SpringBoot+Vue3毕设实战-基于多种机器学习算法的星体分类系统,又名:巧夺天工
随着天文观测技术的飞速进步和数据量的激增,传统的数据处理方法已难以满足需求。本研究开发了一种面向非技术人员的星体分类系统,该系统基于多种机器学习算法,采用B/S架构实现。前端使用Vue.js开发,后端则基于Spring Boot框架,并整合了多种机器学习模型进行数据分析。用户可通过Web浏览器上传数据集和算法,自由选择进行星体分类。一个大四学生的毕业设计。
一、项目背景与目标
1. 项目背景
随着天文观测技术的飞速进步和数据量的激增,传统的数据处理方法已难以满足需求。本研究开发了一种面向非技术人员的星体分类系统,该系统基于多种机器学习算法,采用B/S架构实现。前端使用Vue.js开发,后端则基于Spring Boot框架,并整合了多种机器学习模型进行数据分析。用户可通过Web浏览器上传数据集和算法,自由选择进行星体分类。
于是乎,我在大四做的毕业设计实现了这个系统。
2. 项目目标
通过本系统,非技术人员可以方便地进行星体分类和探索,无需具备专业的机器学习知识和技能。这一点为天体物理研究和教学提供了一种便利且高效的工具,有助于用户深入了解星体的特性。系统的便携性和易用性允许用户在不同的设备上使用,从而进一步提高了数据的可访问性和可分享性。总而言之,该研究致力于将机器学习算法与非技术人员的需求相结合,开发出一个易于使用和便携的星体分类系统,通过优化用户界面和提供展示模块,该系统使非专业用户能够轻松地进行星体分类和探索,并促进了天体物理研究和教学的发展。
二、技术栈与工具
本系统是一个通过采用B/S模式的机器学习算法系统。前后端分离,采用流行的开发工具Spring Boot和Vue框架,提供了丰富的功能和良好的生态系统。数据存储部分采用MySQL,是一种常见的关系型数据库管理系统。后端Java核心业务逻辑采用Java脚本执行Python机器学习算法模型进行分类和预测。
- Java
- Python
- Spring Boot
- Vue3
- MySQL
- Element
- Ajax
- Mybatis Plus
- Vue Router
三、项目实施过程
1. 需求分析
(一) 系统首页:用户允许查看公开的数据集和核心算法和概览天文数据分析结果。
(二) 个人中心:用户许可修改个人账号密码,或管理自己的数据、数据集和核心算法。
(三) 数据统计:用户许可查看所有收集和处理的星体数据或者个人的查询历史。
(四) 可视化图表:用户可以查看各类星体与其光谱特征、亮度等属性之间的可视化图表。
(五) 类型预测和算法评估:用户可以通过选择不同的特征参数和机器学习模型来预测星体类型和对算法进行评估。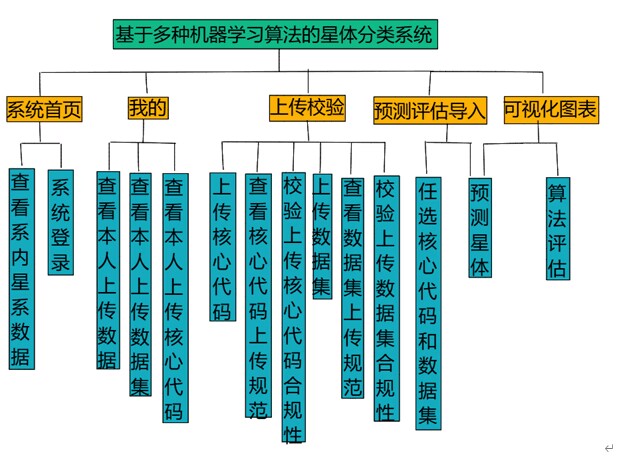
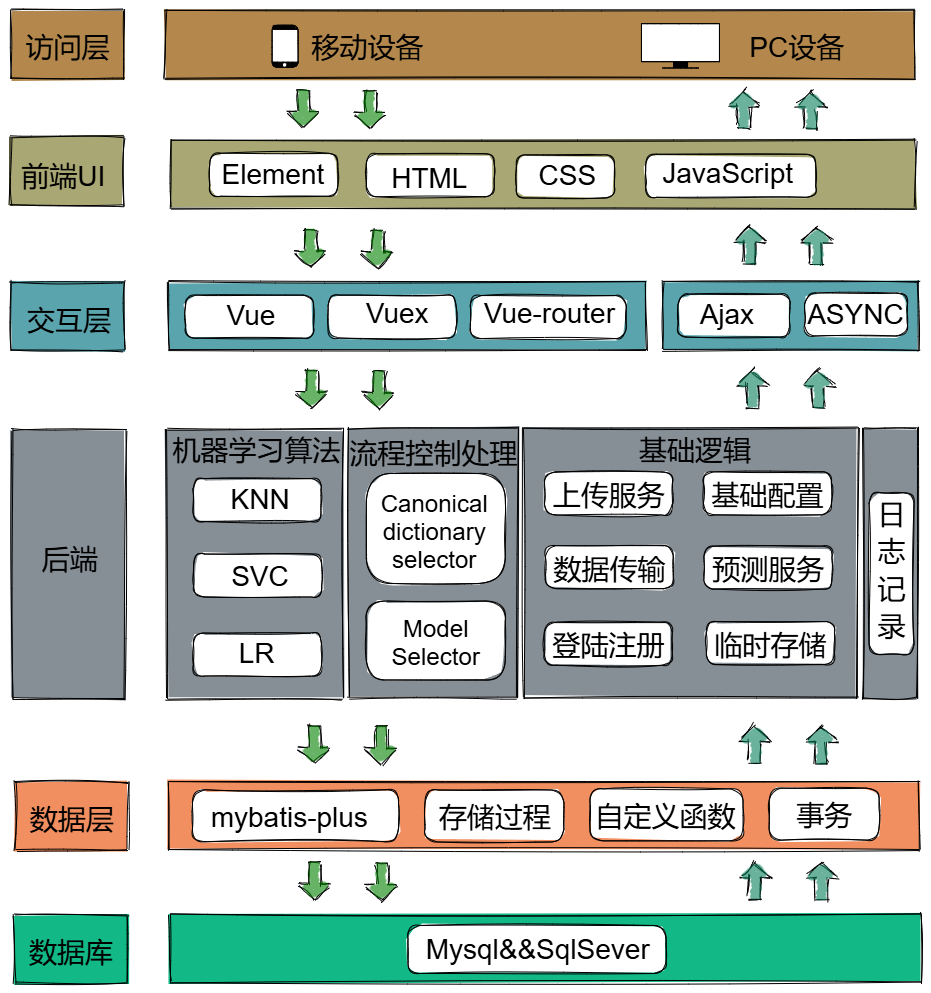
2. 架构设计
本星体分类系统采用分层架构设计,分为数据层、业务逻辑层和表示层,以支持高效的数据处理、灵活的业务实现和动态的用户交互。
数据层: 使用MySQL数据库管理系统存储所有应用数据。数据库设计遵循规范化原则,以减少数据冗余和提高数据完整性。数据层主要负责数据的持久化,包括用户数据、星体数据及分析结果等。
业务逻辑层: 由Spring Boot框架实现,负责处理应用的核心功能,如数据处理、算法执行和结果评估。此层解耦了数据访问和用户界面,确保系统的灵活性和可扩展性。
表示层: 前端使用Vue.js结合Element框架构建,提供响应式的Web界面。用户可以通过这个界面上传数据集,选择分析算法,查看处理结果,并进行交互式的数据探索。
3. 数据库设计
本星体分类系统采用MySQL作为其后端数据库,利用Navicat Premium这一图形化界面工具完成数据库的创建和开发工作。后端采用Spring Boot框架,该框架提供了一个统一的API,能够通过JPA(Java Persistence API)实现实体对象与数据库的交互。这使得开发过程中可以通过Java对象来操作数据库,而无需编写繁琐的SQL语句,简化了后端逻辑的开发和维护。
通过结合这些工具和框架,系统可以高效地管理和查询数据,支持复杂的数据处理流程,如星体数据的清洗、特征提取、以及机器学习模型的训练和预测。此外,Navicat Premium提供了便利的数据库管理和优化工具,可以帮助开发者更容易地进行数据库设计,监控性能,并进行故障排除。
