【深度学习】LSTM的架构及公式
第一个门:决定我们要扔掉哪些信息(forget gate layer)ft=σ(Wf∗[ht−1,xt]+bf)f_t = \sigma(W_{f}*[h_{t-1},x_t] + b_f)ft=σ(Wf∗[ht−1,xt]+bf)第二个门:用来决定我们打算决定储存哪些新信息。it=σ(Wi∗[ht−1,xt]+bi)i_t = \sigma(W_i*[h_{t-1},x_t] + ..
LSTM比传统的RNN强在哪里?
LSTM:long short term memory networks(长短时记忆模型)
传统的RNNs只能解决短期依赖的问题,比如我们想预测这句话“the clouds are in the sky”的最后一个词"sky",我们不需要更多的信息,前面的信息已经足够了,这种情况下,相关信息之间的距离非常近,此时传统的RNNs可以处理此类问题。但当相关信息距离非常远时,比如我们要预测“I grew up in France…I speak fluent French”这句话中的最后一个词“French”,我们需要之前的信息“France”,对于这种长距离的依赖RNNs是无法处理的,但是LSTMs可以解决此类问题。
LSTM的结构
第一幅图是传统的RNN的结构,每个循环单元中只有一层layer。传统的RNN计算公式可以参看此链接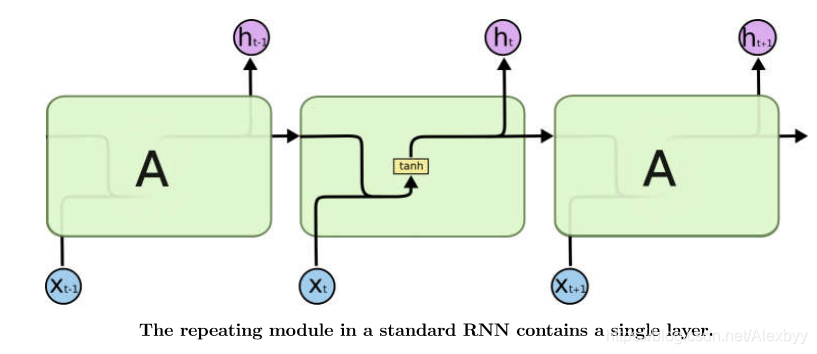
下图是LSTM的结构,每个循环单元中有四层layer。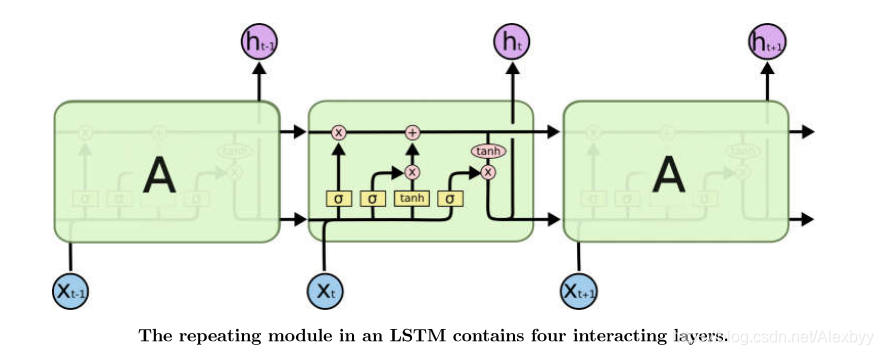
将LSTM循环单元进一步展开如下图: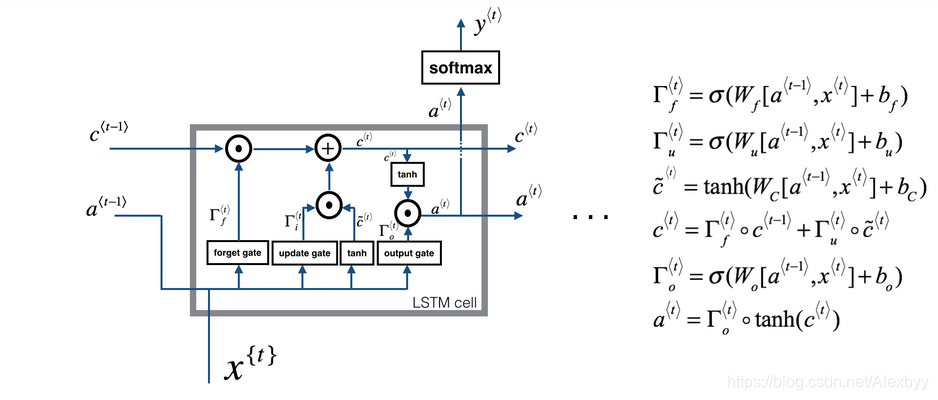
LSTM循环单元包含三个门(gate),分别负责遗忘哪些历史信息(Forget gate)、增加哪些历史信息(updating gate)、以及输出门(Output gate)
- 第一个门((forget gate layer)):决定我们要扔掉哪些信息 (1) Γ f ⟨ t ⟩ = σ ( W f [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b f ) \Gamma_f^{\langle t \rangle} = \sigma(W_f[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_f)\tag{1} Γf⟨t⟩=σ(Wf[a⟨t−1⟩,x⟨t⟩]+bf)(1)该公式计算出的值介于0-1之间(因为激活函数是sigmoid),所以当该值与 c < t − 1 > c^{<t-1>} c<t−1>点乘操作时,值越大的位置相乘后得到的结果值也越大,即该位置保留的历史信息越多。
