基于双语义感知递归全局自适应网络的视觉语言导航
本工作的主要贡献:(1)提出了一种双重语义增强结构,分别增强视觉和语言语义表征;(2)使用显式和隐式记忆传输通道来增强模型自适应记忆和推断导航状态的能力。
前言
目前视觉语言导航存在的问题:
(1)当前的文本和视觉语义表示,要么只关注一种情态的语义增强,要么采用几个独立的注意力模块来学习特殊嵌入中的相关性,而不考虑同时对更精细的视觉和语言语义进行显式建模以实现精确感知;
(2)当前模型推断每一步动作的历史依赖能力不足,一些方法使用图形映射,但它们只是提供了过去观测的平均外部特征,缺乏网络内的推理表示流。
本工作的主要贡献:
(1)提出了一种双重语义增强结构,分别增强视觉和语言语义表征;
(2)使用显式和隐式记忆传输通道来增强模型自适应记忆和推断导航状态的能力(即提出全局自适应融合和循环记忆融合)。
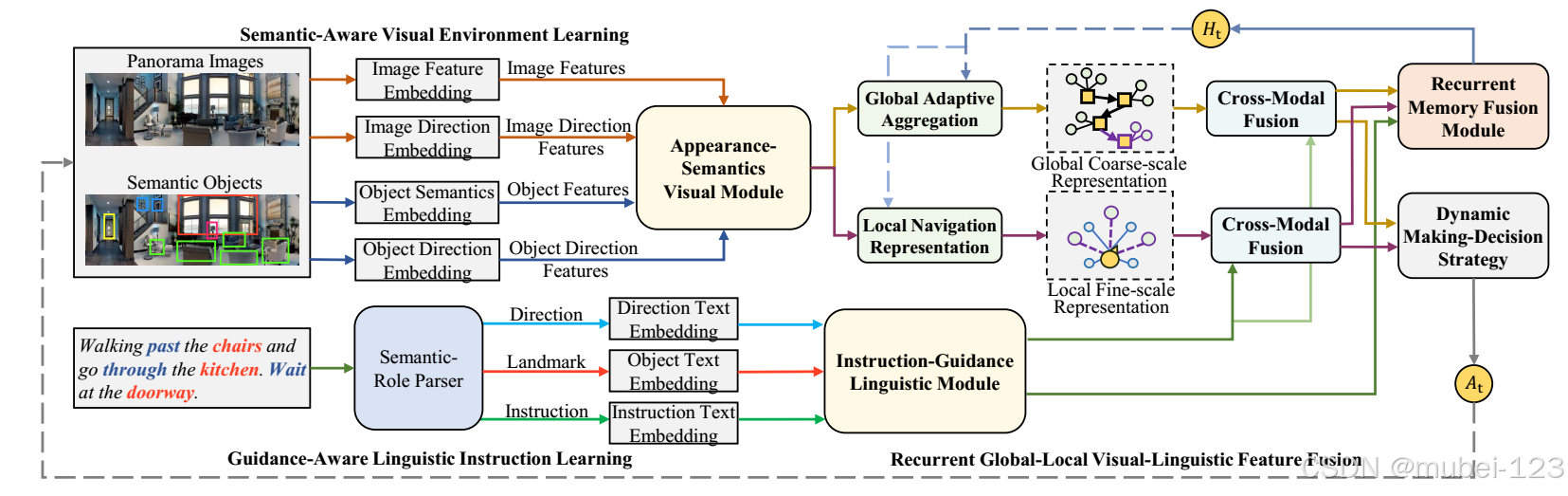
一、模型主要框架
1.1 模型介绍
基于给定的指令,VLN的任务是自动预测朝向目标位置的序列动作。我们的目标是充分利用隐藏在语言和视觉表示中的语义特征来实现更准确的导航。模型的整体框架如下图所示:
可以看出,主要由三大部分组成:
(1)语义感知视觉学习:用于分别获取视觉图像特征和语义目标特征,分别计算注意力特征后,进行concat,再通过线性层,得到总的视觉特征;
(2)指导感知语言指令学习:用于分别获取方向、地标和指令嵌入,然后计算三者的多模态注意力特征,得到总的文本特征;
(3)循环全局局部视觉语言特征融合:局部导航表示用于提供对当前节点的精细观察,全局自适应聚合用于区别不同图像的不同贡献,多模态融合用于计算视觉和文本的多模态注意力,循环记忆融合模块用于传输网络的中间推理状态,动态决策策略用于将注意力特征通过前馈网络映射成动作。
二、难点
2.1 语义感知视觉学习
考虑全景图每个子图像中的细粒度语义对象特征并将其与图像特征融合,环境呈现获得了语义增强。
2.1.1 视觉图像特征
此部分的作用是得到图像级特征。
(1)将每个全景视图分成36个图像,即;
(2)给出角度特征 ,其中
;
(3)给出token类别 ;
(4)给出导航类别 。