本系统的E-R图如图所示。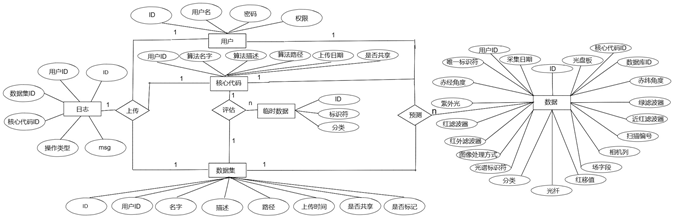
4. 数据表设计
本系统根据实际需求,在MySQl数据库中建立了六张数据表,这六张数据表分别为用户表user,日志表log,数据表data,临时数据表putresult,数据集表datasets,核心算法表corecodes。
4.1 用户表
负责存储系统用户的基本信息,包括他们的身份验证和权限数据。这使得系统能够管理用户访问和执行特定功能。
| 段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 用户的唯一标识符 | |
| name | varchar | 255 | 是 | NULL | 用户的姓名 |
| password | varchar | 255 | 是 | NULL | 用户的密码 |
| role | int | 是 | NULL | 用户的角色标识 |
4.2 临时数据表
临时数据表是一个临时存储表,用于记录数据分析过程中产生的中间结果。该表主要用于存储每次运行的唯一标识和分类结果,以便进行进一步的分析或最终的数据整合。
| 字段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 结果的唯一标识符 | |
| runid | varchar | 255 | 是 | NULL | 运行编号 |
| classa | varchar | 255 | 是 | NULL | 分类结果 |
4.3 数据表
数据表存储关于天体观测对象的核心数据,包括其观测特性和分类相关的信息。这个表是系统中的关键组成部分,用于存储从多个天体观测数据库收集来的详细天体数据。
| 字段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 唯一标识符 | |
| userid | int | 是 | NULL | 关联用户ID | |
| corecodeid | int | 是 | NULL | 关联核心代码ID | |
| datasetid | int | 是 | NULL | 关联数据集ID | |
| objid | varchar | 255 | 是 | NULL | SDSS图像目录中的唯一标识符 |
| alpha | double | 是 | NULL | 赤经角度(J2000时代) | |
| delta | double | 是 | NULL | 赤纬角度(J2000时代) | |
| u | double | 是 | NULL | 紫外光学系统中的滤波器读数 | |
| g | double | 是 | NULL | 光学系统中的绿色滤波器读数 | |
| r | double | 是 | NULL | 光学系统中的红色滤波器读数 | |
| i | double | 是 | NULL | 光学系统中的近红外滤波器读数 | |
| z | double | 是 | NULL | 光学系统中的红外滤波器读数 | |
| runid | int | 是 | NULL | 用于标识特定扫描的运行编号 | |
| rereunid | int | 是 | NULL | 重新运行编号 | |
| camcol | varchar | 255 | 是 | NULL | 用于运行内标识扫描线的相机列 |
| fieldid | int | 是 | NULL | 用于标识每个场的字段编号 | |
| specobjid | varchar | 255 | 是 | NULL | 用于光谱对象的唯一标识符 |
| classa | varchar | 255 | 是 | NULL | 对象类别 |
| redshift | double | 是 | NULL | 基于波长增加的红移值 | |
| plate | varchar | 255 | 是 | NULL | 标识SDSS中的每个光谱板 |
| mjd | varchar | 255 | 是 | NULL | 修改的儒略日 |
| fiberid | int | 是 | NULL | 指示光线指向焦平面的光纤 |
4.4 日志表
日志表用于记录系统中用户的活动,如注册、上传数据集、上传核心算法等。这些日志信息对于监控系统的使用情况、审计和故障排查非常有用。
