【论文笔记】深度学习 Lips Don’t Lie: A Generalisable and Robust Approach to Face Forgery Detection
语义信息:人脸提取出特征点后人脸就有了语义信息。高层语义特征:识别人脸的喜怒哀乐。现有问题:检测方法依赖于常见的后处理操作(如压缩)。想法来源:通过观察得,为了让伪造人脸的身份,语言和表情相匹配,大多数人脸视频伪造者会以某种方式操作嘴巴。例如:假嘴巴在发音某些音时无法充分闭合。口腔形状或口腔内部(例如牙齿)在帧与帧之间的变化。:在高度压缩泛化性好,能检测新的伪造方法。主要检测说话时的不协调。方法:
* Lips Don’t Lie: A Generalisable and Robust Approach to Face Forgery Detection
嘴唇不撒谎:一种泛化的和鲁棒的人脸伪造检测方法
1.概述
-
语义信息:人脸提取出特征点后人脸就有了语义信息。
高层语义特征:识别人脸的喜怒哀乐。
-
现有问题:检测方法依赖于常见的后处理操作(如压缩)。
-
想法来源:通过观察得,为了让伪造人脸的身份,语言和表情相匹配,大多数人脸视频伪造者会以某种方式操作嘴巴。例如:假嘴巴在发音某些音时无法充分闭合。口腔形状或口腔内部(例如牙齿)在帧与帧之间的变化。
