pytorch框架学习---PyTorch基础与简单神经网络
函数:y = x**2 + 3*x + 1,求dy/dx在x=2的梯度。
·
1. 自动求导
1.1 什么是Autograd?
- Autograd是PyTorch的自动微分引擎,用于计算张量(Tensor)的梯度(导数)。
- 梯度是深度学习优化的核心,表示损失函数对模型参数(如权重、偏置)的变化率。
- 作用:通过梯度下降(Gradient Descent)调整参数,最小化损失函数。
- 核心优势:无需手动推导复杂函数的导数,Autograd通过动态计算图自动完成微分。
1.2 动态计算图
- 定义:
- 计算图记录张量之间的运算,形成一个有向图,节点是运算(加、乘等),边是张量流动。
- PyTorch的计算图是动态的(dynamic computational graph),每次前向传播时重新构建,灵活且适合调试。
- 对比:TensorFlow(早期)使用静态图,需预定义图结构。
- 示例:
设 x = torch.tensor(2.0, requires_grad=True),y = x**2 + 3*x + 1。- 计算图:
- 节点1:x^2(幂运算)。
- 节点2:3*x(乘法)。
- 节点3:x^2 + 3*x(加法)。
- 节点4:x^2 + 3*x + 1(加常数)。
- 每步运算记录输入、输出和梯度函数,用于反向传播。
1.3 核心机制
- requires_grad:
- 设置张量属性requires_grad=True,PyTorch会跟踪该张量的所有运算。
- 示例:x = torch.tensor([1.0, 2.0], requires_grad=True),任何以x为输入的运算都会被记录。
- 注意:默认requires_grad=False,需手动启用(通常用于模型参数)。
- backward():
- 调用y.backward()触发反向传播,PyTorch根据链式法则计算所有requires_grad=True张量的梯度。
- 链式法则:若 y = f(g(x)),则 dy/dx = dy/dg * dg/dx。
- 梯度存储在张量的.grad属性中。
- 示例:
x = torch.tensor(2.0, requires_grad=True) y = x**2 + 3*x + 1 # y = x^2 + 3x + 1 y.backward() print(x.grad) # 输出 7.0(dy/dx = 2x + 3,在 x=2 时为 7)
- 梯度累加与清零:
- 梯度默认累加(.grad += new_grad),适合某些场景(如RNN)。
- 训练中需每次清零梯度(zero_()),否则会影响下一次更新。
- 示例:x.grad.zero_()或 optimizer.zero_grad()。
- 脱离计算图:
- detach():生成新张量,停止梯度跟踪,常用于推理或冻结参数。
- 示例:x_detached = x.detach(),x_detached 无梯度。
- with torch.no_grad():临时关闭梯度计算,节省内存。
- 示例:
with torch.no_grad(): y = x**2 # 不记录梯度
- 示例:
- detach():生成新张量,停止梯度跟踪,常用于推理或冻结参数。
1.4 数学推导示例
函数:y = x**2 + 3*x + 1,求dy/dx在x=2的梯度。
x = torch.tensor(2.0, requires_grad=True)
y = x**2 + 3*x + 1
y.backward()
print(x.grad) # 输出 7.01.5 应用场景
- 优化模型参数:通过梯度下降更新权重和偏置。
- 调试:检查梯度是否正确,诊断模型问题(如梯度消失)。
- 自定义梯度:通过torch.autograd.grad实现复杂优化算法。
2. 线性回归
2.1 什么是线性回归?