| 字段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 唯一标识符 | |
| userid | int | 是 | NULL | 用户ID | |
| corecodeid | int | 是 | NULL | 核心代码ID | |
| datasetid | int | 是 | NULL | 数据集ID | |
| type | int | 是 | NULL | 操作类型 | |
| msg | varchar | 255 | 是 | NULL | 附加消息 |
4.5 数据集表
数据集表负责存储关于天体数据集的详细信息,这些数据集由用户上传并用于系统中的分析和分类任务。
| 字段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 唯一标识符 | |
| userid | int | 是 | NULL | 用户的ID | |
| datasetname | varchar | 255 | 是 | NULL | 数据集名称 |
| datasetdescription | varchar | 255 | 是 | NULL | 数据集描述 |
| filepath | varchar | 255 | 是 | NULL | 文件路径 |
| Uploaddate | datetime | 是 | NULL | 上传日期 | |
| isshared | int | 是 | NULL | 是否共享 | |
| ifclass | int | 是 | NULL | 是否已分类 |
4.6 核心代码表
核心代码表在系统中用于存储与用户上传的核心代码相关的信息。这些代码通常是由用户提供,用于在系统中执行特定的数据处理或分析任务。
| 字段名 | 类型 | 长度 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|---|
| id | int | 是 | NULL | 唯一标识符 | |
| userid | int | 是 | NULL | 用户ID | |
| codename | varchar | 255 | 是 | NULL | 代码名称 |
| codedescription | varchar | 255 | 是 | NULL | 代码描述 |
| codefilepath | varchar | 255 | 是 | NULL | 文件路径 |
| uploaddate | datetime | 是 | NULL | 上传日期 | |
| Isshared | int | 是 | NULL | 是否共享 |
四、具体实现
1. 系统注册登录功能实现
普通用户和管理员进行登录注册,二者需要选择不同身份,因为普通用户和管理员实体属性的role不同,对于用户输入的账号密码与本实体相关的表进行判断和验证。

用户填写对应的用户名和密码以及密码确认以后选择对应的身份后可以进行相关的用户信息的注册。注册后在登录时进行逻辑验证判断。对应的用户注册代码如下:
public Result<?> register(@RequestBody User user){
//注册之前先验证是否有重名
User res = userMapper.selectOne(Wrappers.<User>lambdaQuery().eq(User::getName, user.getName()));
//判断查询是否存在
if (res != null)
{
eturn Result.error("-1", "用户名已存在!");
}
//默认密码
if (user.getPassword() == null)
{
user.setPassword("123456");
}
user.setRole(2);
userMapper.insert(user);
return Result.success();
}
用户在注册完成以后,选择当前普通身份以后可以进行登录操作,登录完成以后,验证当前登录的用户useranme是否和数据库中的用户账号相匹配,若匹配,则验证密码是否相同。
2. 三种数据查询功能实现
