
互信息详解
📊 互信息:机器学习特征选择的隐藏利器!本文深入浅出剖析互信息的数学本质,从熵与KL散度双重视角诠释核心原理,配合Python实现代码与实际应用案例,助你摆脱线性相关局限,发掘数据间真正的非线性关联。无论是特征工程还是模型评估,这篇通关指南都能让你的ML技能更上一层楼!
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
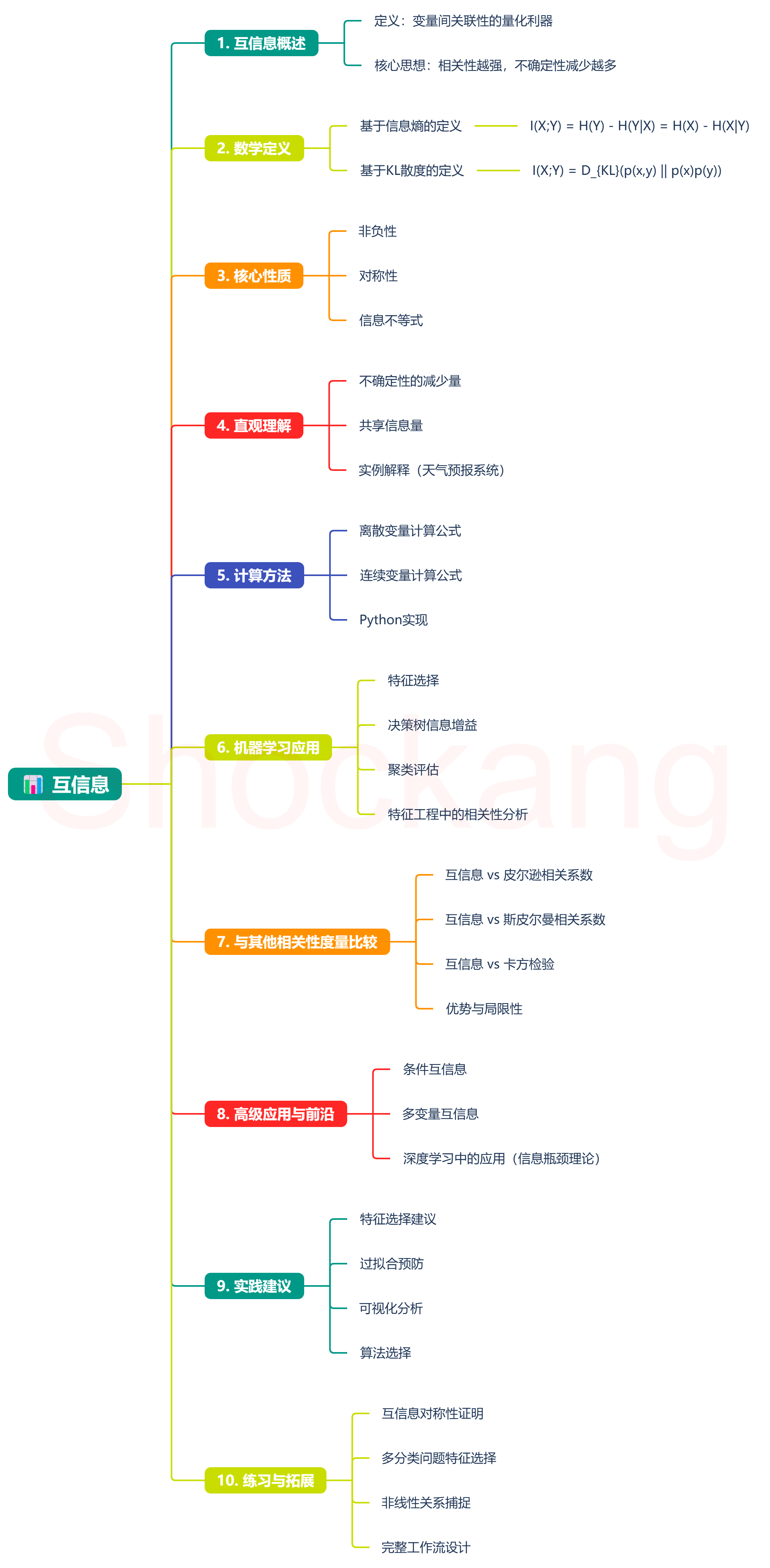
🔍 互信息:变量间关联性的量化利器
互信息(Mutual Information)是信息论中的核心概念,也是机器学习特征选择、模型评估的重要工具。本文将带您深入理解这一概念的数学本质与应用价值。
1️⃣ 互信息的数学定义
互信息衡量两个随机变量之间"共享"的信息量,即它们之间的相关程度。从不同角度,互信息有以下等价定义:
基于信息熵的定义 📝
互信息可以表示为信息熵与条件熵之差:
I ( X ; Y ) = H ( Y ) − H ( Y ∣ X ) = H ( X ) − H ( X ∣ Y ) I(X;Y) = H(Y) - H(Y|X) = H(X) - H(X|Y) I(X;Y)=H(Y)−H(Y∣X)=H(X)−H(X∣Y)
其中:
- (H(Y)) 是随机变量 (Y) 的信息熵,衡量 (Y) 的不确定性
- (H(Y|X)) 是条件熵,表示已知 (X) 后 (Y) 的剩余不确定性
这一定义直观体现了"获取信息 = 减少不确定性"的本质。
基于KL散度的定义 🔄
互信息也可以定义为联合分布与边缘分布乘积之间的KL散度:
I ( X ; Y ) = D K L ( p ( x , y ) ∥ p ( x ) p ( y ) ) = ∑ x , y p ( x , y ) log p ( x , y ) p ( x ) p ( y ) I(X;Y) = D_{KL}(p(x,y) \parallel p(x)p(y)) = \sum_{x,y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)} I(X;Y)=DKL(p(x,y)∥p(x)p(y))=∑x,yp(x,y)logp(x)p(y)p(x,y)
这表明互信息度量的是联合分布与独立情况下的分布之间的"距离"。
2️⃣ 互信息的核心性质 ⭐
互信息具有以下关键性质:
非负性 ✅
I ( X ; Y ) ≥ 0 I(X;Y) \geq 0 I(X;Y)≥0
互信息始终非负,当且仅当 (X) 和 (Y) 相互独立时等于零。
对称性 🔄
I ( X ; Y ) = I ( Y ; X ) I(X;Y) = I(Y;X) I(X;Y)=I(Y;X)
变量间的互信息是对称的,不存在方向性。
信息不等式 📊
I ( X ; Y ) ≤ min { H ( X ) , H ( Y ) } I(X;Y) \leq \min\{H(X), H(Y)\} I(X;Y)≤min{H(X),H(Y)}
互信息不会超过任一变量自身的熵。
3️⃣ 直观理解互信息 💡
不确定性的减少量 📉
互信息可理解为:
“知道 (X) 后,(Y) 的不确定性减少了多少?”
当 (I(X;Y)) 较大时,表示已知 (X) 能显著降低对 (Y) 的不确定性,意味着两个变量高度相关。
实例解释 🌟
想象一个天气预报系统:
- 如果今天的天气((X))与明天的天气((Y))高度相关,那么知道今天天气后,我们对明天天气的预测准确度会大幅提高
- 这时 (I(X;Y)) 较大,表示两个变量共享信息量大
4️⃣ 互信息的计算 🧮
离散变量
对于离散随机变量,互信息计算为:
I ( X ; Y ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log p ( x , y ) p ( x ) p ( y ) I(X;Y) = \sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)} I(X;Y)=∑x∈X∑y∈Yp(x,y)logp(x)p(y)p(x,y)
连续变量
对于连续随机变量,互信息通过积分计算:
I ( X ; Y ) = ∫ X ∫ Y p ( x , y ) log p ( x , y ) p ( x ) p ( y ) d x d y I(X;Y) = \int_X \int_Y p(x,y) \log \frac{p(x,y)}{p(x)p(y)} dx dy I(X;Y)=∫X∫Yp(x,y)logp(x)p(y)p(x,y)dxdy