- 线性回归是一种监督学习模型,假设输入x和输出y之间存在线性关系。
- 数学公式:y = w * x + b,其中:
- x:输入特征(可以是多维)。
- w:权重(斜率),控制x对y的影响。
- b:偏置(截距),调整输出基准。
- 目标:通过训练数据学习最优的w和b,使预测值
接近真实值
。
2.2 数学原理
- 损失函数:
- 衡量预测值y_pred与真实值y_true的差距。
- 常用均方误差(MSE):
L = 1/N * Σ(y_pred - y_true)^2,N 是样本数。 - 目标:最小化L,使y_pred ≈ y_true。
- 梯度下降:
- 通过梯度更新参数:
- w = w - learning_rate * dL/dw
- b = b - learning_rate * dL/db
- 通过梯度更新参数:
- 学习率(learning_rate):
- 控制参数更新步长,典型值0.01或0.001。
- 太大:可能震荡或发散;太小:收敛慢。
- 随机梯度下降(SGD):
- 每次用小批量数据(batch)计算梯度,效率更高。
- 示例:批量大小32,随机抽取32个样本计算梯度。
2.3 训练流程
- 初始化:随机初始化w和b(PyTorch自动处理)。
- 前向传播:计算
。
- 计算损失:
。
- 反向传播:调用loss.backward(),Autograd计算dL/dw和dL/db。
- 更新参数:优化器(SGD)根据梯度调整w和b。
- 重复:多轮训练(epochs),直到损失收敛。
2.4 PyTorch实现细节
- 模型:
- 使用nn.Module定义模型,封装w和b。
nn.Linear(in_features, out_features):实现 y = w*x + b。- 示例:nn.Linear(1, 1),1维输入到1维输出。
- 定义类
class LinearRegression(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(1, 1) def forward(self, x): return self.linear(x)
- 损失函数:
- nn.MSELoss():计算均方误差,支持批量输入。
示例:criterion = nn.MSELoss()。
- 优化器:
- torch.optim.SGD:实现随机梯度下降。
- 参数:模型参数(model.parameters())和学习率(lr)。
示例:optimizer = torch.optim.SGD(model.parameters(), lr=0.01)。
- 训练循环:
-
for epoch in range(epochs): y_pred = model(x) # 前向传播 loss = criterion(y_pred, y) # 计算损失 optimizer.zero_grad() # 清零梯度 loss.backward() # 反向传播 optimizer.step() # 更新参数
-
3. 理论与实践的连接
- Autograd在线性回归中的作用:
- 自动计算dL/dw和dL/db,无需手动推导复杂的损失函数导数。
- 使训练流程简化为“前向-损失-反向-更新”。
- 线性回归的扩展:
- 单层线性回归是神经网络的基础。
- 增加层数(多层感知机MLP)、非线性激活(如ReLU),即可构建复杂模型。
- 实践重点:
- 通过代码实现Autograd(简单函数梯度)和线性回归(完整训练)。
- 观察损失下降,验证w和b是否接近真实值。
torch.utils.data.Dataset 类及其方法
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = data # 张量
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]__init__
作用:
- 初始化数据集,加载或指定数据源,设置必要的参数和预处理逻辑。
- 这是 Dataset 类的构造函数,用于存储数据或元数据(如文件路径、标签列表)。
实现细节:
- __init__ 通常接收数据和相关参数(如文件路径、标签、变换函数)。
- 数据可以是:
- 内存中的张量或数组(如你的 data, labels)。
- 文件路径列表(如图像路径 [img1.jpg, img2.jpg])。
- 数据库连接或其他数据源。
- 常见操作:
- 存储输入数据(如 self.data = data)。
- 应用预处理(如 transforms)。
- 检查数据有效性(如确保 data 和 labels 长度一致)。
-
def __init__(self, data, labels): assert len(data) == len(labels) #验证数据集 标签和数据的数量相等 self.data = data self.labels = labels self.transform = transform #使数据支持预处理
len 方法
作用:
- 返回数据集的总样本数,告诉 PyTorch 数据集有多大。
- DataLoader 使用 __len__ 确定迭代次数和批量分割。
实现细节:
- 返回一个整数,通常是数据列表或张量的长度。
- 由 len(dataset) 调用,DataLoader 依赖它来计算批次数量:
例如,len(dataset) = 1000, batch_size = 32,则有 1000 / 32 ≈ 31 个批次。
- 实现简单,通常基于 __init__ 中存储的数据:
如果 self.data 是张量,调用 len(self.data) 或 self.data.shape[0]。- 如果是文件路径列表,返回 len(self.image_paths)。
getitem 方法
作用:
- 根据给定的索引 idx,返回对应样本的数据和标签。
- 这是 Dataset 的核心方法,定义了如何访问单个样本,供 DataLoader 批量加载。
实现细节:
- 输入:整数 idx(从 0 到 len(dataset)-1)。
- 输出:通常是一个元组 (data, label),其中:
- data:输入特征(如图像张量)。
- label:目标标签(如类别索引)。
- 功能:
- 从 self.data 和 self.labels 中提取第 idx 个样本。
- 可应用动态预处理(如 self.transform)。
- DataLoader 会调用 __getitem__ 多次,收集一个 batch 的样本,并自动堆叠为张量:
- 例如,batch_size=32,调用 32 次 __getitem__,返回形状 [32, ...] 的张量。
添加预处理支持
def __getitem__(self, idx):