实现对数据、数据集、核心算法的全查询,并在前端页面分页展示,并在前端代码里实现限制输出,以此实现仅当前用户的个人数据、数据集、核心算法展示,同时在前端界面限制用户权限,使只有管理员用户才能进行操作全部数据。此处展示datasets库的查询,其它两种雷同。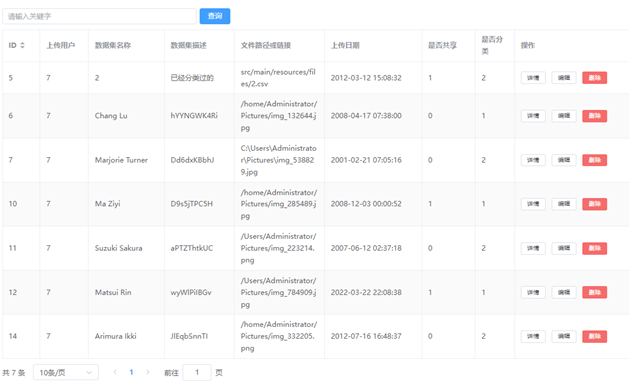
核心代码如下:
前端代码:
function handleResponse(response) {
const { code, msg } = response;
const messageType = code === '0' ? 'success' : 'error';
const messageText = code === '0' ? "更新成功" : msg;
this.$message({
type: messageType,
message: messageText
});
}
// 使用定义好的函数
if (this.form.id) { // 如果需要更新
request.put("/datasets", this.form).then(response => {
handleResponse.call(this, response);
});
}
后端代码:
LambdaQueryWrapper<Datasets> wrapper = Wrappers.<Datasets>lambdaQuery();
if (StrUtil.isNotBlank(search)){
wrapper.like(Datasets::getDatasetname, search);
}
if (userid != 0) {
wrapper.eq(Datasets::getUserid, userid);
}
Page<Datasets> datasetsPage = datasetsMapper.selectPage(new Page<>(pageNum, pageSize), wrapper);
return Result.success(datasetsPage);
3. 预测和评估功能实现
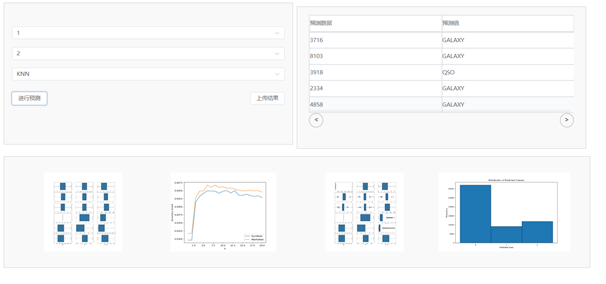
实现任选数据集和任选算法进行训练模型进行算法评估或者对2号数据集分类的操作,当只选择1号数据集,不对二号数据集选择时候,程序会执行对当前算法的评估,如下图的所示,如果1号数据集和2号数据集全选中的时候,会将1号数据集拿来训练模型,来预测未标记的二号数据集。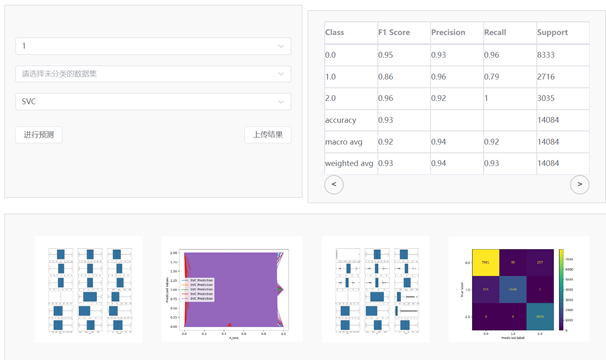
该过程从经历预处理步骤(如数据清理、异常值处理、数据缩放、特征选择和数据集分割)的数据集开始。这些数据集被规范词典选择器选择,标记过的数据集合用于算法评估,未标记的数据用于预测任务。
在算法评估阶段,系统使用 30% 的数据作为测试集来评估不同的机器学习模型,如 KNN(K 最近邻)和 SVC(支持向量分类)。模型经过训练、使用和评估。同时,剩余的 70% 数据用作训练集,应用于选定的机器学习算法模型。
预测分类阶段涉及与初始阶段类似的数据处理,例如清理、缩放和特征选择,然后去标记未标记的数据集。然后,机器学习模型的预测结果以 CSV 文件格式保存,用于在预测应用程序中进一步分析或部署。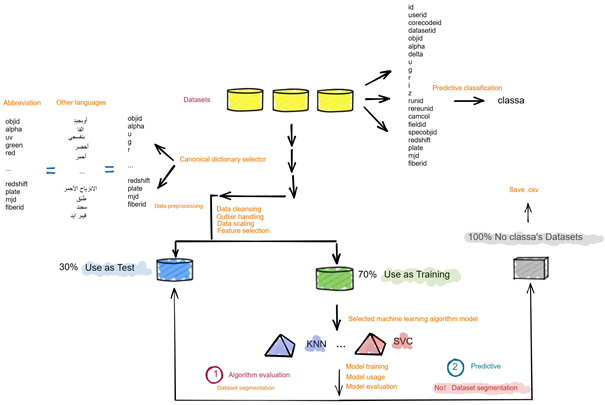
核心代码如下:
前端代码:
let url;
// 检查 selectedUnclassifiedDataset 是否有有效值
if (this.selectedUnclassifiedDataset != null && this.selectedUnclassifiedDataset !== '') {
// 两个数据集 ID 都有效时
url = `/forecast?classifiedId=${encodeURIComponent(this.selectedClassifiedDataset)}&unclassifiedId=${encodeURIComponent(this.selectedUnclassifiedDataset)}&corecodesId=${encodeURIComponent(this.selectedCorecodes)}`;
} else {
// 只有分类数据集和核心代码有效时,不包括 unclassifiedId