- 第二个门(updating gate):用来决定我们要增加哪些新的信息 (2) Γ u ⟨ t ⟩ = σ ( W u [ a ⟨ t − 1 ⟩ , x { t } ] + b u ) \Gamma_u^{\langle t \rangle} = \sigma(W_u[a^{\langle t-1 \rangle}, x^{\{t\}}] + b_u)\tag{2} Γu⟨t⟩=σ(Wu[a⟨t−1⟩,x{t}]+bu)(2)
第三层layer的计算公式如下,用来与更新门点乘得到要增加的信息: (3) c ~ ⟨ t ⟩ = tanh ( W c [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b c ) \tilde{c}^{\langle t \rangle} = \tanh(W_c[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_c)\tag{3} c~⟨t⟩=tanh(Wc[a⟨t−1⟩,x⟨t⟩]+bc)(3)最终该循环单元的 c < t > c^{<t>} c<t>,即用来保存历史信息的输出,用下面公式计算: (4) c ⟨ t ⟩ = Γ f ⟨ t ⟩ ∗ c ⟨ t − 1 ⟩ + Γ u ⟨ t ⟩ ∗ c ~ ⟨ t ⟩ c^{\langle t \rangle} = \Gamma_f^{\langle t \rangle}* c^{\langle t-1 \rangle} + \Gamma_u^{\langle t \rangle} *\tilde{c}^{\langle t \rangle} \tag{4} c⟨t⟩=Γf⟨t⟩∗c⟨t−1⟩+Γu⟨t⟩∗c~⟨t⟩(4) - 第三个门(Output gate),该门用来计算 a < t > a^{<t>} a<t>, 然后 a < t > a^{<t>} a<t>用来计算该单元的输出 y y y (5) Γ o ⟨ t ⟩ = σ ( W o [ a ⟨ t − 1 ⟩ , x ⟨ t ⟩ ] + b o ) \Gamma_o^{\langle t \rangle}= \sigma(W_o[a^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_o)\tag{5} Γo⟨t⟩=σ(Wo[a⟨t−1⟩,x⟨t⟩]+bo)(5)
(6) a ⟨ t ⟩ = Γ o ⟨ t ⟩ ∗ tanh ( c ⟨ t ⟩ ) a^{\langle t \rangle} = \Gamma_o^{\langle t \rangle}* \tanh(c^{\langle t \rangle})\tag{6} a⟨t⟩=Γo⟨t⟩∗tanh(c⟨t⟩)(6)
参考博客及论文:
https://arxiv.org/pdf/1402.1128v1.pdf
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)