unsloth报错RuntimeError: ptxas failed with error code 4294967295:
unsloth报错RuntimeError: ptxas failed with error code 4294967295:
·
运行环境
- 平台:Windows
- CUDA版本:12.6
报错信息
由于是先修复BUG后才发布的文章,所以BUG显得有点乱,将就着看吧哈哈
- main.c 正在创建库 main.lib 和对象 main.exp ptxas C:\Users\winds\AppData\Local\Temp\tmpy90b496m.ptx, line 5; fatal : Unsupported .version 8.6; current version is '8.5' ptxas fatal : Ptx assembly aborted due to errors Traceback (most recent call last): File "C:\Python312\Lib\site-packages\triton\backends\nvidia\compiler.py", line 295, in make_cubin subprocess.run(ptxas_cmd, check=True, close_fds=False, stderr=flog) File "C:\Python312\Lib\subprocess.py", line 571, in run raise CalledProcessError(retcode, process.args, subprocess.CalledProcessError: Command '['C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin\ptxas.exe', '-lineinfo', '-v', '--gpu-name=sm_86', 'C:\Users\winds\AppData\Local\Temp\tmpy90b496m.ptx', '-o', 'C:\Users\winds\AppData\Local\Temp\tmpy90b496m.ptx.o']' returned non-zero exit status 4294967295. During handling of the above exception, another exception occurred: Traceback (most recent call last): File "C:\Python312\Lib\site-packages\IPython\core\interactiveshell.py", line 