基于机器视觉的番茄图像分割和品质分级系统
基于机器视觉的番茄图像分割和品质分级系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着计算机视觉和机器学习技术的快速发展,基于机器视觉的图像分割和品质分级系统在农业领域得到了广泛的应用。其中,番茄作为全球重要的蔬菜作物之一,其种植和产量对于人类的生活和经济发展具有重要意义。然而,番茄的品质评估和分级通常需要大量的人力和时间,且存在主观性和不一致性的问题。因此,开发一种基于机器视觉的番茄图像分割和品质分级系统具有重要的研究意义和实际应用价值。
首先,基于机器视觉的番茄图像分割和品质分级系统可以提高番茄品质评估的效率和准确性。传统的人工评估方法需要专业人员对番茄进行视觉检查和手工测量,这不仅耗时耗力,而且容易受到主观因素的影响。而基于机器视觉的系统可以通过图像处理和机器学习算法自动分割番茄图像,并提取关键特征进行品质评估,大大减少了人力成本和时间成本,并且可以消除主观性和不一致性的问题,提高评估的准确性和一致性。
其次,基于机器视觉的番茄图像分割和品质分级系统可以促进农业生产的智能化和自动化。随着农业科技的不断进步,农业生产已经逐渐向着智能化和自动化的方向发展。而番茄作为重要的农产品之一,其种植和品质管理也需要借助先进的技术手段来提高生产效率和质量。基于机器视觉的系统可以实时监测和分析番茄的生长情况和品质变化,为农民提供决策支持和管理指导,帮助他们更好地控制生产过程和提高产量和品质。
此外,基于机器视觉的番茄图像分割和品质分级系统还可以为番茄行业的质量控制和市场竞争提供有力支持。随着人们对食品安全和品质的要求越来越高,番茄行业也面临着更加严格的质量控制和市场竞争。基于机器视觉的系统可以快速准确地评估番茄的品质,帮助企业实现全程质量控制和追溯,提高产品的竞争力和市场占有率。同时,基于机器视觉的系统还可以帮助企业进行市场调研和预测,根据消费者的需求和市场趋势调整生产和销售策略,提高企业的盈利能力和市场竞争力。
综上所述,基于机器视觉的番茄图像分割和品质分级系统在农业领域具有重要的研究意义和实际应用价值。通过提高番茄品质评估的效率和准确性,促进农业生产的智能化和自动化,以及为番茄行业的质量控制和市场竞争提供支持,该系统有望为番茄产业的可持续发展和农业现代化进程做出积极贡献。因此,开展基于机器视觉的番茄图像分割和品质分级系统的研究具有重要的理论和实践意义。
2.图片演示



3.视频演示
基于机器视觉的番茄图像分割和品质分级系统_哔哩哔哩_bilibili
4.参考流程图
参考该博客的基本流程图来设计系统,分为图像采集,图像预处理,番茄大小,形状,颜色,损伤分级,机器实现等步骤。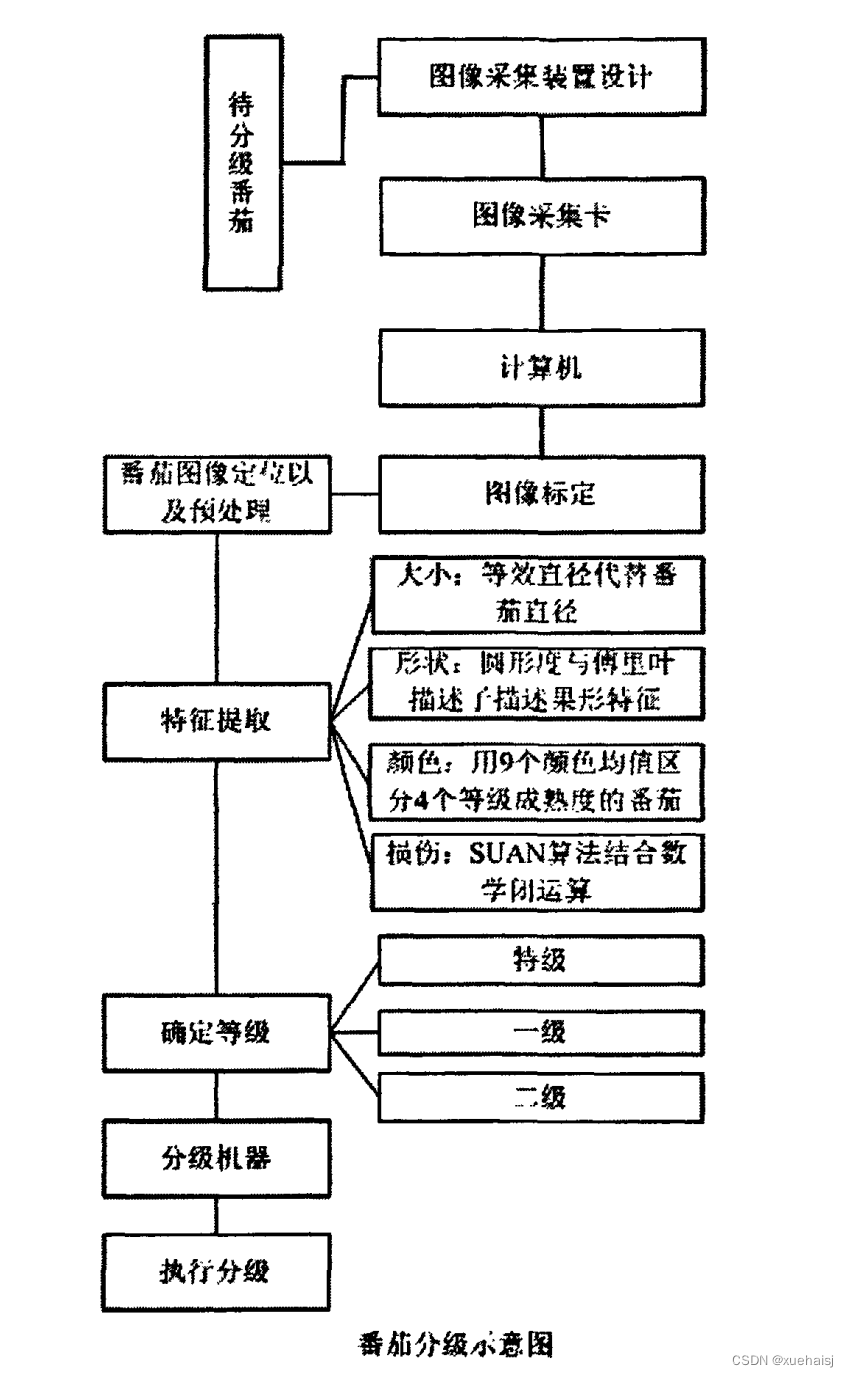
5.核心代码讲解
5.1 export.py
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx>=1.12.0')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_simp, check = onnxsim.simplify(f, check=True)
assert check, 'assert check failed'
onnx.save(model_simp, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure {e}')
return f, None
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。该文件提供了不同的导出格式和相应的命令行参数,用户可以根据需要选择导出的格式。导出的格式包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。用户可以使用命令行参数来指定要导出的格式,例如--include torchscript onnx openvino engine coreml tflite表示导出TorchScript、ONNX、OpenVINO、TensorRT、CoreML和TensorFlow Lite格式的模型。导出的模型可以用于推理,可以使用detect.py脚本进行推理,根据不同的模型格式选择相应的模型文件进行推理。