url = `/forecast?classifiedId=${encodeURIComponent(this.selectedClassifiedDataset)}&corecodesId=${encodeURIComponent(this.selectedCorecodes)}`;
}
console.log('URL for prediction:', url);
// 使用 GET 请求进行预测
request.get(url)
.then(response => {
if (response.code === "0") {
if (this.selectedUnclassifiedDataset != null && this.selectedUnclassifiedDataset !== '') {
ElMessage.success('分类成功');
this.updatePage("classification", "1");
}
else {
ElMessage.success('评估成功');
console.log('预测结果:', response.msg);
this.updatePage("evaluation", response.data);
}
} else {
ElMessage.error('预测失败: ' + response.msg);
}
})
.catch(error => {
console.error('预测请求失败:', error);
ElMessage.error('预测请求失败');
});
}
后端代码:
ProcessBuilder processBuilder = new ProcessBuilder(command);
processBuilder.environment().put("CONDA_DEFAULT_ENV", "base");
Process process = processBuilder.start();
BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream(), "UTF-8"));
StringBuilder output = new StringBuilder();
String line;
while (true) {
String line = reader.readLine();
if (line == null) break;
output.append(line).append("\n");
}
4. 数据集规范器实现逻辑
对上传的数据集进行检查校验,首先会获取表名的每一个字段,并根据alpha字段进行判别语言,并对其他的进行字典对应,若是不支持的语言,就返回语言不支持的结果。若正常,就进行下一步缺省项判断,若缺省字段为非Class的其他字段,就会返回数据集有缺省的提示,若无异常,则根据是否有Class字段进行数据集类型的分类,然后给数据集添加描述和去寻找本地静态资源地址,发送给后端并保存。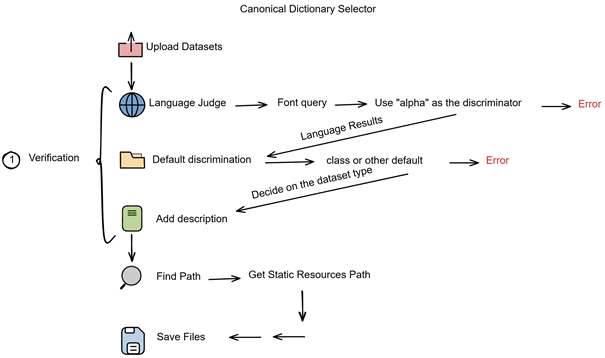
5. 上传页面功能实现
对于用户想自主上传数据集和核心算法,用户可以点击选择文件打开本地文件,然后点击校验文件,会触发数据集规范器或者核心算法规范器,然后返回相应的结果。若无异常,用户可以上传自己的数据集或者核心算法,并添加描述到服务器中。
实现代码如下:
前端代码:
<div class="home" style="display: flex; justify-content: space-between; padding: 10px;">
<!-- 左侧区域 -->
<div class="left-section" style="width: 48%; padding: 20px; border: 1px solid #ccc; box-shadow: 0 2px 5px rgba(0,0,0,0.1);">
<h3>数据集上传</h3>
<div>
<el-input v-model="datasetName" placeholder="文件名称将在这里显示" readonly></el-input>
<el-upload
class="upload-demo"
:http-request="uploadFile('dataset')"
:file-list="datasetList"
