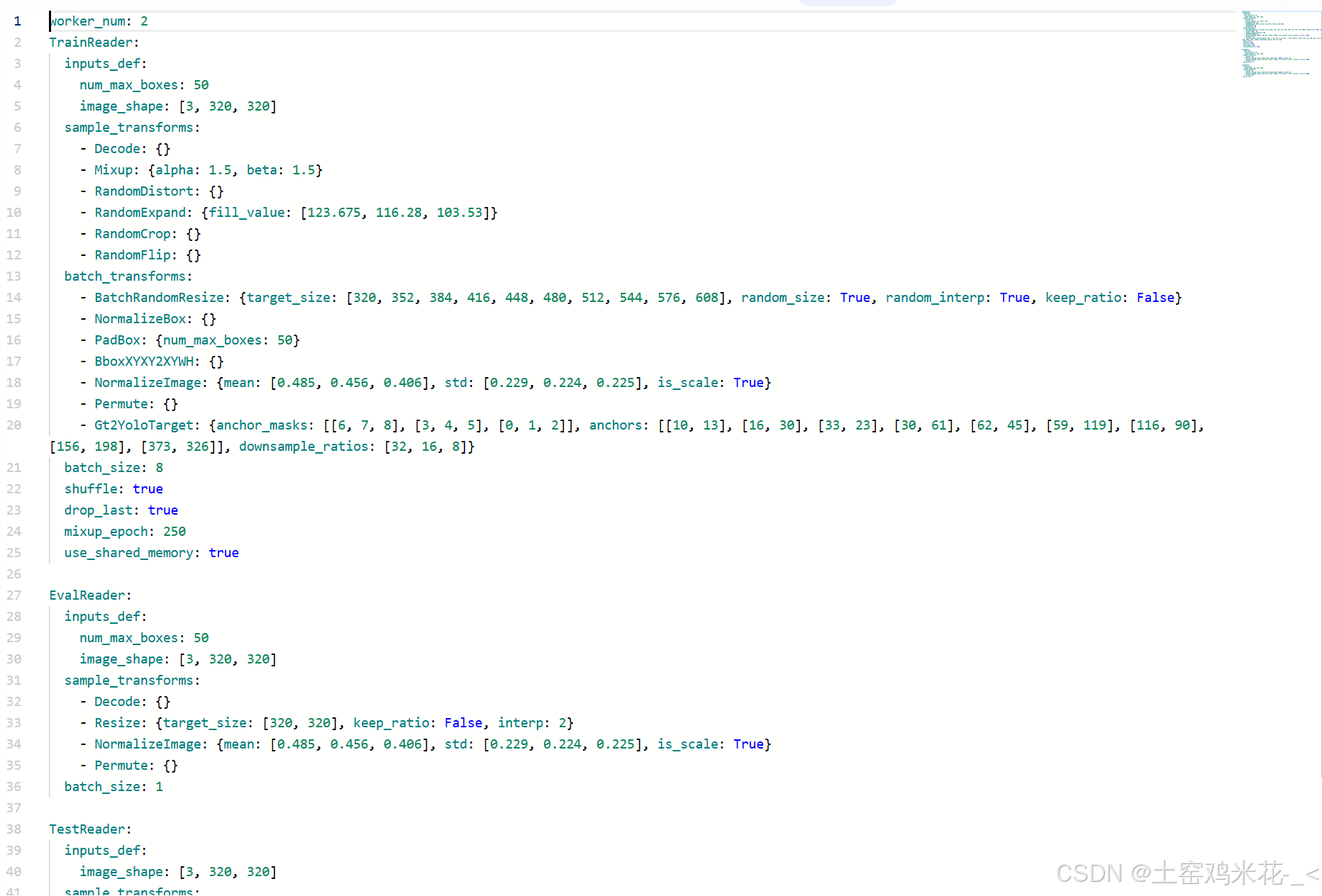
这是yolov3_reader.yml的部分,这个文件我基本只是改图像大小,如果帧率需要提高,就需要改小图像。根据我的经验608*608的图像会比320*320的图像的帧率慢很多。
***圈中第一个文件就是上文所说的config/datasets/voc.yml
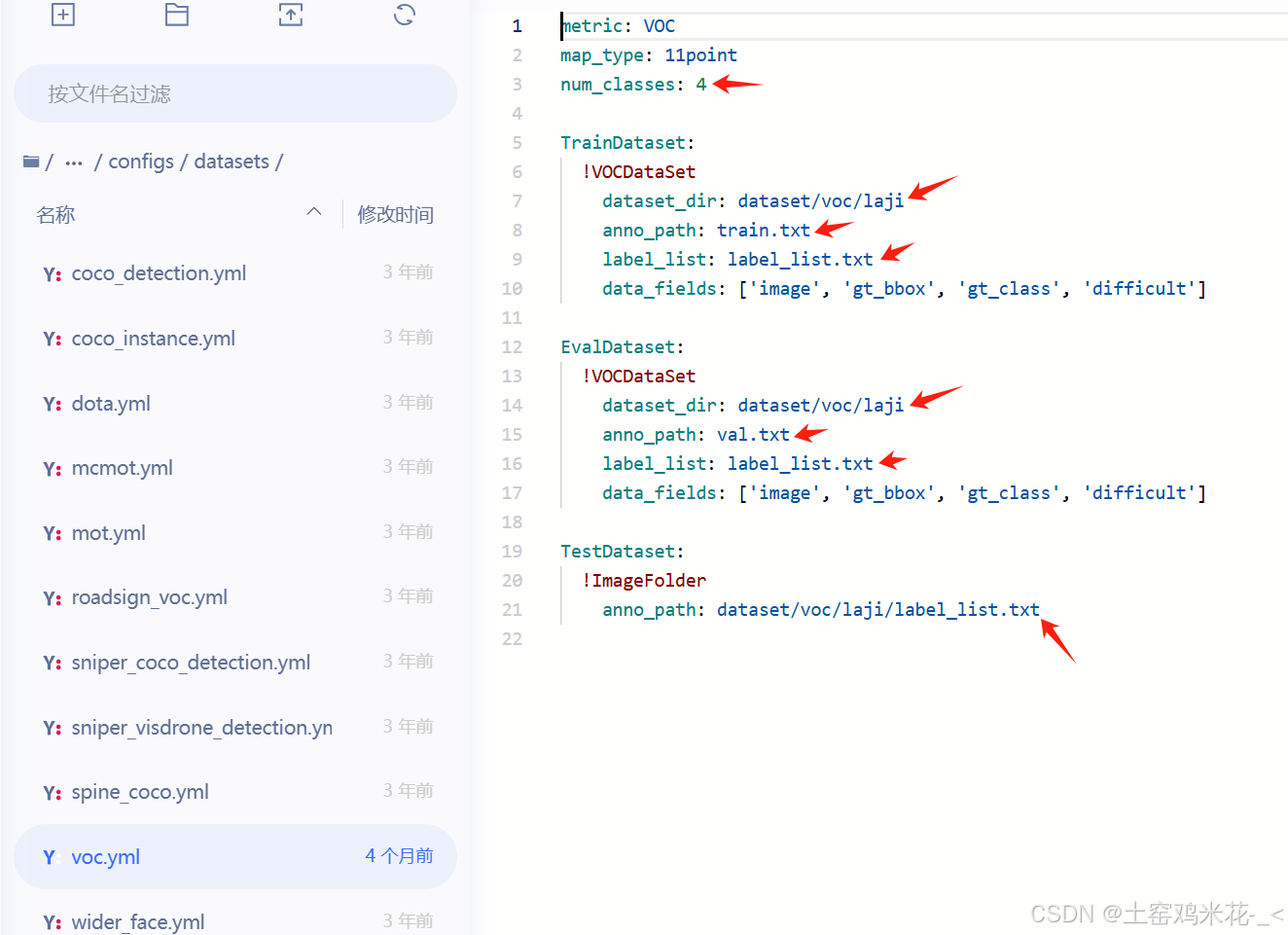
这个文件每个有箭头的地方的参数和地址都要修改,需要根据自己的情况来修改。 其中num_classes——标签数量,
dataset_dir数据集位置
train.txt——训练集
val.txt——测试集
label_list——标签名称
****圈中第二个文件一般不用管<_<(本人太菜不会改)
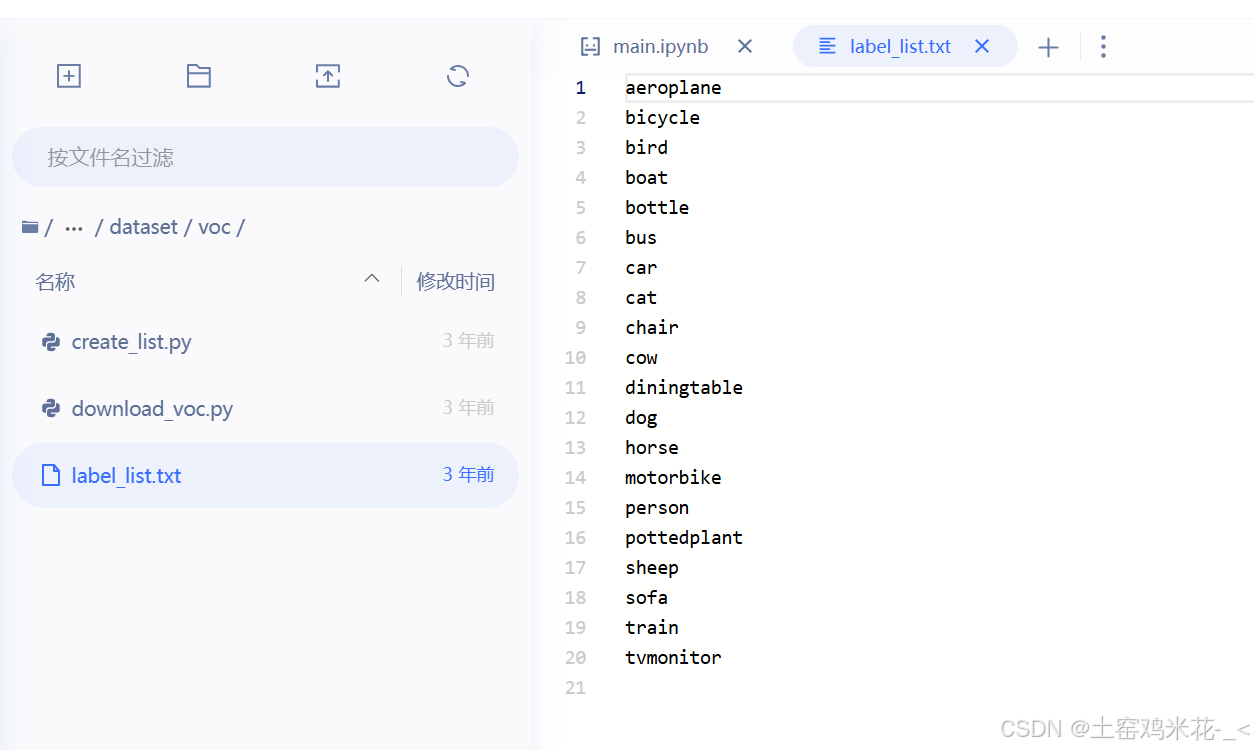
*****最后就是很简单的dataset/voc/label_list.txt
这个文件如下图所示,只需把数据标签改成自己需要的类就行了
2.4训练模型
以下是需要输入的命令:
cd ~/work/PaddleDetection && pip install -r requirements.txt && python setup.py install
