创新实训(六)——实现基于DeepSeek的辩论会话的记录与管理功能
之前已经实现了在项目中接入DeepSeek API并能够与其进行基础的辩论对话,但是我发现DeepSeek API并没有上下文记忆功能,缺乏对历史会话的记录与管理功能。这种限制使得DeepSeek在辩论中无法关联之前的会话内容进行辩论,也无法在后续的对话中基于历史数据进行更深入的记录与分析。为了解决这一问题,为辩论助手增加会话记录和上下文关联功能显得尤为重要。本周的任务是实现辩论会话的记录与管理功
之前已经实现了在项目中接入DeepSeek API并能够与其进行基础的辩论对话,但是我发现DeepSeek API并没有上下文记忆功能,缺乏对历史会话的记录与管理功能。这种限制使得DeepSeek在辩论中无法关联之前的会话内容进行辩论,也无法在后续的对话中基于历史数据进行更深入的记录与分析。为了解决这一问题,为辩论助手增加会话记录和上下文关联功能显得尤为重要。
本周的任务是实现辩论会话的记录与管理功能,记录完整辩论流程,将历史会话融入大模型Prompt,支持会话回溯与持续对话,查看辩论记录等功能。
目录
一、实现思路
在实现功能前,我首先设计了一套该功能的合理且可靠的实现流程,流程图如下图所示。
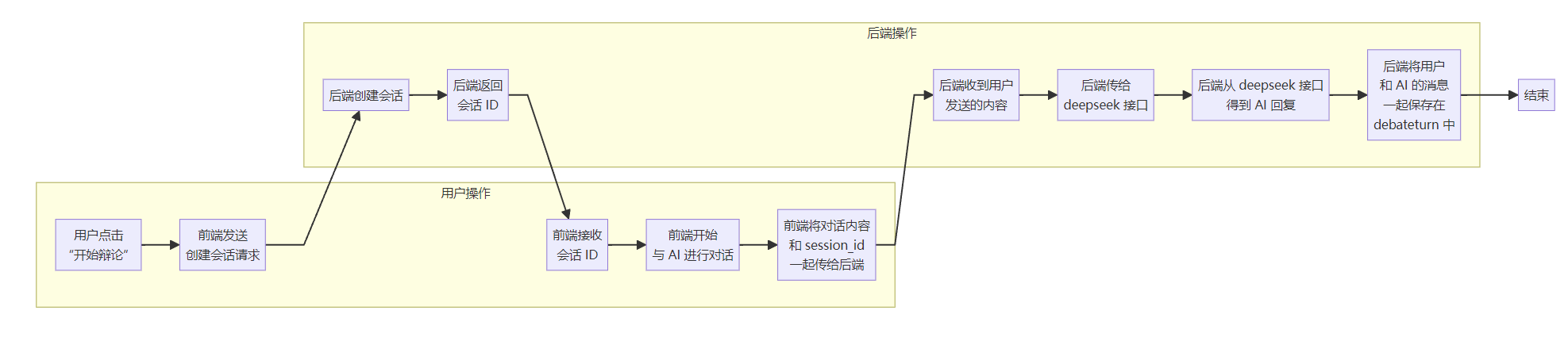
二、辩论记录实现过程
1. 后端实现
我之前在数据库模型建立的时候,创建了两个模型,一个是debate_session,用于存储一个完整的辩论过程,其具体属性如下表所示。
| 字段名 | 字段描述 | 数据类型 |
|---|---|---|
| id | 辩论会话唯一标识 | uuid |
| user_id | 发起辩论会话的用户标识 | uuid |
| topic | 辩论话题 | string |
| position | 用户在辩论中的立场 | enum |
| result | 辩论结果 | enum |
| created_at | 辩论会话创建时间 | datetime |
同时,我还创建了debate_turn,用于存储一个会话中的每一回合的内容,其具体属性如下表所示。
| 字段名 | 字段描述 | 数据类型 |
|---|---|---|
| id | 辩论轮次唯一标识 | uuid |
| session_id | 辩论轮次所属的会话标识 | uuid |
| speaker | 发言人(AI或user) | string |
| content | 该轮次的发言内容 | longtext |
| turn_index | 轮次序号 | enum |
| timestamp | 发言时间戳 |
datetime |
首先,在保存辩论轮次之前,首先要创建一个辩论会话,并返回给前端,以便于前端同发送的内容一起发送给后端,在存储debate_turn的时候同时保存session_id。创建辩论的会话方法可以直接使用之前为数据库模型创建的CRUD接口方法:
@router.post("/", response_model=DebateSessionPublic)
def create_debate_session(
*, session: SessionDep, current_user: CurrentUser, item_in: DebateSessionCreate
) -> Any:
debate = DebateSession.model_validate(item_in, update={"user_id": current_user.id})
session.add(debate)
session.commit()
session.refresh(debate)
return debate
先前已经实现了websocket连接的对话接口方法,现在需要对方法进行改造,在每次用户发言和AI发言后,将二者的发言内容存入debate_turn中,具体实现如下。在api地址中,加入session_id,以便在前端发起请求的时候一同传回本会话的id,表明该轮次的对话属于哪个session_id。另一改动是在回复的过程中,由于是流式生成回复,因此需要对完整的回复内容进行收集,将最终的结果存入内容中。
@router.websocket("/stream/{session_id}")
async def websocket_chat(websocket: WebSocket, session_id: str, session: SessionDep):
await websocket.accept()
try:
while True:
data = await websocket.receive_text()
message = json.loads(data)
# 发送开始信号
await websocket.send_json({
"type": "start",
"content": ""
})
ai_response = ""
# 流式生成响应
async for chunk in llm_streamer(message["message"]):
ai_response += chunk # 收集完整回复
await websocket.send_json({
"type": "stream",
"content": chunk
})
# 发送结束信号
await websocket.send_json({
"type": "end",
"content": ""
})在AI内容生成结束后,对对话记录进行保存。首先根据session_id查询目前的轮数,从而确定turn_index属性的值。在下面分别保存user_turn和ai_turn对象,实现辩论轮次的内容的保存。
with session.begin():
