# RAG 框架 | 技术栈 #一文读懂Xinference架构!优秀开源项目技术栈分析
Xinference是一个利用actor编程框架Xoscar来管理机器、设备和模型推理进程的系统。每个actor都是模型推理的基本单元,可以集成多种推理后端。它支持多种推理引擎和硬件,并且具有异步和非阻塞的特性。:使用FastAPI实现,提供了一个示例API/status对应函数get_status。命令行:通过Click实现,允许用户在终端与Xinference进行交互。提供了几个命令行工具,如
这是原文内容
这是知识点解读
一、概述
Xinference是一个利用actor编程框架Xoscar来管理机器、设备和模型推理进程的系统。每个actor都是模型推理的基本单元,可以集成多种推理后端。它支持多种推理引擎和硬件,并且具有异步和非阻塞的特性。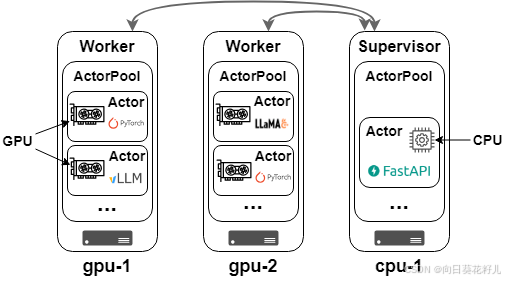
-
RESTful API:使用FastAPI实现,提供了一个示例API
/status对应函数get_status。 -
命令行:通过Click实现,允许用户在终端与Xinference进行交互。提供了几个命令行工具,如
xinference、xinference-local、xinference-supervisor和xinference-worker。 -
Actor:基于Xoscar框架,可以管理计算资源和Python进程,支持并发编程。提供了一个
WorkerActor的示例。 -
异步编程:Xinference和Xoscar依赖于
asyncio库,这是一种非阻塞的编程范式。 -
模型:支持不同类型的模型,包括大型语言模型(LLM)、图像模型、音频模型、嵌入模型等。提供了LLM的管理和启动方式,以及使用JSON文件管理模型元数据的方法。
-
代码指南:主要代码位于
xinference/目录下,包括API、客户端、核心部分、部署、本地化、模型和前端用户界面等。
文档还包含了一些图表和代码示例,以帮助理解Xinference的内部结构和工作原理。如果您需要更详细的信息或有具体问题,请告诉我,我可以进一步解释或提供帮助。
二、RESTful API
RESTful API 是利用 FastAPI 实现的,具体代码在 api/restful_api.py。
self._router.add_api_route("/status", self.get_status, methods=["GET"])这是一个 API 的示例,API
/status对应函数get_status。您可以在 api/restful_api.py 中添加RESTful API 和对应后端函数之间的关系
2.1 RESTful API 和FastAPI的区别和联系
2.1.1 RESTful API
RESTful API 是一种设计方法,它基于REST(Representational State Transfer,表现层状态转移)架构风格。
REST是一种软件架构风格,用于设计网络应用,关键点在于它的设计理念和架构原则,而不是具体的实现技术。你可以使用任何编程语言和框架来实现RESTful API,只要遵循REST原则即可。这些原则指导开发者如何设计和实现Web服务,使其易于理解、使用和维护。
- RESTful API的核心原则包括:
- 客户端-服务器分离:客户端和服务器应该分离,服务器负责数据存储,客户端负责用户交互。
- 无状态:每个请求从客户端到服务器必须包含所有必要的信息,以便服务器能够理解请求并独立地处理它。
- 可缓存:数据应该被标记为可缓存或不可缓存。如果可缓存,客户端可以缓存数据以提高效率。
- 统一接口:系统组件之间的通信应该通过统一的接口进行,以简化整体系统架构。
- 分层系统:客户端不能依赖于服务器的内部结构。
- 按需编码:服务器可以根据请求提供数据的特定表示,如JSON、XML等。
2.1.2 FastAPI
FastAPI 是一个具体的实现框架,它是用Python编写的,用于构建高性能的Web服务和API。
FastAPI遵循现代Web开发的最佳实践,提供了许多强大的功能,如自动文档生成、数据验证、异步支持等。
FastAPI的主要特点包括:
- 高性能:FastAPI基于Starlette和Pydantic,这两个库都是高性能的库,使得FastAPI能够提供快速的响应时间。
- 自动生成文档:FastAPI可以自动生成API文档,如Swagger UI和ReDoc,这使得API的测试和文档化变得非常简单。
- 数据验证和序列化:FastAPI使用Pydantic来处理数据验证和序列化,这使得数据验证变得非常快速和方便。
- 异步支持:FastAPI支持异步请求处理,这意味着它可以处理大量的并发请求,而不会阻塞服务器。
- 类型提示:FastAPI利用Python的类型提示来自动生成API文档,并且可以自动验证传入的数据。
联系:
FastAPI是一个具体的技术实现,它提供了一套工具和库,帮助你快速构建RESTful API。FastAPI本身是RESTful API的一种实现方式,但它并不是唯一的方式。你可以使用其他框架(如Flask、Django REST framework等)来实现RESTful API。