-
LipForensics:在高度压缩
泛化性好,能检测新的伪造方法。
主要检测说话时的不协调。
方法:通过时空结合网络学习唇读(视觉语言识别),从而学习与自然口腔运动相关的内容表示。再加入时间网络微调,增加泛化性。
-
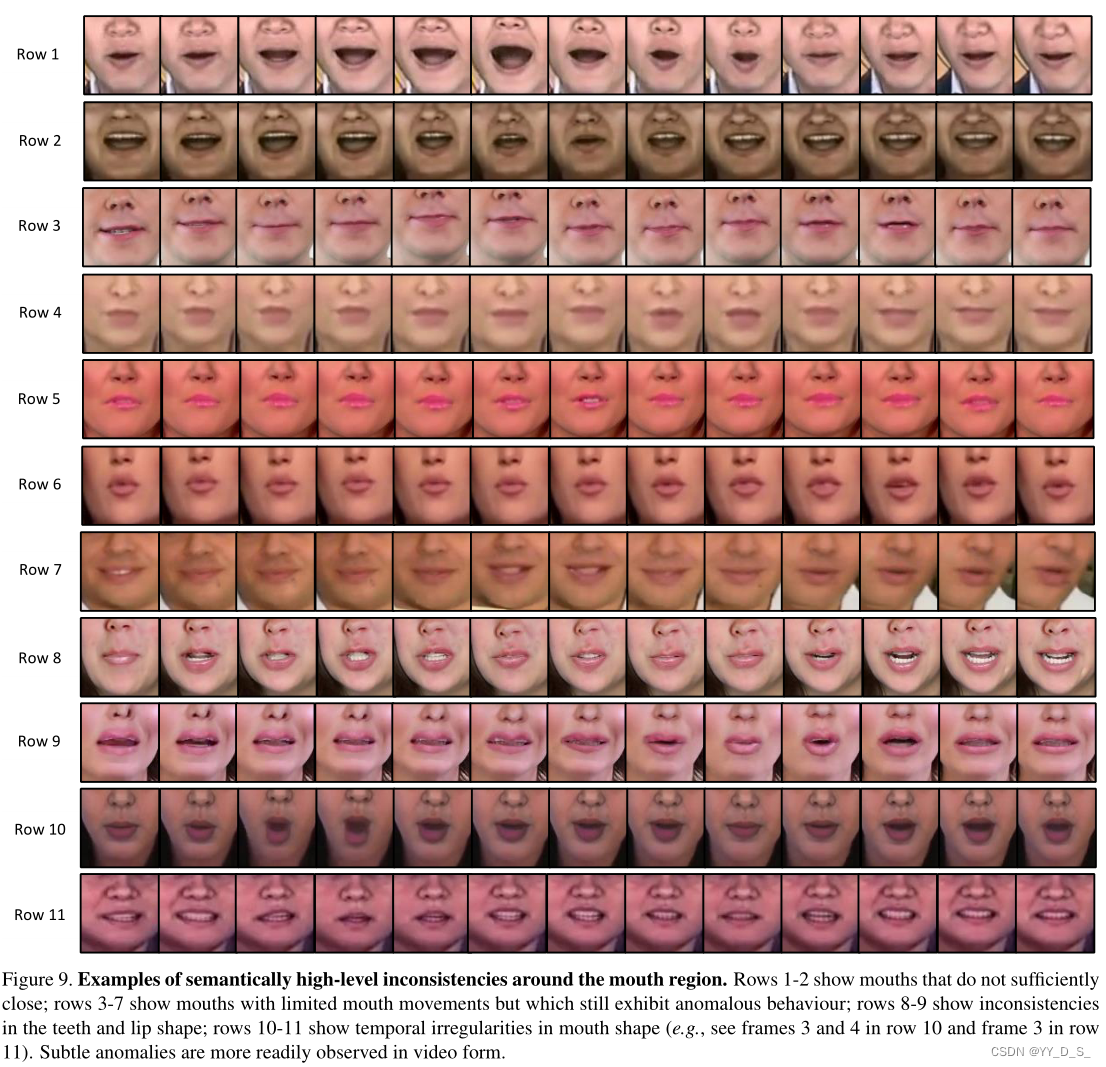 高级语义不一致:
高级语义不一致: -
第1-2行显示的嘴没有充分闭合;第3-7行示出了嘴运动受限但仍表现出异常行为的嘴;第8-9行显示了牙齿和唇形的不一致;行10-11示出嘴部形状的时间不规则性
2.LipForensics
-
前提假设:无论生成方法如何,假视频中都存在嘴巴运动的不规则性。
-
概述:通过监测嘴部运动是否自然来判断是否伪造。但是,只训练针对嘴巴的
spatio-temporal CNN不一定会学到所需特征,因为它可能会学习到其他更明显的操作线索来分离数据,容易造成过拟合。为此,采取两步走的方法。-
1.对由时空特征提取器和时间卷积网络组成的CNN,用于唇读任务。
目标:检测出嘴部的异常。
-
2.冻结特征提取器+微调时间网络。否则,网络可能学到除嘴部之外的伪影,而不是嘴部运动。
-
