
理解ARIMA模型的数学基础
揭秘ARIMA模型背后的数学原理!本文深入浅出地解析差分方程与特征多项式如何支撑时间序列预测,从平稳性条件到参数估计,既有严谨的数学推导,又有实用的Python代码实现。无论你是数据科学初学者还是算法工程师,这份通关指南都能助你精准把握ARIMA模型的核心精髓,提升时间序列分析能力!
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
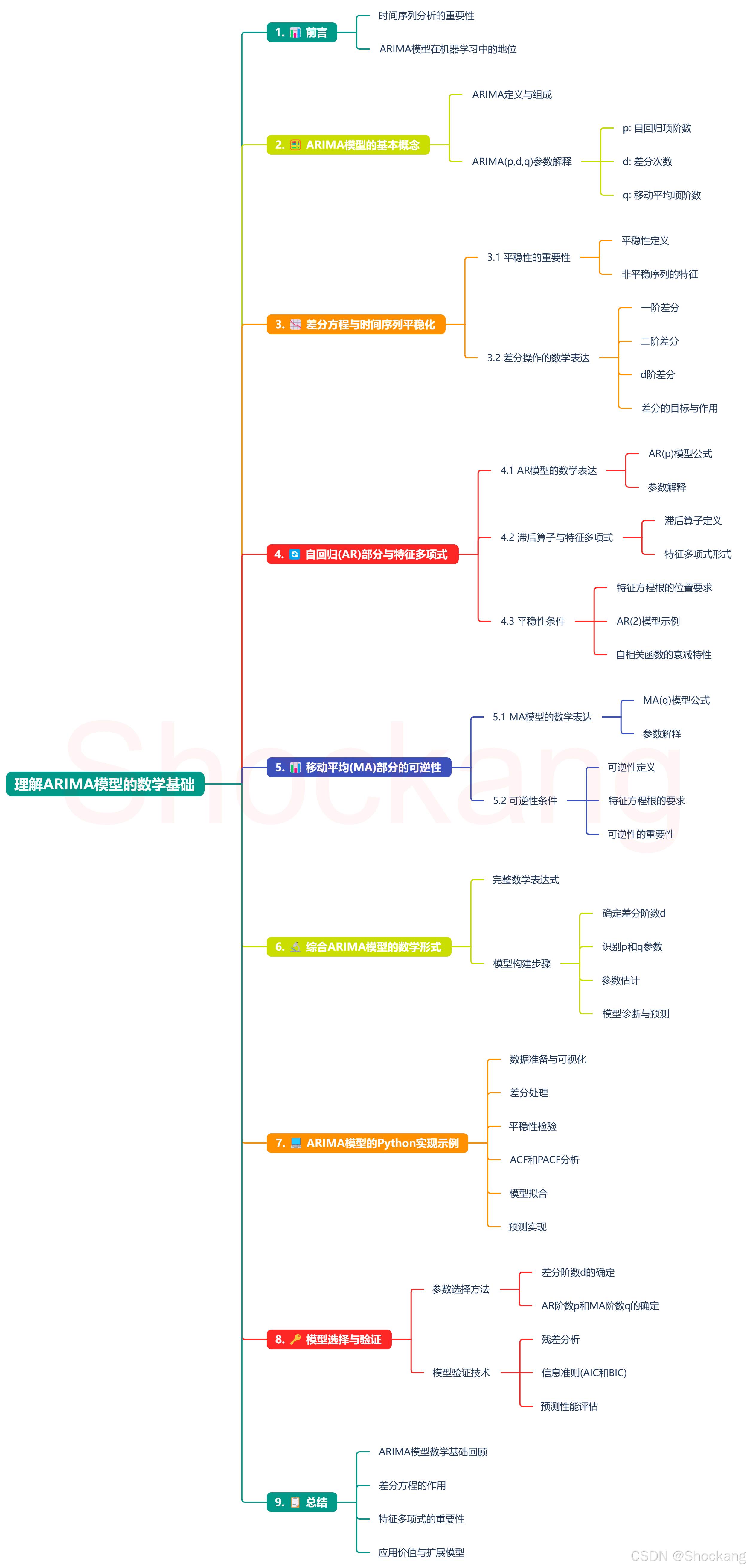
📊 引言
时间序列分析在机器学习和数据科学中占据重要地位,而ARIMA(自回归积分移动平均)模型作为经典方法,其数学基础值得深入理解。本文将揭开ARIMA模型背后的数学原理,聚焦差分方程和特征多项式如何支撑这一强大的预测工具。
🧮 1. ARIMA模型的基本概念
ARIMA是差分自回归移动平均模型(AutoRegressive Integrated Moving Average)的缩写,通常表示为ARIMA(p,d,q):
- p: 自回归项(AR)的阶数,表示模型中包含的延迟观测数
- d: 为实现平稳性所需的差分次数(I)
- q: 移动平均项(MA)的阶数,表示模型中包含的延迟预测误差数
这三个参数共同构建起一个能够捕获时间序列复杂模式的综合模型。
📉 2. 差分方程与时间序列平稳化
2.1 平稳性的重要性
在时间序列建模中,平稳性是一个基本要求,它确保序列的统计特性不随时间变化。非平稳序列通常表现为存在趋势或季节性,这会导致模型预测不准确。
2.2 差分操作的数学表达
差分是ARIMA中"I"(积分)部分的核心,通过计算相邻观测值之间的差值来消除非平稳性:
-
一阶差分:
∇ X t = X t − X t − 1 \nabla X_t = X_t - X_{t-1} ∇Xt=Xt−Xt−1 -
二阶差分:
∇ 2 X t = ∇ ( ∇ X t ) = X t − 2 X t − 1 + X t − 2 \nabla^2 X_t = \nabla(\nabla X_t) = X_t - 2X_{t-1} + X_{t-2} ∇2Xt=∇(∇Xt)=Xt−2Xt−1+Xt−2 -
d阶差分:
∇ d X t \nabla^d X_t ∇dXt
差分操作的核心目标是将非平稳序列转换为满足均值恒定、方差恒定的平稳序列,这是应用ARMA模型的前提条件。
🔄 3. 自回归(AR)部分与特征多项式
3.1 AR模型的数学表达
AR§模型描述当前值与其历史值之间的线性关系:
X t = c + ϕ 1 X t − 1 + ϕ 2 X t − 2 + ⋯ + ϕ p X t − p + ε t X_t = c + \phi_1 X_{t-1} + \phi_2 X_{t-2} + \cdots + \phi_p X_{t-p} + \varepsilon_t Xt=c+ϕ1Xt−1+ϕ2Xt−2+⋯+ϕpXt−p+εt
其中:
- X t X_t Xt 是当前观测值
- c c c 是常数项
- ϕ 1 , ϕ 2 , … , ϕ p \phi_1, \phi_2, \ldots, \phi_p ϕ1,ϕ2,…,ϕp 是自回归系数
- ε t \varepsilon_t εt 是白噪声误差项
3.2 滞后算子与特征多项式
引入滞后算子 L L L(其中 L k X t = X t − k L^k X_t = X_{t-k} LkXt=Xt−k)后,AR方程可重写为:
( 1 − ϕ 1 L − ϕ 2 L 2 − ⋯ − ϕ p L p ) X t = c + ε t (1 - \phi_1 L - \phi_2 L^2 - \cdots - \phi_p L^p) X_t = c + \varepsilon_t (1−ϕ1L−ϕ2L2−⋯−ϕpLp)Xt=c+εt