data, label = self.data[idx], self.labels[idx]
if self.transform is not None:
data = self.transform(data)
return data, label处理非张量数据:
- 如果 self.data 是图像路径,需动态加载
def __getitem__(self, idx): img_path = self.data[idx] label = self.labels[idx] image = Image.open(img_path) # 使用 PIL 加载图像 if self.transform: image = self.transform(image) return image, label
Dataset 与 DataLoader 的协作
- DataLoader 迭代 Dataset,调用 __len__ 确定总样本数,调用 __getitem__ 获取样本。
- 工作流程:
- DataLoader 根据 batch_size 和 shuffle 决定索引顺序。
- 调用 __getitem__(idx) 获取单个样本。
- 堆叠样本为 batch(如 [32, 1, 28, 28])。
- 返回 batch 供模型训练。
手动实现MLP
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
#数据的预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))#数据进行归一化
])
#定义 训练集 和 验证集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
#初始化模型中的参数 并进行梯度跟踪 方便后面的计算
torch.manual_seed(42)
w1 = torch.randn(784, 128, requires_grad=True) * 0.01
b1 = torch.zeros(128, requires_grad=True)
w2 = torch.randn(128, 10, requires_grad=True) * 0.01
b2 = torch.zeros(10, requires_grad=True)
params = [w1, b1, w2, b2]
#定义训练参数
learning_rate = 0.01
epochs = 5
#具体的训练流程
for epoch in range(epochs):
total_loss = 0 #记录这一轮的累计损失
correct = 0 #记录正确预测的个数
total = 0 #记录参与训练的样本数量
for images, labels in train_loader:#每次从train_loader拿出一个epoch所需的样本的images, labels
#将输入的数据 从2D变为1D view是高效的重塑操作不复制数据 -1自动推断batch大小,784 = 28*28
#本来的数据格式为[batch_size, 1, 28, 28] 变为[batch_size, 784] 为了适配MLP输入
x = images.view(-1, 784)
#MLP的第一层 隐藏层
h = x @ w1 + b1
h = torch.relu(h)#激活函数 加入非线性变化 ReLU(Rectified Linear Unit):f(x) = max(0, x),增强模型表达能力,缓解梯度消失。
#MLP的第二层 输出层
logits = h @ w2 + b2
exp_logits = torch.exp(logits)
p = exp_logits / exp_logits.sum(dim=1, keepdim=True)
loss = -torch.log(p[range(len(labels)), labels]).mean()#手写的交叉熵损失函数
for param in params:
if param.grad is not None:
param.grad.zero_() # 将所有的参数的梯度清零,防止梯度增加
#Autograd默认累加梯度(param.grad += new_grad),每次反向传播前需清零
loss.backward()# 反向传播
with torch.no_grad():
for param in params:
param -= learning_rate * param.grad #手写的梯度下降 优化器
total_loss += loss.item() * len(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
avg_loss = total_loss / total
accuracy = correct / total
print(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")
# 验证部分
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
x = images.view(-1, 784)
h = x @ w1 + b1
h = torch.relu(h)
logits = h @ w2 + b2
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
print(f"Test Accuracy: {correct/total:.4f}")1. nn.模块简介(10 分钟)
- 什么是 nn.模块 ?
- nn.Module 是 PyTorch 中定义神经网络的基类,提供了模块化构建模型的框架。
- 作用:
封装参数 :自动管理权重和偏置(如 w1, b1),无需手动定义。
前向传播 :通过 forward 方法定义模型计算逻辑。
模块化 :支持嵌套子模块(如多层网络、复杂模型)。
- 核心方法:
__init__:定义网络层(如 nn.线性 )。- forward:实现前向传播逻辑。
parameters():返回所有可训练参数。
手动实现 vs. nn.模块 :- 手动实现 (如之前代码):
手动定义 w1, b1, w2, b2,手写矩阵乘法和激活。- 手动清零梯度和更新参数。
- 代码繁琐,易出错,难以扩展到复杂模型。
- nn.模块 :
- 使用 nn.Linear 自动处理权重和偏置。
内置激活函数(如 nn.ReLU) 和损失函数。- 配合 torch.optim 简化优化,代码更简洁。
- 手动实现 (如之前代码):
- 示例 :