5.2 TomatoAnalysis.py
class TomatoAnalysis:
def __init__(self):
self.maturity_classifier = MLPClassifier()
def load_model(self, model_path):
from joblib import load
return load(model_path)
def rgb_to_hsi(self, rgb_image):
hsi_image = rgb2hsv(rgb_image)
return hsi_image
def extract_features(self, hsi_image):
hue_hist = np.histogram(hsi_image[:, :, 0], bins=10, range=(0, 1))[0]
saturation_hist = np.histogram(hsi_image[:, :, 1], bins=10, range=(0, 1))[0]
intensity_hist = np.histogram(hsi_image[:, :, 2], bins=10, range=(0, 1))[0]
features = np.concatenate([hue_hist, saturation_hist, intensity_hist])
return features.reshape(1, -1)
def grade_maturity(self, rgb_image):
hsi_image = self.rgb_to_hsi(rgb_image)
features = self.extract_features(hsi_image)
maturity_grade = self.maturity_classifier.predict(features)
return maturity_grade
def detect_edges_susan(self, grayscale_image):
edges = cv2.Canny(grayscale_image, 100, 200)
return edges
def detect_damage(self, rgb_image):
grayscale_image = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2GRAY)
edges = self.detect_edges_susan(grayscale_image)
selem = disk(2)
closed_edges = closing(edges, selem)
return closed_edges
TomatoAnalysis.py是一个用于番茄分析的程序文件。该文件包含了一个名为TomatoAnalysis的类,该类具有以下方法:
-
__init__(self): 初始化方法,创建了一个MLPClassifier对象用于成熟度预测。 -
load_model(self, model_path): 加载预训练的模型,用于成熟度预测。 -
rgb_to_hsi(self, rgb_image): 将RGB图像转换为HSI图像。 -
extract_features(self, hsi_image): 使用颜色直方图作为特征,提取特征。 -
grade_maturity(self, rgb_image): 将图像转换到HSI模型,提取特征,并预测成熟度。 -
detect_edges_susan(self, grayscale_image): 使用SUSAN算子检测边缘。 -
detect_damage(self, rgb_image): 将RGB图像转换为灰度图像,使用SUSAN算子检测边缘,并应用闭运算填充损伤。
该程序文件使用了一些第三方库,包括numpy、cv2、skimage和sklearn。它提供了一些方法用于对番茄图像进行成熟度预测和损伤检测。
5.3 TomatoGrading.py
class TomatoGradingSystem:
def __init__(self):
# 初始化BP神经网络,可能需要调整参数
self.maturity_classifier = MLPClassifier(hidden_layer_sizes=(10, 10), max_iter=500)
