
微积分基本概念与机器学习实践
掌握机器学习数学基础的关键在于理解函数与导数的本质关联。本文系统解析映射关系、极限存在性判定、方向导数几何意义等核心要点,结合梯度下降算法与反向传播原理,通过空调能耗模型等生活案例,揭示数学工具在AI训练中的实际应用。
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
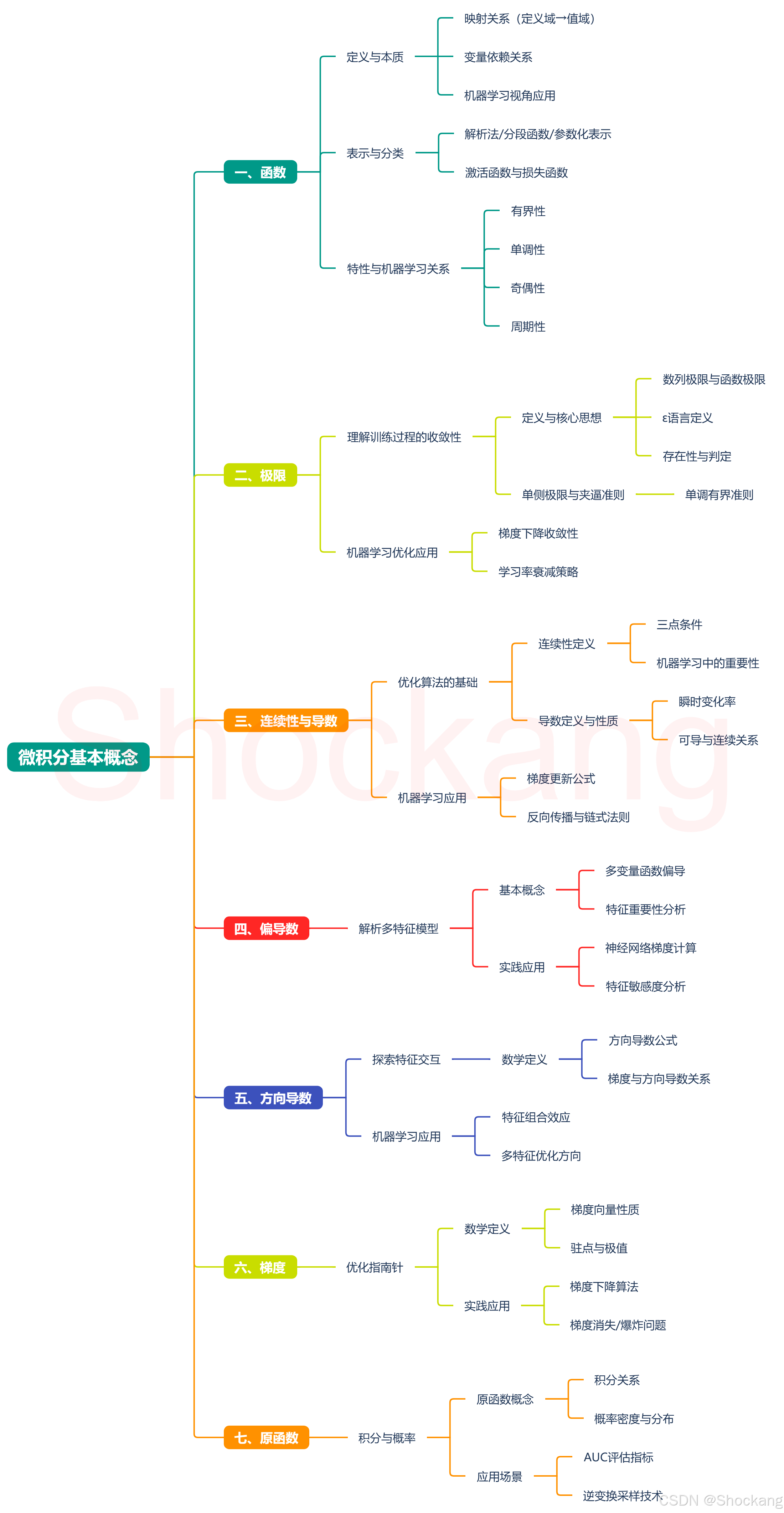
数学是机器学习的基石,微积分则是其中的核心支柱。本文将深入浅出地解析微积分中的关键概念,并将其与机器学习实践紧密结合。
📚 函数:机器学习的基本映射关系
一、函数的定义与本质 🔍
-
映射关系:函数是 实数集到实数集的映射(或更一般地,从一个非空集合到另一个集合的映射)。
- 规范形式: f : D → R f: D \to \mathbb{R} f:D→R,其中 D ⊆ R D \subseteq \mathbb{R} D⊆R 为定义域, f ( D ) ⊆ R f(D) \subseteq \mathbb{R} f(D)⊆R 为值域。
- 核心要素:定义域( D D D)和 对应法则( f f f),两者共同决定函数的唯一性。
-
变量依赖:自变量 x ∈ D x \in D x∈D 通过对应法则 f f f 唯一确定因变量 y = f ( x ) y = f(x) y=f(x),形成依赖关系。
机器学习视角:在监督学习中,函数可视为从特征空间到标签空间的映射,如预测房价的函数 f ( 面积, 位置, 房龄 ) = 房价 f(\text{面积, 位置, 房龄}) = \text{房价} f(面积, 位置, 房龄)=房价。
二、函数的表示与分类 📊
-
表示方法
- 解析法(公式法):如 y = x 2 y = x^2 y=x2
- 分段函数:不同定义域区间用不同表达式
- 参数化表示:如神经网络中的权重参数化表示 f ( x ; θ ) f(x; \theta) f(x;θ)
-
特殊类型
- 激活函数:机器学习中常用的非线性函数,如ReLU f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x),Sigmoid f ( x ) = 1 1 + e − x f(x) = \frac{1}{1+e^{-x}} f(x)=1+e−x1
- 损失函数:衡量模型预测与实际值差距的函数,如均方误差 L ( y , y ^ ) = ( y − y ^ ) 2 L(y, \hat{y}) = (y - \hat{y})^2 L(y,y^)=(y−y^)2
实践应用:选择适当的激活函数可以显著影响神经网络的性能。例如,ReLU解决了传统Sigmoid函数的梯度消失问题,使深度网络训练更加高效。
三、函数的特性与机器学习关系 🔄
-
有界性
- 对神经网络权重初始化和梯度裁剪至关重要,防止梯度爆炸
-
单调性
- 影响函数的优化难度,单调函数通常更易于优化
- 例如:线性回归假设特征与目标变量之间存在单调关系
-
奇偶性
- 可用于特征工程和数据增强
- 在卷积神经网络中,理解奇偶性有助于设计更有效的卷积核
-
周期性
- 对时序数据建模至关重要,如季节性预测模型
案例分析:在时间序列预测中,周期性函数(如傅里叶级数)常用于捕获数据的季节性变化模式,如零售销售、网站流量等周期性行为。
🔭 极限:理解训练过程的收敛性
一、极限的定义与核心思想 💡
-
本质
- 变量趋于某点时的趋势:描述自变量无限接近某一状态时,因变量稳定趋近的确定值。
- 几何意义:点的无限趋近行为(如数列点在数轴上向a聚集)
-
严格数学定义(ε语言)
- 数列极限:∀ε>0,∃正整数N,当n>N时,|uₙ−A|<ε
- 函数极限:
- x→x₀:∀ε>0,∃δ>0,当0<|x−x₀|<δ时,|f(x)−A|<ε
