EAGLE框架:投机解码需要重思考特征的不确定性
这篇代码开源!
在DeepSeek-V3中,训练过程加入了多token预测这一目标(让每个头预测出来的token尽可能接近真实情况),但实际上每个token是顺序预测的,在所有预测深度都保留了完整的因果链,推理阶段甚至直接舍弃那些MTP模块,它们存在的意义只是为了在训练时提升主模型的性能!
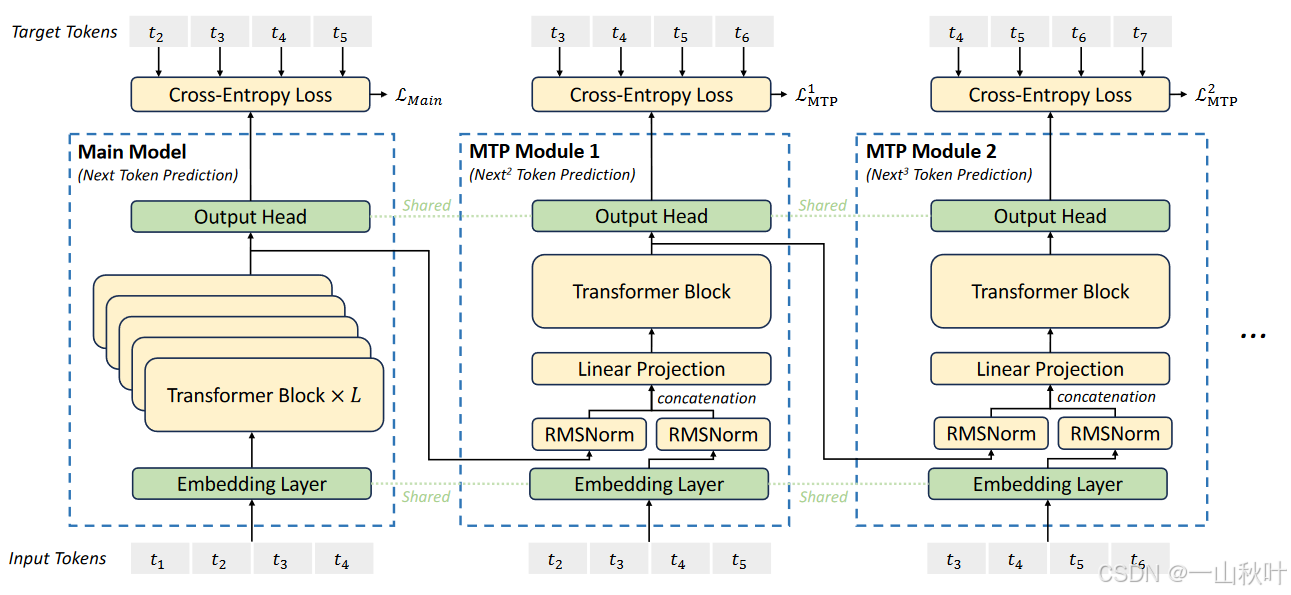
为什么MTP这个训练目标可以改善主模型?能不能将MTP模块也用于投机解码以减少推理延迟?技术报告中提到了这篇原理相同,用途不同的论文,俺又来了😭代码链接:Github;论文链接:EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
投机解码
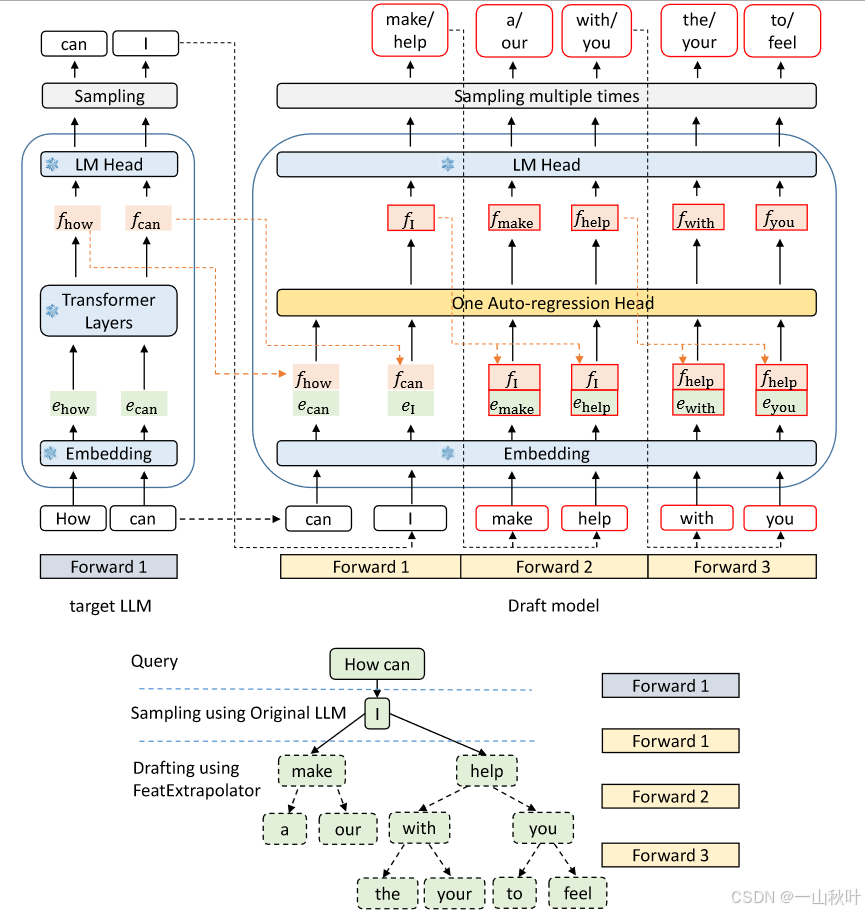
采用原始的token级自回归解码流程如下:输入序列由个个token组成,token经过嵌入层转化成嵌入向量,模型提炼出其中特征,语言模型头据特征输出概率分布,最后采样出下一个token,即针对每次迭代,有
。但自回归式推理过程很耗时,作者想换成投机解码。投机解码将解码过程分为低开销的“打草稿”阶段和在草稿token上做并行验证的阶段,在一个LLM pass产生多个token,加速生成,另外还能保证文本分布和单用LLM产生的解码结果精准对齐。
应用投机解码的关键在于找一个和LLM功能相近的低开销草稿模型,比如在LLaMA2系列模型中,7B的模型就可以给70B模型打草稿,但找个给7B模型打草稿的就棘手了,一个替代方案是用TinyLLaMA,但是LLaMA2-Chat和TinyLLaMA-Chat的指令模板不一样,没办法指令调优。另外用7B模型打草稿这事也不靠谱,将草稿长度从2设到10,测量各情况下的最高加速率【声明:即挂钟时间加速率,相较于原始自回归解码的现实加速率,是全文的一个重要指标】,都因为其高开销而带来不了多少加速增益——对13B模型就没有改善,对33B模型和70B模型的加速比分别是1.12x和1.88x。专门训练一个新的大小合适的草稿模型也不是最理想的方案,TinyLLaMA训练起来要3000B token,相比于只要2-4B token的EAGLE而言训练成本太高。
什么是指令调优?