# 其他成员变量初始化...
# 图像预处理示例
def preprocess_image(self, image):
# 将背景转换为黑色
if self.background_color == 'black':
mask = image < threshold_otsu(image)
image[mask] = 0
# 使用开运算去除背景噪点
selem = disk(2)
image = opening(image, selem)
# 应用中值滤波去噪
image = medfilt2d(image, kernel_size=3)
return image
# 大小和形状分级示例
def grade_size_and_shape(self, image):
# 使用Canny算子找到边缘
edges = canny(image)
# 标记区域
labeled_tomato = label(edges)
# 计算等效直径和圆形度
properties = regionprops(labeled_tomato)
for prop in properties:
equivalent_diameter = prop.equivalent_diameter
circularity = (4 * np.pi * prop.area) / (prop.perimeter * prop.perimeter)
# 这里简化处理,实际可能需要更多逻辑
return equivalent_diameter, circularity
TomatoGrading.py是一个番茄分级系统的程序文件。该程序使用了OpenCV、NumPy、scikit-image和scikit-learn等库来进行图像处理和分析。
程序中定义了一个TomatoGradingSystem类,该类包含了番茄分级系统的各种功能和方法。
在类的初始化方法中,程序初始化了一个BP神经网络分类器,并设置了隐藏层的大小和最大迭代次数。
程序还定义了一个图像预处理方法preprocess_image,该方法用于对图像进行预处理。预处理过程包括将背景转换为黑色、使用开运算去除背景噪点和应用中值滤波去噪。
程序还定义了一个大小和形状分级方法grade_size_and_shape,该方法用于对图像进行大小和形状分级。分级过程包括使用Canny算子找到边缘、标记区域、计算等效直径和圆形度。
需要注意的是,程序中的部分逻辑可能需要根据实际情况进行更多的处理和调整。
5.4 classify\predict.py
class YOLOv5Classifier:
def __init__(self, weights, source, data, imgsz, device, view_img, save_txt, nosave, augment, visualize, update,
project, name, exist_ok, half, dnn, vid_stride):
self.weights = weights
self.source = source
self.data = data
self.imgsz = imgsz
self.device = device
self.view_img = view_img
self.save_txt = save_txt
self.nosave = nosave
self.augment = augment
self.visualize = visualize
self.update = update
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.vid_stride = vid_stride
def run(self):
source = str(self.source)
save_img = not self.nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(self.imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.Tensor(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