- x→∞:∀ε>0,∃M>0,当|x|>M时,|f(x)−A|<ε
机器学习应用:极限概念帮助我们理解梯度下降算法何时收敛。随着迭代次数增加,损失函数值应趋于某个极小值(理想情况下是全局最小值)。
二、极限的存在性与判定 ✅
-
必要条件
- 单侧极限存在且相等:函数在某点的左右极限必须相等才能保证极限存在
-
存在性准则
- 夹逼准则:若g(x)≤f(x)≤h(x)且limg(x)=limh(x)=A⇒limf(x)=A
- 单调有界准则:单调递增(减)且有上(下)界的数列必收敛
深度学习实践:在训练深度网络时,学习率衰减策略基于极限理论设计,如指数衰减 l r = l r 0 × e − k t lr = lr_0 \times e^{-kt} lr=lr0×e−kt 确保随着训练进行,参数更新幅度逐渐减小,帮助模型收敛到局部最优解。
三、极限在机器学习优化中的应用 🚀
-
基本性质与优化算法
- 唯一性:保证最优解的确定性
- 局部有界性:与梯度裁剪相关,防止训练不稳定
- 保号性:与凸优化中的性质密切相关
-
无穷小与无穷大
- 无穷小:优化过程中梯度逐渐变小,趋近于零
- 无穷大:梯度爆炸问题中的数学解释
学习率调整案例:在实践中,许多优化器如Adam和RMSprop通过自适应调整学习率,实现更快收敛,本质上是控制参数更新步长趋向某个优化极限的过程。
🔄 连续性与导数:优化算法的基础
一、连续性的定义与理解 🌊
-
基本定义
函数 f ( x ) f(x) f(x) 在点 x 0 x_0 x0 处连续,需满足:- 三点条件:
- f ( x ) f(x) f(x) 在 x 0 x_0 x0 有定义
- lim x → x 0 f ( x ) \lim_{x \to x_0} f(x) limx→x0f(x) 存在
- 极限值等于函数值: lim x → x 0 f ( x ) = f ( x 0 ) \lim_{x \to x_0} f(x) = f(x_0) limx→x0f(x)=f(x0)
几何意义:函数图像在 x 0 x_0 x0 处无间断、跳跃或无限发散。
- 三点条件:
机器学习中的连续性:损失函数的连续性对优化算法极为重要。连续可导的损失函数(如均方误差)允许梯度下降等算法有效工作,而非连续函数(如0-1损失)则需要特殊处理。
二、导数的定义与核心性质 📈
-
导数本质
函数 f ( x ) f(x) f(x) 在 x 0 x_0 x0 处的导数描述其 瞬时变化率,定义为:
f ′ ( x 0 ) = lim Δ x → 0 f ( x 0 + Δ x ) − f ( x 0 ) Δ x f'(x_0) = \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x) - f(x_0)}{\Delta x} f′(x0)=limΔx→0Δxf(x0+Δx)−f(x0)几何意义:切线的斜率。
-
可导与连续的关系
- 若可导,则必连续,但连续不一定可导
深度学习应用:反向传播算法本质上是利用链式求导法则计算复合函数的导数。选择合适的激活函数时,其导数性质至关重要—ReLU在正半轴导数恒为1,计算高效但在0处不可导;Sigmoid函数处处可导但存在梯度消失问题。
三、机器学习中的导数应用实例 ⚙️
-
梯度更新公式
在梯度下降中,参数更新遵循:
θ n e w = θ o l d − η ⋅ ∇ θ J ( θ ) \theta_{new} = \theta_{old} - \eta \cdot \nabla_\theta J(\theta) θnew=θold−η⋅∇θJ(θ)其中 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 是损失函数关于参数 θ \theta θ 的导数(梯度)
-
链式法则与反向传播