Python实现示例 💻
import numpy as np
from sklearn.metrics import mutual_info_score
from sklearn.feature_selection import mutual_info_classif
# 离散变量的互信息计算
def mutual_information_discrete(x, y):
# 构建联合概率分布
xy_counts = np.zeros([len(np.unique(x)), len(np.unique(y))])
x_values = np.unique(x)
y_values = np.unique(y)
x_idx = {x_val: idx for idx, x_val in enumerate(x_values)}
y_idx = {y_val: idx for idx, y_val in enumerate(y_values)}
n_samples = len(x)
for i in range(n_samples):
xy_counts[x_idx[x[i]], y_idx[y[i]]] += 1
# 计算联合概率和边缘概率
xy_probs = xy_counts / n_samples
x_probs = np.sum(xy_probs, axis=1)
y_probs = np.sum(xy_probs, axis=0)
# 计算互信息
mi = 0
for i in range(len(x_values)):
for j in range(len(y_values)):
if xy_probs[i, j] > 0:
mi += xy_probs[i, j] * np.log2(xy_probs[i, j] / (x_probs[i] * y_probs[j]))
return mi
# 使用sklearn进行计算(更推荐的方法)
X = np.array([0, 0, 1, 1, 0, 1, 0, 1])
Y = np.array([0, 1, 1, 0, 0, 1, 1, 0])
mi = mutual_info_score(X, Y)
print(f"互信息值: {mi:.4f}")
5️⃣ 互信息在机器学习中的应用 🚀
特征选择 ✨
互信息是评估特征与目标变量相关性的有效指标,不受线性关系限制:
from sklearn.feature_selection import SelectKBest, mutual_info_classif
import pandas as pd
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 使用互信息进行特征选择
selector = SelectKBest(mutual_info_classif, k=2)
X_selected = selector.fit_transform(X, y)
# 查看每个特征的互信息分数
mi_scores = pd.Series(selector.scores_, index=iris.feature_names)
mi_scores.sort_values(ascending=False)
决策树中的信息增益 🌲
在ID3决策树算法中,信息增益(互信息的一种应用)用于选择最优划分特征:
G a i n ( Y , A ) = H ( Y ) − H ( Y ∣ A ) Gain(Y, A) = H(Y) - H(Y|A) Gain(Y,A)=H(Y)−H(Y∣A)
其中Y是类别变量,A是特征。信息增益越高,表明该特征对分类越有价值。
聚类评估 📈
互信息用于评估聚类结果与真实标签的一致性:
from sklearn.metrics import mutual_info_score, normalized_mutual_info_score
from sklearn.cluster import KMeans
# 假设y_true是真实标签,y_pred是聚类结果
y_true = [0, 0, 1, 1, 0, 1, 0, 1]
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