results = model(im)
# Post-process
with dt[2]:
pred = F.softmax(results, dim=1) # probabilities
# Process predictions
for i, prob in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
annotator = Annotator(im0, example=str(names), pil=True)
# Print results
top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices
s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
# Write results
text = '\n'.join(f'{prob[j]:.2f} {names[j]
这个程序文件是一个用于运行YOLOv5分类推理的脚本。它可以对图像、视频、目录、YouTube、网络摄像头等进行分类推理。
该脚本可以通过命令行参数来指定模型权重文件、数据源、推理尺寸、设备等。它会加载模型、数据集,并对数据进行预处理。然后,它会对每个输入进行推理,并对结果进行后处理和可视化。最后,它会将结果保存到指定的目录中。
该脚本还支持一些其他功能,如保存结果到文本文件、显示结果、使用半精度推理等。
你可以通过命令行参数来配置脚本的行为,并运行该脚本来进行分类推理。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于机器视觉的番茄图像分割和品质分级系统。它包含了多个程序文件和模块,用于实现不同的功能,包括图像分割、番茄成熟度预测、品质分级等。
该项目的整体构架如下:
-
数据集准备:包括数据集的下载、预处理和划分。
-
图像分割模块:使用YOLOv5模型进行图像分割,将番茄从图像中分割出来。
-
番茄成熟度预测模块:使用机器学习算法(如BP神经网络)对番茄的成熟度进行预测。
-
品质分级模块:对番茄进行大小和形状分级,评估番茄的品质。
-
用户界面模块:提供用户界面,方便用户进行图像上传、预测和分级。
-
训练和验证模块:用于训练和验证模型的脚本,包括分类模型和分割模型。
-
工具模块:包括各种辅助工具和功能模块,如模型导出、数据加载、图像处理、日志记录等。
下面是每个文件的功能概述:
| 文件路径 | 功能 |
|---|---|
| TomatoAnalysis.py | 番茄成熟度预测模块的实现 |
| TomatoGrading.py | 番茄品质分级模块的实现 |
| ui.py | 用户界面模块的实现 |
| val.py | 验证训练好的YOLOv5分类模型的脚本 |
| classify/predict.py | 运行YOLOv5分类推理的脚本 |
| classify/train.py | 训练基于YOLOv5的分类器模型的脚本 |
| classify/val.py | 在分类数据集上验证训练好的YOLOv5分类模型的脚本 |
| models/common.py | 共享的模型相关函数和类 |
| models/experimental.py | 实验性的模型实现 |
| models/tf.py | TensorFlow模型实现 |
| models/yolo.py | YOLOv5模型实现 |
| models/init.py | 模型初始化文件 |
| segment/predict.py | 运行YOLOv5分割推理的脚本 |
| segment/train.py | 训练基于YOLOv5的分割模型的脚本 |
| segment/val.py | 在分割数据集上验证训练好的YOLOv5分割模型的脚本 |
| utils/activations.py | 激活函数相关的工具函数 |
| utils/augmentations.py | 数据增强相关的工具函数 |
| utils/autoanchor.py | 自动锚框相关的工具函数 |
| utils/autobatch.py | 自动批处理相关的工具函数 |
| utils/callbacks.py | 回调函数相关的工具函数 |
