
RAG系统中的隐性噪声:文档格式、语言风格对知识性问答效果的影响
此工作第一次探讨了隐性噪声对RAG系统的影响,并发现当前SOTA模型也存在类似缺陷,开启了新的研究方向,这启示我们在做RAG系统时,不仅要规避参考文档中的误导信息,也不能忽视语言风格、格式等非内容特性至于上述鲁棒性缺陷的原因,本文倒是没有做深入探讨目前对此工作的了解仅限于发表的论文,git上还是个空仓库,相关细节未知,huggingface的人正在催更。
论文标题
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
论文地址
https://arxiv.org/pdf/2503.05587
代码地址
https://github.com/maybenotime/RAG-SpuriousFeatures
动机
在构建RAG系统时,检索出无关或者误导性事实往往会对回答的准确性带来损害。但召回文档中的【隐性噪声】又会不会影响系统性能呢?这个问题一直被人们所忽略,本文对此进行了探讨与测试;
注:
【隐性噪声】是那些并不影响文档所描述事实的内容,比如:
| 噪声类别 | 具体类型 |
|---|---|
| 语言风格 | 简练 or 学术 |
| 文档格式 | json or html or yaml or markdown |
| 文档总结 | 使用不同的LLM对召回文档进行总结释义 |
| 句子顺序 | 乱序 or 原始文档逆序 or LLM重排序 |
| 元数据 | 时间戳、引用url等 |
而对回答问题无益的事实被称为“显式噪声”,本文不做探讨
测试指标
- 鲁棒率(Robustness Rate):参考文档加入噪声后,模型回答结果不变的比率
- 胜率(Win Rate):参考文档加入噪声后,模型回答结果变好的比率
- 败率(Lose Rate):参考文档加入噪声后,模型回答结果变差的比率
RR + WR + LR = 100%
小尺寸开源模型
在正式开始实验之前,作者通过统计分析证明了向量检索器对上述隐性噪声存在偏好,也就是说这些跟事实不相关的文本也会影响文档的排序结果。这点比较符合直觉,因为无关的文本也会影响向量值
作者首先在两个尺寸较小的开源模型上做了详细的测试,分别是Mistral-7B-Instruct和Llama3.1-8B-Instruct
测试数据是基于NQ-Open(一个事实性QA数据集,每个问题的答案都可以在维基百科上找到)构造的,例如:

作者抽取了1000个问题,包括以下两种各500条:
- known问题:当前测试模型内部知识就能正确回答的query
- unknown问题:必须借助参考文档才能正确回答的query
然后针对每个问题,从维基百科数据集上各召回了100个参考文档,划分成两类:
- golden文档:包含正确答案的参考文档
- noise文档:不包含正确答案的参考文档
此时测试集被分为四类:(known, golden),(known, noise),(unknown, golden),(unknown, noise)
在每类测试数据中,分别引入上述5种隐性噪声,例如:
| 噪声类别 | 具体类型 | 实现 |
|---|---|---|
| 语言风格 | 简练 | 使用基础词汇和简单句子改写原文 |
| 语言风格 | 学术 | 使用专业词汇和严谨语句改写原文 |
| 文档格式 | json | 将召回结果改写为json格式 |
| 文档总结 | strong LLM | 使用较强的LLM总结参考文档 |
| 文档总结 | RAG LLM | 使用与RAG相同的LLM总结参考文档 |
| 句子顺序 | 乱序 | 随机打乱参考文档句子顺序 |
| 元数据 | pre时间戳 | 加入Known cutoff之前的时间戳 |
| 元数据 | post时间戳 | 加入Known cutoff之后的时间戳 |
| 元数据 | twitter url | 加入虚构的twitter url作为参考链接 |
| 元数据 | wiki url | 加入虚构的wiki url作为参考链接 |
实验结果:
- 不同类型的隐性噪声对系统性能的影响不同
- 隐性噪声不一定有害,有些甚至能提高回答准确性(比如让文档可读性更好)
- 对于模型内部知识能回答的问题,在不相关的参考文档中加入隐性噪声,对系统的影响不大(K-N结果);在相关的参考文档中加入隐性噪声,对系统的影响相对更大(K-G结果)
- 对于模型不知道的问题,在不相关的参考文档中加入隐性噪声,对系统影响也不大(U-N);在相关的参考文档中加入隐性噪声,对系统的影响也更大(U-G结果)
可见RAG模型会受到来自于内部知识、外部参考信息、参考文档隐性噪声三方势力的“拉扯”;当参考文档中包含有用信息时,模型对隐性噪声反而变得更敏感了,这是一个有趣的现象:
你给我一份没用的资料,我基本上懒得看;
你给我一份有用的资料,我会仔细看,但它乱七八糟的格式反而可能会把我搞来不自信了