import torch.nn as nn class MLP(nn.Module): def __init__(self): super().__init__() self.layer1 = nn.Linear(784, 128) self.relu = nn.ReLU() self.layer2 = nn.Linear(128, 10) def forward(self, x): x = self.layer1(x) x = self.relu(x) x = self.layer2(x) return x- 定义了一个与之前手写 MLP 相同的结构(784→128→10),但更简洁。
2. 核心 API(12 分钟)
- nn.线性:
- 实现全连接层:y = x @ W^T + b。
- 参数:
in_features:输入维度(如 784)。
out_features:输出维度(如 128)。
自动初始化权重(W)和偏置(b),默认使用 Kaim 初始化(适合 ReLU)。
示例:nn.Linear(784, 128) 替代手写的 x @ w1 + b1。
- nn.CrossEntropyLoss:
- 结合 Softmax 和负对数似然,计算分类损失。
- 输入:
logits:未归一化的输出([batch_size, num_classes])。
labels:整数标签([batch_size],如 0-9)。
替代手写的 exp_logits, p, 和 loss = -torch.log(p[...]).mean() 的。
示例:criterion = nn.CrossEntropyLoss() 的。
- torch.optim 中:
- 提供优化器(如 SGD、Adam),自动更新参数。
- 替代手写的 param -= learning_rate * param.grad。
- 示例:
import torch.optim as optim optimizer = optim.SGD(model.parameters(), lr=0.01) - model.parameters():从 nn.module 自动获取所有可训练参数。
- 方法:
zero_grad():清零梯度。- step():更新参数。
- nn.ReLU 的:
封装 ReLU 激活函数(max(0, x)), 作为模块化层。
替代手写的 torch.relu(h), 更符合模块化设计。
3. 训练流程与优势(8分钟)
训练流程 (使用 nn.模块 ):
定义模型 :继承 nn.Module,实现 __init__ 和 forward。
数据加载 :使用 DataLoader 获取 batch。
前向传播 :调用 model(x) 计算 logits。
计算损失 :loss = criterion(logits, labels)。
反向传播 :loss.backward()。
更新参数 :optimizer.step()。
- 优势 :
简洁 :减少手动矩阵运算和参数管理。
可扩展 :易于添加层、修改结构(如增加隐藏层)。
标准化 :与 PyTorch 生态(如预训练模型)无缝集成。
自动管理 :参数、梯度、优化器统一处理,降低出错概率。
- 对比手写实现 :
手写:需要手动定义 w1, b1, w2, b2,手写 Softmax 和损失,代码约 30 行。- nn.Module:几行定义模型,损失和优化器内置,代码约 10-15 行。
手写适合学习底层原理,nn.Module 适合快速开发和复杂模型。
总结 :
- nn.Module 提供模块化框架,简化神经网络定义和训练。
nn.线性,nn。CrossEntropyLoss, torch.optim 封装底层作,提高效率。
学习 nn.Module 是阶段 1 的里程碑,为后续复杂模型(如 CNN)打基础。
使用 nn.Module 实现 MNIST 分类的 MLP
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
#数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5),(0.5))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
#使用nn.Module 定义模型
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(784,128)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(128,10)
def forward (self,x):
x = x.view(-1,784) #改变输入数据张量的形状 方面MPL的应用
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
model = MLP() #定义模型
criterion = nn.CrossEntropyLoss() #交叉熵损失函数
optimizer = optim.SGD(model.parameters(),lr=0.01) #优化器
epochs = 5 #训练次数
for epoch in range(epochs):
total_loss = 0
correct = 0
total = 0
for images , labels in train_loader:
x = images
logits = model(x) #模型的总分数
loss = criterion(logits , labels)
optimizer.zero_grad() #反向传播前 梯度归零
loss.backward() #反向传播 计算梯度
optimizer.step() #更新参数
total_loss += loss.item() * len(images)
pred = torch.argmax(logits,dim=1) #将总分变为概率
correct += (pred == labels).sum().item()
total += len(labels)
avg_loss = total_loss/ total
accuracy = correct / total
print(f"Epoch {epoch + 1}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")
model.eval() #将模型变为检验模式
correct = 0
total = 0
with torch.no_grad(): #停止计算变量的梯度
for images,labels in test_loader:
logits = model(images)
pred = torch.argmax(logits,dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
print(f"Test Accuracy: {correct / total:.4f}")1. CNN 简介
- 什么是 CNN?