| utils/dataloaders.py | 数据加载相关的工具函数 |
| utils/downloads.py | 下载相关的工具函数 |
| utils/general.py | 通用工具函数 |
| utils/loss.py | 损失函数相关的工具函数 |
| utils/metrics.py | 评估指标相关的工具函数 |
| utils/plots.py | 绘图相关的工具函数 |
| utils/torch_utils.py | PyTorch相关的工具函数 |
| utils/triton.py | Triton Inference Server相关的工具函数 |
| utils/init.py | 工具模块初始化文件 |
| utils/aws/resume.py | AWS相关的工具函数 |
| utils/aws/init.py | AWS模块初始化文件 |
| utils/flask_rest_api/example_request.py | Flask REST API示例请求的工具函数 |
| utils/flask_rest_api/restapi.py | Flask REST API的实现 |
| utils/loggers/init.py | 日志记录模块初始化文件 |
| utils/loggers/clearml/clearml_utils.py | ClearML日志记录工具函数 |
| utils/loggers/clearml/hpo.py | ClearML超参数优化工具函数 |
| utils/loggers/clearml/init.py | ClearML日志记录模块初始化文件 |
| utils/loggers/comet/comet_utils.py | Comet日志记录工具函数 |
| utils/loggers/comet/hpo.py | Comet超参数优化工具函数 |
| utils/loggers/comet/init.py | Comet日志记录模块初始化文件 |
| utils/loggers/wandb/log_dataset.py | WandB日志记录工具函数 |
| utils/loggers/wandb/sweep.py | WandB超参数优化工具函数 |
| utils/loggers/wandb/wandb_utils.py | WandB日志记录工具函数 |
| utils/loggers/wandb/init.py | WandB日志记录模块初始化文件 |
| utils/segment/augmentations.py | 分割数据增强相关的工具函数 |
| utils/segment/dataloaders.py | 分割数据加载相关的工具函数 |
| utils/segment/general.py | 分割通用工具函数 |
| utils/segment/loss.py | 分割损失函数相关的工具函数 |
| utils/segment/metrics.py | 分割评估指标相关的工具函数 |
| utils/segment/plots.py | 分割绘图相关的工具函数 |
| utils/segment/init.py | 分割模块初始化文件 |
7.图像采集系统背景选择
作为果蔬识别系统的背景,采用得比较多的有纯白色与纯黑色背景两种,由于实时采集的图片质量好坏对后续的图像处理影响非常大,如果背景选取合适,后期的处理速度、效率将大大提高。CCD 相机采集的图像都是彩色图像,由于番茄表面非常光滑,很容易产生镜面反射,而且其不规则性容易导致阴影的出现,出于易于分割以及不易于造成反射的考虑,黑色漫反射背景正能满足一系列的要求,为此,我们选择常用的黑色鼠标垫背面作为背景,能获得比较好的实时采集图像。
图像采集系统光源安放
合理放置光源,主要是为了获得均匀照明度的环形光源,减少因光照不均而导致的偏光,阴影等而造成的后期处理不准确或者处理困难等。因此,在照明室内必须产生均勾的环形光源,如系统硬件图所示,在照相机下面安装一个环形日光灯,从上而下照射番茄,在跟番茄水平的四周,应该如图所示安放4相同规格的日光灯:
番茄图像标定