一种用于优化LLM理解和执行指令能力的技术。其核心思想是在模型的预训练或微调阶段,提供大量高质量的指令-响应(instruction-response)训练数据,使模型能够更好地理解自然语言指令,并以符合人类期望的方式回答问题或执行任务。主要方法有以下几种:
1. 监督微调(SFT):使用标注好的指令-响应数据微调模型
2. 生成式数据增强(Self-Instruct):通过已有大模型生成高质量的合成数据,减少对人工标注的依赖
3. 通过人类偏好强化学习(RLHF)优化:训练一个奖励模型(reward model),让人类对不同的回答进行评分。采用近端策略优化(PPO)算法,使模型生成的回答更符合人类偏好,直接给出答案V.S详细解释?口语化V.S正式表达?事实性v.s主观性?
4. 多任务学习(MTL):让模型在不同类型的指令数据上进行训练,使其能够处理更广泛的任务,而非局限于单一类型的问题。
指令调优的核心目标就是让模型更好地完成指令追随任务,这种任务通常涉及多个领域,如问答、文本摘要、翻译、代码生成、推理、多轮对话,任务的共同点是用户提供一个指令,模型需按照指令去完成任务。
(LLM的幻觉hallucination指的是模型生成的内容在事实层面上是错的或凭空捏造的)
前文中提到的指令模板,指的是LLM处理prompt的方式,比如问题和回答之间的格式(User:和Assistant:)、特殊的控制token(<<SYS>>、###)、prompt的组织结构。TinyLLaMA和LLaMA2 7B使用不同的指令模板的话,小模型的草稿可能不符合大模型的输入习惯从而大量草稿被拒,同时小模型模拟大模型输出时可能引入额外误差(指令调优本质上无法解决模型结果和风格的根本差异)。
什么是PPO?
(强化学习也是一个巨坑இ௰இ)RLHF的核心算法。由OpenAI在2017年提出,广泛用于机器人控制、游戏AI、自然语言处理等领域。PPO是策略梯度(Policy Gradient)的改进版本,属于基于策略(On-Policy)的强化学习算法,其核心目标是在优化策略时,通过限制新旧策略的变化幅度,提高训练的稳定性和样本效率。主要采用两种策略更新方法:1.PPO-Clip(常见),限制新旧策略的比值在一定范围内;2.PPO-KL(不常见),使用KL散度作为正则项,控制策略更新的步幅。具体工作原理如下:
强化学习的目标是找到一个策略使得累积奖励最大化。传统的策略梯度方法(如REINFORCE)使用梯度优化公式:,其中策略
表示在状态s下采取动作a的概率,优势函数
用于衡量当前动作相对于平均水平的好坏,
表示对策略参数
进行梯度优化。
但这样容易导致策略更新过快,训练不稳定,模型性能下降,为了解决这个问题,PPO引入策略比值和裁剪机制,核心目标函数为
其中策略比值用于衡量新策略
相较于旧策略
的变化程度。最小值操作的作用就在于,若策略更新方向是正确的,即
处于合理范围内,则进行更新,若策略更新过度,即偏离
(超参数
通常设为0.2),则裁剪更新幅度,防止训练不稳定。超参数敏感,仍有一定的策略发散风险。
TRPO(Trust Region Policy Optimization)收敛稳定,理论保证好,但计算复杂,优化困难。相较于它,PPO允许多个epoch进行更新,提高样本效率,只需一阶梯度下降,计算量小。
也有其他打草稿的方式,如Lookahead和Medusa,这些方法专注于减少草稿阶段的开销,但它们的有效性受限于草稿的低准确度。Medusa的准确度为0.6,Lookahead更低,而EAGLE能将近0.8。除了训练开销小、性能好,EAGLE还有其他优势:
1. 通用性,EAGLE原则上适用于任何自回归LLM。遵循零样本或小样本学习设置,所有实验用一样的基于ShareGPT数据集训练得到的模型权重,未针对特定的评估数据集进行额外的训练或微调。仅需添加一个轻量级的插件,即一个单独的transformer解码层,模型部署简单高效。
2. 可靠性,EAGLE不对原始模型做任何微调,理论上在采取贪心策略与否这两种设置下,EAGLE都能保持输出分布,这和Lookahead或Medusa形成鲜明对比,前者只专注于贪心策略,后者在非贪心设置下不能保证输出分布。
两个观察
1.在特征维度比在token维度做自回归更简单有效。【声明:在这篇论文中,“特征”专指原始LLM中第二层到顶层的特征表示(第一层是输入层),位于语言模型头之前】相较于由自然语言直接转化而来的token序列,特征序列蕴含更多规律。下图是在基于token、特征、特征-移位后token混合(特征序列+将原始token序列向前移动一个时间步后得到的token序列)的不同情况下,草稿模型分别得到的准确度和加速率变化情况,实验设置是温度为0、基准数据集是MT-bench、原始LLM是Vicuna 7B,从结果可见自回归特征预测确实会有更好的性能、更高的加速率。
