[SIGMOD 2025] 带属性超图聚类的新范式 AHRC(Attributed Hypergraph Representation for Clustering)
IMM直接基于综合相似度矩阵SSS比较簇内的“实际相似度”和“期望相似度”之间的差值,越大说明簇划分越显著。
目录
Intro
传统图聚类的局限
图聚类不仅要看结构(比如谁连着谁),还要考虑节点的属性相似性(比如两个用户兴趣标签是否接近)。
现实中很多图是高阶关系图(超图),比如一篇论文的多个作者组成一个“超边”,这不是简单的“点-点”连接关系。
为什么现有方法不够好?
现有的带属性超图聚类方法主要靠 矩阵分解(如NMF),非常依赖预设聚类数,而且计算代价大,不能扩展到大规模数据。
有些方法试图用随机游走传播属性信息,但“为什么属性也要传播”?逻辑站不住脚。
文章的目标
设计一个既高效又高质量的带属性超图聚类方法,满足:
- 不需要提前知道聚类数;
- 能同时整合拓扑结构 + 属性信息;
- 可扩展到大图;
- 可用于现有的对比学习方法。
实验的流程
以下是从超图中生成一个聚类的流程,文章依据这个流程进行详细展开: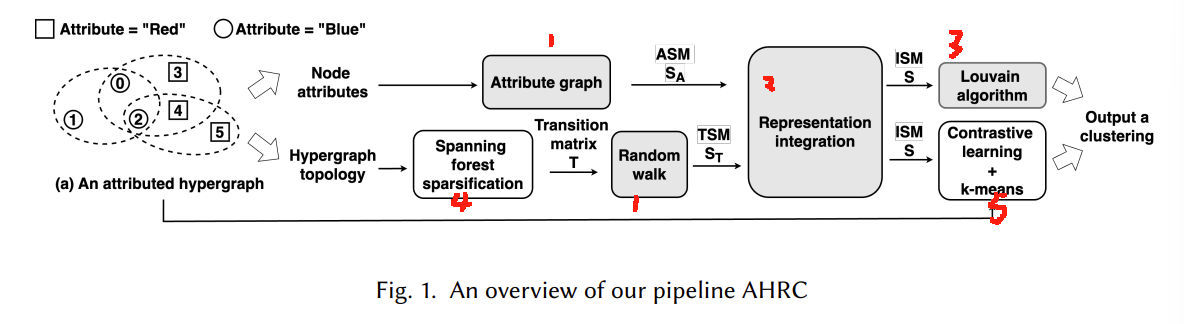
Step1: 处理两部分的输入数据
Step1.1 获取属性相似矩阵 S A S_A SA
按照定义,输入一个代带属性的超图 H ( V , E , att ) H(V, E, \text{att}) H(V,E,att),属性函数 a t t att att 自己给定。
使用属性图(Attribute graph),通过计算每个节点与其他节点的属性相似度,得到属性相似矩阵 S A S_A SA(Attribute Similarity Matrix,ASM)。
为了衡量超图中节点之间的属性相似性,本文采用了经典的 K 近邻(K-Nearest Neighbor, KNN) 搜索方法。
基本步骤如下:
1.输入:
- 属性超图 H ( V , E , a t t ) H(V, E, att) H(V,E,att)
- V V V 表示节点集合
- E E E 表示超边集合
- a t t ( v ) att(v) att(v) 表示节点 V V V 的属性向量
- 参数: K K K 表示每个节点要保留的最相似邻居个数
2.计算过程:
-
对于每个节点 v ∈ V v \in V v∈V,找到其最相似的 K K K 个邻居,记为:
N K ( V ) N_K(V) NK(V) -
使用余弦相似度来计算两个节点属性的相似性
f ( a t t ( v i ) , a t t ( v j ) ) = a t t ( v i ) ⋅ a t t ( v j ) ∥ a t t ( v i ) ∥ ∥ a t t ( v j ) ∥ f(att(v_i), att(v_j)) = \frac{att(v_i) \cdot att(v_j)}{\|att(v_i)\| \|att(v_j)\|} f(att(vi),att(vj))=∥att(vi)∥∥att(vj)∥att(vi)⋅att(vj) -
构建一个稀疏矩阵,对于任意两个节点 v i v_i vi , v j ∈ V v_j \in V vj∈V,定义:
M [ i , j ] = { f ( a t t ( v i ) , a t t ( v j ) ) , 如果 v j ∈ N K ( v i ) 0 , otherwise M[i,j] = \begin{cases} f(att(v_i), att(v_j)), & \text{如果 } v_j \in N_K(v_i) \\\\ 0, & \text{otherwise} \end{cases} M[i,j]=⎩ ⎨ ⎧f(att(vi),att(vj)),0,如果 vj∈NK(vi)otherwise -
归一化:由于初始属性相似度矩阵 M M M 通常不是对称矩阵,为了适用于聚类算法中的随机游走过程,AHCKA 构造了一个对称的属性相似度矩阵 S A S_A SA:
S A = M + M ⊤ , S A ∈ R n × n S_A = M + M^\top,\quad S_A \in \mathit{R}^ {n \times n} SA=M+M⊤,SA∈Rn×n
其中 M [ i , j ] M[i, j] M[i,j] 表示节点 v i v_i vi 与 v j v_j vj 之间的属性余弦相似度,仅当 v j v_j vj 是 v i v_i vi 的KNN邻居时才非零。
#精确计算KNN图的时间复杂度是 n 2 n^2 n2,研究人员常采用快速的近似 KNN 算法。属性图是基于 S A S_A SA 构建的加权图。
Step1.2 进行"超图随机游走",得到结构相似矩阵 S T S_T ST
超图跳转矩阵 T T T
在普通图中,随机游走就是从一个节点走到相邻节点。但在超图中,一个超边可以连接多个节点,所以游走过程分成三步:
- 从节点跳到超边: T V T_V TV
- T V T_V TV表示节点跳到超边的概率矩阵
- 每一行表示一个节点 v v v;
- 每一列表示一个超边 e e e;
- T V [ i , e ] : T_V[i , e]: TV[i,e]:节点 v i v_i vi跳到它关联的某条超边 e e e 的概率,公式表达如下:
T V [ i , e ] = H [ e , i ] ∑ e ′ H [ e ′ , i ] = 1 deg ( v i ) 如果 v i ∈ e T_V[i,e] = \frac{H[e,i]}{\sum_{e'} H[e',i] } = \frac{1}{\deg(v_i)} \text{ 如果 } v_i \in e TV[i,e]=∑e′H[e′,i]H[e,i]=deg(vi)1 如果 vi∈e
其中: deg ( v i ) \deg(v_i) deg(vi) 表示节点 V i V_i Vi参与的超边数。
- 从超边到节点: T E T_E TE
T V [ i , e ] = H [ e , j ] ∑ j ′ H [ e , j ′ ] = 1 ∣ e ∣ 如果 v j ∈ e T_V[i,e] = \frac{H[e,j]}{\sum_{j'} H[e,j'] } = \frac{1}{|e|} \text{ 如果 } v_j \in e TV[i,e]=∑j′H[e,j′]H[e,j]=∣e∣1 如果 vj∈e
其中: ∣ e ∣ |e| ∣e∣ 表示超边 e e e 包含的节点数量。
- 最终构造出超图跳转矩阵 T : T: T:
T = T V × T E T = T_V \times T_E T=TV×TE
结构相似矩阵 S T S_T ST (Transition Similarity Matrix,TSM):
S T = α ∑ ℓ = 0 γ ( 1 − α ) ℓ T ℓ S_T = \alpha \sum_{\ell=0}^\gamma (1 - \alpha)^\ell T^\ell ST=αℓ=0∑γ(1−α)ℓTℓ
其中:
- α \alpha α:随机游走中"重启"的概率;