stmt = select(func.count()).select_from(DebateTurn).where(DebateTurn.session_id == uuid.UUID(session_id))
result = session.execute(stmt)
turn_count = result.scalar_one() # 当前已有的轮数
next_index = turn_count # 新的 user 是第 next_index 条
# 保存聊天记录
user_turn = DebateTurn(
session_id=uuid.UUID(session_id),
speaker="user",
content=message["message"],
turn_index=next_index
)
session.add(user_turn)
ai_turn = DebateTurn(
session_id=uuid.UUID(session_id),
speaker="ai",
content=ai_response,
turn_index=next_index + 1
)
session.add(ai_turn)
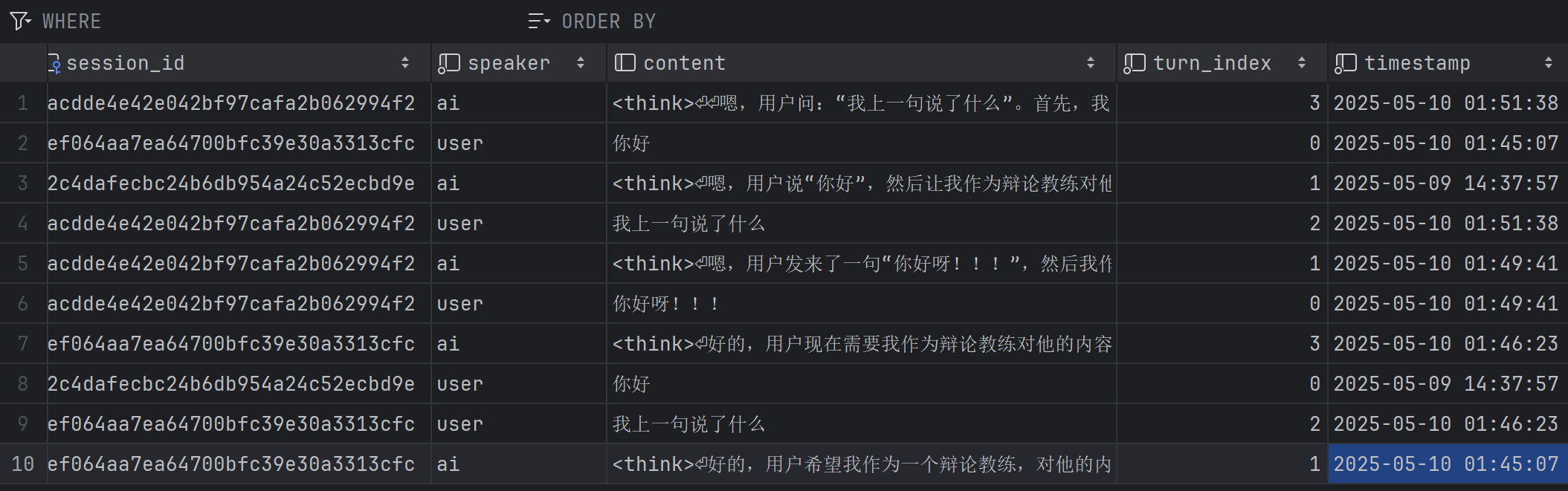
session.commit()在数据库中成功保存用户和ai的会话记录
2.前端实现
对于前端的改动有以下几点:
1. 加入用户身份验证:由于在对websocket接口的调用中无法直接使用之前在http协议中的身份,因此我单独在页面初始化的时候加入身份验证方法,向后端请求身份验证,如果处于未登录状态,则直接跳转道登录界面。
const res = await getUserId();
if (!res) {
alert("未登录或 token 无效");
router.push('/Login')
}2. 在之前的页面中添加了一个“开始辩论”的按钮,输入该次辩论会话的基本信息,点击之后即可调用后端接口创建一个会话,再在对websocket进行初始化,在请求中加入该会话的session_id,即可成功在后端实现辩论记录的保存。
const beginDebate = async () => {
try {
const postData = {
topic: '',
position: '',
result: ''
};
const res = await createSession(postData)
console.log(res)
if (res) {
session_id = res.id
console.log("新会话创建成功:", session_id)
// 初始化 WebSocket
initWebSocket()
} else {
alert("会话创建失败")
}
} catch (err) {