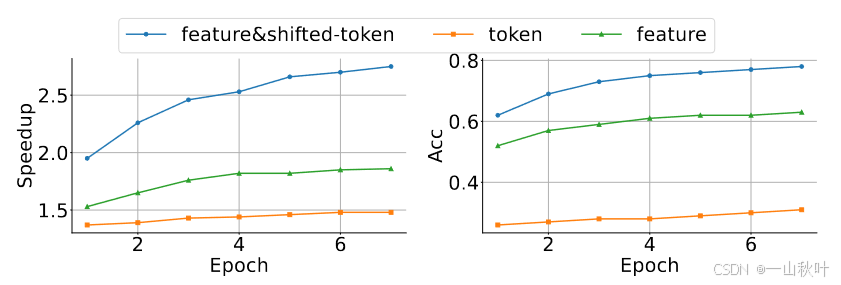
2. 特征序列中固有的不确定性显著限制了下一特征的预测性能。在文本生成任务中,目标LLM【声明:“目标LLM”专指希望能提速的LLM】会预测token的分布,并据此进行采样,存在随机性。而特征高维且连续,特征级模型在处理这些不确定性时,无法像token级那样简单地进行选择。如下图,紧随之后的下一个特征受到潜在的多种输出的影响,而非单由
决定,“always”和“am”都有可能是“I”的下一个token,便会造就两条不同的特征序列,预测过程更加复杂。
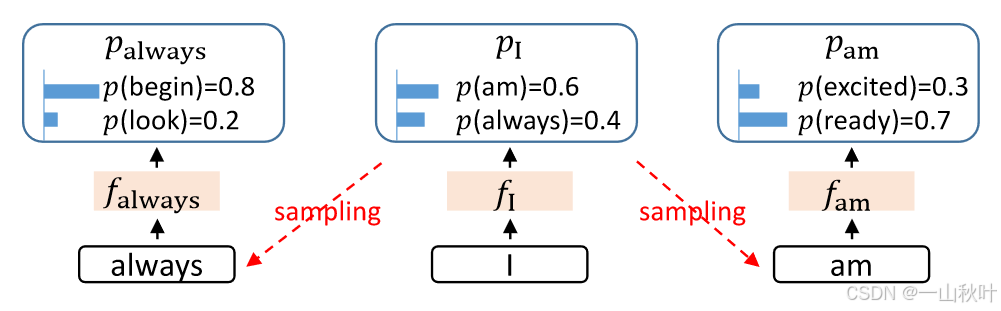
Medusa在预测间隔的token时也不确定输入的真正目标是
还是
。为了解决这个问题,EAGLE将token序列提前一个时间步,一并作为草稿模型输入,其中也就包含了采样结果。还是以上图为例,基于
和
预测
,基于
和
预测
。解决不确定性后,图3中加速比可进步从1.9x提升到2.8x。
草稿模型的架构
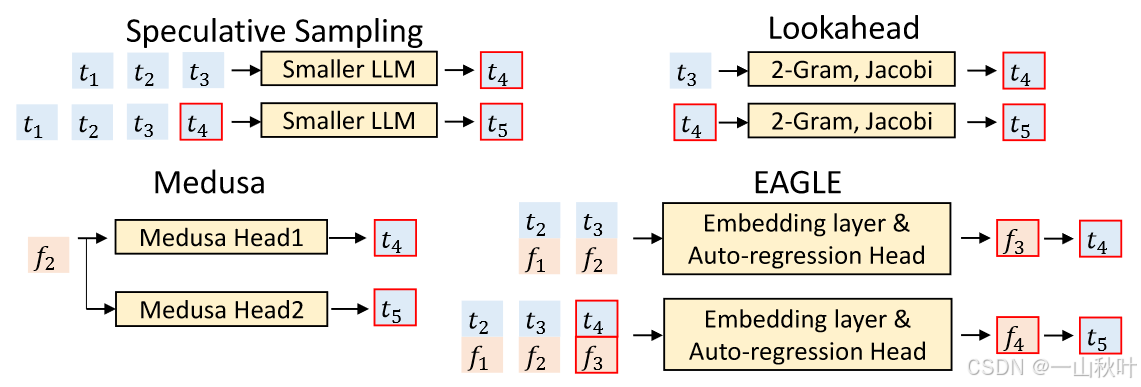
EAGLE和其他投机解码方法最大的不同就在于它打草稿的方式。下图中演示了各类方法预测、
的示意图,简单起见,Lookahead直接设为2-gram,原始投机解码和Lookahead都是基于token进行顺序预测,Medusa基于目标LLM提炼出的特征
独立预测出
和
,EAGLE则是利用特征序列和前移token序列预测下一特征,从概率分布采样出下一token。
如下图所示,EAGLE的草稿模型主要由3个模块组成:嵌入层、LM头、自回归头。其中嵌入头和LM头采用目标LLM的参数,无需额外训练。草稿模型将形为(bs, seq_len,hidden_dim)的特征序列和形为(bs, seq_len)的前递token序列一并作为输入,将token序列转换为和特征序列同形状的嵌入向量序列后,把嵌入向量序列和特征序列拼接成形为(bs, seq_len,2xhidden_dim)的序列。自回归头由一个全连接层和一个解码层组成,FC层会将拼接序列的维度减到(bs, seq_len,hidden_dim),再由解码层预测下一特征,LM头会基于特征计算分布,再从中采样出下一token,最后预测的特征和采样的token被一起拼到输入序列上,延续后面的自回归过程。
EAGLE采用树形注意力机制构建树状草稿,m步前向过后,树深m,产生超m个token,如上图3步后已打出10个草稿token。在贪心设定下,选取具有最高概率的k个token作为子节点,在非贪心设定下则随机采样出k个token。真实部署中为何要采用下图这样一个树形架构呢?作者表示无法证明这是严格最优的,但满足直觉:概率较高的token应该有更宽更深的分支。
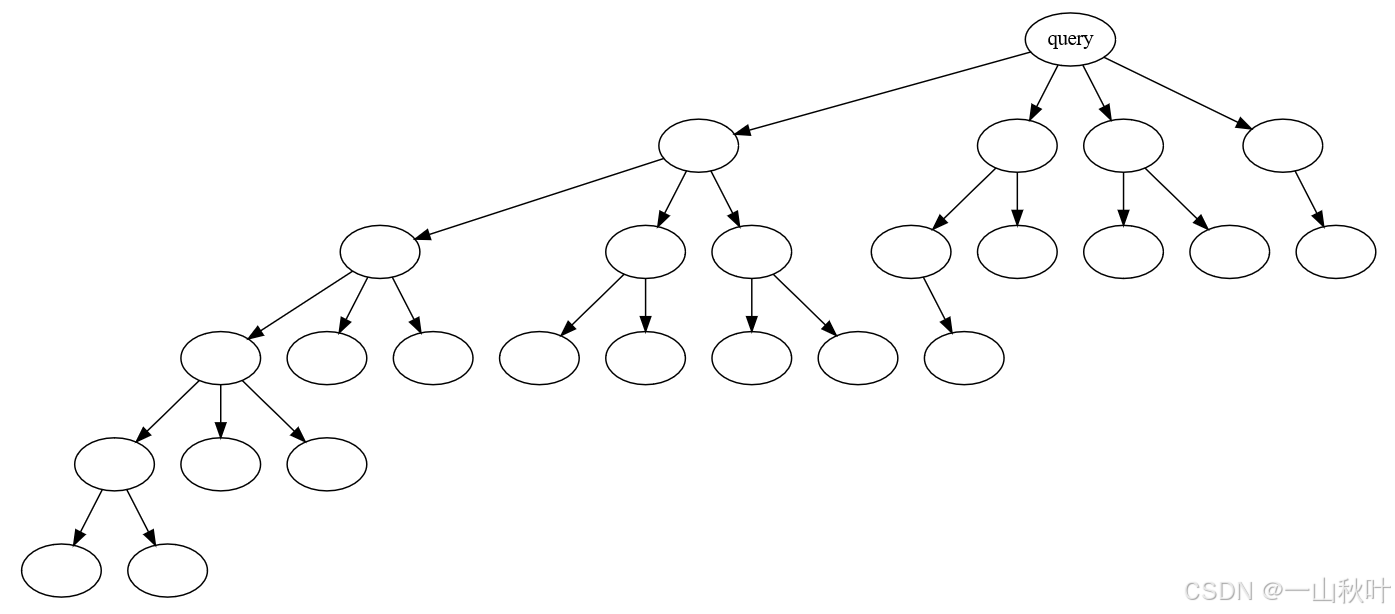
最优树结构很有可能也与情境相关,批量大小增大、冗余计算资源减少时,较小的树会更合适。对草稿结构的调整可能会带来更好的性能。
草稿模型的训练
针对特征预测这个回归问题,作者采用光滑L1损失:
什么是Smooth L1 loss?
一种结合了L1损失(绝对误差)和L2损失(平方损失)特性的损失函数,能有效平衡对异常值的鲁棒性和对小误差的敏感性,数学表达式如下:
在小误差范围内采用L2损失,在解决零的区域更平滑,有助于优化过程的稳定性,大误差范围内改L1损失,对异常值更鲁棒,超参数也能影响损失函数的形为。常用于回归任务,尤其是数据中可能存在异常值的情况,如目标检测、图像重建等。
预测特征只是草稿模型的一个辅助目标,终极目标是预测token,故又利用分类损失进行优化:
两相结合形成损失函数。一般分类损失在数值上会比回归损失大一个数量级,故设
为0.1。
验证阶段
和链状的草稿结构不同,树状草稿有必要调整采样策略。类似于下列论文:SpecInfer: Accelerating generative LLM serving with speculative inference and token tree verification.
