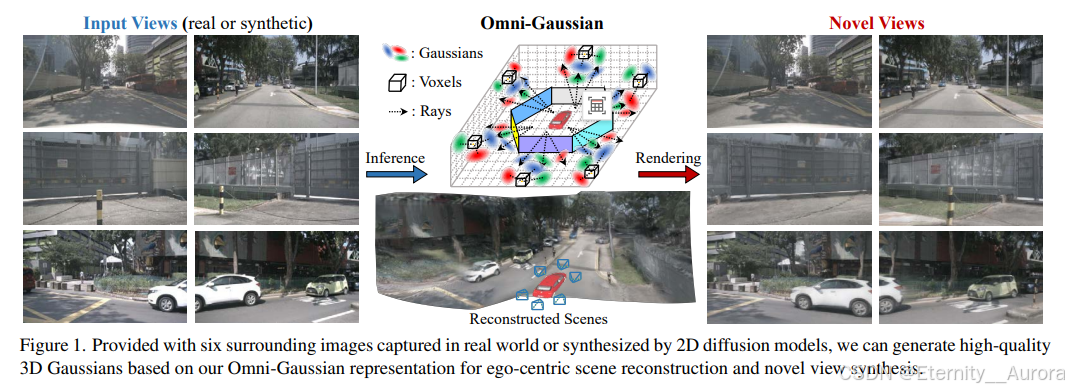
【论文笔记】Omni-Scene——以自我为中心稀疏视图场景重建的全高斯表征
Omni-Scene: 采用 Omni-Gaussian 表示法,通过结合基于像素和基于体积高斯表示的优势,实现了以自我中心的稀疏视图场景下高保真的三维重建,并支持多模态三维场景生成。
原文链接:https://arxiv.org/abs/2412.06273

原文摘要:以往采用基于像素的高斯表示的工作已在前馈稀疏视图重建中证明了其有效性。然而,这种表示需要跨视图重叠以实现准确的深度估计,并且在面对物体遮挡和视锥截断时面临挑战。因此,这些方法需要以场景为中心的数据采集来保持跨视图重叠,并通过完整的场景可见性来避免遮挡和截断,这限制了它们在场景重建中的适用性。相比之下,在自动驾驶场景中,一个更实用的范式是以自我为中心的重建,其特点是跨视图重叠极小且频繁出现遮挡和截断。 因此,像素表示的局限性阻碍了以往工作在这一任务中的应用。鉴于此,本文对不同表示方法进行了深入分析,并引入了 Omni-Gaussian 表示,并针对其进行了定制的网络设计,以发挥它们的优势并弥补其不足。实验表明,我们的方法在以自我为中心的重建中显著优于当前最先进的方法 PixelSplat 和 MVSplat,并且在场景重建中的表现与以往工作相当。
一、核心要点
Omni-Scene: 采用 Omni-Gaussian 表示法,通过结合基于像素和基于体积高斯表示的优势,实现了以自我中心的稀疏视图场景下高保真的三维重建,并支持多模态三维场景生成。
二、研究背景
1. 传统的基于像素高斯表示的重建方法
- 依赖于跨视图重叠的表示以实现准确的深度估计,在面对物体遮挡和视锥截断时面临挑战。(前提条件复杂)
- 只能依赖于非遮挡物体的二维局部特征来推断被遮挡的物体,需要以场景为中心(scene-centric) 的数据采集来保持跨视图重叠,并通过完整的场景可见性来避免遮挡和截断。(不适用于自动驾驶等场景)
2. 自动驾驶系统实际情况
- 以自我为中心(ego-centric) 的场景重建,只能从安装在车辆周围的刚性摄像头获取输入视图,相邻摄像头之间仅存在极小的重叠区域,且具有频繁的物体遮挡和视锥截断。
3. 三维感知工作中采用的体积表示方法
优势:
- 体积在三维空间中是空间连续的,二维输入中缺失的内容可以通过三维层面的邻近内容来补充
- 借助相机投影知识实现交叉注意力可以直接将二维特征提升到三维空间,不需要基于深度的反投影
不足:
- 编码体积特征的立方复杂性( O ( n 3 ) O(n^3) O(n3))限制了体积分辨率,可能会导致细节缺失
4. 本文主要贡献
- 提出了 Omni-Scene,这是一种用于以自我为中心的重建的 Omni-Gaussian 表示,它结合了像素和基于体积的表示的优点,同时消除了它们的缺点。
- 在一个流行的驾驶数据集(即nuScenes)中引入了一个新的以自我为中心的重建任务,目标是仅使用单帧周围图像进行场景级三维重建和新视图合成。
- 实验证明:在以自我为中心的任务中显著优于最先进的前馈重建方法,包括 PixelSplat 和 MVSplat。在 RealEstate10K 数据集上进行的场景重建任务中也取得了与以往工作相当的性能。
三、研究方法
Omni-Scene是一种以自我为中心的、稀疏视图重建的前馈方法。如图所示:

- 首先,(a)以 K K K 个环视图像 { I i } i = 1 K \{I^i\}_{i=1}^K {Ii}i=1K 作为输入,并使用以 DINO 目标预训练的 ResNet-50 主干提取下采样特征 F = { F i } i = 1 K F = \{F^i\}_{i=1}^K F={Fi}i=1K。
- 随后,(b,c)将特征分别输入 Volume Builder 和 Pixel Decorator,预测基于体素的高斯 G V G_V GV 和基于像素的高斯 G P G_P GP。
- 最后,采用体素-像素协同的设计,使 G V G_V GV 与 G P G_P GP 进行特征交互并获取属性,得到 Omni-Gaussian 表达 G G G。
1. 输入和输出
输入:来自周围摄像头的 K 张图像,这些图像是在单帧中捕获或合成的。
输出:基于这些输入图像生成高质量的三维高斯表示,用于自我中心场景重建和新视图合成。
2. Volume Builder:负责预测粗略的三维结构,预测基于体积的高斯
(1)Triplane Transformer
负责将二维多视图图像特征提升到三维体积空间,利用三平面来将体积分解为三个轴对齐的正交平面 HW、ZH 和 WZ。利用可变形注意力来实现二维和三维空间之间稀疏但有效的空间相关性。
跨图像可变形注意力(Cross-Image Deformable Attention,CIDA),以 HW 平面为例: 对于查询 q h , w q_{h,w} qh,w,将其扩展到沿 Z 轴均匀分布的多个三维柱状点,并通过将它们投影回输入视图来计算它们在二维空间中的参考点 Ref h , w 2 D \text{Ref}_{h,w}^{2D} Refh,w2D。表示为:
q h , w C I D A = 1 K ′ ∑ i = 1 K ′ DA ( q h , w , Ref h , w , i 2 D , F i ) q_{h,w}^{CIDA} = \frac{1}{K'} \sum_{i=1}^{K'} \text{DA}(q_{h,w}, \text{Ref}_{h,w,i}^{2D}, F_i) qh,wCIDA=K′1i=1∑K′DA(qh,w,Refh,w,i2D,Fi)
其中 K ′ K′ K′、 Ref h , w , i 2 D \text{Ref}_{h,w,i}^{2D} Refh,w,i2D 和 D A DA DA 分别表示相关视图的数量、第 i 个相关视图中的二维参考点和可变形注意力函数。
跨平面可变形注意力(Cross-Plane Deformable Attention, CPDA),对于查询 q h , w q_{h,w} qh,w,将它的坐标 (h, w) 投影到 HW、ZH 和 WZ 平面上,以获得三组参考点 Ref h , w 3 D = Ref h , w H W ∪ Ref h , w Z H ∪ Ref h , w W Z \text{Ref}_{h,w}^{3D} = \text{Ref}_{h,w}^{HW} \cup \text{Ref}_{h,w}^{ZH} \cup \text{Ref}_{h,w}^{WZ} Refh,w3D=Refh,wHW∪Refh,wZH∪Refh,wWZ
利用 Ref h , w 3 D \text{Ref}_{h,w}^{3D} Refh,w3D,可以从不同平面中提取上下文信息,从而增强特征,表示为:
q h , w C P D A = DA ( q h , w , Ref h , w 3 D , Q H W , Q Z H , Q W Z ) q_{h,w}^{CPDA} = \text{DA}(q_{h,w}, \text{Ref}_{h,w}^{3D}, Q_{HW}, Q_{ZH}, Q_{WZ}) qh,wCPDA=DA(qh,w,Refh,w3D,QHW,QZH,QWZ)
对所有平面的查询重复上述两种交叉注意力操作,可以获得具有丰富语义和空间上下文的三平面特征,无需依赖于以往仅依赖于像素级高斯表示的方法所必需的跨视图重叠。
(2) Volume Decoder
- 给定一个位于 (h, w, z) 的体素,首先将其坐标投影到三个平面上,通过双线性插值获得平面特征,然后进行逐平面求和以得到聚合的体素特征 f h , w , z f_{h,w,z} fh,w,z。
- 接下来,在 f h , w , z f_{h,w,z} fh,w,z 后附加三个线性层,以预测各项高斯参数(V个)。
- 对所有体素重复相同的操作,获得我们的基于体积的高斯表示 G V ∈ R H × W × Z × V × D G_V ∈ R^{H×W×Z×V×D} GV∈RH×W×Z×V×D,其中 V 代表每个体素锚定的高斯参数的数量,D 是高斯参数的维度。
3. Pixel Decorator:负责提取跨视图相关特征,预测基于像素的高斯。
必要性:
- G P G_P GP(基于像素的高斯)是与细粒度图像空间对齐的,可以为粗略的以体素为锚点的高斯 G V G_V GV 添加细节
- G P G_P GP 可以被反投影到无限远处的位置,它可以补充体积受限的 G V G_V GV 中的远距离高斯。
(1)Multi-View U-Net:负责提取跨视图相关特征
- 拼接图像特征 { F i } i = 1 K \left\{F^{i}\right\}_{i=1}^{K} {Fi}i=1K 及Plücker射线嵌入 { S i } i = 1 K \left\{S^{i}\right\}_{i=1}^{K} {Si}i=1K 作为输入(后者可提供相机姿态信息)
- 使用分块的交叉注意力进行跨视图交互,获取3D感知的特征 { F ^ i } i = 1 K \left\{\hat{F}^{i}\right\}_{i=1}^{K} {F^i}i=1K
(2)Pixel Decoder:负责预测基于像素的高斯
- 通过双线性插值,上采样U-Net特征 { F i } i = 1 K \left\{F^{i}\right\}_{i=1}^{K} {Fi}i=1K到原始图像分辨率,
- 通过卷积解码得到每个像素深度 d p d_{p} dp 和高斯参数 ( δ p , α p , s p , q p , c p ) \left(\delta_{p}, \alpha_{p}, s_{p}, q_{p}, c_{p}\right) (δp,αp,sp,qp,cp)。
- 其中,高斯中心位置通过 µ p = o p + d p ⋅ r p + δ p µ_p = o_p + d_p·r_p + δ_p µp=op+dp⋅rp+δp得到.