计算视觉图像特征,如下公式:
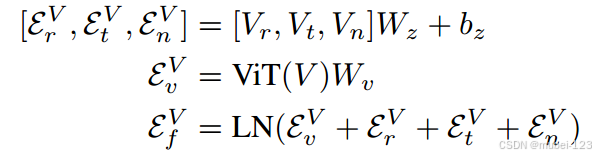
得到的。其中
,
,
。
2.1.2 语义目标特征
此部分的作用是得到目标级特征。
(1)得到36个图像的目标级特征,其中
表示每个图像中目标的最大数量;
(2)给出几何特征;
(3)给出角度特征;
(4)给出标签特征;
(5)给出导航类别。
计算语义目标特征,如下公式:
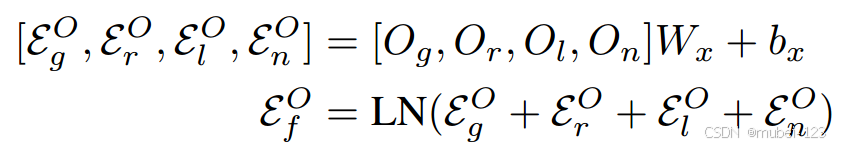
得到的。其中
,
。
2.1.3 外观语义视觉模块
此部分的作用是将得到的图像级特征和目标级特征合并。如下图所示:
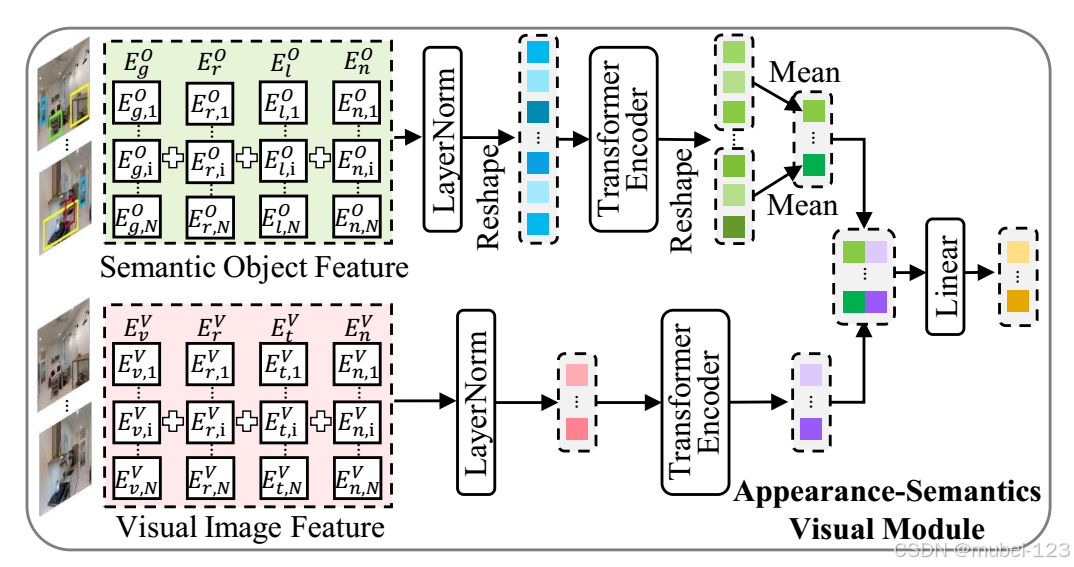
整体思路是将两者分别通过一个Transformer Encoder,再用concat操作将结果连起来,再通过一个线性层,得到最后的图像特征。具体公式如下:
![]()
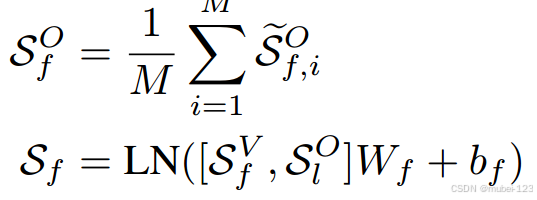
其中,
。
2.2 指导感知语言指令学习
首先从指令中提取指导语义短语,然后鼓励模型关注这些主导部分并增强指令表示。如下图所示:
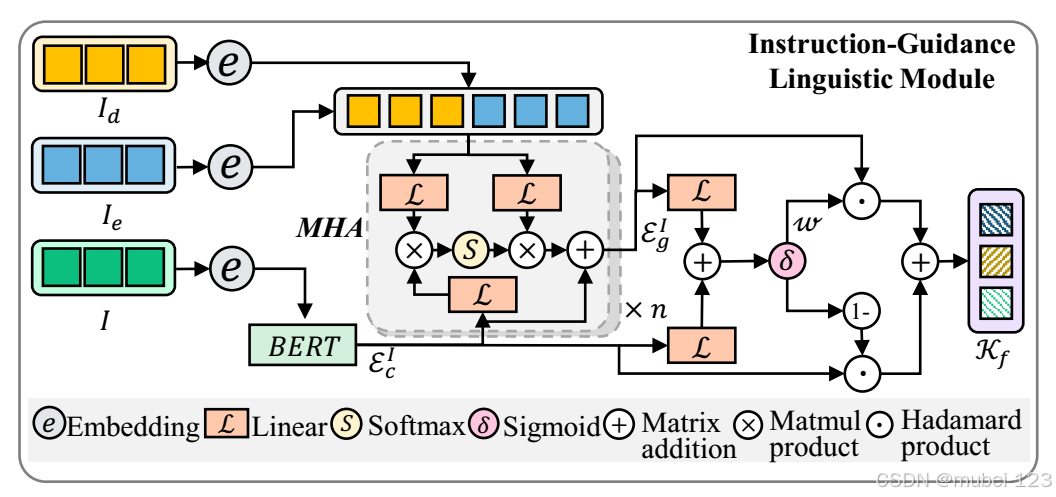
主要流程如下:
(1)基于工具包NLTK提取方向和地标;
(2)将完整指令、方向级短语
和地标级短语
分别嵌入到768维的矢量中;
![]()
(3)给3个矢量分别添加位置嵌入函数来注入排序关系;
(4)将完整指令的嵌入通过BERT编码,将方向级短语和地标级短语的嵌入通过多头注意力编码;
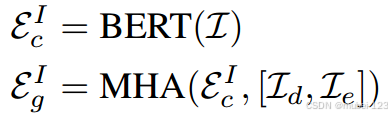
(5)将完整指令的特征和短语级的特征加权求和,作为最后的文本特征。
![]()
其中,
。
2.3 循环全局局部视觉语言特征融合
2.3.1 局部导航表示
这部分主要提供对当前节点的精细观察,局部导航表示的结构如下:
![]()
其中零初始化token 是
的“精华”,能代表
的全部信息,循环记忆token
是循环记忆融合模块的输出。
最后,添加位置编码,使 变为
。
2.3.2 全局自适应融合