d L d w = d L d y ⋅ d y d z ⋅ d z d w \frac{dL}{dw} = \frac{dL}{dy} \cdot \frac{dy}{dz} \cdot \frac{dz}{dw} dwdL=dydL⋅dzdy⋅dwdz
神经网络训练中各层梯度的计算依赖链式法则
实践案例:在训练深度CNN时,通过链式法则计算每层权重的梯度,实现参数的高效更新。随着网络层数增加,梯度计算复杂度呈指数增长,因此需要优化技术如梯度检查点来提高效率。
🔍 偏导数:解析多特征模型
在机器学习中,模型通常处理多个输入特征,偏导数提供了分析每个特征独立贡献的数学工具。
基本概念与机器学习映射 🧩
偏导数定义:对多变量函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn),关于变量 x i x_i xi 的偏导数表示为 ∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂xi∂f,代表当其他变量保持不变时,函数值随 x i x_i xi 变化的瞬时变化率。
机器学习解释:
- 在线性回归 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_\theta(x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + ... + \theta_n x_n hθ(x)=θ0+θ1x1+θ2x2+...+θnxn 中, ∂ h θ ( x ) ∂ x i = θ i \frac{\partial h_\theta(x)}{\partial x_i} = \theta_i ∂xi∂hθ(x)=θi 表示特征 x i x_i xi 对预测结果的独立影响程度
- 偏导数帮助分析特征重要性:偏导数绝对值越大,该特征对模型输出的影响越显著
实例分析:在房价预测模型中,如果房屋面积的偏导数值为0.7,而房龄的偏导数为-0.3,说明面积对房价影响更大,且面积增加导致房价上涨,而房龄增加导致房价下降。
代码实践:计算神经网络中的偏导数 💻
import numpy as np
import matplotlib.pyplot as plt
# 定义一个简单的神经网络前向传播函数
def simple_nn(x, w1, w2):
# x: 输入特征 [x1, x2]
# 第一层计算
z = np.dot(w1, x) + 0.5 # 加权和 + 偏置
a = 1 / (1 + np.exp(-z)) # Sigmoid激活
# 第二层计算
y = np.dot(w2, a) # 输出层
return y, a, z
# 计算偏导数
def compute_gradients(x, y_true, w1, w2):
# 前向传播
y_pred, a, z = simple_nn(x, w1, w2)
# 损失函数:均方误差
loss = 0.5 * (y_pred - y_true)**2
# 反向传播 - 计算偏导数
dL_dy = y_pred - y_true # 损失对输出的偏导
dL_dw2 = dL_dy * a # 损失对第二层权重的偏导
dL_da = dL_dy * w2 # 损失对激活值的偏导
dL_dz = dL_da * a * (1 - a) # 损失对z的偏导(sigmoid导数)
dL_dw1 = dL_dz * x # 损失对第一层权重的偏导
return {'dL_dw1': dL_dw1, 'dL_dw2': dL_dw2, 'loss': loss}
# 测试代码
x = np.array([0.5, 0.3]) # 输入特征
y_true = 0.7 # 真实标签
w1 = np.array([0.2, 0.4]) # 第一层权重
w2 = 0.5 # 第二层权重
gradients = compute_gradients(x, y_true, w1, w2)