特征多项式 ϕ ( L ) = 1 − ϕ 1 L − ϕ 2 L 2 − ⋯ − ϕ p L p \phi(L) = 1 - \phi_1 L - \phi_2 L^2 - \cdots - \phi_p L^p ϕ(L)=1−ϕ1L−ϕ2L2−⋯−ϕpLp 在模型中至关重要。
3.3 平稳性条件
AR模型的平稳性依赖于特征方程 ϕ ( z ) = 0 \phi(z) = 0 ϕ(z)=0 的根的位置:
平稳性定理: AR过程平稳的充要条件是特征方程的所有根的绝对值大于1(即位于复平面的单位圆外)。
例如,对于AR(2)模型 X t = 0.4 X t − 1 + 0.4 X t − 2 + ε t X_t = 0.4X_{t-1}+0.4X_{t-2} + \varepsilon_t Xt=0.4Xt−1+0.4Xt−2+εt,其特征方程为 1 − 0.4 z − 0.4 z 2 = 0 1 - 0.4z - 0.4z^2 = 0 1−0.4z−0.4z2=0,我们需要计算其根并验证它们是否都位于单位圆外。
当根接近单位圆时,自相关函数会呈现缓慢衰减的特性,表现为"长记忆"过程。
📊 4. 移动平均(MA)部分的可逆性
4.1 MA模型的数学表达
MA(q)模型通过当前和过去的白噪声误差项的线性组合来表示时间序列:
X t = μ + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 + ⋯ + θ q ε t − q X_t = \mu + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \theta_2 \varepsilon_{t-2} + \cdots + \theta_q \varepsilon_{t-q} Xt=μ+εt+θ1εt−1+θ2εt−2+⋯+θqεt−q
其中:
- μ \mu μ 是期望值
- ε t , ε t − 1 , … , ε t − q \varepsilon_t, \varepsilon_{t-1}, \ldots, \varepsilon_{t-q} εt,εt−1,…,εt−q 是白噪声误差项
- θ 1 , θ 2 , … , θ q \theta_1, \theta_2, \ldots, \theta_q θ1,θ2,…,θq 是移动平均系数
4.2 可逆性条件
MA模型的可逆性是指能否将其表示为无穷阶AR模型的能力,这与特征多项式密切相关:
θ ( L ) = 1 + θ 1 L + θ 2 L 2 + ⋯ + θ q L q \theta(L) = 1 + \theta_1 L + \theta_2 L^2 + \cdots + \theta_q L^q θ(L)=1+θ1L+θ2L2+⋯+θqLq
可逆性定理: MA过程可逆的充要条件是特征方程 θ ( z ) = 0 \theta(z) = 0 θ(z)=0 的所有根的绝对值大于1(位于单位圆外)。
可逆性对于参数估计和模型解释至关重要,因为它确保了从观测数据中唯一地确定MA参数的能力。
🔬 5. 综合ARIMA模型的数学形式
将差分、AR和MA组件结合起来,ARIMA(p,d,q)模型的完整数学表达式为:
ϕ ( L ) ( 1 − L ) d X t = θ ( L ) ε t \phi(L)(1-L)^d X_t = \theta(L)\varepsilon_t ϕ(L)(1−L)dXt=θ(L)εt
展开后:
∇ d X t = c + ∑ i = 1 p ϕ i ∇ d X t − i + ε t + ∑ j = 1 q θ j ε t − j \nabla^d X_t = c + \sum_{i=1}^p \phi_i \nabla^d X_{t-i} + \varepsilon_t + \sum_{j=1}^q \theta_j \varepsilon_{t-j} ∇dXt=c+∑i=1pϕi∇dXt−i+εt+∑j=1qθjεt−j