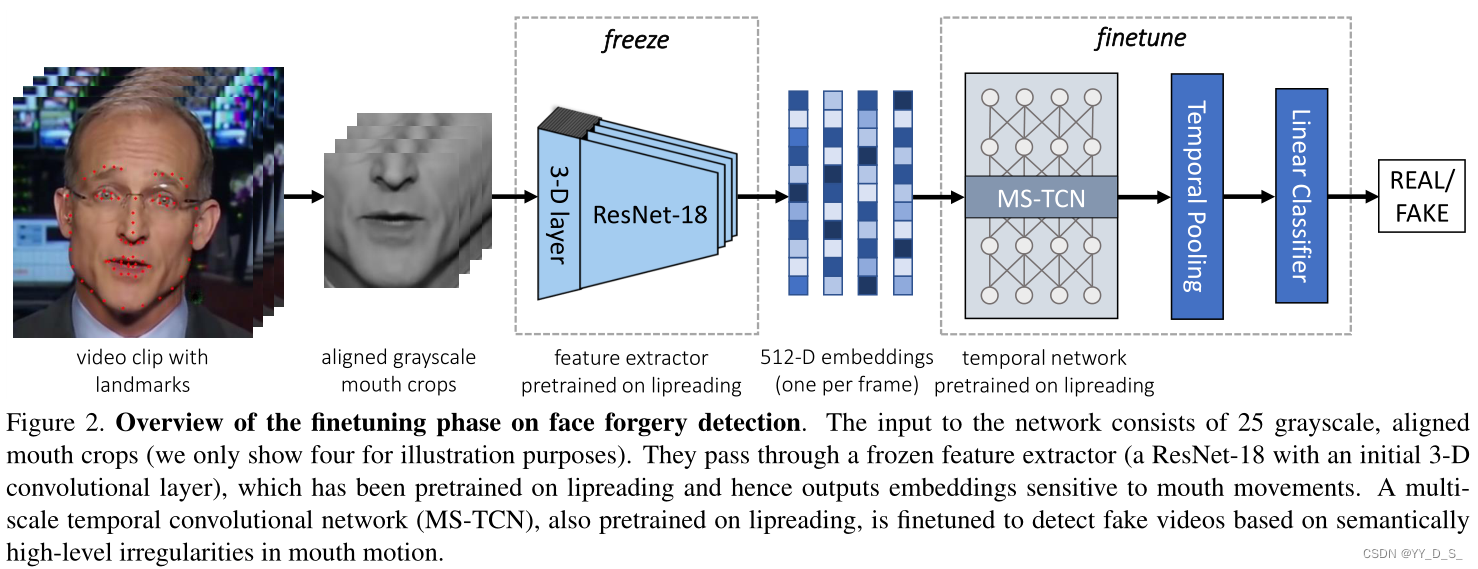
-
-
a ResNet-18 with an initial 3-D convolutional layer:特征提取器,已经过唇读训练。对每个输入帧输出a 512-D vector -
MS-TCN:多尺度时间卷积网络。通过连接多个分支的输出,将每一层的时间信息相结合,每个分支具有不同的时间感受野。(感受野定义:卷积神经网络每一层输出的特征图上的像素点在原始图像上映射的区域大小。)
-
TemporalPooling:时间全局平均池化层。避免过拟合,时间变换更加稳定。 -
Linear Classifier:线性分类器。
2.1 video clip with landmarks

-
1.用
RetinaFace对视频的每一帧检测出一张人脸,如果同一帧中有多个人脸,则取最大的人脸。 -
2.为了定位人脸嘴部,用FAN检测出68个人脸特征点。
2.2 aligned grayscale mouth crops

-
1.在每张人脸中 以嘴部地标的平均值为中心点 裁剪出96×96的区域。
-
2.每张图片中心点对齐。执行对齐是为了消除平移、缩放和旋转变化,它不会影响嘴部动作(嘴型)。
-
3.改为灰度图。