print(f"损失函数对w1的偏导数: {gradients['dL_dw1']}")
print(f"损失函数对w2的偏导数: {gradients['dL_dw2']}")
实践意义:偏导数计算是神经网络训练的核心。通过分别计算损失函数对每个权重参数的偏导数,我们可以确定如何调整每个权重以减小总体误差。这种思路支撑了所有深度学习框架(如TensorFlow和PyTorch)的自动微分功能。
偏导数与特征重要性分析 📊
在训练完成的模型中,偏导数分析可以揭示不同特征的重要性:
- 特征敏感度: ∂ f ∂ x i \frac{\partial f}{\partial x_i} ∂xi∂f 的绝对值大小表示输出对该特征的敏感程度
- 变化方向:偏导数的符号表明特征增加时输出是增加还是减少
- 比较分析:标准化后的偏导数可用于特征重要性排序
应用场景:在金融风险模型中,通过计算信用评分模型对各输入特征的偏导数,可以确定哪些因素(如收入、年龄、信用历史)对客户信用评级影响最大,从而制定更有针对性的风险控制策略。
🧭 方向导数:探索特征交互与最优方向
方向导数的机器学习解读 🔍
方向导数定义:函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn) 在点 P P P 沿单位向量 v ⃗ \vec{v} v 方向的方向导数为:
D v ⃗ f ( P ) = lim t → 0 f ( P + t v ⃗ ) − f ( P ) t = ∇ f ( P ) ⋅ v ⃗ D_{\vec{v}}f(P) = \lim_{t \to 0} \frac{f(P+t\vec{v}) - f(P)}{t} = \nabla f(P) \cdot \vec{v} Dvf(P)=limt→0tf(P+tv)−f(P)=∇f(P)⋅v
机器学习中的应用:
-
特征组合效应:方向导数分析特征协同变化对模型输出的影响,而非单一特征的独立影响
-
多特征优化:在多维特征空间中寻找损失函数下降最快的方向
-
特征交互分析:评估多个特征同时变化时模型的敏感度
实例:在推荐系统中,通过计算用户满意度函数对"价格降低+质量提升"这一组合方向的方向导数,可以评估这种组合策略对用户满意度的提升效果,优于单独分析价格或质量因素。
方向导数与梯度下降优化 ⚙️
# 计算方向导数示例
def directional_derivative(f, x, direction, h=1e-5):
"""
计算函数f在点x处沿direction方向的方向导数
参数:
f: 函数,接受向量x并返回标量
x: 计算点,numpy数组
direction: 方向向量,将被归一化
h: 数值微分的步长
返回:
方向导数值
"""
# 归一化方向向量
direction = direction / np.linalg.norm(direction)
# 数值计算方向导数
return (f(x + h * direction) - f(x)) / h
# 示例函数: f(x,y) = x^2 + 2*y^2
def f(point):
x, y = point
return x**2 + 2*y**2
# 测试点和方向
point = np.array([1.0, 1.0])
direction1 = np.array([1.0, 0.0]) # x轴方向
direction2 = np.array([0.0, 1.0]) # y轴方向
direction3 = np.array([1.0, 1.0]) # 对角线方向
# 计算不同方向的方向导数
dd1 = directional_derivative(f, point, direction1)
dd2 = directional_derivative(f, point, direction2)
