
贝叶斯定理全解析
【贝叶斯定理深度解析】通过医学诊断、文本分类等实战案例,结合Python代码演示与频率学派对比,系统阐述贝叶斯思维在机器学习中的应用,并探讨贝叶斯深度学习等前沿趋势,为技术人员提供从理论到实践的全方位指南 。
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
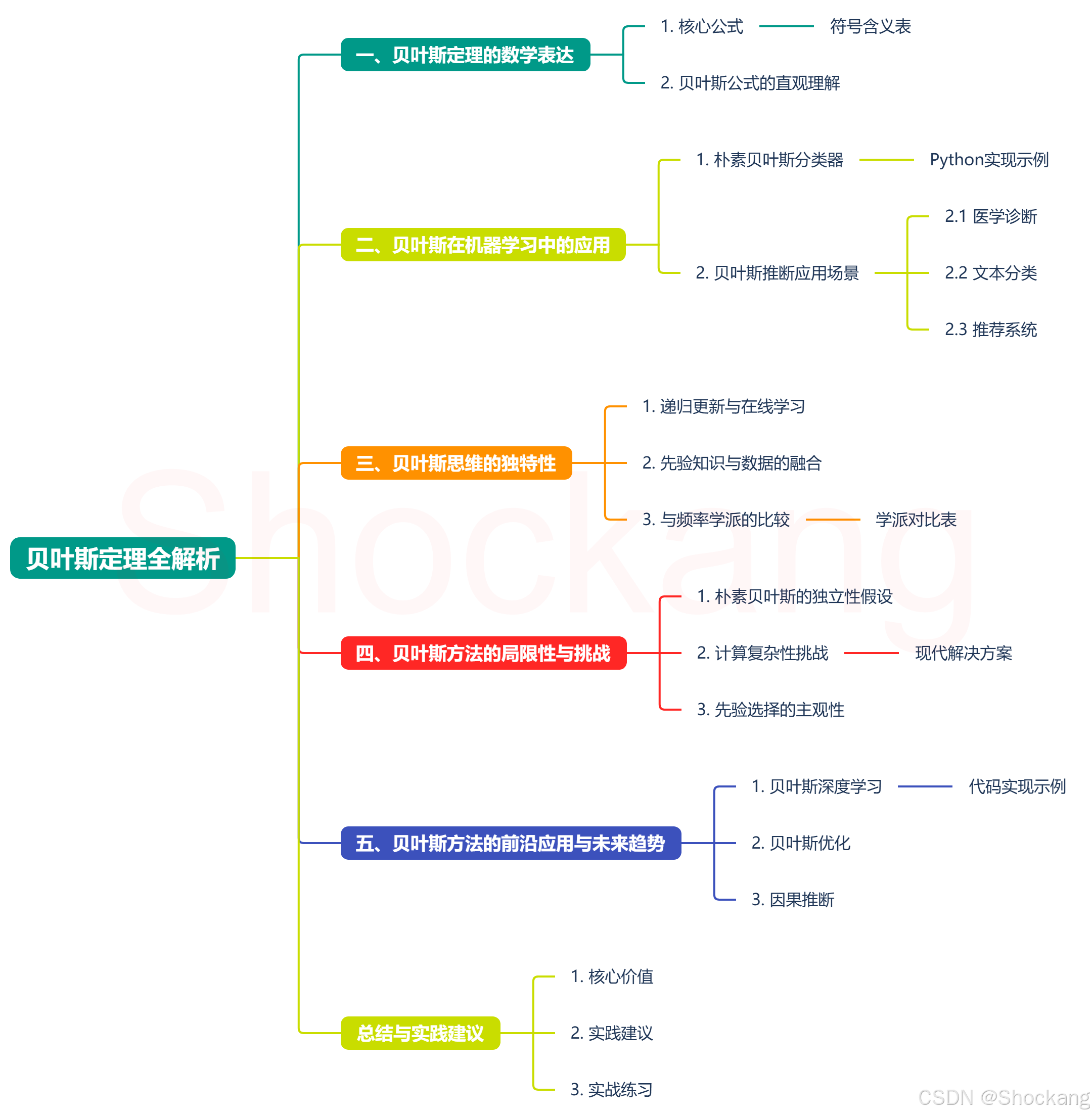
🧩 一、贝叶斯定理的数学表达
🔍 核心公式
贝叶斯定理是概率论和机器学习的基石,其核心公式为:
P ( H ∣ D ) = P ( D ∣ H ) ⋅ P ( H ) P ( D ) P(H|D) = \frac{P(D|H) \cdot P(H)}{P(D)} P(H∣D)=P(D)P(D∣H)⋅P(H)
各组成部分的含义:
| 符号 | 名称 | 含义 | 机器学习对应 |
|---|---|---|---|
| P ( H ∣ D ) P(H|D) P(H∣D) | 后验概率 | 在观察到数据D后,假设H成立的概率 | 模型根据数据预测的类别概率 |
| P ( H ) P(H) P(H) | 先验概率 | 在观察数据前,假设H的初始概率 | 类别的原始分布 |
| P ( D ∣ H ) P(D|H) P(D∣H) | 似然概率 | 若假设H为真,观察到数据D的概率 | 特定类别产生特定特征的概率 |
| P ( D ) P(D) P(D) | 边缘概率/证据 | 数据D出现的总概率 | 用于归一化,确保后验概率和为1 |
🔄 贝叶斯公式的直观理解
简化记忆: 后验概率 ∝ 似然 × 先验 后验概率 \propto 似然 \times 先验 后验概率∝似然×先验
这表达了贝叶斯学派的核心思想:通过新证据不断更新我们的信念。
🚀 二、贝叶斯在机器学习中的应用
📊 朴素贝叶斯分类器
朴素贝叶斯是最经典的贝叶斯机器学习算法,其"朴素"来自于特征条件独立性假设:
P ( x 1 , x 2 , . . . , x n ∣ c ) = P ( x 1 ∣ c ) × P ( x 2 ∣ c ) × . . . × P ( x n ∣ c ) P(x_1,x_2,...,x_n|c) = P(x_1|c) \times P(x_2|c) \times ... \times P(x_n|c) P(x1,x2,...,xn∣c)=P(x1∣c)×P(x2∣c)×...×P(xn∣c)
💻 Python实现示例
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.pipeline import Pipeline
# 垃圾邮件分类训练数据
emails = ["免费获取", "会议通知", "促销优惠", "项目报告", "中奖通知"]
labels = [1, 0, 1, 0, 1] # 1表示垃圾邮件,0表示正常邮件
# 创建朴素贝叶斯分类器
model = Pipeline([
('vectorizer', CountVectorizer()), # 将文本转换为词频向量
('classifier', MultinomialNB()) # 朴素贝叶斯分类器
])
# 训练模型
model.fit(emails, labels)