4. Volume-Pixel Collaboration:实现两种高斯表示之间的协作
基于投影的特征融合和深度引导的训练分解
(1)基于投影的特征融合
将三平面查询 Q H W Q_{HW} QHW、 Q Z H Q_{ZH} QZH、 Q W Z Q_{WZ} QWZ 与基于像素的高斯 G P G_P GP 的投影特征进行融合。
- 以 HW 平面为例:首先筛选出超出体积范围 H×W×Z 的 G P G_P GP 中的高斯。
- 收集剩余 G P G_P GP 的 U-Net 特征并将它们投影到 HW 平面上。投影到相同查询位置的特征进行平均池化,并在经过线性层变换后添加到 QHW 的相应查询中。
- 对 ZH 和 WZ 平面应用相同的过程。
(2)深度引导的训练分解
根据像素和基于体积的高斯的不同空间属性分解训练目标。
- 使用 G P G_P GP 为所有 K 个输入视图渲染深度图 { D ^ i } i = 1 K \left\{\hat{D}^{i}\right\}_{i=1}^{K} {D^i}i=1K
- 根据估计的深度将所有像素沿射线方向反投影到三维位置。
- 通过将位于 H×W×Z 范围内的像素分配为 1,其余像素分配为 0,我们可以获得掩膜 M ^ = { M ^ i } i = 1 K \hat{M} = \{ \hat{M}^i \}^K_{i=1} M^={M^i}i=1K。
- 使用 M ^ \hat{M} M^ 计算掩膜光度损失(即均方误差 L V m s e L^{mse}_V LVmse 和 LPIPS 损失 L V l p i p s L^{lpips}_V LVlpips)以及掩膜L1 深度损失 L V d p t L^{dpt}_V LVdpt,用于输入视图图像和从 G V G_V GV 渲染的深度(其中只有掩膜值为 1 的像素将用于损失计算)
- 结合从完整高斯 G = G V ∪ G P G = G_V ∪ G_P G=GV∪GP 渲染的新视图图像的光度损失 L f u l l m s e L^{mse}_{full} Lfullmse 和 L f u l l l p i p s L^{lpips}_{full} Lfulllpips,整体训练目标 L 可以表示为:
L = L f u l l m s e + λ 1 L f u l l l p i p s + λ 2 L V , L V = L V m s e + λ V 1 L V l p i p s + λ V 2 L V d p t \begin{align*} L &= L_{full}^{mse} + \lambda_1 L_{full}^{lpips} + \lambda_2 L_V, \\ L_V &= L_V^{mse} + \lambda_{V_1} L_V^{lpips} + \lambda_{V_2} L_V^{dpt} \end{align*} LLV=Lfullmse+λ1Lfulllpips+λ2LV,=LVmse+λV1LVlpips+λV2LVdpt
其中: λ 1 λ_1 λ1 和 λ 2 λ_2 λ2 是 G 的 LPIPS 损失和 G V G_V GV 的复合损失的权重, λ V 1 λ_{V1} λV1 和 λ V 2 λ_{V2} λV2 分别是 G V G_V GV 的 LPIPS 和深度损失的权重。
四、实验结果


实验在 nuScenes 和 RealEstate10K 数据集上进行,结果表明 Omni-Scene 在自我中心重建任务中显著优于现有的最先进方法,如 pixelSplat 和 MVSplat。此外,在场景中心重建任务中,Omni-Scene 也展现出与先前工作相当的性能。消融研究进一步验证了 Omni-Gaussian 表示和体积-像素协作设计的有效性。
五、应用价值
Omni-Scene 的提出为自我中心场景的三维重建提供了一种高效且准确的方法,特别是在自动驾驶和虚拟现实等应用中,这些领域通常面临稀疏视图和复杂环境的挑战。此外,该方法还可以与二维扩散模型集成,实现多模态三维场景生成,具有广泛的应用前景。
总结来说,Omni-Scene 通过创新的 Omni-Gaussian 表示和体积-像素协作设计,显著提升了自我中心稀疏视图场景重建的性能,为相关领域的研究和应用提供了新的思路和工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)