毕业设计项目:基于Python+Flask的大数据专业招聘推荐与薪资预测数据可视化系统
本项目旨在构建一个基于Python和Flask的大数据专业招聘推荐与薪资预测数据可视化系统。本系统已实现大数据专业招聘推荐与薪资预测的基本功能,提供了数据可视化展示,并支持用户通过Web界面交互。后续可以进一步优化推荐算法,加入深度学习模型以提高推荐准确性,并完善前端用户体验。地址链接:https://pan.baidu.com/s/1niFL_7h0KhdJSW7r0XdtDw?X = data
1. 项目简介
本项目旨在构建一个基于Python和Flask的大数据专业招聘推荐与薪资预测数据可视化系统。该系统通过数据分析和机器学习算法,帮助求职者精准匹配职位并预测薪资水平。系统包括以下主要功能模块:
- 招聘推荐系统
- 薪资预测模型
- 数据可视化展示
2. 技术栈
- 后端:Python, Flask
- 机器学习:scikit-learn (用于薪资预测模型和推荐算法)
- 数据处理:Pandas, NumPy
- 前端:HTML, CSS, JavaScript, Plotly, D3.js (数据可视化)
- 数据库:SQLite / MySQL (用于存储招聘数据)
- 可视化:Matplotlib, Plotly
3. 系统架构
系统由以下模块组成:
- 数据层:
- 数据库设计:存储招聘信息、用户数据、职位相关属性等。
- 数据预处理:从原始数据中清洗、转换并提取有价值的信息。
- 推荐系统:
- 倒排索引:建立用户与职位的倒排索引,记录每个职位被多少用户查看/喜欢。
- 共现矩阵:计算职位间的相似度,通过协同过滤算法为用户推荐职位。
- 薪资预测模块:
- 特征工程:根据职位的城市、学历、经验等属性,构造数值特征用于模型训练。
- 回归分析:使用线性回归等模型进行薪资预测。
- 前端展示:
- 职位推荐展示:展示用户推荐的职位列表。
- 薪资预测结果展示:将薪资预测结果以图表形式展示,帮助用户了解薪资趋势。
- Web接口:
- API端点:通过Flask构建RESTful API,与前端进行数据交互。
4. 关键功能模块
4.1 数据预处理与加载
- 目标:清洗原始招聘数据,并将数据转化为可供机器学习算法使用的格式。
- 功能:
- 加载招聘数据并对缺失值进行填补。
- 对非数值型数据进行转换(如城市名、学历、经验类型等)。
import pandas as pd
def load_data(file_path):
df = pd.read_csv(file_path)
df = df.fillna(method='ffill') # 填充缺失值
return df
4.2 招聘推荐系统
- 目标:基于用户历史数据,使用协同过滤算法推荐职位。
- 实现:
- 用户-职位倒排索引
- 计算职位间的共现矩阵
- 计算职位间的相似度矩阵
- 基于相似度为用户推荐职位
from math import sqrt
def build_inverted_index(data):
inverted_index = {}
for user, items in data.items():
for item in items:
if item not in inverted_index:
inverted_index[item] = []
inverted_index[item].append(user)
return inverted_index
4.3 薪资预测模型
- 目标:使用机器学习算法预测招聘职位的薪资。
- 实现:
- 使用线性回归模型,根据职位的特征(如城市、学历、工作经验)进行薪资预测。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
def predict_salary(data):
X = data[['city', 'education', 'experience']] # 特征