这部分主要用于区别不同的图像(不包含特定地标或远离候选点的图像的贡献较小,有必要更加关注更多与指导相关的部分来指导导航)。
主要实现方式是添加一个可以学习图像之间编码关系的线性层 + softmax层。假设总的视觉特征,可以得到计算融合特征
的公式如下:
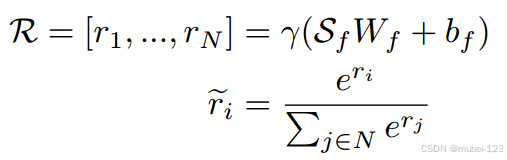
类似于局部导航表示,全局地图表示的结构如下:
![]()
其中零初始化token 是
的“精华”,能代表
的全部信息,循环记忆token
是循环记忆融合模块的输出。
最后,添加位置编码,使 变为
。
2.3.3 多模态特征融合
本部分分别进行文本指令和局部导航表示、文本指令与全局地图表示的多模态融合。采用LXMERT作为多模态编码器:
(1)文本指令特征 仅被分配为键和值;
(2)将文本指令特征 分别与局部视觉特征
和全局视觉特征
进行多模态计算,分别得到
和
。
2.3.4 循环记忆融合模块
此部分主要用于传输网络的中间推理状态。主要流程如下:
(1)从、
和
中分别提取
,标记为
、
和
;
(2)将、
和
进行concat连接,再通过一个线性层:
![]()
得到 后,将
作为
,传给局部导航表示和全局自适应融合。
2.3.5 动态决策策略
此部分主要用于预测代理下一步的动作。主要流程如下:
(1)计算局部和全局分支的一维标量权重:
![]()
(2)将全局特征和局部特征分别投影到得分域:
![]()
(3)将局部动作得分![]() 转换为全局动作空间
转换为全局动作空间![]() ;
;
(4)加权两个分支,获得动作预测![]() 的最终概率:
的最终概率:
![]()
三、总结
(1)大多数VLN方法通过大型预训练网络对视觉和语言特征进行编码,而不考虑对指导代理至关重要的两种输入的语义级线索的显式使用;
(2)低级图像特征会导致环境偏差;
(3)本工作提出的文本(指令+地标+方向)和视觉(图像+目标)显式感知如何迁移到无人机VLN中使用?
(4)能否在无人机VLN中增加全局自适应聚合方法和循环记忆融合模块?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)