- 卷积神经网络(Convolutional Neural Network)是专为处理网格数据(如图像)设计的神经网络。
- 核心组件:
卷积层 :提取局部特征(如边缘、纹理)通过卷积核。
池化层 :下采样,减少空间维度,保留重要信息。
全连接层 :将特征映射到类别(如分类任务)。
- 优势:
局部感知 :卷积核关注局部区域,适合图像的局部模式。
参数共享 :卷积核在整张图像上共享,减少参数量。
平移不变性 :对图像平移不敏感,泛化能力强。
- 与 MLP 的对比 :
- MLP:
输入展平为向量([batch, 784]),丢失空间结构。- 参数多(784*128 的权重矩阵),计算量大。
- 对图像任务效果有限(忽略局部特征)。
- 美国有线电视新闻网(CNN):
输入保留空间结构([batch, 1, 28, 28])。- 参数少(卷积核小,如 3x3),效率高。
- 擅长提取图像特征,适合 MNIST、CIFAR-10 等任务。
- MLP:
- CNN 结构(以 MNIST 为例):
输入:[batch, 1, 28, 28](灰度图像)。
卷积层 1:nn.Conv2d(1, 16, kernel_size=3) → [batch, 16, 26, 26]。
池化层 1:nn.MaxPool2d(2) → [batch, 16, 13, 13]。
卷积层 2:nn.Conv2d(16, 32, kernel_size=3) → [batch, 32, 11, 11]。
池化层 2:nn.MaxPool2d(2) → [batch, 32, 5, 5]。
展平:[batch, 32*5*5]。
全连接层:nn.linear(32*5*5, 10) → [batch, 10](logits)。
2. 核心 API
- nn.卷积 2d (Conv2d):
- 实现 2D 卷积操作,提取图像特征。
- 参数:
- in_channels:输入通道数(如 MNIST 的 1,RGB 图像的 3)。
- out_channels:输出通道数(卷积核数量,如 16)。
- kernel_size:卷积核大小(如 3 表示 3x3)。
- stride:步幅(默认 1)。
padding:填充(默认 0,padding=1 保持尺寸)。
- 输出形状:
H_out = floor((H_in + 2*填充 - kernel_size) / 步幅 + 1)。
示例:[batch, 1, 28, 28] → nn.conv2d(1, 16, 3) → [batch, 16, 26, 26]。
自动管理权重([out_channels, in_channels, kernel_size, kernel_size])和偏置。
- nn.MaxPool2d 中:
- 最大池化,减少空间维度,增强鲁棒性。
- 参数:
- kernel_size:池化窗口大小(如 2 表示 2x2)。
- stride:步幅(默认等于 kernel_size)。
- 输出形状:
H_out = floor((H_in - kernel_size) / 步幅 + 1)。
示例:[batch, 16, 26, 26] → nn.MaxPool2d(2) → [batch, 16, 13, 13]。
- nn.Module:
定义 CNN 模型,组合 nn.Conv2d,nn.MaxPool2d,nn.线性 。- forward 方法定义数据流:卷积 → 池化 → 展平 → 全连接。
- nn.CrossEntropyLoss 和 torch.optim:
- 损失:nn.CrossEntropyLoss 自动处理 Softmax 和负对数似然。
- 优化器:optim.SGD 或 optim.Adam 自动更新参数。
3. CNN 训练流程
- 流程 :
定义模型 :继承 nn.Module,组合卷积、池化、全连接层。
数据加载 :DataLoader 提供 [batch, 1, 28, 28] 的图像。
前向传播 :model(x) 计算 logits。
损失计算 :loss = criterion(logits, labels)。
反向传播 :loss.backward()。
优化 :optimizer.step()。
- 优势 :
- 比 MLP 更适合图像数据,参数少,精度高。
- 卷积操作提取空间特征(如边缘、纹理),池化降低计算量。
- 与手写 MLP 的对比 :
- 手写 MLP:手动矩阵乘,忽略空间结构。
美国有线电视新闻网:nn.Conv2d 自动处理卷积,保留空间信息,代码仍简洁。
摘要 :
- CNN 通过卷积和池化提取图像特征,适合视觉任务。
- nn.Conv2d 和 nn.MaxPool2d 是 CNN 核心组件,nn.Module 提供模块化实现。
- CNN 在 MNIST 上通常比 MLP 更高效,参数更少,精度更高。
使用 nn.Module 实现 MNIST 分类的 CNN
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5),(0.5))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class CNN(nn.Module):
def __init__(self):
super.__init__()
self.conv1 = nn.Conv2d(1,16,kernel_size=3) #参数分别是 输入数据的尺寸 输出数据的尺寸 卷积核的大小 输出大小= 步输入大小−卷积核大小/步长
self.pool1 = nn.MaxPool2d(2) #2x2最大池化
self.conv2 = nn.Conv2d(16,32,kernel_size=3)
self.pool2 = nn.MaxPool2d(2)
self.fc = nn.Linear(32*5*5,10) #全连接层
self.relu = nn.ReLU() #激活函数
def forward(self,x):
x = self.relu(self.conv1(x))
x = self.pool1(x)
x = self.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 32 * 5 * 5) #将数据展平 应为全连接层只能接受 一维的张量
x = self.fc(x)
return x
model = CNN()
# Training
criterion = nn.CrossEntropyLoss() #交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) #优化器
epochs = 5
#训练循环
for epoch in range(epochs):
model.train()
total_loss = 0
correct = 0
total = 0