- FastAPI是一种实现RESTful API的工具。它遵循REST原则,可以用于创建符合REST架构风格的API。
- FastAPI提供了一种简洁而强大的方式来构建RESTful API,它包含了构建RESTful API所需的许多功能,如请求路由、数据验证、文档生成等。
2.1.3 区别
- RESTful API 是一种设计方法和架构原则,它指导你如何设计Web服务。
- FastAPI 是一个具体的Python框架,用于实现RESTful API。
2.1.4 联系
- FastAPI遵循REST原则,提供了一种高效、便捷的方式来构建RESTful API。
- 你可以使用FastAPI来实现RESTful API,但RESTful API的概念并不局限于FastAPI。
二、命令行
命令行是通过 Click 实现的,具体代码在 deploy/cmdline.py,命令行允许用户直接在终端与 Xinference
进行交互。
Click 允许用户通过命令行方式调用 Xinference 的各种功能。这意味着用户可以在终端中输入命令,比如 xinference --help,来获取帮助信息,或者 xinference start,来启动 Xinference 服务。另外使用Click可以自动处理命令行参数,把命令行参数解析为Python数据类型、可以为每个命令生成易于阅读的帮助界面、支持创建嵌套子命令结构…
具体关于“Click”是什么。可以查看“四、Click”
三、入口点
以我们实现的命令行为例:
xinference:提供命令用于模型管理,包括注册/取消注册模型、列出所有已注册/运行的模型,以及启动或终止特定模型。它还提供生成语言和聊天等交互式命令,用于测试或交互已部署的模型。
xinference-local:启动一个本地 Xinference 服务。
xinference-supervisor:启动 supervisor 进程,在分布式环境中管理和监控 worker actors。
xinference-worker:启动 worker 进程,利用可用计算资源,执行 supervisor 分配的任务。每条命令都配有
option和flag,可自定义其行为,如指定日志级别、主机地址、端口号和其他相关设置。Python 项目会在 setup.cfg 或 setup.py 中定义命令行控制台入口点。
xinference = xinference.deploy.cmdline:cli xinference-local = xinference.deploy.cmdline:local xinference-supervisor = xinference.deploy.cmdline:supervisor xinference-worker = xinference.deploy.cmdline:worker ``` 命令行 `xinference` 可参考 `xinference.deploy.cmdline:cli` 中的代码。
四、Click
我们使用 Click 来实现特定的命令行:
"--host", "-H", default=XINFERENCE_DEFAULT_DISTRIBUTED_HOST, type=str, help="Specify the host address for the supervisor.", ) @click.option( "--port", "-p", default=XINFERENCE_DEFAULT_ENDPOINT_PORT, type=int, help="Specify the port number for the Xinference web ui and service.", )例如,
xinference-local命令允许您定义主机地址和端口。
4.1 Click是什么
Click是一个Python库,用于创建美观、可配置的命令行界面,旨在简化CLI开发并提供合理默认设置。
-
以下是 Click 的一些核心特性:
-
命令的任意嵌套:Click 允许你创建可以嵌套的命令,这意味着你可以构建复杂的命令行工具,其中命令可以有自己的子命令。
-
自动生成帮助页面:Click 自动为每个命令生成格式化的帮助页面,这些页面清晰地展示了命令的用法、选项和参数。
-
支持在运行时延迟加载子命令:Click 支持在需要时才加载子命令,这有助于提高大型命令行
-
-
简单的Click程序的例子:
import click @click.command() @click.option('--count', default=1, help='Number of greetings.') @click.option('--name', prompt='Your name', help='The person to greet.') def hello(count, name): """Simple program that greets NAME for a total of COUNT times.""" for x in range(count): click.echo(f"Hello {name}!") if __name__ == '__main__': hello()运行时的样子:
$ python hello.py --count=3 Your name: John Hello John! Hello John! Hello John!它会自动生成格式良好的帮助页面:
$ python hello.py --help Usage: hello.py [OPTIONS] Simple program that greets NAME for a total of COUNT times. Options: --count INTEGER Number of greetings. --name TEXT The person to greet. --help Show this message and exit.你可以直接从PyPI获取这个库:
pip install click
五、 Actor
Xinference 以 Xoscar 为基础,Xoscar 是我们的 actor 框架,可以管理计算资源和 Python 进程,支持可扩展的并发编程。下面的伪代码演示了 Worker Actor 的工作原理,实际的 Worker Actor 要比这个复杂得多。
class WorkerActor(xo.Actor): def __init__(self, *args, **kwargs): ... async def launch_model(self, model_id, n_gpu, ...): # launch an inference engine, use specific model class to load model checkpoints ... async def list_models(self): # list models on this actor ... async def terminate_model(self, model_id): # terminate the model ... async def __post_create__(self): # called after the actor instance is created ... async def __pre_destroy__(self): # called before the actor instance is destroyed ...我们以
WorkerActor为例,说明如何构建 Xinference。每个 actor 类都是继承自xoscar.Actor的标准 Python 类。该类的实例就是 actor 池中的一个特定的 actor。
定义 Actor 的行为:每个 actor 都需要定义某些动作或行为来完成特定任务。例如,模型推理
WorkerActor需要启动模型(launch_model)、列出该 actor 中的模型(list_models)、终止模型(termininate_model)。有两个特殊方法值得注意。__post_create__在创建 actor 之前调用,进行必要的初始化。而__pre_destroy__会在 actor 被销毁后调用,执行清理任务。引用 Actor 和调用方法:当创建一个 Actor 时,它会产生一个引用变量,以便其他 Actor 可以引用它。Actor 也可以用 IP 地址来引用。假设创建了
WorkerActor,且引用变量为worker_ref,那么就可以通过调用worker_ref.launch_model()来调用该 Actor 类的launch_model。即使 actor 中的方法原来是一个传统的阻塞式的方法,当我们使用引用变量调用这个方法时,它也变成了一个异步方法。推理引擎:Actor 可以管理进程,而推理引擎也是一种进程。在
WorkerActor的启动模型部分,我们可以根据用户的需要初始化不同的推理引擎。因此,Xinference 可以支持多种推理引擎,并能轻松适应未来的新推理引擎。请参阅 Xoscar文档了解更多 Actor 用例。
5.1 actor 是模型
Actor 模型是一种并发编程的范式,用于设计和构建并发系统。它定义了如何组织和管理并发执行的实体(即 Actor),以及它们之间的交互方式。
Actor 模型的特点
- 并发单元:在 Actor 模型中,每个 Actor 是一个独立的并发单元,拥有自己的状态和行为。
- 消息传递:Actor 之间通过发送和接收消息进行通信,而不是通过共享状态。这种方式避免了许多传统并发编程中的问题,如竞态条件和死锁。
- 状态封装:每个 Actor 封装了自己的状态,其他 Actor 不能直接访问或修改这个状态,只能通过消息进行交互。
- 异步执行:Actor 的执行是异步的,一个 Actor 可以在处理消息时继续接收其他消息,从而实现高并发。
5.1.1 Actor 模型与框架的关系
虽然 Actor 是一种模型,但许多编程框架和库实现了 Actor 模型,以便开发者可以更容易地构建基于 Actor 的系统。例如:
- Akka:一个用于构建并发和分布式应用的框架,广泛用于 Scala 和 Java,支持 Actor 模型。