随机采样过程可以简单描述成算法A:如果一个token被接受,就返回它,否则会从一个调整后的分布中重新采样。可以先回顾一下投机解码中能保证输出分布的拒绝采样策略:用一个小模型产生个token
以及对应的概率
,验证阶段,目标LLM在一个前向周期内产生
,据此顺序对token进行评估:针对token
,被接受的概率是
,一旦被拒绝,后续token就都会被丢弃,然后这个token从分布范数
中重采样,其中
是一种得到归一化的非负值分布的运算,有
。
而树状草稿,通过目标LLM单次前向传递计算每个token的概率后,针对有k个候选token,多轮投机采样会递归地调用算法A,直到所有的token都被拒绝后,才会直接返回重采样的结果,伪代码如下:

性能表现
实验设置
作者做了大量实验测试性能,任务有多轮对话、代码生成、数学推理、指令跟随,分别采用基准数据集MT-bench、HumanEval、GSM8K、Alpaca,被测试的LLM包括Vicuna(7B 13B 33B)和LLaMA2-Chat(7B 13B 70B)系列的所有模型,还有Mixtral 8x7B Instruct(一个基于MoE架构,专注于指令跟随任务的LLM),涵盖了主流LLM的常见大小。主体实验中批量大小设为1,其他工作也采用这样的设定,例如DistillSpec:Improving Speculative Decoding via Knowledge Distillation、Speculative Decoding with Big Little Decoder。评估专注于延迟而非吞吐量,用以下指标来衡量加速效应:挂钟时间加速率、 平均接收长度【声明:目标LLM每轮前向时接收的平均token数】、接受率
【声明:打草稿期间接收的token数和生成的token数之比,用来衡量草稿的准确性,这对于树状草稿适用性较低,因为每个位置会采样多个token,但只会接受一个,故在测量这个指标时,作者会改用链状草稿,和投机解码、DistillSpec对齐。在测量接受率时,考虑到草稿模型预测的n个特征可能存在不准确性,接受率被定义为
】
4. EAGLE的加速理论上会保持目标LLM的输出分布,故无需评估其生成结果的质量。
在训练的过程中,固定目标LLM,训练数据集抽取ShareGPT数据集中的68000轮对话,学习率设为3e-5。采用AdamW优化器,其中设置为(0.9, 0.95),实现0.5的梯度裁剪。
7B、13B、33B和70B模型对应的EAGLE的可训练参数量分别为0.24B、0.37B、0.56B和0.99B,MoE模型Mixtral 8x7B对应的为0.28B。故EAGLE训练成本极低,在一台A100 40G服务器上,70B模型的自回归头在1-2天内就能训练完。针对7B、13B和33B模型,甚至可以在一台RTX 3090节点上画1-2天完成训练。在实际应用中,EAGLE只需要一个完整的训练周期就能对所有询问进行加速,随着询问次数上升,分摊下来的训练成本可以忽略。
Lookahead
《Breaking the sequential dependency of LLM inference using lookahead decoding》采用n-gram架构和Jacobi迭代。n-gram指在一个序列中连续出现的n个词或字符,例如在句子“我爱自然语言处理中”,1-gram(unigram)就是“我”、“爱”、“自然”、“语言”、“处理”,2-gram(bigram)就是“我爱”、“爱自然”、“自然语言”、“语言处理”,3-gram(trigram)就是“我爱自然”、“爱自然语言”、“自然语言处理”,它会统计每个n-gram在训练语料库中出现的概率来构建语言模型。(简单易懂)其构建和实现相对简单,易于理解和使用;(高效性)对于许多应用,n-gram能快速生成预测,且在小型数据集上表现良好;(上下文限制)但它只考虑有限的上下文信息,可能忽略更长范围的依赖关系;(数据稀疏)许多n-gram组合在训练数据中可能没有出现。Jacobi迭代将线性方程组中每个方程视为对未知数的更新公式,算法结构简单适用于并行计算、能有效利用矩阵稀疏性,但相较于Gauss-Seidel迭代收敛慢,初始猜测值选择不当可能收敛困难。
Medusa
《Medusa: Simple framework for accelerating LLM generation with multiple decoding heads.》(参考博客)使用一组多层感知机(即美杜莎头),基于原始模型second-to-top-layer的中间特征,进行多token预测。
什么是多层感知机(MLP)?