- γ = 2 \gamma = 2 γ=2:最多考虑 2 2 2 跳;
- T T T:超图跳转矩阵;
- T ℓ T^\ell Tℓ:从一节点到另一节点正好经过 ℓ \ell ℓ 步的概率。
这个方法保留了超图的高阶连接特性。
Step2: 融合结构和属性得到 相似度矩阵(ISM) S S S
Step2.1 归一化矩阵 S A S_A SA 和 S T S_T ST
S A S_A SA 和 S T S_T ST 的数值范围可能不同,比如一个稀疏一个稠密,为了让两者融合时做出"对等的贡献",我们需要对每个矩阵按行归一化,也就是概率归一化。
归一化公式:
S ^ T [ i , j ] = S T [ i , j ] ∑ k S T [ i , k ] , S ^ A [ i , j ] = S A [ i , j ] ∑ k S A [ i , k ] \hat{S}_T[i, j] = \frac{S_T[i, j]}{\sum_k S_T[i, k]}, \quad \hat{S}_A[i, j] = \frac{S_A[i, j]}{\sum_k S_A[i, k]} S^T[i,j]=∑kST[i,k]ST[i,j],S^A[i,j]=∑kSA[i,k]SA[i,j]
这些归一化结果满足每一行的和为 1,即:
∑ j S T ^ [ i , j ] = 1 , ∑ j S A ^ [ i , j ] = 1 {\sum_j \hat{S_T} [i, j]} = 1,{\sum_j \hat{S_A} [i, j]} = 1 j∑ST^[i,j]=1,j∑SA^[i,j]=1
Step2.2 融合归一化后的矩阵
我们将归一化后的两个矩阵做矩阵乘法,表示在结构路径上传播属性相似性,或者反之。
S ′ = S ^ T ⋅ S ^ A S' = \hat{S}_T \cdot \hat{S}_A S′=S^T⋅S^A
Step2.3 平衡融合结果
如果有些路径过强(可能一端结构或属性权重太大),直接相乘会放大差异,所以我们取平方根作为“soft balance”,来平衡高低值之间的差距,使得 ISM 更稳定、更泛化。
开方公式:
S [ i , j ] = S ′ [ i , j ] S[i, j] = \sqrt{S'[i, j]} S[i,j]=S′[i,j]
最终得到的 S S S 就是 Integrated Similarity Matrix,可用于 Louvain 聚类或对比学习嵌入。
Step3 基于ISM进行聚类
本文设计了一个新的聚类质量评估函数: Integrated Multi-hop Modularity(IMM)。
为什么不使用经典的模块度?
经典图聚类中的模块度 Q Q Q 定义如下:
Q = 1 2 m ∑ i , j ( A [ i , j ] − d i d j 2 m ) δ ( c i , c j ) Q = \frac{1}{2m} \sum_{i,j} \left( A[i,j] - \frac{d_i d_j}{2m} \right) \delta(c_i, c_j) Q=2m1i,j∑(A[i,j]−2mdidj)δ(ci,cj)
其中:
- A [ i , j ] A[i,j] A[i,j]:邻接矩阵;
- δ ( c i , c j ) = 1 \delta(c_i, c_j) = 1 δ(ci,cj)=1,当 i, j 同属于一个簇;
- 缺点:
- 只考虑了“结构”(即邻接矩阵);
- 容易产生 “分辨率限制”:小簇会被合并成大簇,错过细粒度结构;
