MapReduce实现TopN中文词频统计
最近在重新学习MapReduce框架,为之后学习Spark计算框架打下基础;想到之前实现过一个WordCount,借着大数据技术这门课的机会,在此项目中实现TopN中文词频统计。划重点!由于三个实验难度层层递进,故本文只对MapReduce实现TopN中文词频统计做重点阐述。但是后续会把三个项目的实现都打包发上来,感兴趣的家人可以自行下载参考。
国科大学习生活(期末复习资料、课程大作业解析、学习文档等): 文章专栏(点击跳转)
大数据开发学习文档(分布式文件系统的实现,大数据生态圈学习文档等): 文章专栏(点击跳转)
文档目录
MapReduce实现TopN中文词频统计
1. 背景描述
最近在重新学习MapReduce框架,为之后学习Spark计算框架打下基础;想到之前实现过一个WordCount,借着大数据技术这门课的机会,在此项目中实现TopN中文词频统计。划重点!
- 使用MapReduce框架实现(
Spark我还不会) - 区别于普通的单词计数,本次实现的是中文汉字计数(要使用分词器)
- 区别于单纯的统计词数,本项目实现的是求汉字词频的TopN
2. 实验过程
- MapReduce实现英文词频统计
- 使用中文分词工具实现中文词频统计
- 实现TopN中文词频统计。
由于三个实验难度层层递进,故本文只对MapReduce实现TopN中文词频统计做重点阐述。但是后续会把三个项目的实现都打包发上来,感兴趣的家人可以自行下载参考。
思路:
求TopN中文词频与单纯统计中文词频的区别主要是在reduce阶段,因为map阶段主要任务是处理输入文本,执行词频统计操作,而reduce阶段用于将相同单词的词频进行累加,并且执行TopN词频统计和将结果写入到输出文件的功能。
3. 完整项目代码
怕你们等不及没耐心,逼得我在文章第三部分就贴出来了完整代码!!!
复制粘贴会吧?复制粘贴到自己的项目里就能跑,但是有一点注意,其中有一个jar包(中文分词器)使用maven依赖导入会失败:在项目里不失败,等你打包完项目在hdfs运行的时候就出事了!会报错:java.lang.ClassNotFoundException: org.wltea.analyzer.core.IKSegmenter,所以还得自己去下载这个IKAnalyzer2012_u6.jar包,然后手动添加进项目里去。
百度网盘链接:https://pan.baidu.com/s/1xICjyCTM-fGC7aUlLc-9GQ
提取码:6s9r
接下来是项目完整代码,分为Mapper、Reducer以及Main三部分
Mapper类:(求TopN中文词频与单纯统计中文词频的Mapper类没有差别)
package TopNWordCount;
import java.io.*;
import java.nio.charset.StandardCharsets;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//下面这俩包是中文分词工具,下文会讲到。
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
public class TopNMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private final Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//分词工具的使用
byte[] bt = value.getBytes();
InputStream ip = new ByteArrayInputStream(bt);
Reader read = new InputStreamReader(ip, StandardCharsets.UTF_8);
IKSegmenter iks = new IKSegmenter(read,true);
Lexeme t;
while ((t = iks.next()) != null) {
word.set(t.getLexemeText());
context.write(word, ONE);
}
}
}
Reducer类:(求TopN中文词频的核心实现)
package TopNWordCount;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TopNReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private TreeMap<Integer, String> topWords;
private int count;
@Override
protected void setup(Context context) {
topWords = new TreeMap<>();
count = 0;
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) {
int frequency = 0;
for (IntWritable value : values) {
frequency += value.get();
}
//top50
topWords.put(frequency, key.toString());
if (topWords.size() > 50) {
topWords.remove(topWords.firstKey());
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Map.Entry<Integer, String> entry : topWords.descendingMap().entrySet()) {
int frequency = entry.getKey();
String word = entry.getValue();
context.write(new Text(word), new IntWritable(frequency));
}
}
}
主程序Main:(基本都是一个写法)
package TopNWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TopNMain {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Word Count Top N");
job.setJarByClass(TopNMain.class);
// Mapper和Reducer类设置
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
// 作业的输出键值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 输入和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 等待作业完成并打印统计结果
System.exit(job.waitForCompletion(true)?0:1);
}
}
3.1. 核心实现思路
首先大家要知道,这个项目代码的核心在于Reduce阶段,从代码中可以看到是使用了TreeMap这个数据结构,它是由红黑树实现,红黑树结构天然支持排序,默认情况下通过Key值的自然顺序进行排序。将词频作为key,对应的中文作为value存到TreeMap中,并通过
topWords.put(frequency, key.toString());
if (topWords.size() > 50) {
topWords.remove(topWords.firstKey());
}
//为什么是remove树结构的firstkey呢?