一种前馈神经网络,深度学习中的基础模型之一,由多个神经元层组成,通常包括以下几层:1.输入层。2.隐藏层,至少一个,每层神经元与前一层神经元全连接,每个神经元进行线性变换(加权求和),并通过非线性激活函数处理,计算可以表示为。3.输出层,针对不同任务有不同结构,
,回归任务仅一个神经元用于预测一个连续值(如房价、温度等),无激活函数或有个ReLU以确保输出非负;二分类任务一个神经元输出正类别的概率y,需要Sigmoid将y限于(0,1),y>0.5则预测为正类;多分类任务(独立类别)有多个神经元,每个神经元输出一个数值,表示每个类别的得分,Softmax归一化后转化为概率;多标签分类(每个类别独立判断)有多个神经元,每个神经元的输出独立,分别表示某个类别是否存在的概率,采用Sigmoid。
其局限性在于缺乏记忆能力,不能捕捉时间依赖关系,不适合处理时序数据;不具备局部感知能力,不适合处理处理图像等高维数据;参数多,计算量大,尤其层数多时易过拟合。
DistillSpec
一种通过知识蒸馏技术优化推测解码过程的方案,公平起见,对其采用和EAGLE一样的训练数据集。散度函数采用FKL。
什么是FKL?
Fisher-Kullback-Leibler Divergence,一种结合了Fisher信息矩阵和KL散度的度量方法,主要用于衡量概率分布之间的差异,同时考虑了分布的局部几何结构,通常表示为,详情见论文附录A.1
蒸馏的主要目的在于提高草稿模型的接受率,加速率只得到微微提升,而投机采样的性能瓶颈在于草稿模型的高开销。
EAGLE有效性
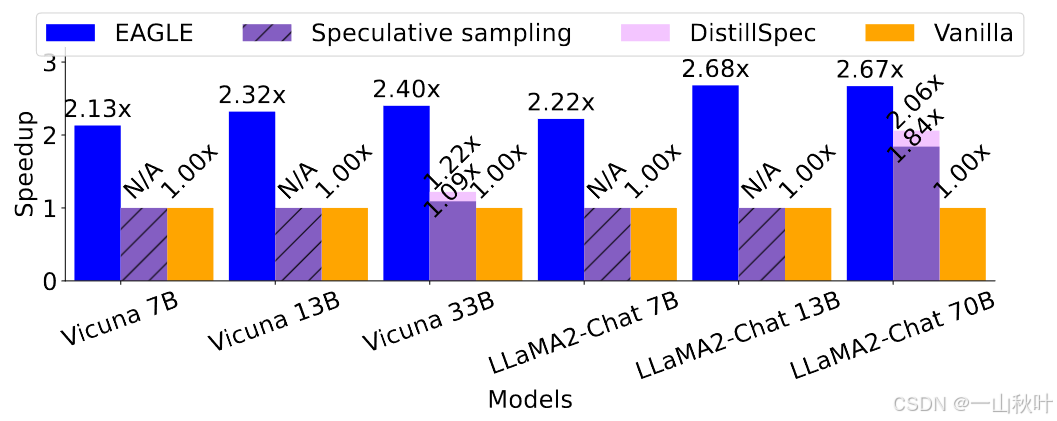
下图展示了在 MT-bench测试框架(包含类似与ChatGPT对话的多轮指令,逼近于现实场景,在前沿研究如Lookahead和Medusa中都有使用)上,采用贪心策略(temperature=0)时【声明:本文所有实验中,没特别声明的,默认这两配置】,各种策略对Vicuna和LLaMA2-Chat系列模型推理延迟的加速比。
其中Medusa和Lookahead对应的加速比是直接从它们的技术报告里粘过来的;想对7B模型采用投机采样时找不到合适的草稿模型,所以显示“N/A”;用7B模型作为13B模型的草稿模型做投机解码时,7B模型的开销太大,甚至导致比原始的自回归解码还要低效,所以也是“N/A”。这里只和基于投机解码又无需调整主干模型的方法作比较,确保输出相同的文本分布。针对LLaMA2-Chat 70B,EAGLE可以带来2.7x-3.5x的延迟加速比,翻倍的吞吐量,理论上相同的生成文本分布。
相较于Lookahead和Medusa,EAGLE还要分别再快个1.70-2.08x和1.47-1.60x。
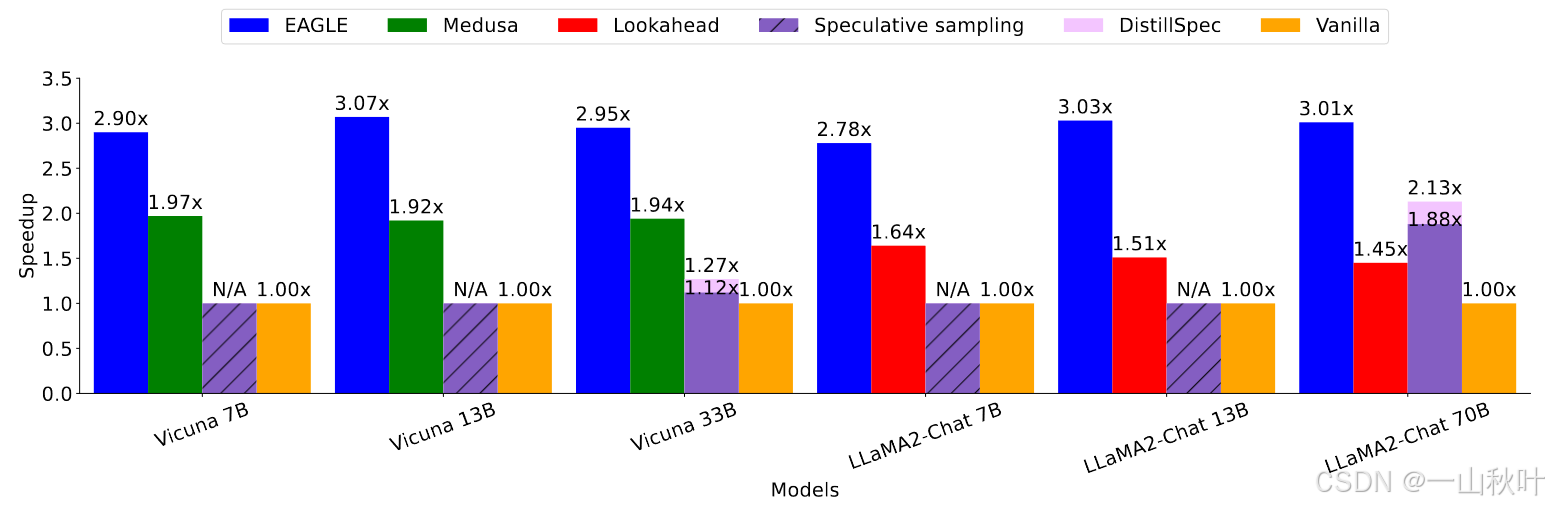
下图是在非贪心(temperature=1)设置下的比对结果,Lookahead只能设成贪心解码,Medusa在非贪心的情况下不能保证无损性能,所以不拿来和EAGLE比较。