unzip -oqd /home/aistudio/work/PaddleDetection/dataset/voc/ /home/aistudio/data/数据集文件夹的名字/数据集.zip
export CUDA_VISIBLE_DEVICES=0//启动训练
(cd ~/work/PaddleDetection && python tools/train.py
-c configs/yolov3/yolov3_mobilenet_v1_ssld_270e_voc.yml --eval ) //选择训练模型,进行训练
训练结束后,文件就会保存在paddle的output文件中,图片我就不截了
2.5模型预测
训练完模型之后,可以先在网上看看模型的好坏再决定要不要下载这个模型。
首先要把你检测模型的照片新建文件夹放到output中,检验模型的照片最好是训练模型的时候没有用到的,这样更能决定你是不是需要这个模型。

然后输入以下命令生成检测模型的照片文件夹,照片上会带有准确率(这个命令就可以直接复制到main的文件中,会很方便)
cd ~/work/PaddleDetection/ && python tools/infer.py \-c configs/yolov3/yolov3_mobilenet_v1_ssld_270e_voc.yml \-o weights=output/yolov3_mobilenet_v1_ssld_270e_voc/best_model.pdparams \--infer_dir=output/sample \--output_dir=output/test

(这张照片是工创垃圾分类检测的照片啦,所以模型训练都差不多)

如果满意就可以用下面的指令导出这个模型(这个指令同样可以放到main)
cd ~/work/PaddleDetection && python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_ssld_270e_voc.yml -o weights=output/yolov3_mobilenet_v1_ssld_270e_voc/best_model.pdparams --output_dir=output_inference
在paddle的output_inference文件中就能找到啦!
三.本地编译
等我下期再讲。
内容参考北京赛曙科技有限公司。感谢管看

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 64
64 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)