for images, labels in train_loader:
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
avg_loss = total_loss / total
accuracy = correct / total
print(f"Epoch {epoch + 1}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")
# 测试
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
logits = model(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
print(f"Test Accuracy: {correct / total:.4f}")输出数据的大小的计算公式
一、无 padding 时的卷积输出公式
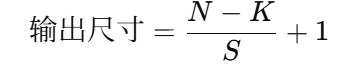
-
N:输入尺寸(高或宽)
-
K:卷积核大小
-
S:步长(stride)
-
没有 padding,所以图像边缘会被“卷”掉
二、有 padding 时的卷积输出公式
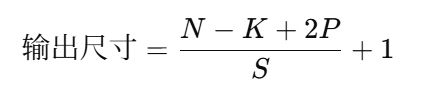
-
P:padding 填充的像素数(在每一边)
CIFAR-10 数据集 CNN代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
#数据增强
train_transform = transforms.Compose([
transforms.RandomCrop(32,padding=4), #随机裁剪
transforms.RandomHorizontalFlip(), #水平翻转 里面的参数是 反转的概率
transforms.ToTensor(), #将数据 变为张量
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) #将数据归一化
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
#导入数据
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
#CNN构建
class CIFAR10_CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3,16,kernel_size=3 ,padding = 1)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16,32,kernel_size=3,padding=1)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.fc = nn.Linear(64 * 8 * 8, 10)
self.relu = nn.ReLU()
def forward(self,x): #前向传播
x = self.relu(self.conv1(x))
x = self.pool1(x)
x = self.relu(self.conv2(x))
x = self.pool2(x)
x = self.relu(self.conv3(x))
x = x.view(-1, 64 * 8 * 8)
x = self.fc(x)
return x
model = CIFAR10_CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
model.train()
total_loss = 0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
avg_loss = total_loss / total
accuracy = correct / total
print(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")
# Testing
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
logits = model(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
print(f"Test Accuracy: {correct/total:.4f}")多通道卷积
- 多通道卷积原理:
- MNIST CNN:输入是单通道(in_channels=1),nn.Conv2d(1, 16, 3) 每个卷积核处理灰度图像。
- CIFAR-10 CNN:输入是三通道(RGB,in_channels=3),nn.Conv2d(3, 16, 3) 的卷积核有 [3, 3, 3] 形状(3 通道 × 3x3)。
- 卷积核:
- 每个输出通道(如 16)对应一个卷积核组,处理所有输入通道(3)。
- 输出形状:[batch, out_channels, H_out, W_out],H_out = (H_in - kernel_size + 2*padding) / stride + 1。
- 示例:
- 输入:[batch, 3, 32, 32]。
- nn.Conv2d(3, 16, 3) → [batch, 16, 30, 30](无 padding,stride=1)。
- 知识点:
- 多通道卷积提取 RGB 图像的颜色和空间特征,参数量随通道数增加。
- 需调整全连接层输入尺寸,考虑卷积和池化后的特征图大小。
- 与 MNIST CNN 的区别:
- 输入通道:MNIST(1) vs. CIFAR-10(3)。
- 模型深度:CIFAR-10 需更深网络(更多卷积层)捕获复杂特征。
- 数据增强:CIFAR-10 需强增强防止过拟合。
数据增强
- 什么是数据增强?
- 通过随机变换(如翻转、裁剪)增加训练数据多样性,防止过拟合。
- CIFAR-10 小图像和高类别复杂度尤其需要增强。
- 常见增强(torchvision.transforms):
- RandomCrop(size, padding):随机裁剪(如 32x32,padding=4)。
- RandomHorizontalFlip(p=0.5):50% 概率水平翻转。
- ColorJitter(brightness, contrast):调整亮度、对比度(稍后阶段深入)。
- 作用:
- 提高模型泛化能力,尤其对小数据集(如 CIFAR-10)。
- 模拟真实场景的图像变化(如光照、角度)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)