dd3 = directional_derivative(f, point, direction3)
print(f"x轴方向导数: {dd1:.4f}")
print(f"y轴方向导数: {dd2:.4f}")
print(f"对角线方向导数: {dd3:.4f}")
优化应用:方向导数在强化学习中的策略梯度方法中扮演关键角色,帮助智能体确定哪个动作组合可以最大化长期奖励。这比单独考虑每个动作的影响更有效,尤其在复杂环境中。
📈 梯度:机器学习优化的指南针
梯度的数学定义与直观理解 🧠
梯度定义:函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn) 在点 P P P 处的梯度是一个向量:
∇ f ( P ) = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) P \nabla f(P) = \left(\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}\right)_{P} ∇f(P)=(∂x1∂f,∂x2∂f,...,∂xn∂f)P
机器学习解读:
- 梯度指向函数值增长最快的方向,其负方向是函数值下降最快的方向
- 梯度的模长表示在最快方向上的变化率
- 梯度为零的点是函数的驻点(可能是极值点)
核心应用:梯度下降是深度学习中最基础的优化算法,通过计算损失函数关于模型参数的梯度,迭代更新参数以最小化损失。其数学表达式为 θ t + 1 = θ t − α ∇ θ J ( θ t ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t) θt+1=θt−α∇θJ(θt),其中 α \alpha α 是学习率。
梯度在机器学习中的实践应用 🚀
-
神经网络训练:通过反向传播算法计算损失函数对各层权重的梯度,实现参数优化
-
特征重要性:梯度的分量大小直接反映了各个特征对模型输出的影响程度
-
梯度消失/爆炸问题:深层网络中常见的梯度值趋近于零或急剧增大的问题,解决方法包括残差连接、批量归一化等
-
梯度检查:通过数值梯度与解析梯度比较,验证反向传播算法正确性
高级应用:在生成对抗网络(GAN)训练中,梯度提供了生成器改进的方向信息,使其能够逐步生成更真实的样本以欺骗判别器。同样,在风格迁移等计算机视觉任务中,内容与风格的梯度指导了图像合成过程。
梯度下降变种与优化技巧 ⚙️
# 梯度下降算法变体示例代码
def gradient_descent(loss_func, initial_params, learning_rate=0.01, iterations=1000):
"""标准梯度下降"""
params = initial_params.copy()
history = []
for i in range(iterations):
# 计算梯度
grad = compute_gradient(loss_func, params)
# 更新参数
params = params - learning_rate * grad
# 记录损失
loss = loss_func(params)
history.append(loss)
return params, history
def momentum_gd(loss_func, initial_params, learning_rate=0.01, momentum=0.9, iterations=1000):
"""带动量的梯度下降"""
params = initial_params.copy()
velocity = np.zeros_like(params)
history = []
for i in range(iterations):
# 计算梯度
grad = compute_gradient(loss_func, params)