:before-upload="beforeUpload">
<el-button type="primary">选择数据集文件</el-button>
</el-upload>
<el-button type="primary" @click="validateFile('dataset')">校验数据集</el-button>
<el-button type="primary" @click="submitFile('dataset')">上传数据集</el-button>
</div>
</div>
<!-- 右侧区域 -->
<div class="right-section" style="width: 48%; padding: 20px; border: 1px solid #ccc; box-shadow: 0 2px 5px rgba(0,0,0,0.1);">
<h3>核心算法上传</h3>
<div>
<el-input v-model="operationName" placeholder="文件名称将在这里显示" readonly></el-input>
<el-upload
class="upload-demo"
:http-request="uploadFile('operation')"
:file-list="operationList"
:before-upload="beforeUpload">
<el-button type="primary">选择核心算法</el-button>
</el-upload>
<el-button type="primary" @click="validateFile('operation')">校验核心算法</el-button>
<el-button type="primary" @click="submitFile('operation')">上传核心算法</el-button>
</div>
</div>
</div>
</template>
后端代码:
public void uploadFile(MultipartFile file, String subDir) throws IOException {
String directory = BASE_PATH + subDir + "/";
createDirectory(directory);
String path = generateFilePath(directory, file);
saveFile(file, path);
}
private void createDirectory(String path) {
FileUtil.mkdir(path);
}
private String generateFilePath(String directory, MultipartFile file) {
return directory + IdUtil.fastSimpleUUID() + "_" + file.getOriginalFilename();
}
private void saveFile(MultipartFile file, String path) throws IOException {
FileUtil.writeBytes(file.getBytes(), path);
}
public void downloadFile(String flag, HttpServletResponse response) throws IOException {
String filename = findFileByName(flag);
if (!filename.isEmpty()) {
byte[] data = readFileBytes(filename);
writeFileToResponse(data, filename, response);
}
}
private String findFileByName(String nameFragment) {
return FileUtil.listFileNames(BASE_PATH).stream()
.filter(name -> name.contains(nameFragment))
.findAny()
.orElse("");
}