下表是在HumanEval、GSM8K、Alpaca基准下加速率和平均接收长度的测试结果,其中T表示温度,V表示Vicuna系列模型,LC表示LLaMA2-Chat系列模型。相较于1,温度为0时EAGLE的表现会更好,例如针对模型LLaMA2-Chat 13B,在温度为0时,加速率在3.01-3.76x,而在温度为1时,只有2.66-2.89x了。在代码生成任务上(HumanEval),EAGLE取得最好的加速性能,这归因于代码中普遍存在固定模板,为这些模板打草稿就容易些。
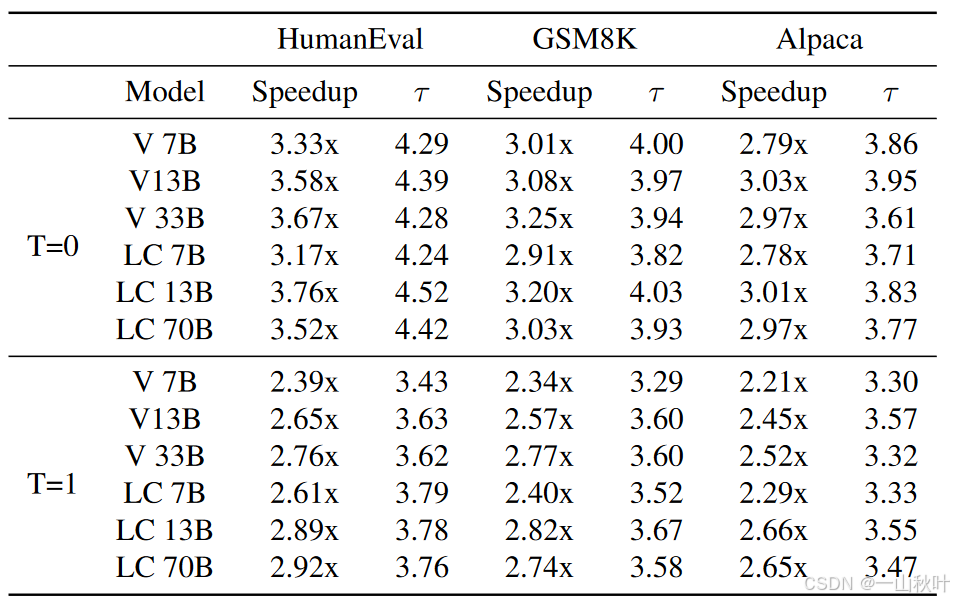
下表是在MT-bench基准下平均接受长度和接受率的测试结果
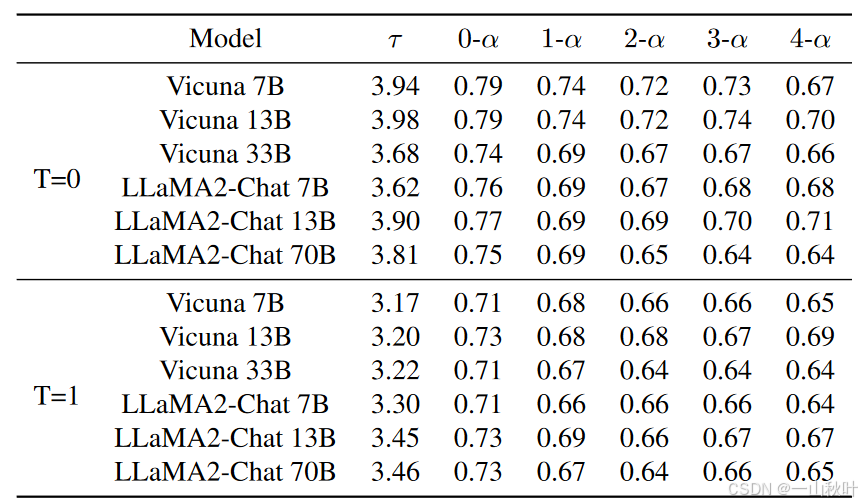
下表是温度设为0时,在其他3个基准下,对加速率、平均接受长度、接受率的测试结果
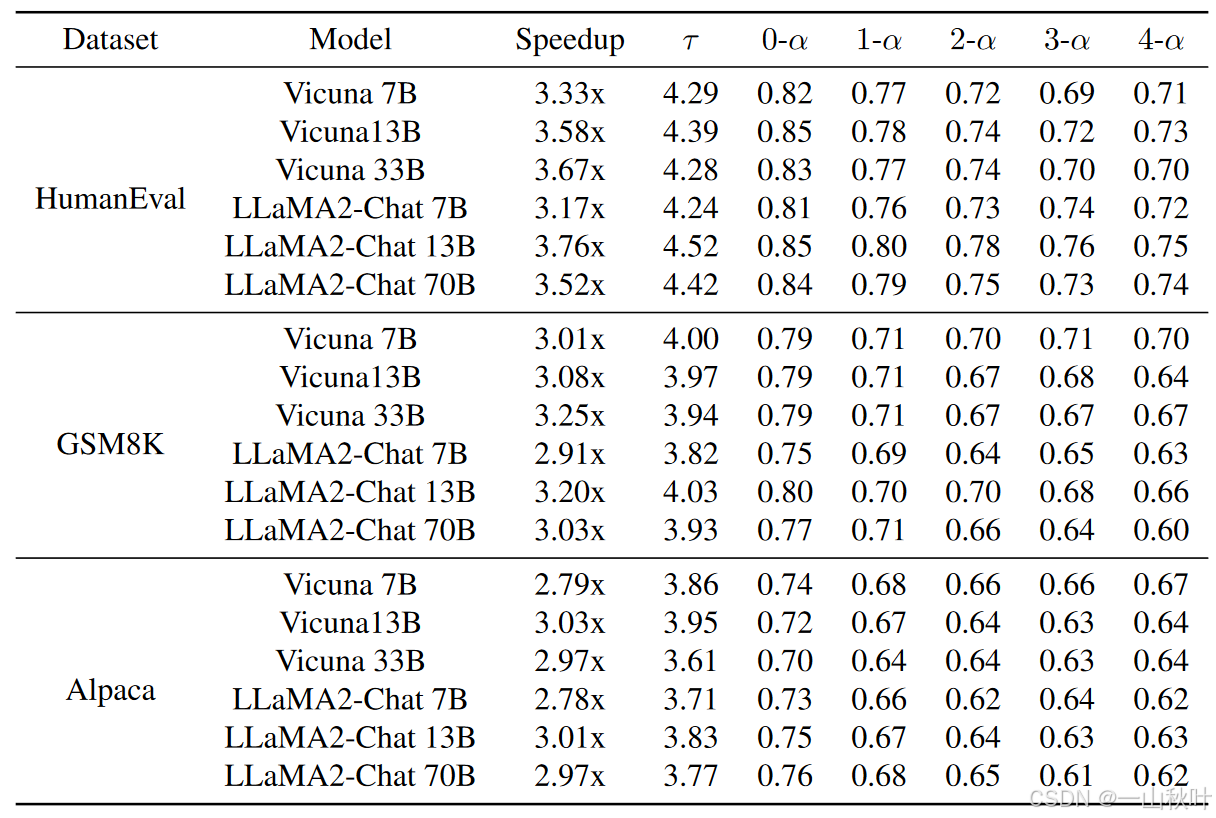
不同基准、温度、指标、模型,搞那么多表。从结果来看,在EAGLE中,目标LLM每次前向会产生3.2-4.5个token,远超自回归的每次一个,生成速度显著加快。完全准确的特征序列所产生的接受率,显著高于存在单个错误特征的序列产生的接受率
,可见错误特征对于草稿模型性能的影响,而从
到
的微小变化也体现出EAGLE对错误特征的鲁棒性和对错误积累的处理能力。
以Mixtral 8x7B Instruct-v0.1为目标LLM,加速率、平均接受长度、接受率的测试结果如下表。和LLaMA这类模型相比,这个加速率就没那么明显了,因为平均接受长度短,而且用投机采样加速MoE模型更复杂。原始的自回归解码过程中,MoE模型通常只需要读取每个token的两位专家的权重,然而在投机采样的验证阶段,处理多个token就得访问超过两个专家的权重了(人为限制的激活专家数,提高计算效率、避免过拟合、保持性能与多样性之间的平衡、增强模型灵活性,使得MoE模型在处理复杂任务时,既能利用专家特长,又能有效管理计算资源),需要动态选择和访问更多的专家以确保生成的文本质量,模型的计算需求增加(专家路由的不确定性)。密集型单解码器模型与之相比,处理输入时不论多少token,都会一次性读取所有权重,简化了计算过程,但可能在灵活性和适应性上不如MoE模型了。

还能改进
EAGLE还能和其他加速或提升吞吐率的方法结合,如量化、编译等,进一步减少LLM系统的运行成本。例如结合gpt-fast,EAGLE可以让LLaMA2-Chat 7B在一台RTX 3090 GPU上的解码速率达到160.4tokens/s。
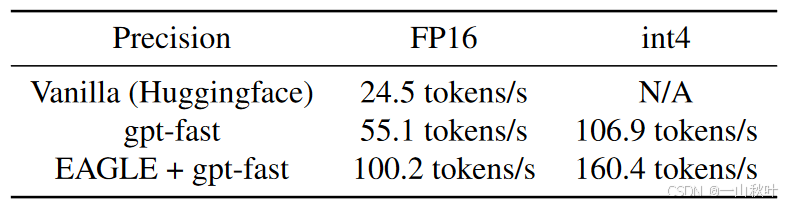
消融实验
树形注意力机制
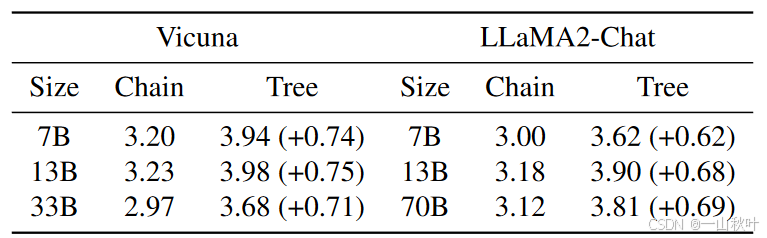
EAGLE和SpecInfer、Medusa一样采用了树形注意力机制,基于树状结构产生和验证草稿,而投机解码用的则是链状草稿。下标是EAGLE在采用树形注意力机制与否的两种情况下,对平均接受长度的测量:
下图是同样设置下加速率的测量结果:
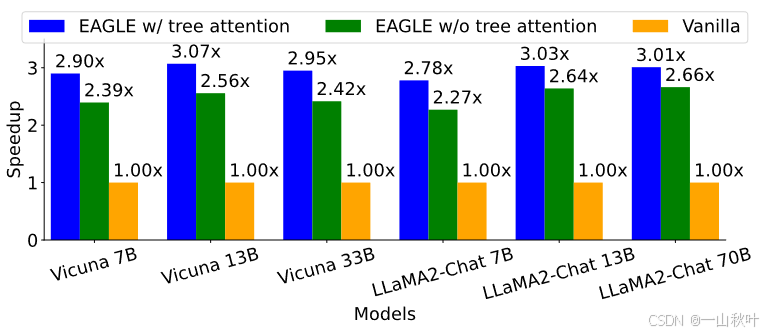
