如何利用AnythingLLM部署在线硅基流动的DeepSeek满血版API
是一款开源的全栈应用程序,旨在帮助用户构建基于检索增强生成(RAG)技术的私有知识库。通过将本地的 PDF、Word 文档、文本文件等嵌入到本地向量库,并连接大型语言模型(LLM),用户可以通过对话或搜索的方式获取答案、见解,甚至生成摘要。通过AnythingLLM,可以方便的构建自己的知识库,不用再手动上传文档到模型中了。2025年02月14日 09:27。
浅木先生
2025年02月14日 09:27
AnythingLLM 是一款开源的全栈应用程序,旨在帮助用户构建基于检索增强生成(RAG)技术的私有知识库。通过将本地的 PDF、Word 文档、文本文件等嵌入到本地向量库,并连接大型语言模型(LLM),用户可以通过对话或搜索的方式获取答案、见解,甚至生成摘要。
通过AnythingLLM,可以方便的构建自己的知识库,不用再手动上传文档到模型中了。
但是需要注意,上传文件的内容是否涉密,如果涉密,请勿上传。
下载 AnythingLLM
https://anythingllm.com/desktop
教程如下:
1、注册SILICONFLOW并获取API
首先注册(硅基流动):
https://cloud.siliconflow.cn/i/24s1PqPc
然后打开API页面,新建一个API密钥:

2、在AnythingLLM中添加DeepSeekAPI
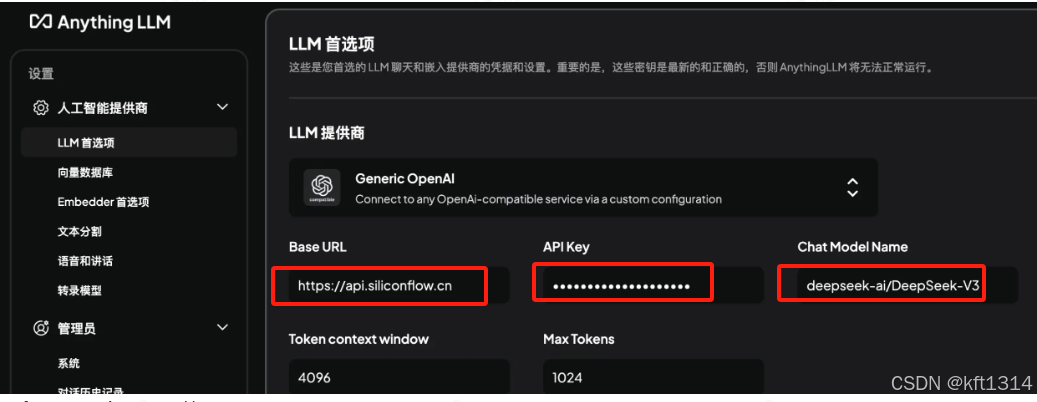
打开AnythingLLM的设置,找到LLM首选项,在LLM提供商处找到“Generic OpenAI”,然后按照下面的配置进行填写:
解释一下两个重要参数:
1). Token Context Window(上下文窗口大小)
定义:指的是模型一次能够处理的 最大输入 token 数量(包括问题和上下文)。
作用:决定模型能“记住”多少内容,在 RAG(检索增强生成)应用中,context window 限制了检索后能提供给模型的上下文信息。
2). Max Tokens(最大生成 token 数量)
定义:控制模型 最大可以输出的 token 数量。
作用:影响回答的长度,防止生成过长的内容导致超时或消耗过多算力。这里的chat Model Name可以在上面的硅基流动的模型广场中找到:Models
推荐一个比较NB的ai工具,好不好用试过的不言而喻
https://ai.rcouyi.com/auth/register?inviteCode=W1PXYCM4J

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)