private byte[] readFileBytes(String filePath) throws IOException {
return FileUtil.readBytes(BASE_PATH + filePath);
}
private void writeFileToResponse(byte[] data, String filename, HttpServletResponse response) throws IOException {
response.getOutputStream().write(data);
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(filename, "UTF-8"));
response.setContentType("application/octet-stream");
}
public void sendImage(String imageName, HttpServletResponse response) throws IOException {
String imagePath = generateImageFilePath(imageName);
if (FileUtil.exist(imagePath)) {
byte[] imageBytes = FileUtil.readBytes(imagePath);
sendImageData(imageBytes, imageName, response);
}
}
private String generateImageFilePath(String imageName) {
return BASE_PATH + imageName + ".png";
}
private void sendImageData(byte[] imageData, String imageName, HttpServletResponse response) throws IOException {
response.getOutputStream().write(imageData);
response.setContentType("image/png");
response.setHeader("Content-Disposition", "inline; filename=" + imageName + ".png");
}
6. 核心算法规范器实现逻辑
在用户上传自己的核心算法,并点击校验之后,系统会自己把当前的核心算法上传到服务器中,进行一个简单的数据集跑一下预测功能,检测是否能正常运行,有异常就会退回。若正常运行,则检查生成文件是否正常,若有异常则返回异常,无异常返回正常。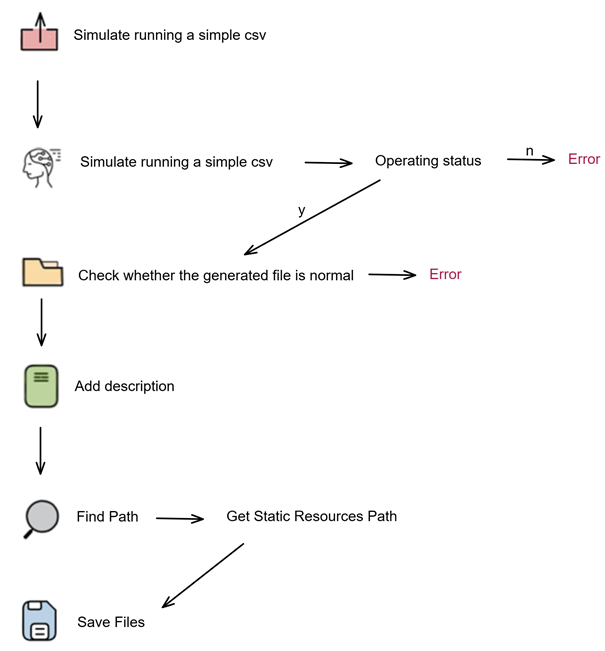
五、个人收获与心得体会
在完成这个巧夺天工系统的毕业设计过程中,我获得了不仅仅是编程技能的提升,更多的是对整个软件开发生命周期的深入理解,以及在解决复杂问题时的系统思维能力的增强。
技术技能的提升
通过这个项目,我深入学习了Java和Python两种编程语言,并实际应用了Spring Boot, Vue.js, MySQL等技术。这些都是目前极为流行且实用的技术栈,未来无论是在求职还是实际工作中,这些技能都将极大地增加我的竞争力。此外,通过整合Java和Python进行机器学习模型的调用和数据处理,我也对如何在不同编程语言和框架间进行高效的数据交互有了更深的理解。
解决问题的能力
在开发过程中,我遇到了各种各样的挑战,例如数据预处理的复杂性,机器学习模型的选择和调优,以及前后端的数据同步问题。每一个挑战都需要我不仅仅依赖已有的知识,更多的是需要进行创新思考和快速学习新知识。这种持续的问题解决过程,极大地锻炼了我的独立思考和自我学习能力。
对未来的展望
通过这个项目,我不仅仅看到了自己能力的提升,更看到了技术在天文学领域的广阔应用前景。未来,我希望能继续在这种跨领域发展,可能的话,进一步研究如何将更多先进的机器学习技术应用于其他各个方面的处理和分析中,以揭示宇宙中更多未知的奥秘。
这个项目不仅仅为我打开了这种新领域的大门,更激发了我对知识探索的无限热情。我期待将来能将这种热情和能力,转化为更多实际的技术成果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)