3577, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-2-c22759990ddf>", line 1, in <module> runfile('D:\python_projects\deepseekProject\src\distill.py', wdir='D:\python_projects\deepseekProject\src') File "C:\Program Files\JetBrains\PyCharm 2024.1.1\plugins\python\helpers\pydev_pydev_bundle\pydev_umd.py", line 197, in runfile pydev_imports.execfile(filename, global_vars, local_vars) # execute the script ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Program Files\JetBrains\PyCharm 2024.1.1\plugins\python\helpers\pydev_pydev_imps_pydev_execfile.py", line 18, in execfile exec(compile(contents+"\n", file, 'exec'), glob, loc) File "D:\python_projects\deepseekProject\src\distill.py", line 47, in <module> input_ids=inputs.input_ids, ^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\utils_contextlib.py", line 116, in decorate_context return func(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\models\llama.py", line 1596, in _fast_generate output = generate(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\utils_contextlib.py", line 116, in decorate_context return func(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\transformers\generation\utils.py", line 2215, in generate result = self._sample( ^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\transformers\generation\utils.py", line 3206, in _sample outputs = self(**model_inputs, return_dict=True) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1739, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1750, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\accelerate\hooks.py", line 170, in new_forward output = module._old_forward(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\models\llama.py", line 1061, in _CausalLM_fast_forward outputs = self.model( ^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1739, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1750, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\accelerate\hooks.py", line 170, in new_forward output = module._old_forward(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\models\llama.py", line 885, in LlamaModel_fast_forward layer_outputs = decoder_layer( ^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1739, in _wrapped_call_impl return self._call_impl(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\nn\modules\module.py", line 1750, in _call_impl return forward_call(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\accelerate\hooks.py", line 