我们采用CCD相机对番茄进行拍照采样,得到的图片会存在一定的畸变,同时,得到的图像单位为象素(pixel)。要测量实际的番茄大小,必须通过一定的转换调整,把图像像素距离与实际距离对应起来。这就需要应用到计算机视觉的标定理论,计算机视觉的基本任务之一是从摄像机获取的图像信息出发计算三维空间中物体的几何信息,并由此重建和识别物体,而空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系是由摄像机成像的几何模型决定的,这些几何模型参数就是摄像机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个过程被称为是摄像机定标。
目前的摄像机标定技术大致可归结为传统的摄像机标定方法和摄像机自标定方法两类3。自适应标定的计算复杂,对硬件要求比较高,不适合在工业生产应用,番茄图像标定采用的是CCD相机拍照照片,而且实时性要求高,而传统摄像机标定方法,其标定物绘制简单,价格低廉,是一种非常实用、精度较高的标定方法。所以本文采用传统的摄像机标定方法,对于近距离的标定能满足快速准确的要求。常用的方法有1998年张正友的平面标定法[瑚,考虑了径向畸变,利用多幅平面模板代替传统的摄像机标定块,标定摄像机的内外参数;Tsail39在他的论文中所使用的典型两步法。给出了一种在假定只存在径向畸变条件下的标定算法,该算法分为两步进行,第1步基于图像点坐标只有径向畸变误差,而无周向畸变偏移的特性,通过建立和求解超定线性方程组,先计算出外部参数;第2步考虑畸变因素,利用一个三变量的优化搜索算法求解非线性方程组,来确定其他参数。张艳珍,欧宗瑛[在一种新的摄像机线性标定方法中提出了对Tsai的一种线性求解方法,避免了非线性优化的不稳定性,同时方法简单,对实验条件要求较低,速度较快,满足工业的实时性要求,比较实用。本文采用改进算法对番茄图像进行标定。
8.番茄图像定位以及缩放处理
由于CCD相机拍摄的图片比较大(尺寸:2592x1944),而且非目标区域占了很大的比例,因此,为了快速有效的处理,必须对图片进行缩放和快速定位,本论文通过批量读入采集图像对每一张图片进行了25%缩放比例处理;同时,在取得目标区域的有效边界以后,依靠边界对目标区域快速定位,为以后的目标区域处理减少了搜索时间,进一步提高处理的效率。具体定位的算法为:具体提取到的番茄边缘,从上至下,从左到右水平扫描,获得边缘的最小横坐标与最小纵坐标为定位图像的左上角坐标点(起始点),获得最大横坐标与最大纵坐标为定位图像右下角坐标点(终止点),然后上下左右分别留出一定的像素余度,即可获得定位图像。获得的定位图像大小为(267×263),所需要处理的图像大小为原图像大小的,而这种缩放以及定位对于番茄的分类检测是没有影响的。
番茄图像分割研究
图像处理的主要任务就是对图像中的对象进行分析和理解,为此需要将目标从图像中提取出来,并在此基础上进行进一步分析。图像分割就是把图像分成互不重叠的区域并提出感兴趣目标的技术(3]。常用的图像分割方法有阙值分割和边缘检测,但是现在并没有一套通用的分割模板能适应各种图像的分割需求,所以在本文中,需要寻找一种合适番茄图像分割精度要求同时能满足分类实时性要求的分割方法,图对常用的分割方法进行了总结: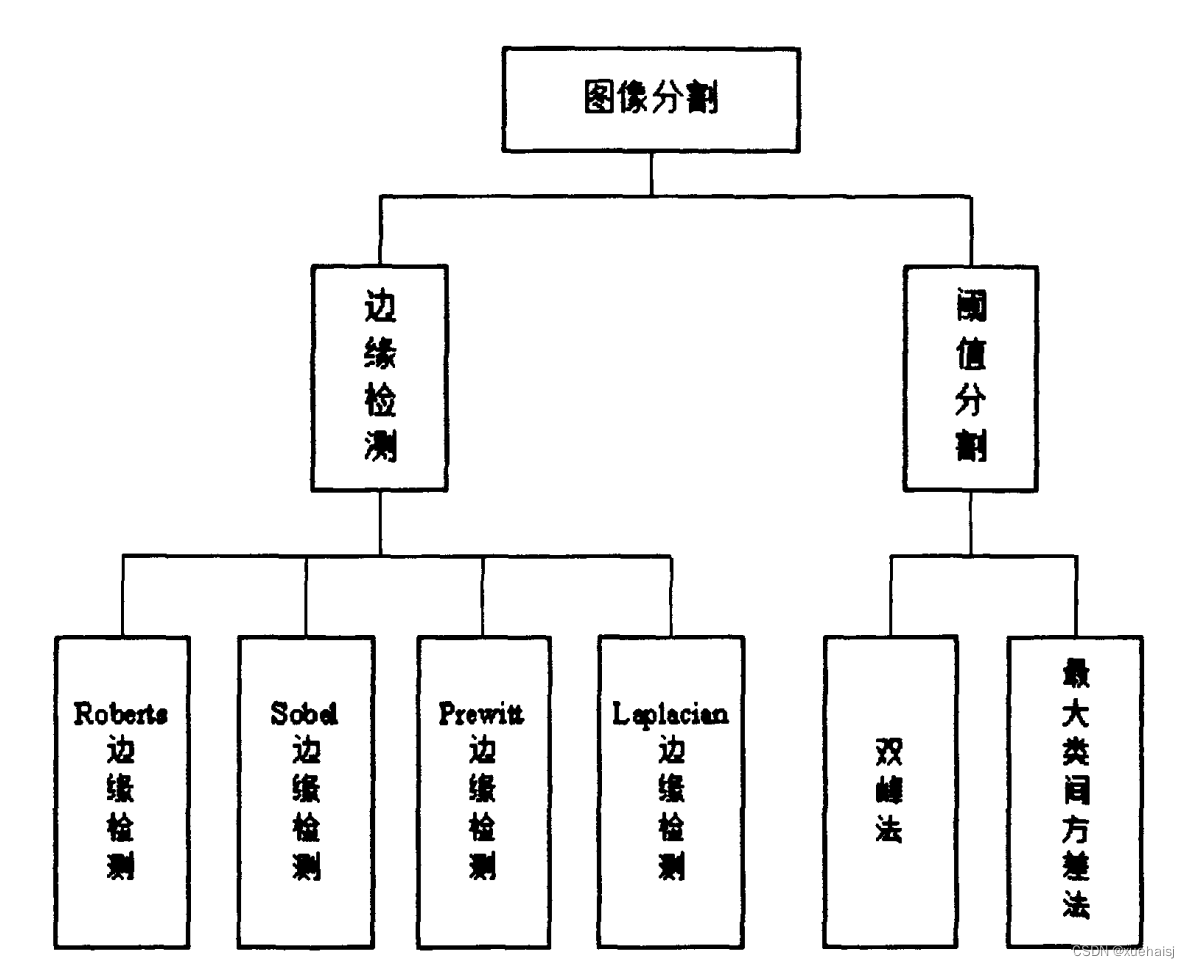
9.图像预处理
阙值分割法
1,双峰法
在某些简单的图像当中,物体跟背景的直方图分布会比较有规律,直方图形成两个波峰,分别对应着物体跟背景,而在两波峰之间,有一个波谷,这样,可以通过在波谷区域设定一个阈值,就可以把背景跟物体分割开来l*5。本文对一幅番茄的图像采用双峰法进行图像分割。如图所示,阙值可取60。
由于低谷处像素个数比较少,即使阙值选择在低谷处有很大偏差,分割的结果也相差不大。把低谷取为60,分割后的图像如图所示: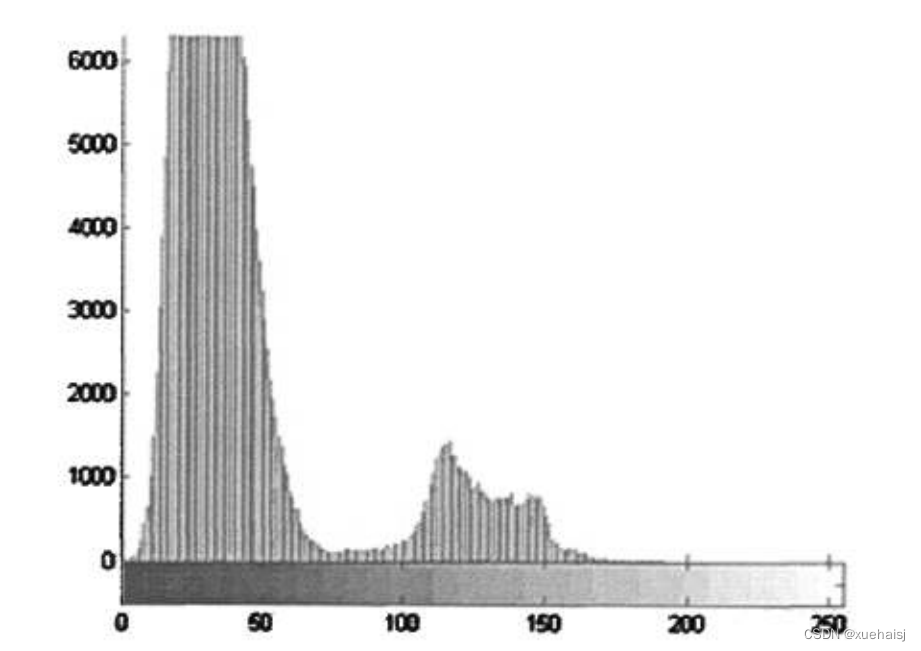
出现波峰间的波谷平坦、直方图的波形重叠等情况时,用双峰法便难以确定阈值。上图可以看到,背景的噪声以及番茄本身的果蒂没好很好的抑制,显然对后续处理不利。
2,最大类间方差法
双峰法只需要设定一个单一的全局阈值,就可以实现背景与目标的分割,比较简单。但很多时候,特别是光照、噪声等因素影响的时候,背景跟目标区域是有部分重叠的,单一的阈值并不能很好的把他们区分出来,实际分割中,希望能找到一个使得分割误差最小的阈值,这就提出了一个选取最优阈值的问题,最优阈值是指能使误分割概率最小的分割阈值*。图像的直方图是像素灰度值概率密度函数的一个近似,番茄图像主要包括番茄与背景两大类灰度值区域,它直方图所代表的像素灰度值概率密度分布函数实际就是目标跟背景两个单峰分布密度函数之和。因此,通过求解密度函数,就可以算出最优阈值,然后把番茄从图像中分割出来。