- Xoscar:在 Xinference 中使用的 Actor 框架,专门用于管理计算资源和模型推理进程。
总结 - Actor 是模型:它定义了一种并发编程的方式。
- 框架实现 Actor 模型:许多框架(如 Akka 和 Xoscar)实现了 Actor 模型,提供了工具和库,帮助开发者构建基于 Actor 的应用。
5.2 Xoscar是框架
Xoscar 是一个专门为 Xinference 设计的框架,它实现了 actor 模型。在这个上下文中,Xoscar 提供了必要的工具和抽象,使得开发者可以在 Xinference 系统中创建和管理 actor。
具体来说,Xoscar 框架可能包括以下功能:
- Actor 创建和管理:提供创建 actor 的方法,以及管理 actor 生命周期(如创建、运行和销毁)的机制。
- 消息传递系统:实现一个机制,允许 actor 之间通过发送和接收消息进行通信。
- 并发和异步执行:支持 actor 的并发执行,确保消息处理是异步的,以提高性能和响应能力。
- 资源管理:由于 actor 通常与特定的计算资源(如 CPU 核心或 GPU 设备)相关联,Xoscar
可能还提供了资源分配和管理的功能。 - 故障处理和恢复:实现容错机制,以便在 actor 出现故障时能够进行恢复或重新分配任务。
- 扩展性和可维护性:设计为易于扩展和维护,以适应不同规模和复杂性的应用需求。
在 Xinference 系统中,Xoscar 框架使得开发者可以利用 actor 模型的优势,如简化并发编程、提高系统的可扩展性和容错性。通过使用 Xoscar,Xinference 可以有效地管理和调度大量的模型推理任务,同时保持代码的清晰和易于维护。
六、异步编程
Xinference 和 Xoscar 非常依赖异步编程库
asyncio。异步编程是一种非阻塞的编程范式。相比于传统的阻塞式的函数调用,异步编程中的请求或函数调用在后台执行,运行结果在未来某个时刻返回。异步编程的优势是使得可以同时并发进行很多不同的活动或任务。如果您不熟悉 Python 的
asyncio,可以查看更多教程以获得帮助:
五、模型
Xinference 支持不同类型的模型,包括大型语言模型(LLM)、图像模型、音频模型、嵌入模型等。所有模型在 model/ 文件夹下实现。
六、LLM
以 model/llm/ 为例,它主要管理和启动 LLM,包括加载、配置和运行大语言模型。
我们支持不同的推理后端,比如 GGML、PyTorch 和 vLLM。我们生成的内容与 OpenAI 的格式兼容,比如支持流式输出(stream),对话模型以 chat completion 格式返回。因此模型输出内容后要做很多适配工作。这些工作并不难,但需要一些时间。编写这部分代码时,请参考 OpenAI 的 API 文档 和各个推理后端的文档,做必要的适配。
七、JSON
在 model/llm/llm_family.json 中,我们利用 JSON 文件来管理新出现的开源模型的元数据。添加一个新模型并不需要编写新代码,只需要将新的元数据添加到现有的 JSON 文件中即可。
"model_name": "llama-2-chat", "model_ability": ["chat"], "model_specs": [ { "model_format": "ggmlv3", "model_size_in_billions": 70, "quantization": ["q8_0", ...], "model_id": "TheBloke/Llama-2-70B-Chat-GGML", }, ... ], "prompt_style": { "style_name": "LLAMA2", "system_prompt": "<s>[INST] <<SYS>>\nYou are a helpful AI assistant.\n<</SYS>>\n\n", "roles": ["[INST]", "[/INST]"], "stop_token_ids": [2], "stop": ["</s>"] } }这是一个如何定义 Llama-2 聊天模型的示例。
model_specs定义了模型的信息,因为一个模型系列通常有不同的尺寸、量化方法和文件格式。例如,model_format可以是pytorch(使用 Hugging Face Transformers 或 vLLM 作为后端)、ggmlv3(与 llama.cpp 相关的张量库)或gptq(训练后量化框架)。
model_id 定义了模型中心的资源库,Xinference 从模型中心下载检查点文件。此外,由于不同的指令调整过程,不同的模型系列有不同的提示风格。JSON 文件中的prompt_style指定了该特定模型的提示格式。例如,system_prompt和roles用于指定模型的指令和个性。
八、参考文档与推荐书目
Xinference 的内部结构
软件架构:架构模式特征及实践指南

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)