2.3 feature extractor
-
组成:
已经过唇读预训练的 带有3-D convolutional layer的a ResNet-18 -
唇读预训练方法:
-

-
训练过程
在
LipReading in the Wild(LRW)上训练。该方法包含500000张不同姿势说话人的话语。训练模型:
Towards practical lipreading with distilled and efficient models。由时空特征提取器、时间网络和线性分类器组成。损失函数:三个随机初始化的参数(与三个组成部分对应),去最小化交叉熵损失.f_l(x_l^j):预测值
-
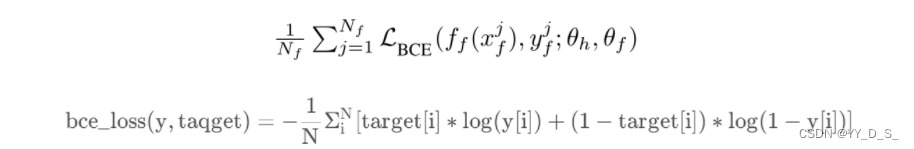
输出:512-D vector,对嘴部运动非常敏感的嵌入。
freeze:冻结就是预训练之后参数不变
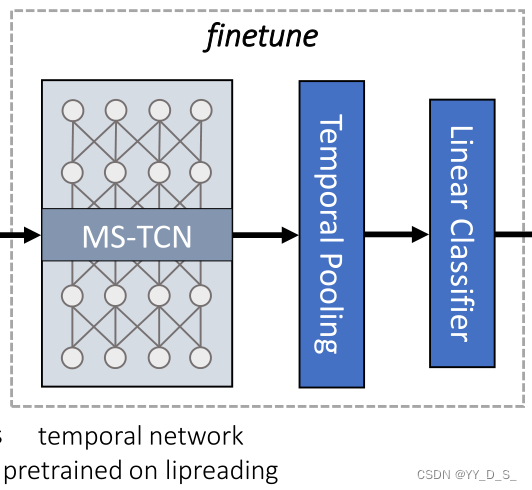
2.4 MS-TCN
-
-
-
训练参数:
\{(x_f^j,y_f^j)\}_{j=1}^{N_f}:大小为N_f的人脸伪造数据集。其中x_f^j是人脸帧,x_f^j \in X。y_f^j是真假标签,y_f^j \in \{0,1\}