# 预测新邮件
new_emails = ["紧急会议通知", "免费获取优惠券"]
predictions = model.predict(new_emails)
probabilities = model.predict_proba(new_emails)
print(f"预测类别: {predictions}")
print(f"预测概率: {probabilities}")
🔍 贝叶斯推断应用场景
1️⃣ 医学诊断
假设乙肝检测的案例:
- 先验:乙肝发病率0.05%( P ( H ) = 0.0005 P(H) = 0.0005 P(H)=0.0005)
- 似然:检测准确率99.9%( P ( D ∣ H ) = 0.999 P(D|H) = 0.999 P(D∣H)=0.999),误报率0.1%( P ( D ∣ ¬ H ) = 0.001 P(D|\neg H) = 0.001 P(D∣¬H)=0.001)
通过贝叶斯公式计算:
P ( H ∣ D ) = P ( D ∣ H ) ⋅ P ( H ) P ( D ∣ H ) ⋅ P ( H ) + P ( D ∣ ¬ H ) ⋅ P ( ¬ H ) P(H|D) = \frac{P(D|H) \cdot P(H)}{P(D|H) \cdot P(H) + P(D|\neg H) \cdot P(\neg H)} P(H∣D)=P(D∣H)⋅P(H)+P(D∣¬H)⋅P(¬H)P(D∣H)⋅P(H)
= 0.999 × 0.0005 0.999 × 0.0005 + 0.001 × 0.9995 ≈ 0.333 = \frac{0.999 \times 0.0005}{0.999 \times 0.0005 + 0.001 \times 0.9995} \approx 0.333 =0.999×0.0005+0.001×0.99950.999×0.0005≈0.333
这意味着即使检测呈阳性,患病概率也只有约33.3%!这种**基础概率谬误(base rate fallacy)**在医疗决策中尤为重要。
2️⃣ 文本分类
贝叶斯定理在NLP中的应用:
P ( 类别 ∣ 文档 ) ∝ P ( 文档 ∣ 类别 ) × P ( 类别 ) P(类别|文档) \propto P(文档|类别) \times P(类别) P(类别∣文档)∝P(文档∣类别)×P(类别)
- 垃圾邮件过滤: P ( 垃圾邮件 ∣ " 免费 " ) ∝ P ( " 免费 " ∣ 垃圾邮件 ) × P ( 垃圾邮件 ) P(垃圾邮件|"免费") \propto P("免费"|垃圾邮件) \times P(垃圾邮件) P(垃圾邮件∣"免费")∝P("免费"∣垃圾邮件)×P(垃圾邮件)
- 情感分析: P ( 积极评价 ∣ " 喜欢 " ) ∝ P ( " 喜欢 " ∣ 积极评价 ) × P ( 积极评价 ) P(积极评价|"喜欢") \propto P("喜欢"|积极评价) \times P(积极评价) P(积极评价∣"喜欢")∝P("喜欢"∣积极评价)×P(积极评价)
3️⃣ 推荐系统
贝叶斯个性化排序(BPR)利用贝叶斯框架优化排序任务:
P ( i > u j ) = σ ( x u i j ) P(i >_u j) = \sigma(x_{uij}) P(i>uj)=σ(xuij)