y = data['salary'] # 标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
salary_pred = model.predict(X_test)
return salary_pred
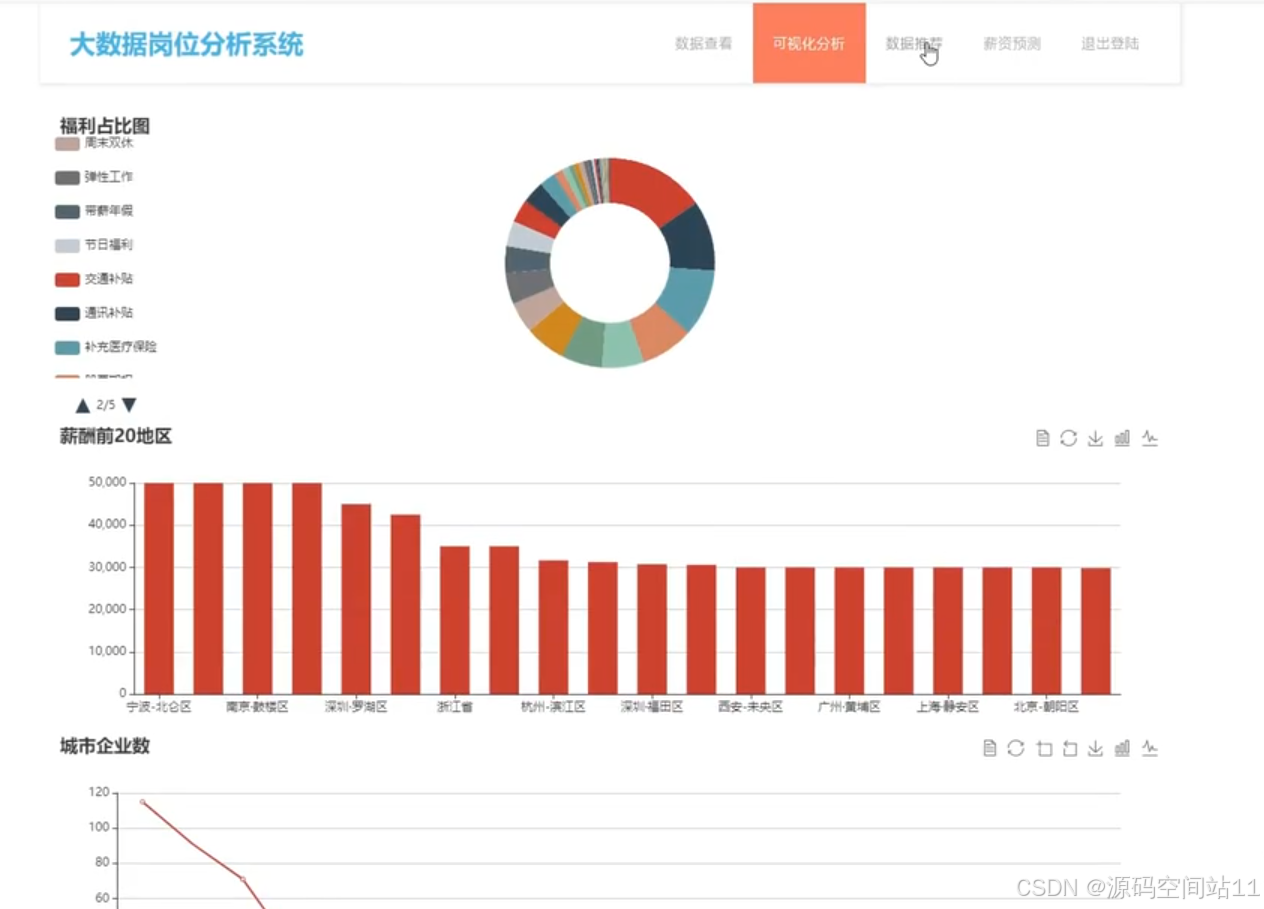
4.4 数据可视化
- 目标:将职位推荐和薪资预测结果可视化展示。
- 实现:
- 使用
Matplotlib和Plotly绘制图表,展示职位推荐的分布和薪资预测趋势。
import matplotlib.pyplot as plt
import plotly.express as px
def visualize_salary(salary_data):
fig = px.scatter(salary_data, x="education", y="salary", color="experience")
fig.show()
5. Flask Web应用
Flask应用用于处理Web请求,并将数据提供给前端展示。主要包含以下API端点:
- GET /recommendations:获取用户推荐的职位列表
- GET /salary_prediction:获取职位的薪资预测
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/recommendations/<user_id>', methods=['GET'])
def get_recommendations(user_id):
recommendations = recommend_jobs(user_id)
return jsonify(recommendations)
@app.route('/salary_prediction/<job_id>', methods=['GET'])
def get_salary_prediction(job_id):
salary = predict_salary(job_id)
return jsonify({"predicted_salary": salary})
if __name__ == '__main__':
app.run(debug=True)
6. 系统部署
- 虚拟环境:
- 使用
venv管理项目依赖,安装所需库:
python -m venv .venv source .venv/bin/activate # 激活虚拟环境 pip install -r requirements.txt
- 启动Flask应用:
python manage.py
- 前端部署:
- 将前端代码(HTML、CSS、JavaScript)放在
templates和static目录下,Flask自动处理路由并渲染页面。
- 数据库配置:
- 使用SQLite或MySQL来存储招聘数据。根据需求,数据库连接可通过SQLAlchemy进行配置。
7. 总结与后续工作
本系统已实现大数据专业招聘推荐与薪资预测的基本功能,提供了数据可视化展示,并支持用户通过Web界面交互。后续可以进一步优化推荐算法,加入深度学习模型以提高推荐准确性,并完善前端用户体验。
项目具体演示效果:
【S2024055基于python+flask+线性回归+协同过滤算法的大数据分析岗位招聘推荐+薪资预测可视化分析202405202153】https://www.bilibili.com/video/BV1yx4y1H7TQ/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
需要配套源码可以私信博主
更多项目见:地址链接:https://pan.baidu.com/s/1niFL_7h0KhdJSW7r0XdtDw?pwd=1234
提取码:1234

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 40
40 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)