console.error("创建会话失败:", err)
alert("创建会话失败")
}
}三、大模型上下文记忆功能实现
1.具体实现
再次对websocket_chat方法进行改进,本次主要进行了如下改进:
首先根据传入的session_id进行查询,查到所有属于本次会话的轮次,根据轮次序号进行排序以确定内容的顺序,遍历这些轮次,并将内容按照speaker进行区分,分为assistant和user身份加入到messages里,最后加上本轮用户的输入,一起传入到大语言模型中,即可实现大模型的上下文记录功能。
#根据session_id查询本次会话中的会话记录,并按顺序加入到messages中传入大模型
stmt = select(DebateTurn).where(
DebateTurn.session_id == uuid.UUID(session_id)
).order_by(DebateTurn.turn_index)
result = session.exec(stmt)
history_turns = result.all()
messages = [{"role": "system", "content": "你是一个辩论教练,请对user内容进行深度点评,并结合上下文"}]
for turn in history_turns:
role = "assistant" if turn.speaker == "ai" else "user"
messages.append({
"role": role,
"content": turn.content
})
#加入本轮用户的输入
messages.append({
"role": "user",
"content": message["message"]
})2.效果展示
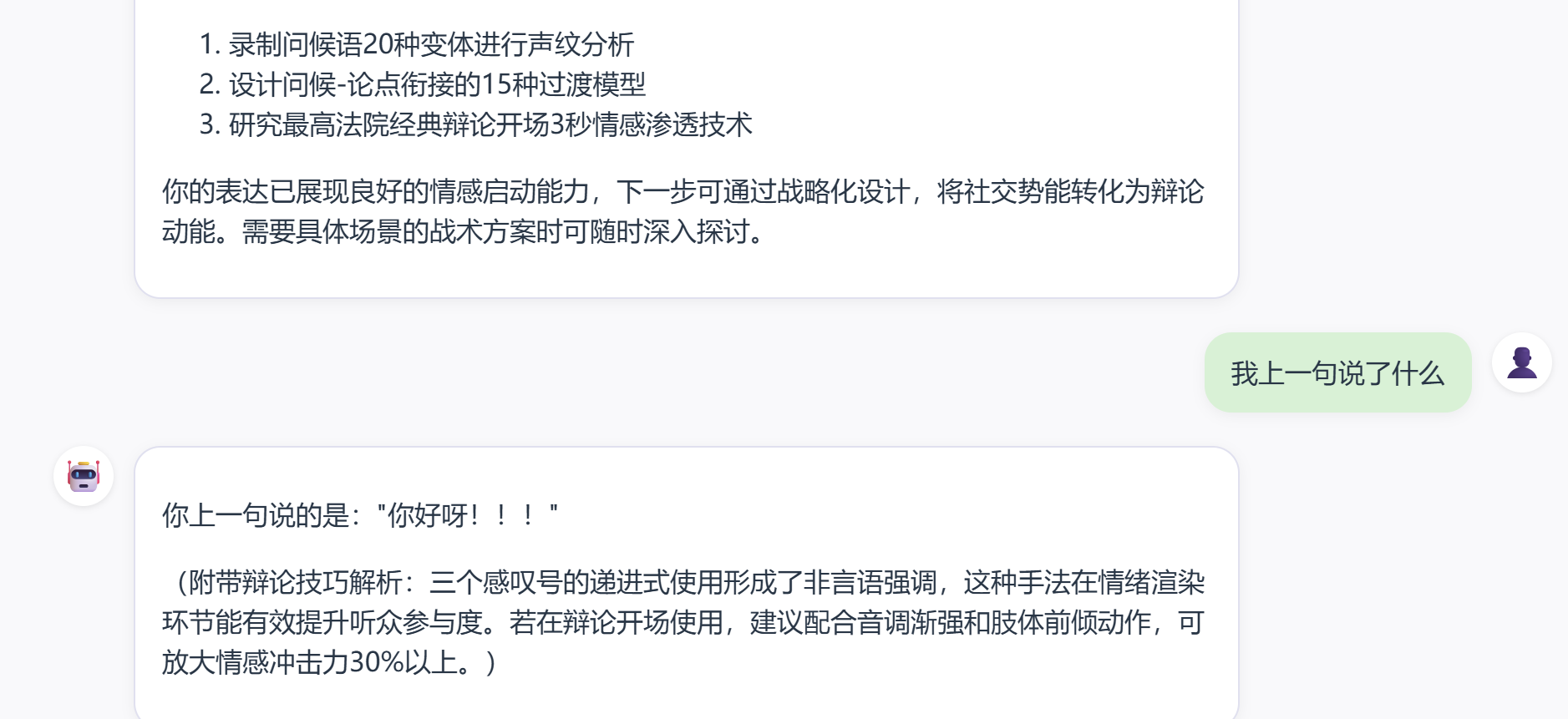
再次在前端进行对话测试,发现已经能够实现对于会话的上下文记忆功能,大模型可以根据我之前的所有会话内容来完成整体的评价。
四、问题解决
1.content内容过长问题
报错如下:
Error: 处理错误: (pymysql.err.DataError) (1406, "Data too long for column 'content' at row 2")
[SQL: INSERT INTO debate_turns (id, session_id, speaker, content, turn_index, timestamp) VALUES (%(id)s, %(session_id)s, %(speaker)s, %(content)s, %(turn_index)s, %(timestamp)s)]
