clip安装使用教程(24-7-11更新,包括虚拟环境下的安装和使用)
注:刚开始直接运行代码报错,Can't load tokenizer for 'openai/clip-vit-base-patch32'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name
1.配置环境 安装依赖
pip install transformers
pip install torch看缺失什么包自己先安装好
2.安装clip
进入https://github.com/openai/CLIP,先将CLIP文件夹下载到本地,随便什么位置。即点击下图中的Download ZIP,下载到本地后进行解压,即得到文件夹CLIP-main,保存位置没有讲究。
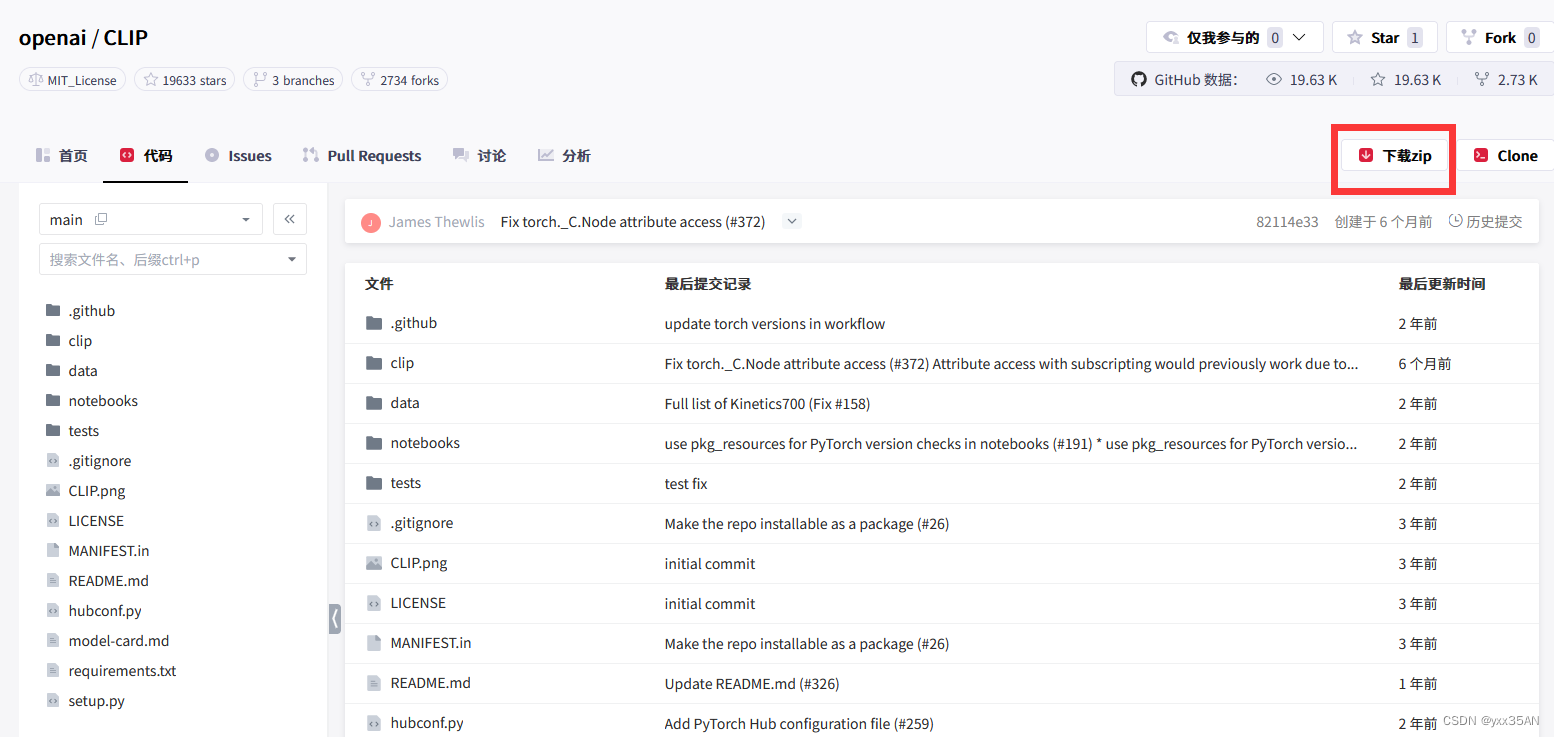
最后在cmd下切换到你保存上述文件夹的位置,cd进入文件夹CLIP-main,然后输入
python install .注:使用python setup.py install 会报错 ....setup.py install is deprecated....