170, in new_forward output = module._old_forward(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\models\llama.py", line 531, in LlamaDecoderLayer_fast_forward hidden_states = fast_rms_layernorm(self.input_layernorm, hidden_states) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch_dynamo\eval_frame.py", line 745, in _fn return fn(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\kernels\rms_layernorm.py", line 210, in fast_rms_layernorm out = Fast_RMS_Layernorm.apply(X, W, eps, gemma) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\torch\autograd\function.py", line 575, in apply return super().apply(*args, **kwargs) # type: ignore[misc] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\unsloth\kernels\rms_layernorm.py", line 156, in forward fx[(n_rows,)]( File "C:\Python312\Lib\site-packages\triton\runtime\jit.py", line 345, in <lambda> return lambda *args, **kwargs: self.run(grid=grid, warmup=False, *args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\triton\runtime\jit.py", line 662, in run kernel = self.compile( ^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\triton\compiler\compiler.py", line 286, in compile next_module = compile_ir(module, metadata) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\triton\backends\nvidia\compiler.py", line 329, in <lambda> stages["cubin"] = lambda src, metadata: self.make_cubin(src, metadata, options, self.capability) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\Python312\Lib\site-packages\triton\backends\nvidia\compiler.py", line 309, in make_cubin raise RuntimeError(f'ptxas failed with error code {e.returncode}: \n{log}') RuntimeError: ptxas failed with error code 4294967295:
报错原因
- 从错误信息来看,问题出在 ptxas 编译器不支持 .version 8.6,而当前版本为 8.5。这通常是因为 CUDA 工具链和 GPU 架构之间的版本不匹配导致的。
解决方法
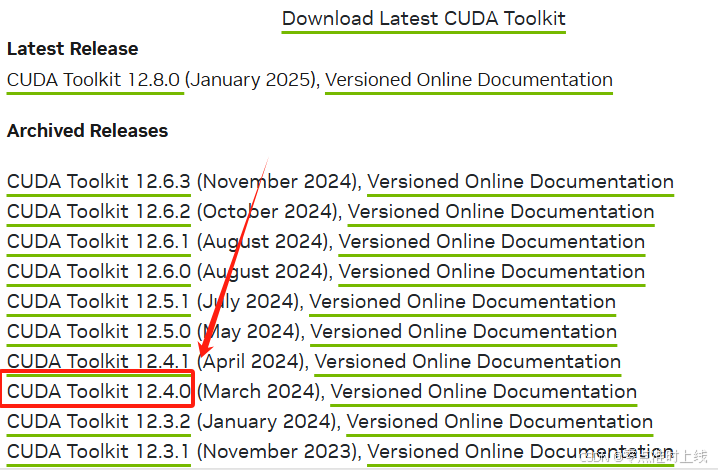
- 降级 CUDA (本文从 12.6 降至 12.4 )
这里强烈推荐 12.4 版本的CUDA,原因如下:
超过 12.4 会出现编译错误,也就是本文章的BUG。
低于 12.4 会导致加速不够快(警告如下),因为unsloth源码用到xFormers库,xFormers需要用到一些加速策略。
-

-
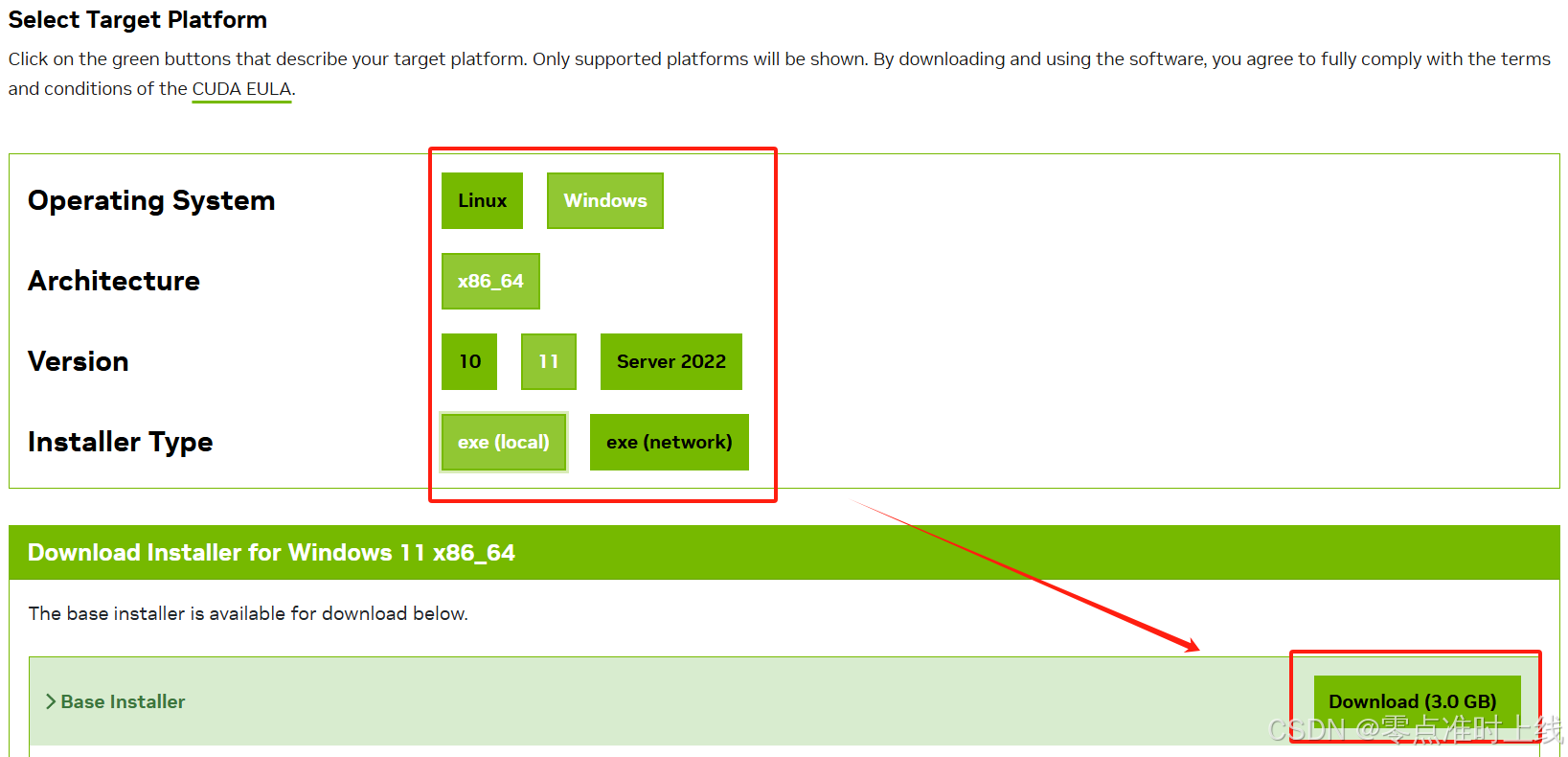
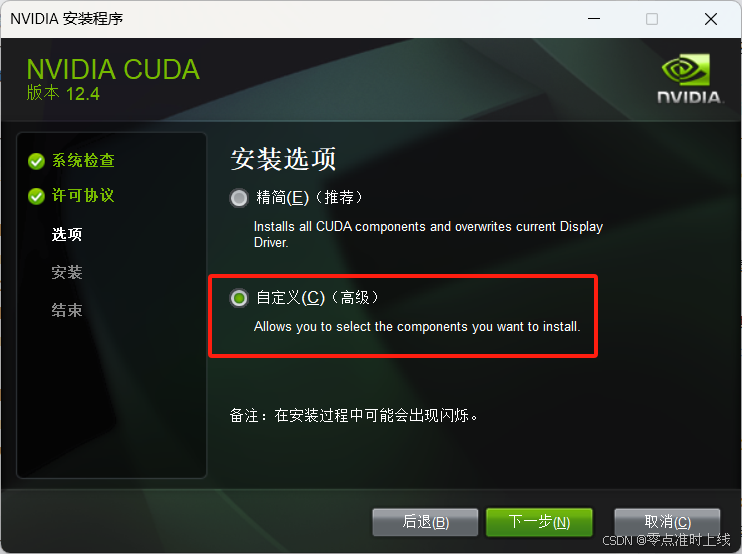
选择对应的版本,下载并安装(安装时选择自定义安装,其他默认)
-
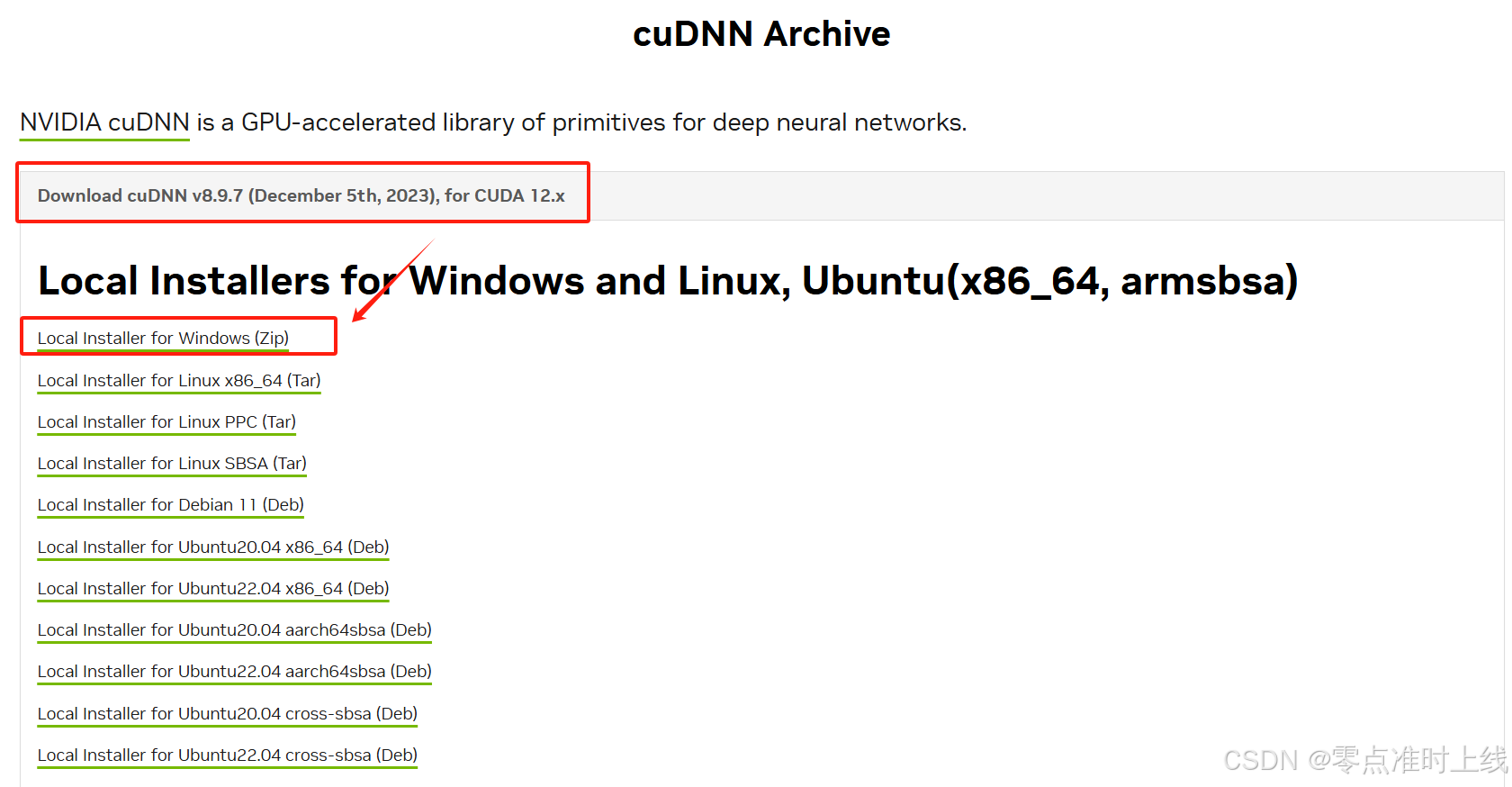
选择对应的版本,下载解压并替换至 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4
-
选择对应的版本,复制命令至本地终端运行(install前最好先uninstall之前的版本)
-
pip3 uninstall torch torchvision torchaudio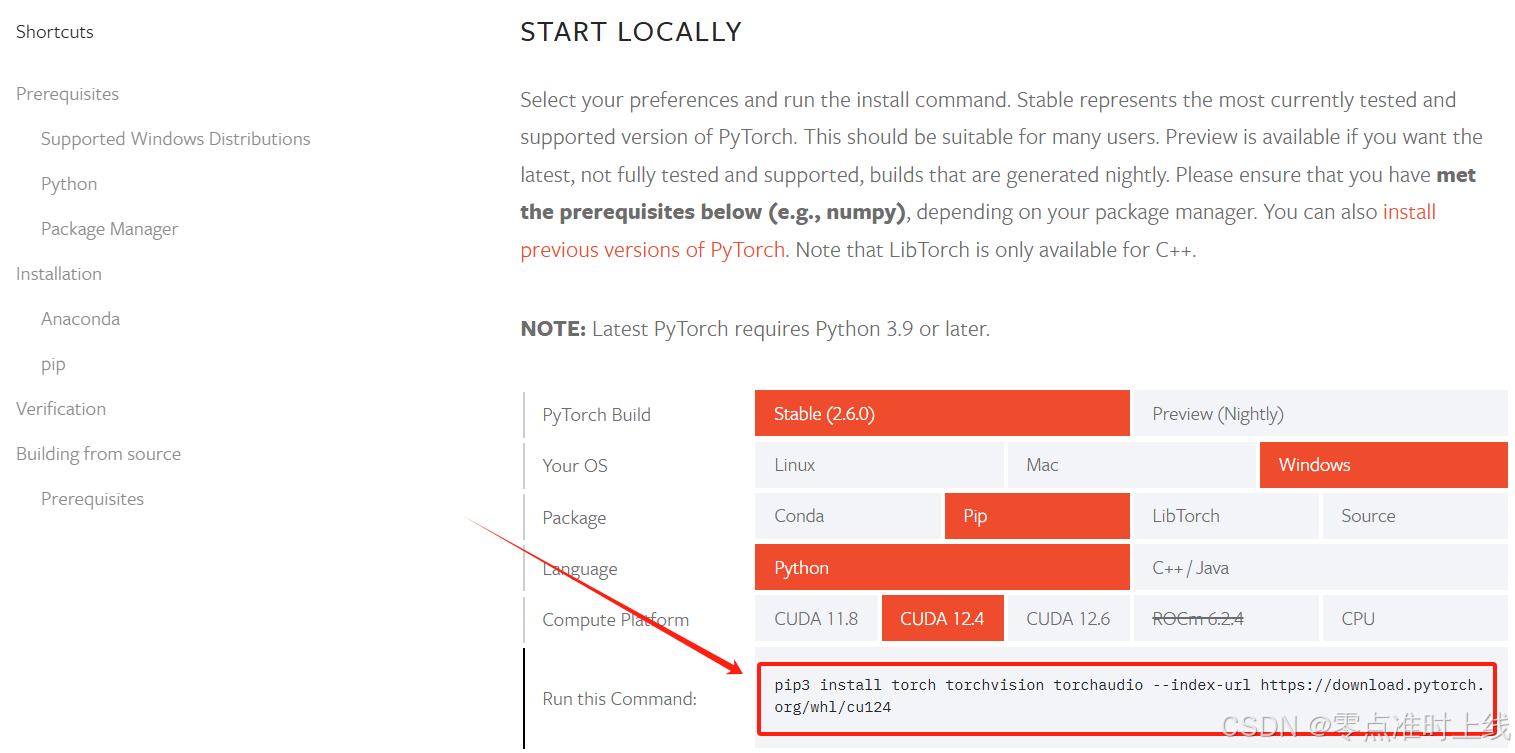
-
重启电脑

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)