大尺寸开源模型 / 闭源模型
为了进一步验证上述结果,作者还在当前第一梯队的开源/闭源模型上进行了测试,不过由于上述数据集过于庞大(1000个query*100个文档),测试之前对数据集做了简化:只取最难的测试样例(两个小尺寸模型表现出较低的鲁棒性),并且只取有用的Golden参考文档

如上图所示,只有GPT-4o-mini表现出了相对较好的鲁棒性,而包括GPT-4o在内的其他SOTA模型都暴露了对隐性噪声的敏感性
Scalling law 验证
本文还验证了,大模型对隐性噪声的缺陷是否会随着模型尺寸的扩大而改善,以qwen系列模型为测试对象:
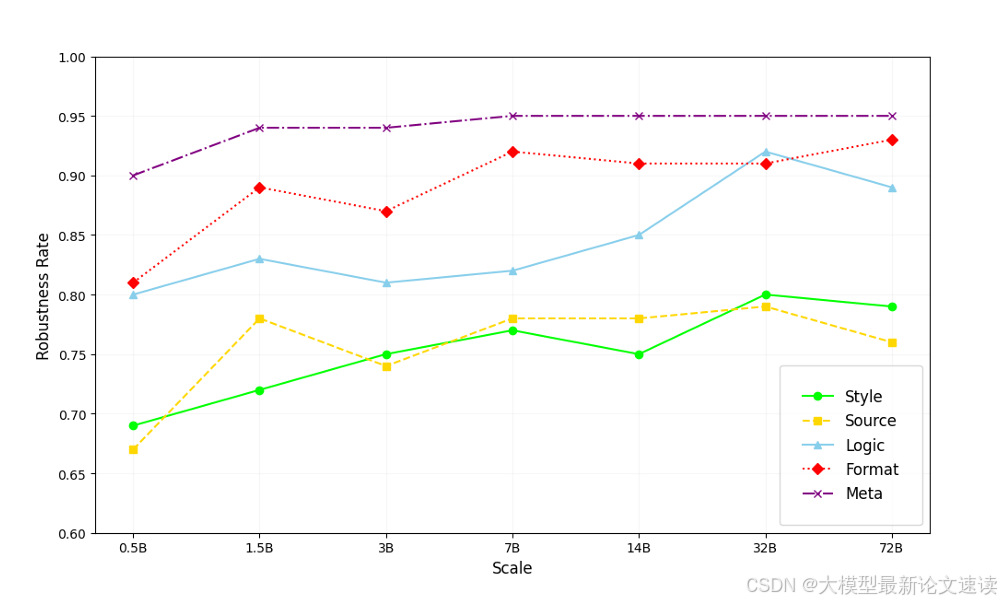
可见本文发现的隐性噪声敏感缺陷,并没用显著地随着模型尺寸的扩大而改善
总结
- 此工作第一次探讨了隐性噪声对RAG系统的影响,并发现当前SOTA模型也存在类似缺陷,开启了新的研究方向,这启示我们在做RAG系统时,不仅要规避参考文档中的误导信息,也不能忽视语言风格、格式等非内容特性
- 至于上述鲁棒性缺陷的原因,本文倒是没有做深入探讨
- 目前对此工作的了解仅限于发表的论文,git上还是个空仓库,相关细节未知,huggingface的人正在催更

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)