-
训练过程:
基于上述网络结构。转移θg和θh,并将分类器替换为由θf参数化的二进制分类器。对时间网络进行调整,并从头训练分类器,以最小化二进制交叉熵损失。
-
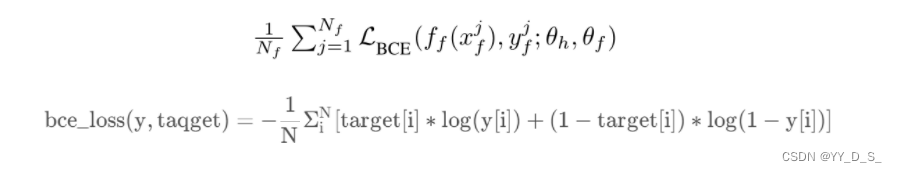
-
对时间网络的调整:
通过连接多个分支的输出,将每一层的短期和长期时间信息相结合,每个分支具有不同的时间感受野。在时间全局平均池化层之后,线性分类器输出估计分类的概率。
-
MS-TCN单个块的网络结构。网络总共有这样的4个块,第一个块中的膨胀率为1,每个后续块的膨胀率是前一个块的2倍。(膨胀率:卷积核间的间隔,改变感受野大小。膨胀率越大,感受野越大,获取的信息越多)
-
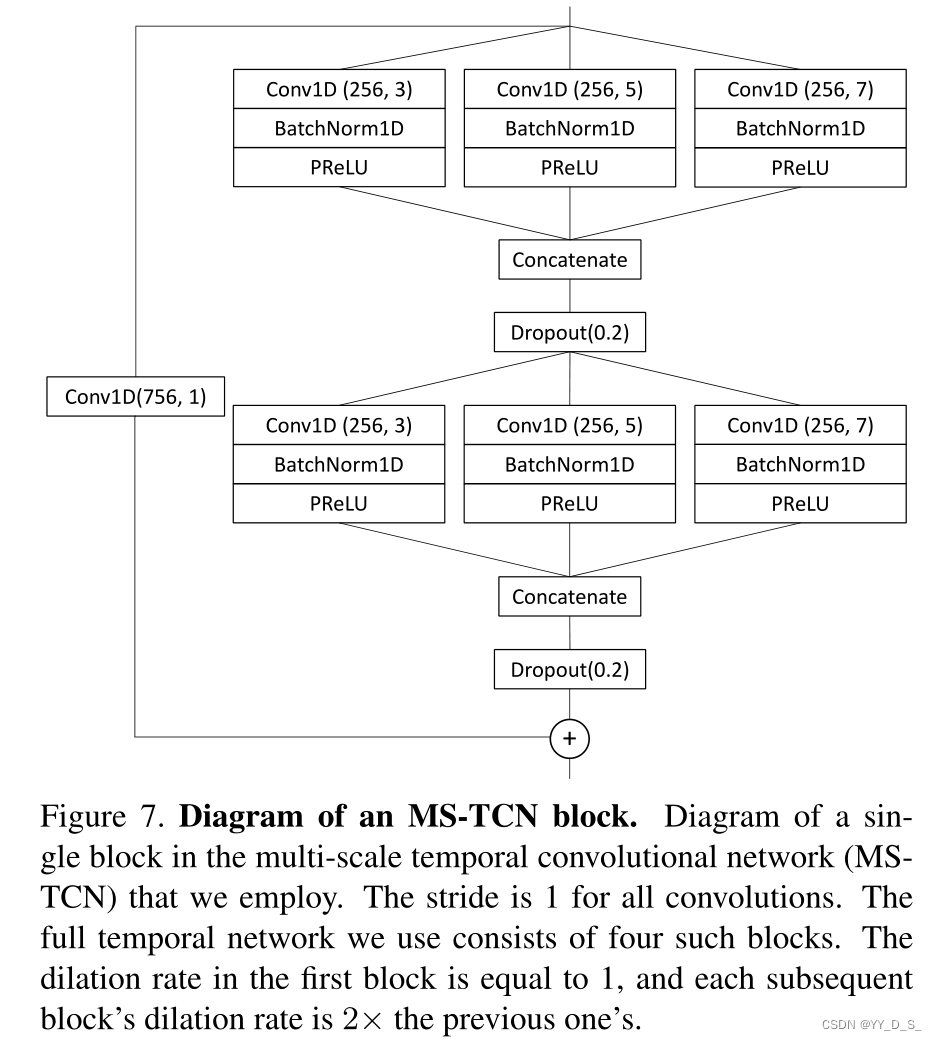
Conv1D(x,y):一维卷积层。x输出通道,y内核大小。
BatchNorm1D:归一化。归纳样本的统计分布性。
PReLU:参数化的激活函数,每个输入通道有一个单独的可学习参数。(激活函数作用:加入非线性因素,加强线性模型的表达能力)
Dropout(x):概率为x的下采样。解决数据分布不均衡,就是从多数集中选出一部分数据与少数集重新组合成一个新的数据集。
-
3.训练
-