- 需要手动设定聚类数。
IMM定义
IMM 直接基于综合相似度矩阵 S S S,其核心思想是:比较簇内的“实际相似度”和“期望相似度”之间的差值,越大说明簇划分越显著。
公式:
I M M ( C ) = ∑ C i ∈ C [ ∑ i , j ∈ C i S [ i , j ] ∑ i , j S [ i , j ] − ( ∑ i ∈ C i , j ∈ V S [ i , j ] ∑ i , j S [ i , j ] ) 2 ] IMM(C) = \sum_{C_i \in C} \left[ \frac{\sum_{i,j \in C_i} S[i,j]}{\sum_{i,j} S[i,j]} - \left( \frac{\sum_{i \in C_i, j \in V} S[i,j]}{\sum_{i,j} S[i,j]} \right)^2 \right] IMM(C)=Ci∈C∑
∑i,jS[i,j]∑i,j∈CiS[i,j]−(∑i,jS[i,j]∑i∈Ci,j∈VS[i,j])2
第一项表示簇内实际观察到的相似度比例:
∑ i , j ∈ C i S [ i , j ] ∑ i , j S [ i , j ] \frac{\sum_{i,j \in C_i} S[i,j]}{\sum_{i,j} S[i,j]} ∑i,jS[i,j]∑i,j∈CiS[i,j]
第二项表示在随机条件下,预期的簇内相似度(基于节点度):
( ∑ i ∈ C i , j ∈ V S [ i , j ] ∑ i , j S [ i , j ] ) 2 (\frac{\sum_{i \in C_i, j \in V} S[i,j]}{\sum_{i,j} S[i,j]})^2 (∑i,jS[i,j]∑i∈Ci,j∈VS[i,j])2
使用Louvain算法优化IMM
IMM 是可被 Louvain 聚类算法直接最大化的目标函数。Louvain 是一种快速、贪心的模块度最大化方法,流程为:
- 每个节点初始化为一个独立簇;
- 每次移动一个节点到临近簇,若增加模块度则保留;
- 多次合并簇形成层次结构;
- 可自适应选择聚类数,不需要预设 k k k
Step4 对超图进行"稀疏化加速",简化计算:
问题背景: S T S_T ST 计算的开销大
在之前的Step1中,我们通过AHRC的公式计算拓扑相似度矩阵:
S T = α ∑ ℓ = 0 γ ( 1 − α ) ℓ T ℓ S_T = \alpha \sum_{\ell=0}^\gamma (1 - \alpha)^\ell T^\ell ST=αℓ=0∑γ(1−α)ℓTℓ
存在问题:如果 T T T 是稠密的, T 2 T^2 T2、 T 3 T^3 T3 就更稠密;
panning Tree 是连接图中所有节点的最小边集,不形成环。如果图不是连通的,就对每个连通分量生成一棵生成树,这就叫 Spanning Forest(生成森林)。
解决办法:Kruskal算法
1.输入跳转矩阵 T T T,将其对称化:
T s y m = T + T T T_{sym} = T + T^T Tsym=T+TT
2.重复 τ \tau τ 次以下过程:
- 使用 Kruskal 最小生成树算法(MST),在 T s y m T_{sym} Tsym中找出一棵“权重最大”的生成森林 F i F_i Fi;
- 每次生成森林后,把这些边从 T s y m T_{sym} Tsym中移除,避免重复;
3.合并所有森林,得到一个重要边组成的稀疏子图。