[parameters: [{'id': '0cb0a6e98ce84e63aecbb992a211907e', 'session_id': '8ebe527c0e744fc2a1cdcbb90b8e3ea0', 'speaker': 'user', 'content': '你好', 'turn_index': 0, 'timestamp': datetime.datetime(2025, 5, 9, 14, 32, 29, 619956)}, {'id': '659d3d8e53974545b898bf3c3c537662', 'session_id': '8ebe527c0e744fc2a1cdcbb90b8e3ea0', 'speaker': 'ai', 'content': '<think>\n好的,用户现在需要我作为辩论教练对他的内容进行全方位智能点评。首先,我要仔细分析他的需求。他可能希望得到专业的反馈,帮助他提升辩论技巧。但用户目前只发送了“你好”,可能还没有提供具体内容。这时候,我需要先确认他是否有具体的辩论内容需要点评,比如辩论稿、论点或者某个辩题的想法。\n ... (1038 characters truncated) ... 多元(统计数据、类比推理、归谬法、诉诸权威的平衡使用) \n- **What层**:语言是否达到“锐度与温度并存”(例:用“数字难民”替代“弱势群体”增强画面感) \n\n请提供具体内容,我将结合国际辩论赛评审标准(如WSDC/WUDC评分体系)为您生成带改进方案的诊断报告。期待您的详细论述!', 'turn_index': 1, 'timestamp': datetime.datetime(2025, 5, 9, 14, 32, 29, 620677)}]]
(Background on this error at: https://sqlalche.me/e/20/9h9h)
socket.onmessage @ ChatPage.vue:152根据报错内容不难看出,本错误是由于content属性data too long,即ai生成的内容已经超过了varchar(255)的长度限制,因此无法成功保存。
MySQL中字符串类型及最大长度
CHAR: 固定长度的字符串类型。最大长度为255字节。如果使用多字节字符集(如UTF-8),实际可存储的字符数会减少。
VARCHAR: 可变长度的字符串类型。最大长度为65535字节。同样,实际可存储的字符数取决于所使用的字符集。
TEXT: 用于存储长文本数据。有三种类型:
TINYTEXT(最大长度为255字节)、TEXT(最大长度为65535字节)和LONGTEXT(最大长度为4294967295字节)。
考虑到后续还需要加入RAG内容以及更多prompt工程,可能造成DeepSeek输出更多内容,在此直接使用LongText进行对话内容的存储。
2.保存的时间与实际时间不符
当前获取时间的语句如下
created_at: datetime = Field(default_factory=datetime.utcnow)