训练数据集:FF++。
它包含180万个操纵帧和4000个假视频,使用两种人脸交换算法DeepFakes和FaceSwap以及两种人脸重建方法Face2Face和NeuralTextures生成。只对每个训练视频使用前270帧,对每个验证/测试视频使用前110帧。
-
参数设置:
batch size:32
优化器:Adam optimisation
学习率:2*10^{-4}
-
结果:
-
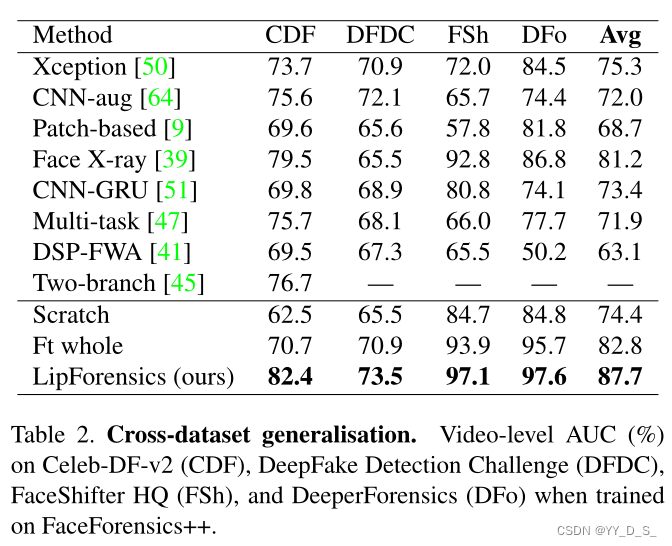
-
鲁棒性:
干扰:饱和度变化、对比度变化、添加块失真、添加高斯白噪声、模糊、像素化和应用视频压缩
-

结果(不同干扰类型的5种强度等级):
-
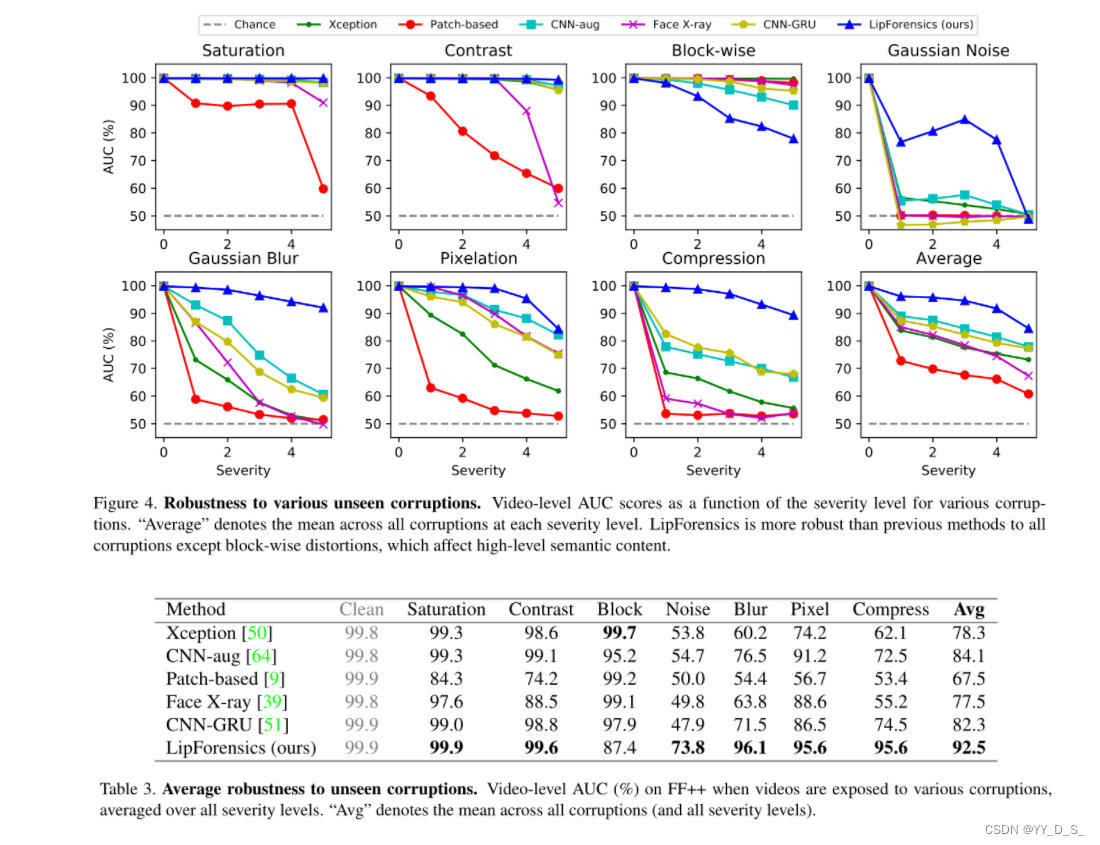
-
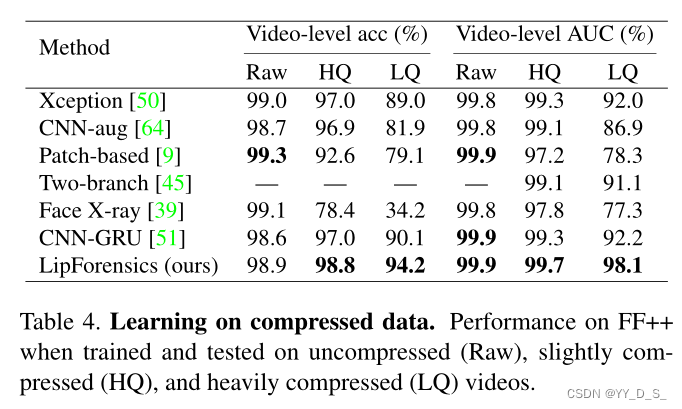
压缩训练:
在未压缩(Raw)、轻度压缩(HQ)和重度压缩(LQ)视频上进行训练和测试时,FF++的性能。
-
4.局限性
无法用于嘴部被遮挡的视频
如果没有说话,性能下降
语言不同,唇读难识别

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)