y_pred = kmeans.labels_
# 计算标准化互信息
nmi = normalized_mutual_info_score(y_true, y_pred)
print(f"标准化互信息分数: {nmi:.4f}")
特征工程中的相关性分析 🛠️
互信息可用于识别特征间的非线性相关性,避免引入冗余特征:
import numpy as np
import pandas as pd
from sklearn.feature_selection import mutual_info_regression
import seaborn as sns
import matplotlib.pyplot as plt
def plot_mi_scores(X):
# 计算特征间的互信息矩阵
n_features = X.shape[1]
mi_matrix = np.zeros((n_features, n_features))
for i in range(n_features):
for j in range(n_features):
mi_matrix[i, j] = mutual_info_regression(X[:, i].reshape(-1, 1), X[:, j], random_state=0)[0]
# 可视化
plt.figure(figsize=(10, 8))
sns.heatmap(mi_matrix, annot=True, cmap='YlGnBu')
plt.title("特征间互信息矩阵")
plt.show()
6️⃣ 互信息与其他相关性度量的比较 🔍
| 度量指标 | 优点 | 局限性 | 适用场景 |
|---|---|---|---|
| 互信息 | 捕捉非线性关系 无分布假设 |
计算复杂 需要充分样本 |
非线性关系 分类变量 |
| 皮尔逊相关系数 | 计算简单 直观理解 |
仅捕捉线性关系 | 线性关系 正态分布数据 |
| 斯皮尔曼相关系数 | 捕捉单调关系 对异常值鲁棒 |
忽略非单调关系 | 单调非线性关系 |
| 卡方检验 | 适用于分类变量 | 对样本量敏感 | 分类特征选择 |
互信息的独特优势在于能够捕捉任意类型的依赖关系,而不仅限于线性或单调关系。
7️⃣ 高级应用与前沿进展 🔬
条件互信息
条件互信息衡量在已知第三个变量的情况下,两个变量间的相关性:
I ( X ; Y ∣ Z ) = H ( X ∣ Z ) − H ( X ∣ Y , Z ) I(X;Y|Z) = H(X|Z) - H(X|Y,Z) I(X;Y∣Z)=H(X∣Z)−H(X∣Y,Z)
这对于特征选择中的冗余检测尤为重要。
多变量互信息
多变量互信息拓展了两个变量的情况到多个变量:
I ( X 1 ; X 2 ; . . . ; X n ) = ∑ i = 1 n H ( X i ) − H ( X 1 , X 2 , . . . , X n ) I(X_1;X_2;...;X_n) = \sum_{i=1}^{n} H(X_i) - H(X_1,X_2,...,X_n) I(X1;X2;...;Xn)=∑i=1nH(Xi)−H(X1,X2,...,Xn)
深度学习中的应用
互信息原理被应用到深度表示学习中,如信息瓶颈理论(Information Bottleneck),用于平衡模型的表达能力与泛化能力。
8️⃣ 总结与实践建议 📝
互信息是连接信息论与机器学习的重要桥梁,其核心思想是:
相关性越强,不确定性减少越多
在实践中,建议:
- 🔹 特征选择:使用互信息而非相关系数寻找非线性特征
- 🔹 过拟合预防:使用信息论原理控制模型复杂度
- 🔹 可视化分析:通过互信息热力图发现数据中的潜在模式
- 🔹 算法选择:针对高互信息特征选择合适的算法
互信息是机器学习数学基础中不可或缺的概念,掌握它将帮助你更深入理解模型行为和数据特性,从而构建更高效的机器学习系统。
💯 练习题
- 证明互信息的对称性:(I(X;Y) = I(Y;X))
- 如何使用互信息进行多分类问题的特征选择?
- 分析互信息与皮尔逊相关系数在非线性关系捕捉上的差异
- 设计一个使用互信息进行特征筛选的完整机器学习工作流
希望这篇文章对你理解互信息的概念和应用有所帮助!如有疑问,欢迎在评论区讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)