假定番茄像素灰度级与背景像素灰度级分别符合正态分布,设背景与目标概率密度为p,(z)、p.(z),可以得到整幅图像的混合概率密度p(z)为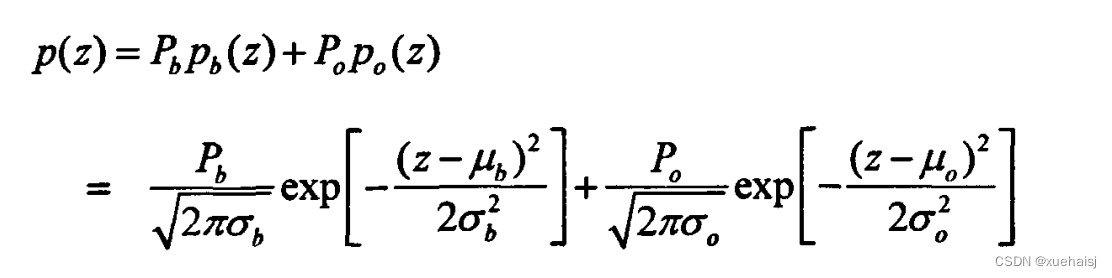
10.番茄大小分级
在番茄的分级生产过程中,大小分级和形状分级是最基础也是最重要的两个初步分级步骤,通过大小、形状的分级,能初步确定番茄的等级,结合后面的颜色,无损分级,可以达到现实生产需要的分级需求。
对番茄的大小进行分级,必须提取反映番茄大小的特征量。而描述物体大小的特征量比较常用的有半径、周长、面积等。半径是最直接反映物体大小的特征分量,可以通过求得物体的周长或者面积,然后通过公式计算出其半径的大小,也可以通过求出其外切矩形然后求得其半径;周长因为跟半径成正比关系,因此,在一定程度上也能反映规则物体的大小;图像处理中,计算区域面积就是对属于物体目标区域的像素进行记数,方法简单。上述的求半径,周长,面积的方法,要求物体和背景内部各自比较平滑,能够清楚的分清物体和背景,同时光照对测量的影响比较小。如果不满足这些条件,效果就不一定好。
周长及面积求取
番茄基本的几何特征对番茄分级研究有十分重要的作用,其中,周长在数字图像的定义中有多种,通常定义有三种[8]。一是把图像的像素看成单位面积小方块,这样,图像就由目标区域方块跟背景方块组成。这中理解对求解目标区域的面积比较合适;第二种表示是用边界所占面积,即边界点点数之和,这种办法对于周长的求解相对简单,但是准确度不高;第三种定义是把像素点看作一个点,周长用链码表示,当奇数链码时,其长度为√2,偶数时,其长度为1。本论文采用第三种表示方法中的8连通来计算周长。
那么,周长的公式可以表示为: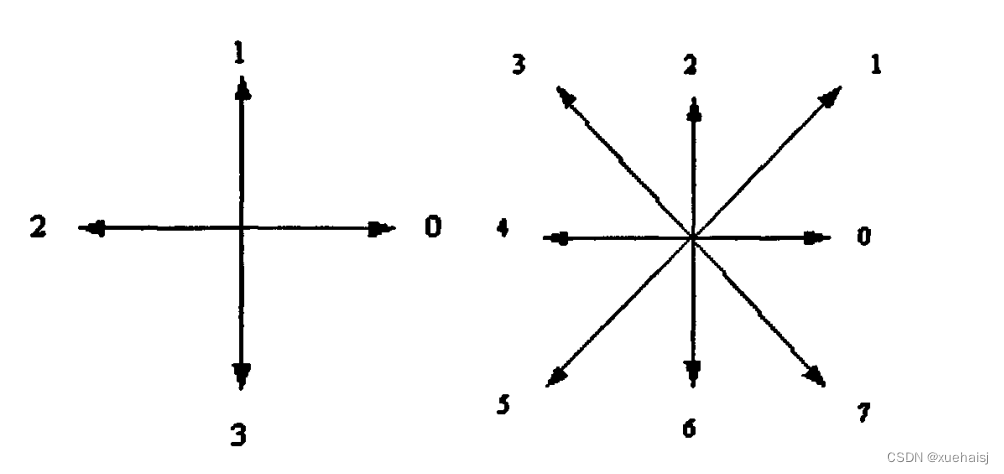
番茄大小特征提取具体步骤
由图像的底层处理,获得了番茄8连通的边缘图像,如图所示:
周长计算具体步骤:
1、计算边缘像素点总值;
2、分别计算水平方向,垂直方向4连通点数目(以横坐标、纵坐标相差是
否为1做判断);求得偶数码的链码数目;
3、总像素值减去偶数码的链码数目得到奇数码的链码数目;
4、由P=N+√2N。求得周长。(N代表偶数点的数量,N代表奇数点的数
量)
面积计算具体步骤:通过水平,垂直双循环扫描,如果像素点值为1,则累加1,当循环结束后,获得的总值就是目标区域的面积。
番茄大小分级实验
可以看出,圆的周长能反映其半径的大小,周长大,半径大,周长与半径成正比。所以,只要求得番茄轮廓的周长,就可以通过判断番茄图像的周长来判断番茄果径的大小,在NY/T 940-2006中7,关于番茄的大果、中果和小果的果径分级参数作出了如表的标准规定:
表番茄果径分级标准
由上表可以看出,不同等级番茄最大横切面直径相差20mm,相差较大,反映到数字图像中,不同等级的番茄其周长也会相差较大。这一个容差范围,对于我们实现番茄的大小快速分级是非常有效的。由上一章标定得到,单位像素的长宽为(0.05555mm,0.05588mm),同时,因为处理的图像进行了25%缩放,以0.05588mm为单位像素长度,可以求出,大果的直径大于313.17像素;中果的直径为大于223.69像素,小于313.17像素;小果的直径为小于223.69像素。因此可以通过简单的设置阈值,就可以进行番茄的大小分类: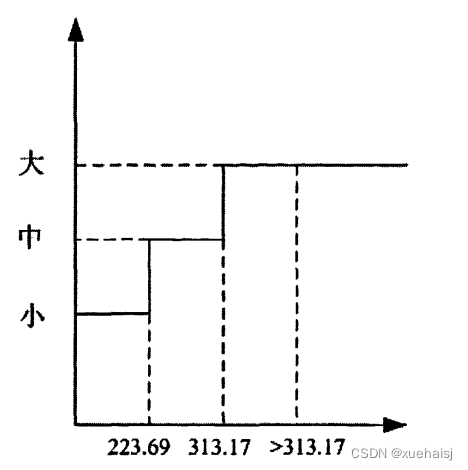
频谱的物理意义是函数f(x)包含的各次谐波的幅度大小|F(n)|,它描述了各次谐波的幅度随频率变化的分布情况。所谓频谱图,通常是频率n和幅度IF(n)|的关系图,它清楚地表明了一个函数包含哪些频率分量及各分量所占的比重。所以能够反映边界函数r(k)的波形成分,间接地反映了原曲线的形状信息。对边界序列r(k)作离散傅里叶变换,如下所示:
11.HSI彩色模型
