论文阅读笔记——BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 论文阅读笔记
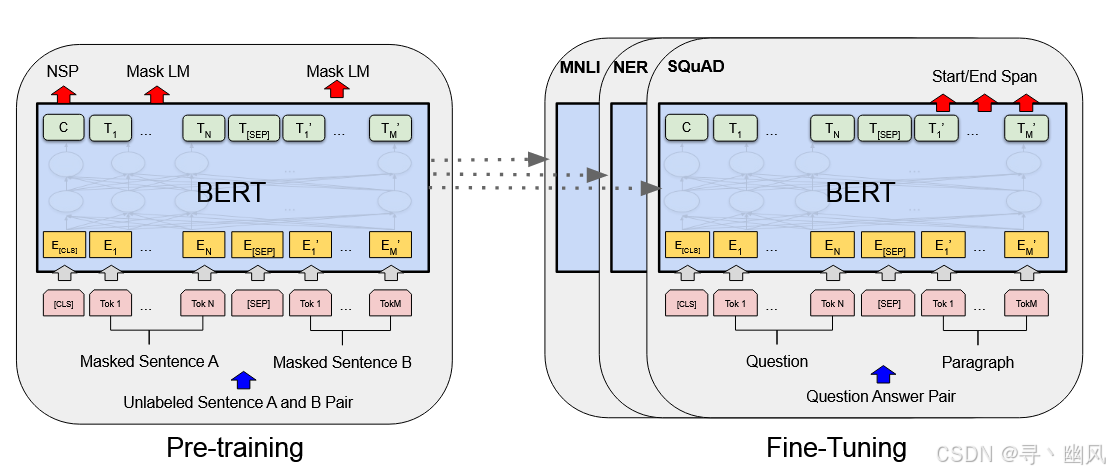
BERT 采用了 Transformer 的 encoder 侧网络,利用 self-attention 在编码一个 token 的时候同时利用了其上下文,并非像 Bi-LSTM 把句子倒序输入一遍。
BERT 在11种不同NLP测试中创出SOTA表现,将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
输入向量
BERT 的输入编码向量(512 个 token):
- WordPiece 嵌入:将单词划分成一组有限的公共字词单元,在有效性和字符的灵活性达到折中平衡。文本开头加上 [ C L S ] [CLS] [CLS] 表示用于分类任务,结尾加上 [ S E P ] [SEP] [SEP] 表示分句符号。
- Segment Embeddings:区分两个句子,如 B 是 A 的下文,A 都是 0,B 都是 1。
- Position Embeddings:与 transformer 的 position embeddings 不同,transformer 通过固定的正余弦计算得到,BERT 采用可学习的嵌入,意味着同一个单词处在不同位置,那么他们的 position embeddings 不同。实际上是一个 (512,768) 的单词查询表。

Masked LM(MLM)
将 15% 的单词被随机 Mask 掉,通过上下文来预测这些单词。
每次确定 Mask 的单词时,有 80% 直接替换为 [ M a s k ] [Mask] [Mask] ,10% 替换为其他任意单词,10% 保留原始 token。这么做的原因在于,如果句子的某个 token 被 100% Mask 掉,那么在微调的时候模型会有一些没见过的单词。加入随机 token 的原因是 transformer 要保持对每个输入 token 的分布式表征,否则模型就会记住 [ M a s k ] [Mask] [Mask] 是某个单词的 token。至于保留 15% × 10% = 1.5% 可忽略。
#Next Sentence Prediction(NSP)
该任务是判断句子 B 是否是句子 A 的上下文,是的话输出 IsNext,不是的话输出 NotNext,训练数据是通过从平行语料中随机抽取的连续两句话,50% 保留这两句话,符合 IsNext 关系,50% 随机抽取第二句话,符合 NotNext关系,该关系被记录在 [ C L S ] [CLS] [CLS] 中。
Finetune
基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个。
基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
问答任务
- SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 命名实体识别
- CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)