出现这一问题的原因是使用 datetime.utcnow() 作为默认工厂时会出现时区不匹配的问题,因为 utcnow() 返回的是UTC 时间(协调世界时),而不是本地时间。因此只需要将utcnow改为now即可成功保存当地当前时间。
datetime.utcnow():返回 当前的 UTC 时间
datetime.now():返回 当前本地时间(依赖操作系统时区)
五、前端对话界面完善
1. 过滤去除思考过程
DeepSeek-R1模型的特色是先思考后回答,辩论过程中也需要推理过程,但是冗长的思考过程输出会影响用户的辩论体验,因此我需要将思考部分过滤掉,只输出内容部分。
分析发现,思考过程使用<think></think>标签包围,且开始和结束标签在websocket传输时都独占一个token,因此我可以根据收到的token是否为<think>来控制思考过程的输出。
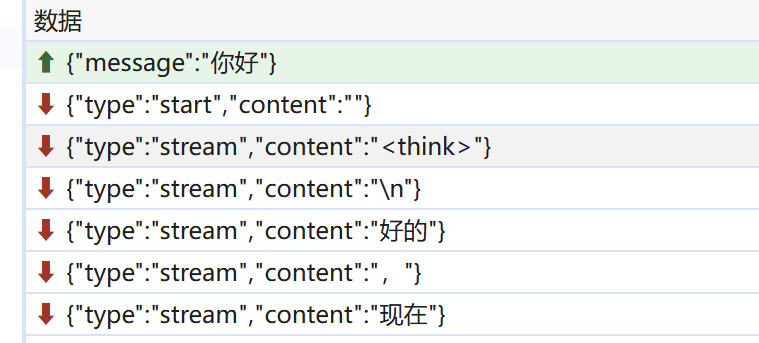

在代码中通过一个bool类型的inThinkBlock属性进行控制。
// 检测 <think> 标签开始
if (token.includes('<think')) {
inThinkBlock = true
}
// 如果不在 think block 内则显示
if (!inThinkBlock) {
lastMessage.chunks.push(token)
lastMessage.content = lastMessage.chunks.join('')
scrollToBottom()
}
// 检测 </think> 标签结束
if (token.includes('</think>')) {
inThinkBlock = false
}2.输出内容格式美化
在之前的对话效果中,AI输出的内容为markdown形式,而前端没有对形式的控制,导致各种markdown格式都被输出,输出显示十分混乱。为了提升 AI 回复内容在前端的可读性与美观性,我对原有的输出格式进行了优化。
为了解决这一问题,我引入了 marked 这一轻量级、功能强大的 Markdown 解析器库。该库能够将 Markdown 格式的文本可靠地转换为 HTML,从而便于在页面中以样式化形式渲染。
<div class="content">
<div v-html="renderMarkdown(message.content)"></div>
<span v-if="message.loading" class="cursor">▎</span>
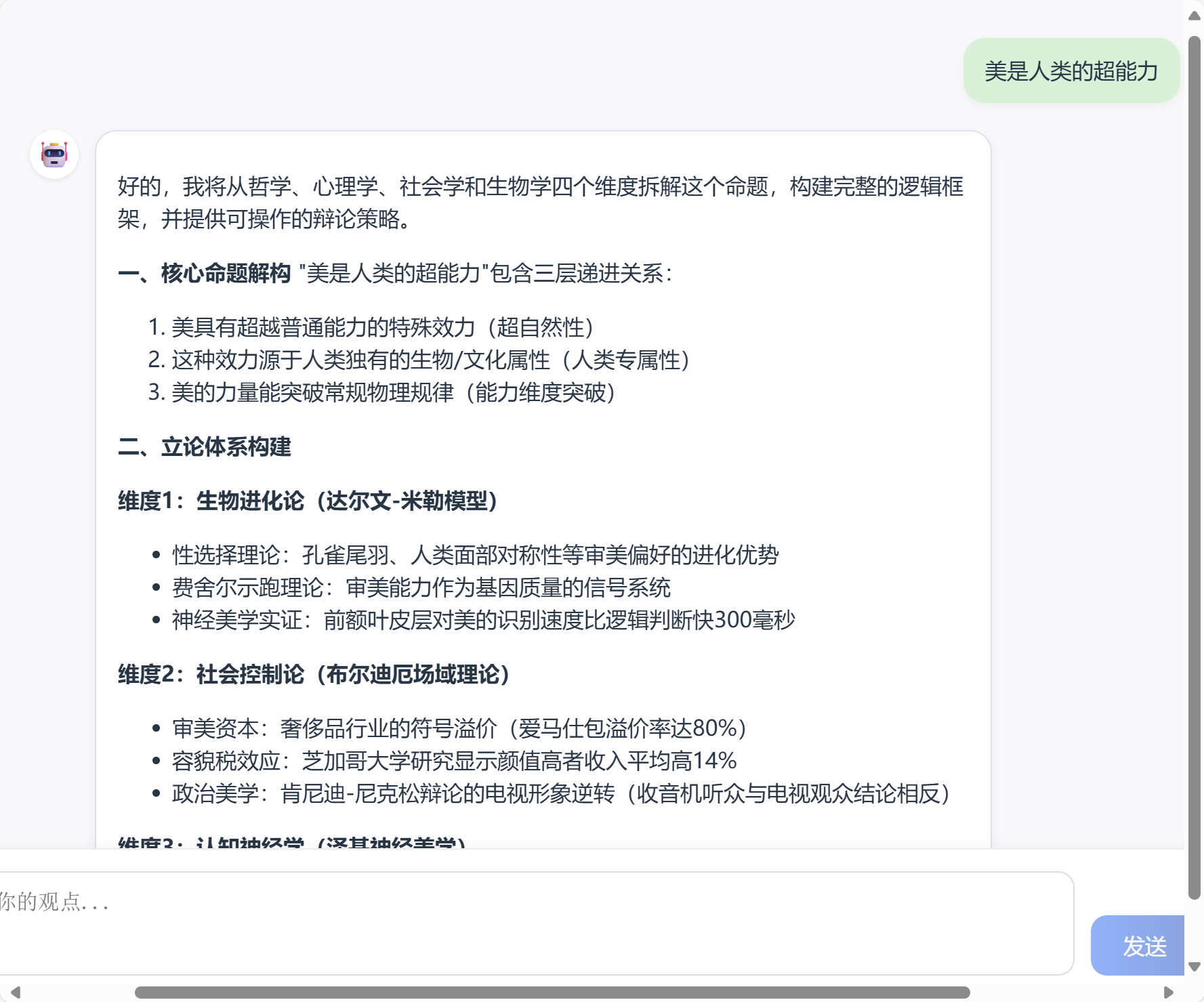
</div>美化后效果如下图所示,界面美观且富有条理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)