/*
在这里topWords是一个TreeMap对象,在通过topWords.put(frequency, key.toString());
往TreeMap里放数据的过程中,其实是会根据数据的key值自动排序的(由小到大)
所以我们要求Top50的时候,需要在TreeMap中的数据超过50条时,
将第一条数据删除掉(remove),因为它最小。
*/
来保证map中始终以词频自增的方式存储50条数据。
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//倒序map数据
for (Map.Entry<Integer, String> entry : topWords.descendingMap().entrySet()) {
int frequency = entry.getKey();
String word = entry.getValue();
context.write(new Text(word), new IntWritable(frequency));
}
}
在处理完map传过来的所有数据后,可以看到Reducer里还设置了一个cleanup函数:首先将上述map倒序,因为它默认是以key自增排序,而TopN的逻辑是要递减排序;然后获得map的key和value并以value和key的位置写入到输出文件(将词频改为了value,中文改为了key输出)。
即一开始数据格式为<4:学习>,操作后格式为<学习,4>,这么做的原因是为了满足输出格式。
大家对Reducer里的reduce函数应该没有什么疑问,现在重点讲一下setup()和cleanup()两个函数的作用:
setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
很明显,这两个函数的存在是为了节约资源,提高程序的运行效率。也就是说你就是不想用这俩方法把初始化资源和释放资源都放在map或者reduce里执行也没错。
TopNMain类不再赘述,与单纯统计中文词频没有差别。
3.2. 如何运行?
将上述代码都参考到项目里后,选择 文件–项目结构:
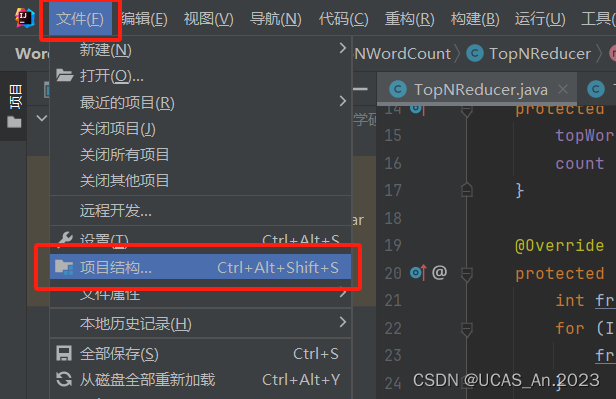
然后选择 工件–点击加号–选择JAR–来自具有依赖项的模块:
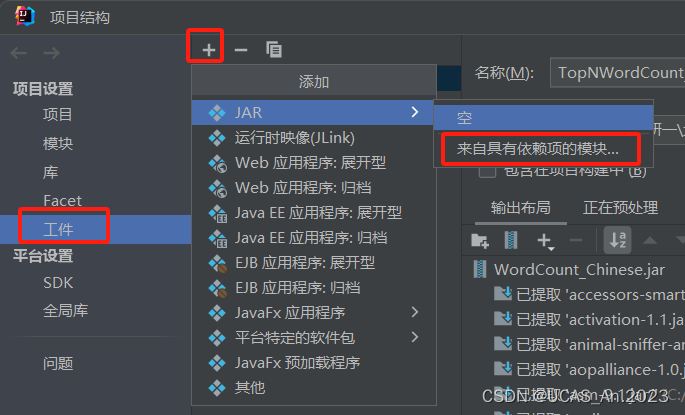
然后选择你的主类(只有一个),点击确定–确定–确定:
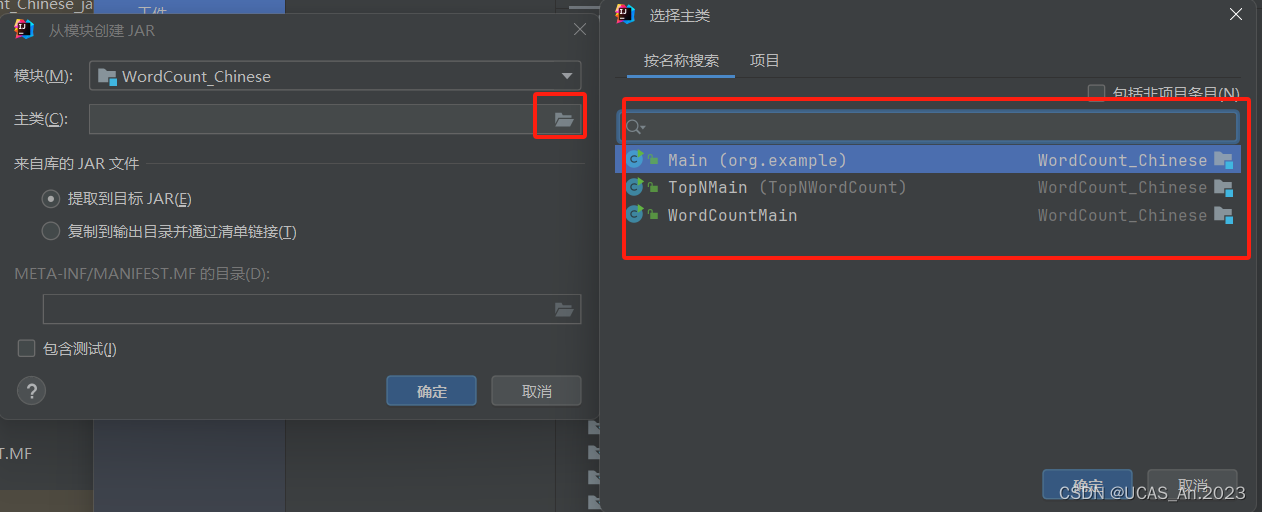
最后在菜单上点击 构建–构建工件:
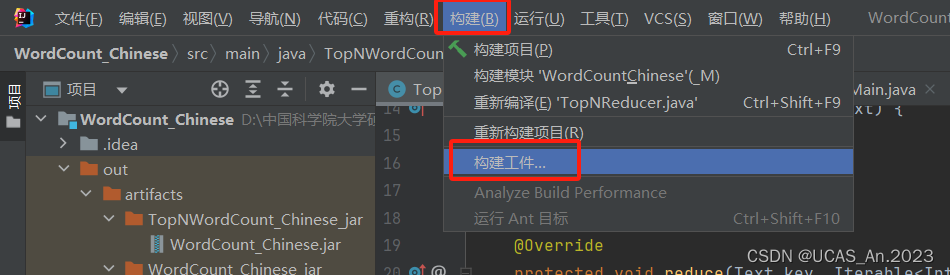
然后选择你的工件进行构建就好了:
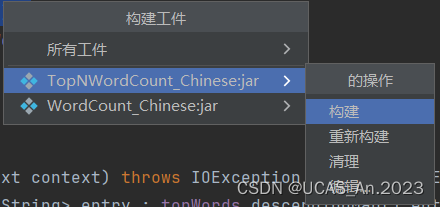
构建完成后在这找JAR包:
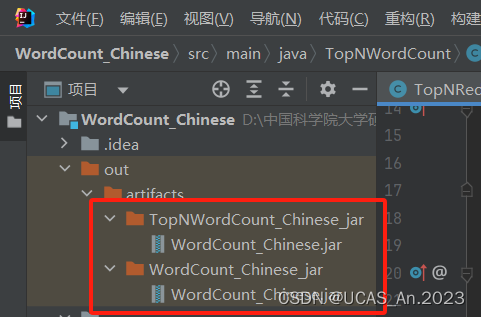
接下来上传到Hadoop上执行:
hadoop jar 你的jar包名 你输入文件的路径 你输出文件的路径
例如:
hadoop jar WordCount_Chinese.jar /WordCount/input/xiyouji.txt /WordCount/TopNoutput
成功得到输出:
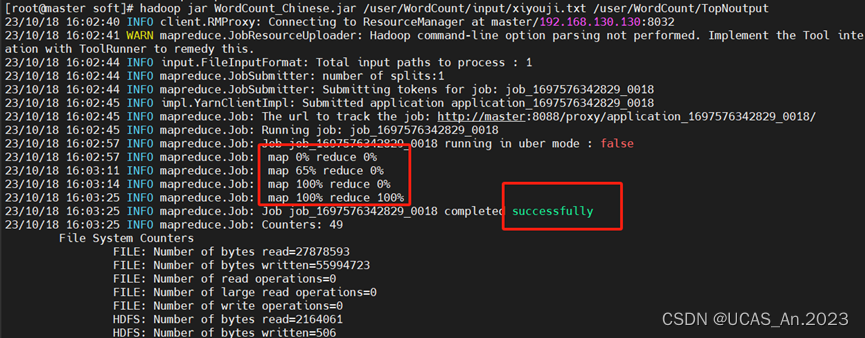
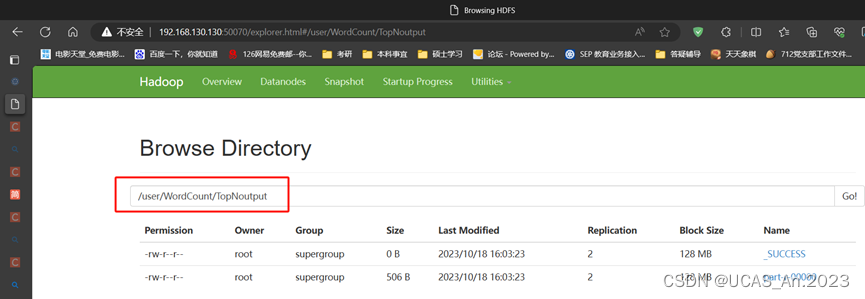
获取结果:hadoop fs -get /WordCount/TopNoutput/part-r-00000 TopNwords.txt
或者直接 hdfs dfs -cat /WordCount/TopNoutput/part-r-00000
查看结果:
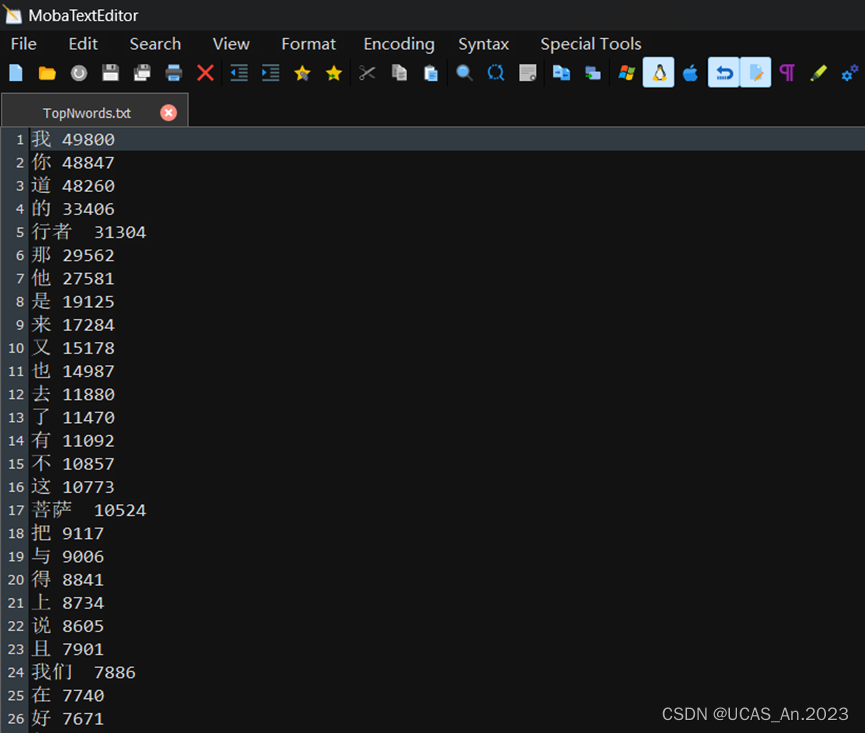
4. 逻辑优化
不知道有没有细心的网友发现,上面那种TopN实现逻辑其实是有问题的!
可以发现在TreeMap那里使用的是词频来做key,这样就会有一个问题就是:当某两个词具有相同词频的时候,会出现覆盖的情况!