# 更新速度项
velocity = momentum * velocity - learning_rate * grad
# 更新参数
params = params + velocity
# 记录损失
history.append(loss_func(params))
return params, history
实践洞察:在真实项目中,梯度下降算法的变种如Adam、RMSprop等通过自适应学习率和动量机制,能显著提高模型收敛速度和稳定性。例如,在训练复杂的图像识别CNN模型时,Adam优化器能在较少迭代次数内达到更低的损失值。
🔄 原函数:理解积分与概率密度
原函数的机器学习联系 📊
原函数定义:若 F ′ ( x ) = f ( x ) F'(x) = f(x) F′(x)=f(x),则 F ( x ) F(x) F(x) 是 f ( x ) f(x) f(x) 的一个原函数,表示为 F ( x ) = ∫ f ( x ) d x F(x) = \int f(x)dx F(x)=∫f(x)dx。
机器学习中的应用:
-
概率分布:累积分布函数(CDF)是概率密度函数(PDF)的原函数,在机器学习中用于概率建模和数据生成
-
面积计算:通过定积分(原函数差值)计算曲线下方面积,如ROC曲线下面积(AUC)评估分类器性能
-
熵与信息量:信息熵计算涉及概率分布的积分运算
应用案例:在贝叶斯模型中,后验概率分布的归一化常数(证据)需通过对先验分布与似然函数乘积的积分计算。如变分自编码器(VAE)中潜在变量的先验分布通常设为标准正态分布,其CDF可通过原函数表示。
原函数与积分在模型评估中的应用 📈
import numpy as np
from scipy import integrate
import matplotlib.pyplot as plt
# ROC曲线和AUC计算示例
def compute_auc(y_true, y_score):
"""计算ROC曲线下面积(AUC)"""
# 按预测分数排序
sorted_indices = np.argsort(y_score)[::-1]
sorted_y_true = y_true[sorted_indices]
# 计算TPR和FPR
n_pos = np.sum(y_true == 1)
n_neg = len(y_true) - n_pos
tpr = np.cumsum(sorted_y_true) / n_pos
fpr = np.cumsum(1 - sorted_y_true) / n_neg
# 计算曲线下面积(积分)
auc = np.trapz(tpr, fpr)
return auc, tpr, fpr
# 测试数据
y_true = np.array([1, 0, 1, 1, 0, 0, 1, 0])
y_score = np.array([0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52])
auc, tpr, fpr = compute_auc(y_true, y_score)
print(f"AUC值: {auc:.4f}")
# 绘制ROC曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, 'b-', linewidth=2, label=f'AUC = {auc:.4f}')
plt.plot([0, 1], [0, 1], 'r--', linewidth=2)
plt.xlabel('假正例率 (FPR)')
plt.ylabel('真正例率 (TPR)')
plt.title('ROC曲线示例')
plt.legend(loc='lower right')
plt.grid(True)