其中 ∇ d X t \nabla^d X_t ∇dXt 表示 X t X_t Xt 的d阶差分。
在ARIMA模型构建过程中,我们需要:
- 确定差分阶数d,使序列平稳
- 识别p和q参数(通常通过ACF和PACF图)
- 估计模型参数
- 进行模型诊断和预测
💻 6. ARIMA模型的Python实现示例
下面是使用Python实现ARIMA模型的简要代码示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# 加载示例数据
data = pd.Series([...]) # 你的时间序列数据
# 可视化原始数据
plt.figure(figsize=(10, 6))
plt.plot(data)
plt.title('原始时间序列数据')
plt.show()
# 差分处理
diff_data = data.diff().dropna() # 一阶差分
# 检查平稳性(通常使用ADF检验)
from statsmodels.tsa.stattools import adfuller
result = adfuller(diff_data)
print(f'ADF统计量: {result[0]}')
print(f'p值: {result}')
# 绘制ACF和PACF图确定p、q参数
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 8))
plot_acf(diff_data, ax=ax1)
plot_pacf(diff_data, ax=ax2)
plt.show()
# 拟合ARIMA模型
model = ARIMA(data, order=(p, d, q)) # 替换为合适的p, d, q值
model_fit = model.fit()
print(model_fit.summary())
# 预测
forecast = model_fit.forecast(steps=10) # 预测未来10个时间点
通过这段代码,我们可以实践前面讨论的ARIMA模型的数学原理,从差分到参数确定,再到模型拟合和预测。
🔑 7. 模型选择与验证
ARIMA模型的成功应用取决于参数(p,d,q)的正确选择:
-
差分阶数d:通过观察时间序列图和单位根检验(如ADF检验)确定
-
AR阶数p和MA阶数q:通过分析自相关函数(ACF)和偏自相关函数(PACF)的图形确定
- ACF拖尾而PACF在lag p后截断,暗示AR§模型
- PACF拖尾而ACF在lag q后截断,暗示MA(q)模型
-
模型验证:通过残差分析、信息准则(AIC和BIC)以及预测性能评估来选择最佳模型
AIC = − 2 log ( L ) + 2 ( p + q + k ) \text{AIC} = -2\log(L) + 2(p+q+k) AIC=−2log(L)+2(p+q+k)
其中L是似然函数,k是包含常数项时为1,否则为0
📋 8. 总结
ARIMA模型的数学基础揭示了它如何通过组合差分方程和特征多项式来捕获时间序列的动态特性:
- 差分方程:通过d阶差分消除非平稳性,为后续建模奠定基础
- 特征多项式:决定AR部分的平稳性和MA部分的可逆性,是模型有效性的数学保证
- 参数估计:通过极大似然法或条件最小二乘法求解最优参数
掌握ARIMA模型的数学基础,不仅有助于正确应用模型,还能更好地理解更复杂的时间序列模型(如SARIMA、ARIMAX等)的原理。
通过深入理解特征多项式与差分方程的关系,我们能够更准确地构建模型、解释结果并做出可靠的预测,这是机器学习中时间序列分析的核心能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)