可以看到,采用树形草稿和验证,平均接受长度大约增加0.6-0.8,加速率增加0.3-0.5。因为每次前向时要处理的token数多于链状草稿,故加速比不如平均接受长度的提高那么明显。另外,即使不部署树形注意力,EAGLE的加速效果也蛮明显的,约2.3x-2.7x。
草稿模型的输入
相较于采用投机解码的模型,EAGLE的关键创新在于其使用了由目标LLM计算的特征,并结合采样结果形成草稿模型的输入。作者以Vicuna 7B为目标LLM进行消融实验,在基准MT-bench上评估了不同输入的草稿模型——输入为“特征&移位token”(即EAGLE)、“特征&token”、“token”、“特征”。前两个都有整合语义信息,区别在于EAGLE采用提前了一个时间步的token序列,使其能有效解决随机性。除了使用FC层对“特征&token”输入进行降维外,草稿模型架构完全一致。结果如下:

有3点观察:1. 当草稿模型的参数量受限时,单用特征比单用token略好;2. 将特征和token结合,能提升性能,主要是因为离散、无误差的token缓解了特征的误差累积,拿“特征&token”和“特征”两种输入比对一下,还相差不大,但
就有显著提升了;3. 解决了采样过程中的内在随机性后,更有助于性能提升,比对一下“特征&token”和“特征&移位token”就知道了。
训练数据
EAGLE自回归头理想的训练是用目标LLM自回归生成的文本,但这种方法成本很高。所幸EAGLE对训练数据没有很敏感,所以作者改用一个固定的数据集。打草稿期间,特征的不准确性会导致误差积累,于是作者又采用数据增强的方法,在训练的过程中从均匀分布中采样作为随机噪声,添加到目标LLM的特征之中。

针对训练数据这个问题,作者比较两种数据集来源的情况下的加速率和平均接收长度 ,目标LLM是LLaMA2-Chat 7B。所谓“固定数据集”指的是问题和答案均源于ShareGPT数据集;“数据产自目标LLM”则是问题源于ShareGPT数据集,答案由目标LLM产生。可以看到后者对性能的提升有限。
批量大小和吞吐量
LLM的推理过程受限于内存,GPU的计算资源未有效利用。投机解码能提高生成速度的背后原理便在于能更有效利用GPU的计算资源。随着批量大小(模型同时处理的样本数量)增加,可用的GPU计算资源减少,加速效果也就没那么明显了。作者尝试了超过1的批量大小,结果如下表

当采用Vicuna 7B作为目标LLM时,加速率在bs=4时比在bs=3时高,这归功于在EAGLE的验证阶段,目标LLM的一个前向过程会产生多个token,前者处理起来更快,对于每次只产生一个token的原始自回归解码,这两种设置下就几乎一样了。
(基于随机采样的方法一般都关注于延迟latency)作者也调查了EAGLE在批量大小超过1时的吞吐量——LLM系统中另一个重要指标。相较于原始自回归解码,EAGLE需要的CUDA内存稍多点。(通过逐步增加批量大小并监控内存使用情况,最终确定最大批量大小?均以FP16精度进行评估)将Vicuna 7B作为目标LLM,在一台带24G CUDA内存的RTX 3090上运行,针对原始的自回归解码和EAGLE的批量大小最多分别设为8和7。在以LLaMA2-Chat 70B为例,在4块A100(40G) GPU共160G的CUDA内存约束下,分别为5和4。原始自回归解码和EAGLE均在最小批量时达到最大吞吐量。树形注意力机制则会消耗更多的计算资源,在bs=7时计算资源更不充裕,不用树形注意力机制较好。如上表所示,EAGLE在吞吐量上可以达到2x的提升。