F = F 1 ∪ F 2 ∪ . . . ∪ F n F = F_1 \cup F_2 \cup ... \cup F_n F=F1∪F2∪...∪Fn
4.用这个稀疏结构去计算新的 T ′ T' T′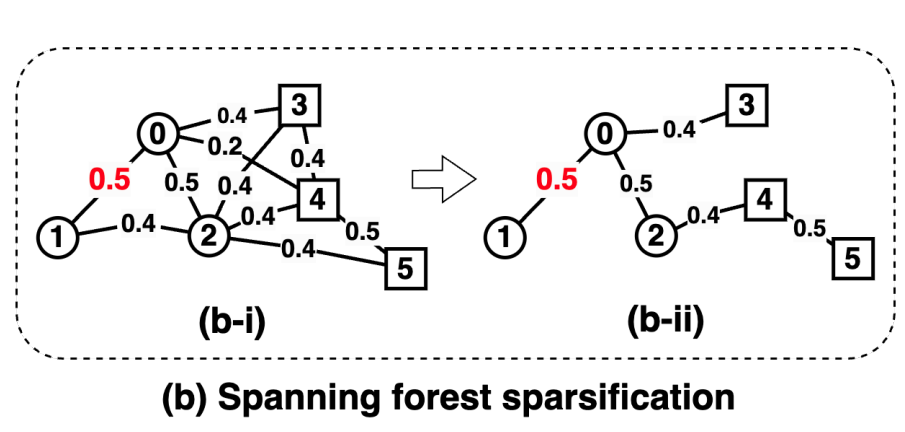
#举例:稀疏化就像是只考虑每个人最信任的几位朋友(权重大的连接),依然能保留网络的大致结构,但大大减少计算量。
Step5 (可选) 将AHRC用于对比学习
功能扩展
在前面的步骤中,AHRC 已经完成了传统意义上的聚类任务:将节点划分为结构 + 属性相似的簇。但在现代图学习领域,节点表示学习也是核心目标,特别是在对比学习方法(如 GRACE、TriCL)中广泛使用。
可以利用AHRC构造出的融合相似度矩阵 S S S,进一步增强GNN对比学习效果。
作者设计了一个新的 GNN 模块 —— AHR Layer,在对比学习模型中作为 Encoder 的一部分。
AHR Layer
- 单节点表示更新形式:
z v ( i ) = f ( z v ( i − 1 ) , { z u ( i − 1 ) ∣ ( u , v ) ∈ E S } ) z^{(i)}_v = f\left(z^{(i-1)}_v, \{z^{(i-1)}_u \mid (u,v) \in E_S\}\right) zv(i)=f(zv(i−1),{zu(i−1)∣(u,v)∈ES})
- z ( i ) : z^{(i)}: z(i):第 i i i 层后节点 v v v 的表示;
- ( u , v ) ∈ E S : (u,v) \in E_S: (u,v)∈ES:表示节点对 u , v u,v u,v在融合图 S S S 中有连接;
- 实际上就是基于 AHRC 得到的相似图进行传播。
- 矩阵形式(GNN 层传播):
Z ( i ) = σ ( D − 1 B Z ( i − 1 ) W ( i ) ) Z^{(i)} = \sigma \left( D^{-1} B Z^{(i-1)} W^{(i)} \right) Z(i)=σ(D−1BZ(i−1)W(i))
- B : B: B:二值化后的 S S S 矩阵;
- D : D: D: B B B的度矩阵;
- W ( i ) : W^{(i)}: W(i):第 i i i 层的可学习权重;
- σ : \sigma: σ:激活函数;
将 AHRC 构造的融合相似度矩阵 S S S,当作“属性+结构”统一图结构输入到 GNN 对比学习模型中,从而提升嵌入表示质量和最终聚类性能。
补充知识
概念
AHC: 带属性超图聚类,是将超图划分为簇,在同一个簇中的节点具有相同的高连通性和同质属性;
AHRC: 用于聚类的带属性超图表示;
Cluster: 图论中,cluster(簇)通常指的是一组相互连接较紧密的节点,与外部节点的连接相对较少。
Clustering: 聚类,是一种无监督学习方法,它的目标是把一组对象(如节点、文档、图像)分成若干“簇”(cluster),使得同一组内的对象尽可能相似,不同组之间的对象尽可能不同;
Clique: 最大的完全子图,全连接的完全子图;
AGC: Attributed Graph Clustering带属性的图聚类;
最大生成森林(MSF):最大生成森林 是一个加权无向图中的一个子图,它是所有连通分量的最大生成树的集合。共有 n−c 条边 (n:节点数,c:连通分量数)
涉及的内容

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)