为了解决这个问题,可以在topWords(TreeMap的一个实例)中使用一个自定义的对象(WordFrequencyPair)作为键,该对象同时包含词频和词语。这样,当词频相同的时候,不同的词语可以作为唯一的区分标识,防止发生数据覆盖。
然后,在Reducer中将TreeMap<Integer, String>更改为TreeMap<WordFrequencyPair, Integer>;同时,修改cleanup()方法中的代码:
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Map.Entry<WordFrequencyPair, Integer> entry : topWords.descendingMap().entrySet()) {
WordFrequencyPair pair = entry.getKey();
int frequency = entry.getValue();
context.write(new Text(pair.getWord()), new IntWritable(frequency));
}
}
此时完整的Reducer类为:
package TopNWordCount;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TopNReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private TreeMap<WordFrequencyPair, Integer> topWords;
private int count;
@Override
protected void setup(Context context) {
topWords = new TreeMap<>();
count = 0;
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) {
int frequency = 0;
for (IntWritable value : values) {
frequency += value.get();
}
//top50
//这样,即使在词频相同的情况下,通过词语作为区分标识,也能正确保存所有词频前50的词语及其词频。
WordFrequencyPair pair = new WordFrequencyPair(frequency, key.toString());
topWords.put(pair, frequency);
if (topWords.size() > 50) {
topWords.remove(topWords.firstKey());
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
for (Map.Entry<WordFrequencyPair, Integer> entry : topWords.descendingMap().entrySet()) {
WordFrequencyPair pair = entry.getKey();
int frequency = entry.getValue();
context.write(new Text(pair.getWord()), new IntWritable(frequency));
}
}
}
附上自定义对象(WordFrequencyPair)的代码:
package TopNWordCount;
import java.util.Objects;
// 自定义辅助类,用于保存词频和词语
public class WordFrequencyPair implements Comparable<WordFrequencyPair> {
private final int frequency;
private final String word;
public WordFrequencyPair(int frequency, String word) {
this.frequency = frequency;
this.word = word;
}
public int getFrequency() {
return frequency;
}
public String getWord() {
return word;
}
// 注意,在该实现中,比较和哈希计算方法均考虑了词频和词语。这样可以确保在构建TreeMap时,不会出现数据覆盖的问题。
@Override
public int compareTo(WordFrequencyPair other) {
if (this.frequency != other.frequency) {
return this.frequency - other.frequency;
} else {
return this.word.compareTo(other.word);
}
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null || getClass() != obj.getClass()) {
return false;
}
WordFrequencyPair other = (WordFrequencyPair) obj;
return frequency == other.frequency && Objects.equals(word, other.word);
}
@Override
public int hashCode() {
return Objects.hash(frequency, word);
}
}
然后重新打包项目成jar包,上传到hdfs运行测试,运行正常,问题解决!
5. 实现TopN的另外方法(简单)
其实没必要用上面那么复杂的方法来实现TopN,我们只需要在reduce阶段将计数好的<词:词频>,放到一个Hashmap里,然后对其value排序即可,最后初始化一个count变量计数,用一个for循环来将TopN的数据用context.write()方法写入到输出文本中。
主要变化:
在reduce()中将
//top50
topWords.put(frequency, key.toString());
if (topWords.size() > 50) {
topWords.remove(topWords.firstKey());
}
改为rawMap.put(key.toString(),sum);
然后cleanup()函数:
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// 遍历前50个元素
// 将 HashMap 转换为 List
List<Map.Entry<String, Integer>> entryList = new ArrayList<>(rawMap.entrySet());
// 使用 Collections.sort 对 List 进行排序
Collections.sort(entryList, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> entry1, Map.Entry<String, Integer> entry2) {
// 降序排序
return entry2.getValue().compareTo(entry1.getValue());
}
});
// 创建一个新的 LinkedHashMap 来存储排序后的结果
LinkedHashMap<String, Integer> sortedMap = new LinkedHashMap<>();
for (Map.Entry<String, Integer> entry : entryList) {
sortedMap.put(entry.getKey(), entry.getValue());
}
// 遍历保存前50个元素
int count = 0;
for (Map.Entry<String, Integer> entry : sortedMap.entrySet()) {
if (count < 50) {
context.write(new Text(entry.getKey()), new IntWritable(entry.getValue()));
count++;
} else {
break;
}
}
}
其余内容不变,即可实现。
6. 遇到的问题
1、项目jar包最初由maven构建生成,但是在hdfs上跑的时候报错:java.lang.ClassNotFoundException: org.wltea.analyzer.core.IKSegmenter,但是明明已经在pom.xml里添加进去依赖了!鼓捣了好久不行,最后放弃了maven,去官网上把jar包下了下来,加到了jdk的jar包里,然后添加工件构建jar包,然后测试成功运行。
2、乱码问题
老师网站上提供的xiyouji.txt是ANSI(GB2312),我使用Reader read = new InputStreamReader(ip, "GB2312");方式解析文件但还是有乱码,于是我把xiyouji.txt文件编码格式转成了UTF-8的格式,然后用Reader read = new InputStreamReader(ip, StandardCharsets.UTF_8);进行解析,最后成功解决乱码问题。
18点50分 2023年12月4日
有什么错误或者大家不理解的地方,欢迎评论留言交流!
学习如逆水行舟,不进则退!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)