评估指标应用:AUC值作为分类器评估的常用指标,本质上是计算ROC曲线下的面积,通过对TPR关于FPR的积分获得。在不平衡数据集中,AUC比准确率更能客观反映模型性能,广泛应用于医疗诊断、欺诈检测等领域。
概率积分变换与随机采样 🎲
机器学习中经常需要从特定概率分布生成样本,这涉及到概率积分变换:
-
累积分布函数(CDF):若随机变量X的概率密度函数为f(x),其CDF为:
F ( x ) = ∫ − ∞ x f ( t ) d t F(x) = \int_{-\infty}^{x} f(t) dt F(x)=∫−∞xf(t)dt -
逆变换采样:如果u是服从(0,1)均匀分布的随机数,则 X = F − 1 ( u ) X = F^{-1}(u) X=F−1(u) 服从分布F
# 逆变换采样示例 - 从指数分布采样
def exponential_inverse_cdf(u, lambda_param=1.0):
"""指数分布的逆CDF"""
return -np.log(1 - u) / lambda_param
# 生成服从指数分布的随机样本
np.random.seed(42)
uniform_samples = np.random.uniform(0, 1, 1000)
exponential_samples = exponential_inverse_cdf(uniform_samples, 0.5)
# 绘制采样结果与理论分布对比
plt.figure(figsize=(10, 6))
plt.hist(exponential_samples, bins=30, density=True, alpha=0.7, label='采样分布')
x = np.linspace(0, 15, 1000)
plt.plot(x, 0.5 * np.exp(-0.5 * x), 'r-', linewidth=2, label='理论分布')
plt.xlabel('x')
plt.ylabel('概率密度')
plt.title('逆变换采样:指数分布(λ=0.5)')
plt.legend()
plt.grid(True)
生成模型应用:在变分自编码器(VAE)和生成对抗网络(GAN)等生成模型中,从先验分布采样并通过网络变换生成新样本的过程,本质上是对概率分布的积分变换。例如,VAE的重参数化技巧就是利用正态分布的性质,将从标准正态分布的采样转换为从任意正态分布的采样。
📝 结语:微积分与机器学习的深度融合
通过本文的探索,我们可以清晰地看到微积分与现代机器学习之间的紧密联系。从函数的基本映射关系到梯度优化的核心算法,微积分不仅是理论基石,更是实践中不可或缺的工具箱。
知识脉络与应用价值
我们从函数的概念出发,经历了极限、连续性、导数、偏导数、方向导数、梯度到原函数的完整旅程,这一数学体系构建了机器学习算法的基础框架:
- 函数映射提供了模型与现实世界的连接桥梁
- 极限理论帮助我们理解算法收敛性
- 导数与梯度指导了参数优化的方向
- 积分原理支持了概率建模与评估指标
这些概念不仅是理论构造,更在每一个实际的机器学习项目中发挥着关键作用。无论是简单的线性回归还是复杂的深度神经网络,微积分思想都在背后默默支撑。
未来展望
随着机器学习向更复杂领域拓展,微积分的重要性将进一步凸显:
- 几何深度学习将需要更深入的微分几何知识
- 概率编程依赖于更高级的积分与测度理论
- 连续时间模型(如神经常微分方程)直接构建在微积分基础上
掌握微积分不仅能帮助理解现有算法,更能启发创新思路,推动前沿技术发展。正如数据是机器学习的燃料,微积分则是引擎的核心部件。
作为学习者,我们应当珍视这一古老而永恒的数学分支,它不仅塑造了现代科学的面貌,也将继续引领人工智能技术的未来方向。在数学与计算的交汇处,微积分的光芒从未暗淡。
“机器可以计算,但微积分教会了它如何思考。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)