相关工作
已有大量研究用于加速语言模型,有蒸馏、量化、剪枝、创新的网络架构设计,这些方法都致力于减少每次前向过程中的延迟。与这篇工作相近的是基于投机采样的许多框架,早期工作加速贪心解码的过程,后来投机采样将其扩展到了非贪心采样,并保持了原始的输出分布。保证一样的输出分布会让加速更有挑战性,许多研究便尝试有损加速以作为一种权衡,比如DistillSpec通过使用宽容函数来调整接受概率,使得模型在推理采样过程中能更灵活地接受生成的令牌;比如BiLD在和目标LLM分布的距离度量低于某个阈值时就接受草稿;再比如Medusa使用硬阈值和基于熵的阈值的较小者进行截断(可以参考博客的“扩展/典型接受策略”这节内容)。而EAGLE没有使用任何松弛,严格保持了和目标LLM一样的输出分布。
各类基于投机采样的方法的主要差异体现在草稿阶段。投机解码(博客)将目标LLM的更少参数版本作为草稿模型;自投机解码(Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding)在生成草稿时跳过了目标LLM的某些层;SpecInfer采用一组小模型并行生成草稿;级联投机解码(Cascade Speculative Drafting for Even Faster LLM Inference)分阶段投机解码(Accelerating LLM Inference with Staged Speculative Decoding)会级联不同开销的草稿模型;在线投机解码(Online Speculative Decoding)在一系列不同查询的分布上训练草稿模型,以适应和响应各种输入;还有其他方法例如Medusa不会部署一个单独的LLM,而是利用来自目标LLM的特征或权重进行草稿的生成;REST(REST: Retrieval-Based Speculative Decoding)基于检索的方法生成草稿;LLMA(Inference with Reference: Lossless Acceleration of Large Language Models),用于对存在重叠的输入输出进行语法纠正,会直接从输入中检索草稿内容。
写在最后:EAGLE(extrapolation algorithm for greater language-model efficiency)为什么要叫“老鹰”?extrapolation(外推),指的是该算法在生成过程中通过预测未来的特征或信息来提高效率。
This approach involves extrapolating the second-top-layer contextual feature vectors of LLMs, enabling a significant boost in generation efficiency.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)