HSI模型是从人的视觉系统出发,用色调(Hue)、色饱和度(Saturation)以及亮度(Intensity)来表示色彩。色调H是彩色彼此相互区分的特性,如红、黄、蓝等各种色调;饱和度S是指彩色的纯洁性;光强Ⅰ是指光照强度。I分量与图像色彩信息无关,因此能减少光照强度对颜色判别的影响;而H和S分量与人对色彩的感受密切相关。该模型可以用一个三维的枣型立体图来表示,垂直轴代表光强工的变化,从底端的黑色(O)变化到顶端的白色(1):色调H由水平面的四周表,圆周上各点(O-360°)代表光谱上各种不同的色调;从圆心向圆周过度表示颜色饱和度S逐步提高。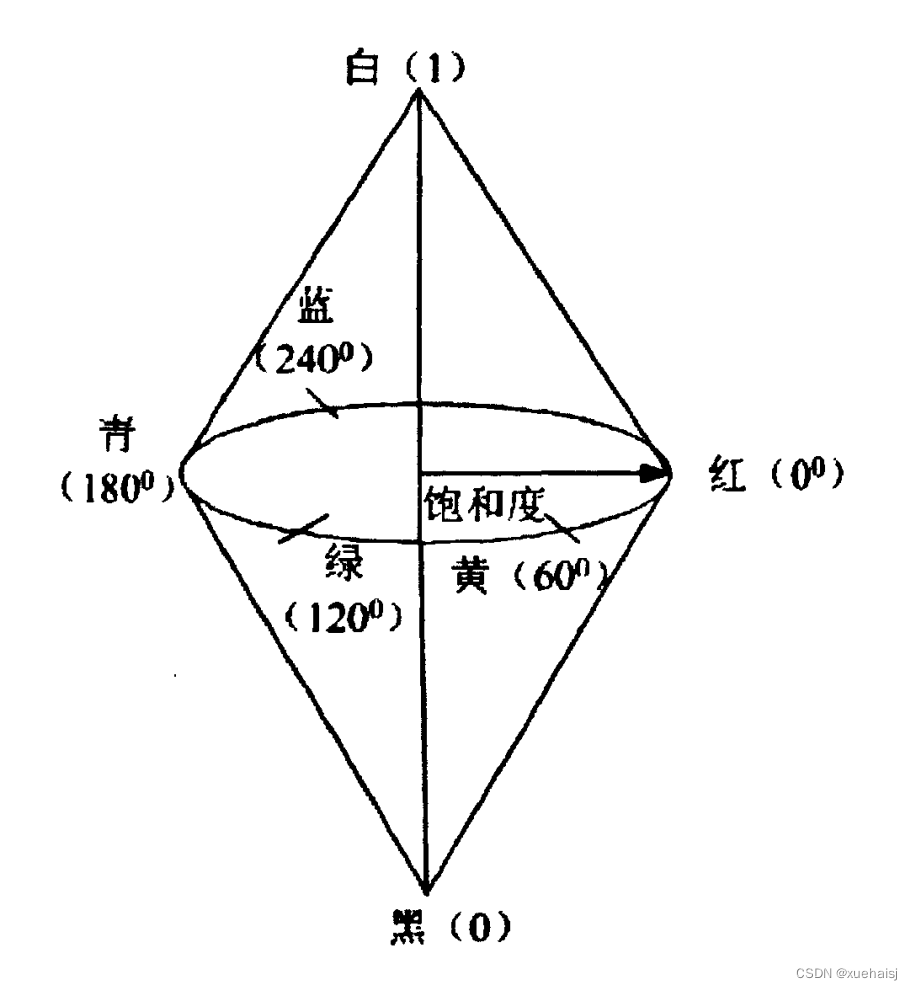
由于我们的CCD相机或者电脑,都是以RGB彩色模型存储图像的,因此,我们需要把RGB模型转化为HSI模型,才可以进行相应的图像处理,具体的转换公式为: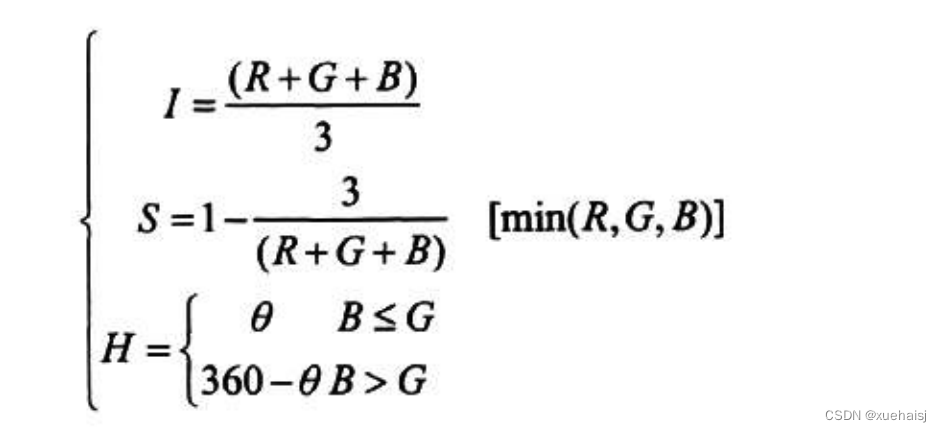
由公式可以看出,因为I分量与彩色信息无关,在实际工作中,影响S分量的光源和光照强度都不变,所以S分量值是确定的,因此对番茄颜色的识别只需考虑H分量就可以。这比直接用RGB彩色模型做番茄颜色识别减少了三分二的工作量,大大提高了处理速度。
基于H分量的番茄成熟度分析研究
由上面公式可以算出H值,通过实验发现,各等级成熟度的番茄H值分布在0°90之间,其中绿熟期(绿色准备转红黄色)分布在70°90°,红熟前期(微黄)分布在30°80°,红熟中期分布在10°30°,红熟后期分布在020°之间,各个区间之间有重叠,因此不能简单的用单一阈值进行分割区别。因此,把90°以10°为单位,划分9个区间,求出每一个区间的平均值代替原区间的值,然后进一步进行神经网络的识别处理。下图是番茄不同时期图像的采集:
去除背景后,提取的番茄图像如下:
基于HSI模型H分量的番茄颜色特征提取如下,可以看到不同成熟期番茄H分量分布在不同的区间。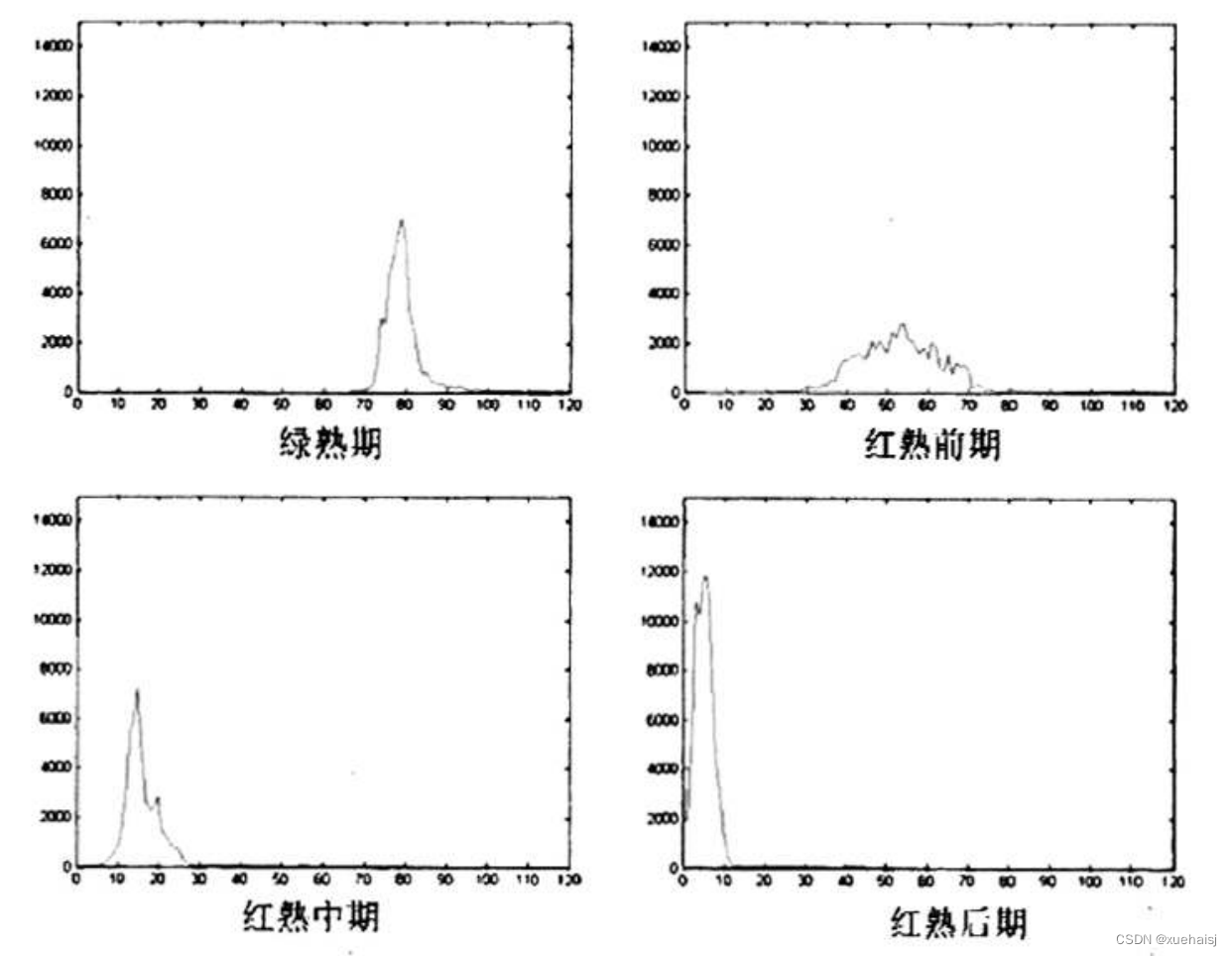
以10°为单位把番茄成熟度区间划分为9个区间,先求取每一个区间的平均值,但是由于番茄有大小,导致了不同大小番茄的平均值没有可比性,因此,把平均值除以番茄像素数做区间归一化处理,这样就可以使得不同大小的番茄具有可比性,用归一化平均值代替原直方图做颜色分级的特征参数。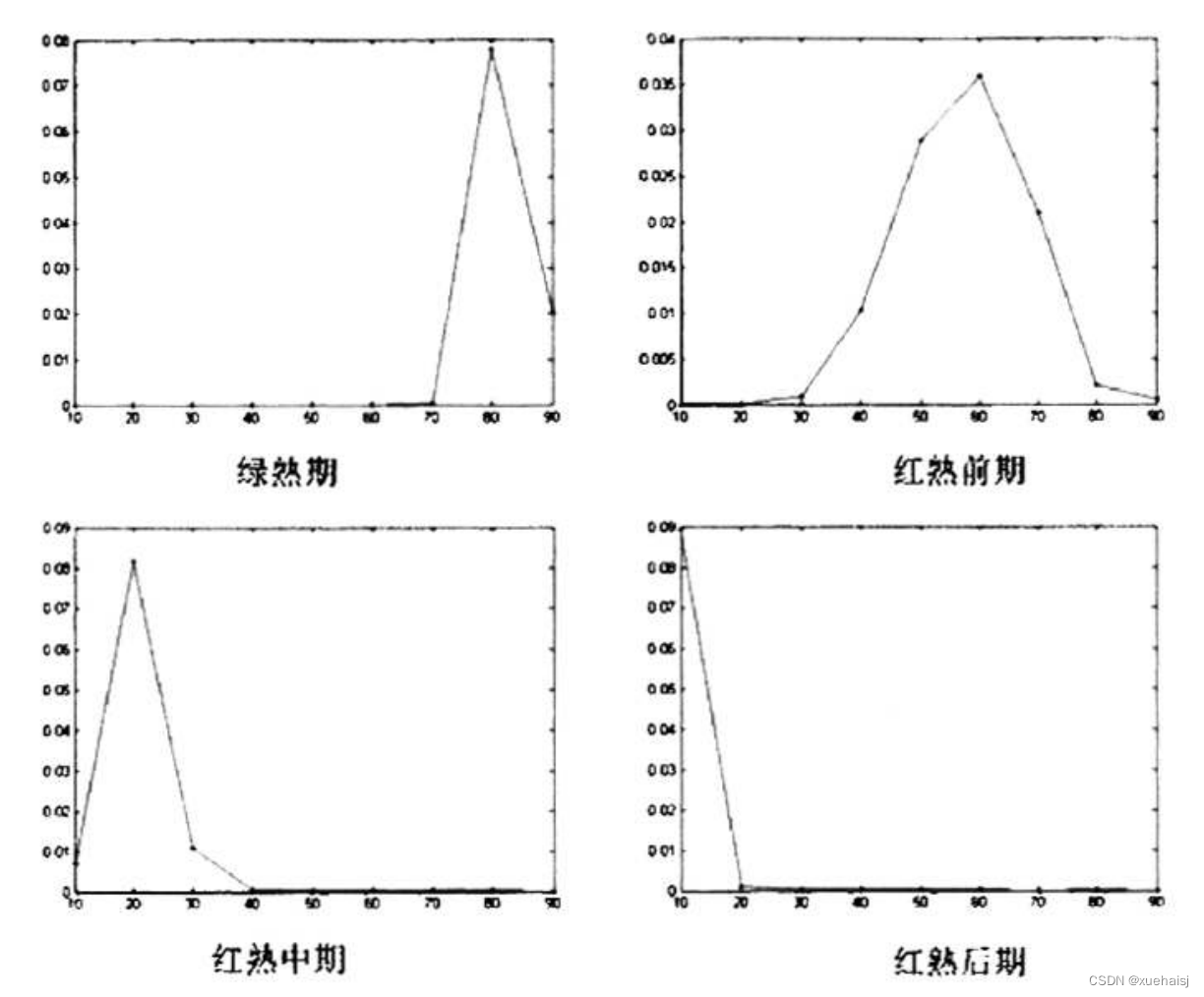
12.系统整合

13.参考文献
[1]金晶,廖桂平,李锦卫,等.农产品品质无损检测概述[J].农业网络信息.2008,(2).DOI:10.3969/j.issn.1672-6251.2008.02.032 .
[2]周政.BP神经网络的发展现状综述[J].山西电子技术.2008,(2).
[3]安爱琴,余泽通,王宏强.基于机器视觉的苹果大小自动分级方法[J].农机化研究.2008,(4).DOI:10.3969/j.issn.1003-188X.2008.04.049 .
[4]刘静,章程辉,黄勇平.无损检测技术在农产品品质评价中的应用[J].福建热作科技.2007,(3).DOI:10.3969/j.issn.1006-2327.2007.03.016 .
[5]蒲春,孙政顺,赵世敏.Matlab神经网络工具箱BP算法比较[J].计算机仿真.2006,(5).DOI:10.3969/j.issn.1006-9348.2006.05.041 .
[6]刘禾,汪懋华.基于数字图像处理的苹果表面缺陷分类方法[J].农业工程学报.2004,(6).DOI:10.3321/j.issn:1002-6819.2004.06.032 .
[7]应义斌,付峰.水果品质机器视觉检测中的图像颜色变换模型[J].农业机械学报.2004,(1).DOI:10.3969/j.issn.1000-1298.2004.01.022 .
[8]苏高利,邓芳萍.论基于MATLAB语言的BP神经网络的改进算法[J].科技通报.2003,(2).DOI:10.3969/j.issn.1001-7119.2003.02.012 .
[9]冯斌,汪懋华.基于颜色分形的水果计算机视觉分级技术[J].农业工程学报.2002,(2).DOI:10.3321/j.issn:1002-6819.2002.02.035 .
[10]王涛,刘文印,孙家广,等.傅立叶描述子识别物体的形状[J].计算机研究与发展.2002,(12).

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)