其中 i > u j i >_u j i>uj 表示用户 u u u偏好项目 i i i胜过项目 j j j的概率。
🧠 三、贝叶斯思维的独特性
🔄 递归更新与在线学习
贝叶斯框架天然支持递归更新,使其非常适合在线学习场景:
今天的后验 = 明天的先验
P ( H ∣ D 1 , D 2 ) ∝ P ( D 2 ∣ H , D 1 ) × P ( H ∣ D 1 ) P(H|D_1, D_2) \propto P(D_2|H, D_1) \times P(H|D_1) P(H∣D1,D2)∝P(D2∣H,D1)×P(H∣D1)
🤝 先验知识与数据的融合
贝叶斯方法的独特优势是能将领域知识(先验)与观测数据(似然)优雅结合:
- 正则化作用:先验概率可视为隐式正则化,防止过拟合
- 小样本学习:当数据稀少时,先验知识尤为重要
- 不确定性量化:提供完整的参数分布而非点估计
📊 与频率学派的比较
| 方面 | 贝叶斯学派 | 频率学派 |
|---|---|---|
| 参数观点 | 参数是随机变量 | 参数是固定但未知的常数 |
| 概率解释 | 表示信念程度 | 表示长期频率 |
| 估计方法 | 后验分布 | 点估计(MLE/MAP) |
| 不确定性 | 直接通过分布表示 | 通过置信区间间接表示 |
| 代表算法 | 贝叶斯网络、变分推断 | 最大似然估计、假设检验 |
⚠️ 四、贝叶斯方法的局限性与挑战
🧩 朴素贝叶斯的独立性假设
"朴素"假设特征间条件独立,但现实数据往往存在关联:
P("cheap" | 垃圾邮件) 和 P("free" | 垃圾邮件) 并非独立
解决方案:
- 贝叶斯网络:通过有向无环图(DAG)建模特征间依赖关系
- 结构化预测:考虑特征间的结构关系
🧮 计算复杂性挑战
对于复杂模型,后验分布的精确计算通常难以实现:
P ( θ ∣ D ) = P ( D ∣ θ ) P ( θ ) ∫ P ( D ∣ θ ′ ) P ( θ ′ ) d θ ′ P(θ|D) = \frac{P(D|θ)P(θ)}{\int P(D|θ')P(θ')dθ'} P(θ∣D)=∫P(D∣θ′)P(θ′)dθ′P(D∣θ)P(θ)
其中分母积分在高维空间中计算困难。
现代解决方案:
- MCMC:马尔可夫链蒙特卡洛方法(如Metropolis-Hastings算法)
- 变分推断:将贝叶斯推断转化为优化问题
- 近似贝叶斯计算(ABC):当似然难以计算时使用
# 变分贝叶斯示例代码片段(PyMC3)
import pymc3 as pm
with pm.Model() as model:
# 先验
mu = pm.Normal('mu', mu=0, sigma=1)
sigma = pm.HalfNormal('sigma', sigma=1)
# 似然
y_obs = pm.Normal('y_obs', mu=mu, sigma=sigma, observed=data)
# 变分推断
trace = pm.fit(method='advi')
👀 先验选择的主观性
不恰当的先验可能导致偏差。解决方式:
- 无信息先验:尽量减少对后验的影响
- 层次贝叶斯模型:从数据中学习先验
- 敏感性分析:测试不同先验的影响
🔮 五、贝叶斯方法的前沿应用与未来趋势
🤖 贝叶斯深度学习
结合贝叶斯推断与深度学习的优势:
- 贝叶斯神经网络(BNN):为权重分配概率分布而非点值
- 贝叶斯丢弃法(Bayesian Dropout):重新解释dropout作为变分推断
- 不确定性量化:为预测提供可靠的置信度估计
# Bayesian Neural Network with TensorFlow Probability
import tensorflow as tf
import tensorflow_probability as tfp
def bayesian_neural_network(features):
# 定义权重的先验分布
w1 = tfp.layers.DenseVariational(
units=10,
make_posterior_fn=tfp.layers.default_mean_field_normal_fn(),
make_prior_fn=lambda *args, **kwargs: tfp.distributions.Normal(loc=0., scale=1.),
)(features)
w2 = tfp.layers.DenseVariational(
units=1,
make_posterior_fn=tfp.layers.default_mean_field_normal_fn(),
make_prior_fn=lambda *args, **kwargs: tfp.distributions.Normal(loc=0., scale=1.),
)(w1)
return w2
🎯 贝叶斯优化
结合高斯过程与贝叶斯框架的黑盒优化方法:
- 超参数优化:比网格搜索与随机搜索更高效
- A/B测试:通过汤普森抽样(Thompson Sampling)平衡探索与利用
- 强化学习:贝叶斯方法在不确定环境中的策略优化
🔄 因果推断
贝叶斯网络在因果关系建模中的应用:
- 从数据中发现因果结构
- 预测干预效果
- 处理反事实问题
📝 总结与实践建议
🌟 核心价值
贝叶斯方法的价值在于:
- 量化不确定性:提供完整的概率分布而非点估计
- 融合先验知识:将领域专业知识纳入模型
- 迭代更新学习:根据新证据不断优化认知
💡 实践建议
- 选择合适问题:数据较少、需要不确定性估计、有强先验知识的场景
- 先从简单开始:优先尝试朴素贝叶斯等基础模型
- 软件工具:熟悉PyMC3、Stan、TensorFlow Probability等贝叶斯推断库
- 结合经典方法:贝叶斯方法通常可与深度学习等现代技术互补
🚀 实战练习
尝试解决以下贝叶斯思维练习题,巩固所学知识:
- 如果某种疾病的发病率为0.1%,检测灵敏度为99%,特异性为98%,那么检测阳性的患者真实患病概率是多少?
- 实现一个朴素贝叶斯分类器处理IMDB电影评论数据集,探索不同先验设置对结果的影响。
- 尝试使用贝叶斯优化寻找神经网络的最佳超参数。
贝叶斯定理从18世纪提出至今,已发展成为机器学习领域的重要基石。掌握贝叶斯思维不仅能帮助我们构建更好的模型,更能培养在不确定世界中的科学决策能力。下次遇到不确定性问题时,请记住贝叶斯的睿智:当新证据出现时,更新你的信念。
“我们所拥有知识的确定性程度取决于支持这些知识的证据的强度。” —— 托马斯·贝叶斯

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)