注:如果你的代码在虚拟环境下的话,就必须在虚拟环境下安装clip
虚拟环境下安装clip的具体步骤:打开Anaconda,激活虚拟环境,在虚拟环境下进入文件夹CLIP-main,然后再输入pip install .进行clip包的安装。
![]()
注:本来是想clone下来,但报错error:subprocess-exited-with-error,采用以上方法解决
接着进入https://huggingface.co/models,选择自己要用的模型,我这里用的是clip-vit-base-patch32
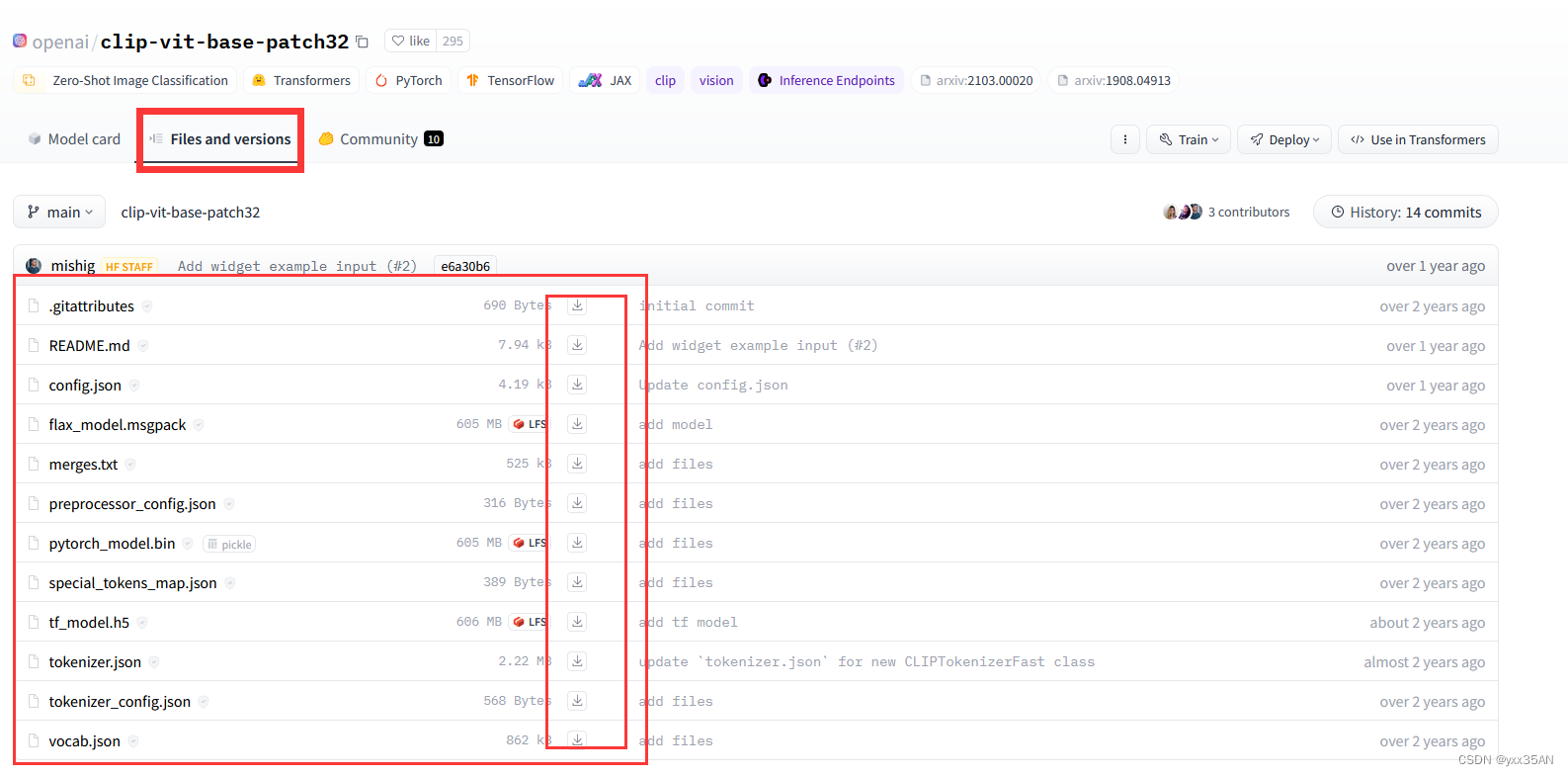
下载这些文件,将它们放在你手动创建的openai/clip-vit-base-patch32文件夹中
注:刚开始直接运行代码报错,Can't load tokenizer for 'openai/clip-vit-base-patch32'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. 依靠上述方法解决,类似的报错都可以依靠上述方法解决,直接下载本地文件然后放入对应的文件夹就行
3.运行代码
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("temp.jpg")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) ![]()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)