决策树构建
熵是信息论中衡量随机事件不确定性的核心概念,描述了一个系统或变量结果的“混乱程度”或“未知性”。简单来说,熵值越高,意味着结果的不确定性越强;熵值越低,结果越确定。
决策树知识概要
决策树定义
决策树是一种监督学习算法模型,用于分类和回归任务。其结构类似树状,由根节点、内部节点和叶子节点组成,通过对特征属性的逐层分裂,将样本空间划分为不同子区域,最终基于叶子节点的类别或数值输出决策结果,具有直观易解释的特点。
例子:
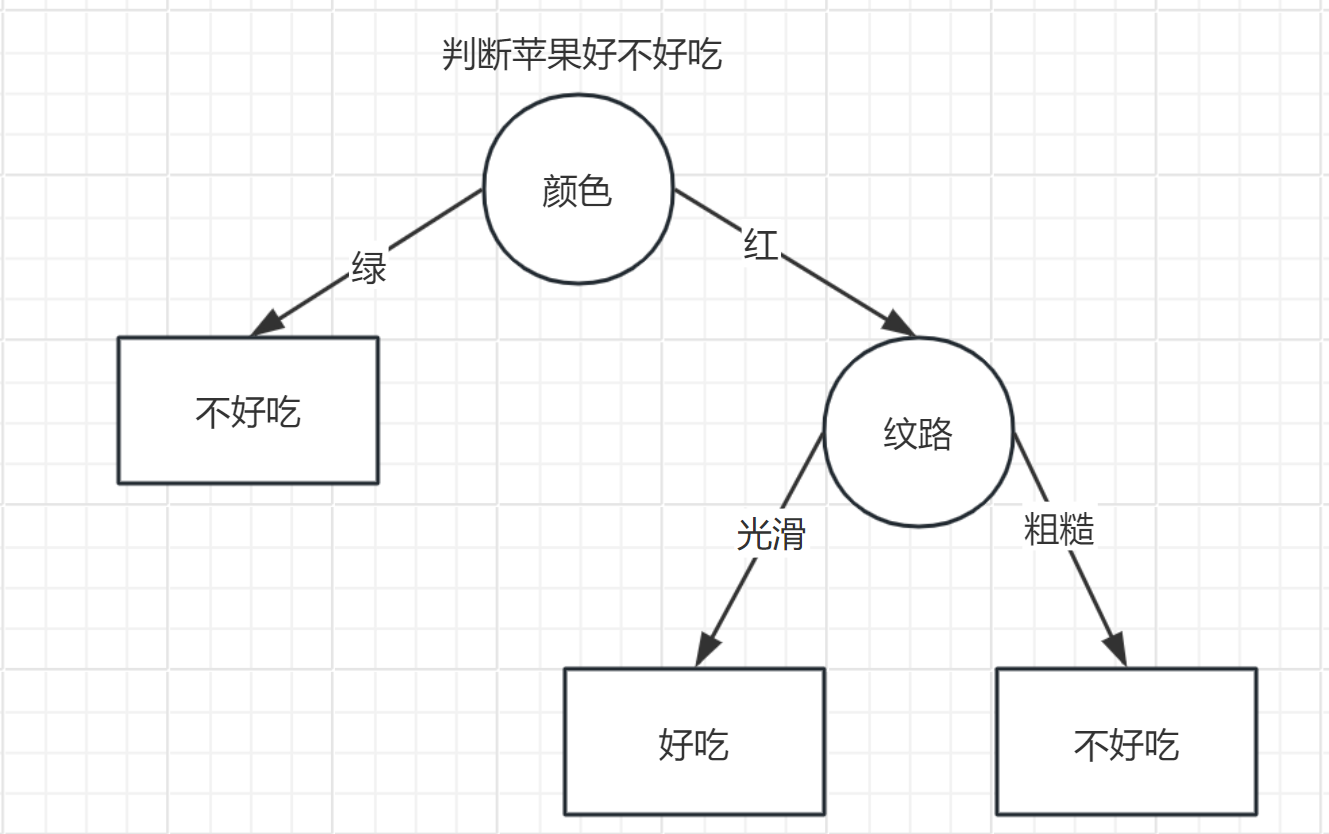
熵
熵的定义
熵是信息论中衡量随机事件不确定性的核心概念,描述了一个系统或变量结果的“混乱程度”或“未知性”。简单来说,熵值越高,意味着结果的不确定性越强;熵值越低,结果越确定。
熵在决策树中的作用
在决策树算法中,熵的主要作用是评估数据的“纯度”。ID3算法中,通过计算分裂前后数据子集的熵变化(即信息增益),算法可以选择最能降低不确定性的特征作为节点,从而让决策树的分支更有效地区分不同类别样本,提升模型分类的准确性。熵帮助算法量化特征对数据划分的价值,是构建高效决策树的关键工具。
熵的计算公式
H ( X ) = − ∑ i = 1 n p ( x i ) l o g 2 p ( x i ) H(X)=- \sum_{i=1}^{n} p(x_i)log_2p(x_i) H(X)=−i=1∑np(xi)log2p(xi)
计算熵的代码实现如下:
def entropy(labels):
num_labels = len(labels)
if num_labels == 0:
return 0
label_counts = Counter(labels)
entropy_value = 0
for count in label_counts.values():
probability = count / num_labels
entropy_value -= probability * math.log2(probability)
return entropy_value
条件熵
H ( X ∣ Y ) = − ∑ x , y p ( x , y ) l o g ( p ( x ∣ y ) ) H(X|Y)=-\sum_{x,y}p(x,y)log(p(x|y)) H(X∣Y)=−x,y∑p(x,y)log(p(x∣y))
信息增益
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V} \frac{|D_v|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
计算信息增益的代码实现如下:
def information_gain(parent_labels, splits):
parent_entropy = entropy(parent_labels)
total = len(parent_labels)
return parent_entropy - sum(
(len(split)/total)*entropy(split)
for split in splits.values()
)
基尼(Gini)系数
在使用CART算法时需要使用基尼系数进行评估
基尼系数的计算
G i n i ( X ) = 1 − ∑ i = 1 k p i 2 Gini(X)=1-\sum_{i=1}^{k} p_i^2 Gini(X)=1−i=1∑kpi2
计算基尼指数的代码实现如下:
def gini(labels):
counts = Counter(labels)
total = len(labels)
return 1 - sum((count/total)**2 for count in counts.values())
决策树的构建
构建流程
(1)选择最佳的划分属性
用信息增益等标准评估属性,选提升子集纯度最大的属性,决定节点分裂,影响分类性能。
(2)构建子树
按划分属性将数据集划分子集,递归创建子节点,重复选属性操作,形成树状结构分类数据。
(3)剪枝处理
用预剪枝或后剪枝,去除贡献小的节点分支,解决过拟合问题,提高模型泛化能力。
(4)生成决策树
经属性划分、子树构建与剪枝,得到模型,依数据属性判断输出分类或预测结果 。
决策树构建方法
决策树有三种方法构建:分别为ID3算法,C4.5算法,CART算法
三种构建方法的区别
(1)ID3算法
ID3算法以信息增益为准则来进行选择划分属性,选择信息增益最大的。
(2)C4.5算法
C4.5算法选择增益率最高的。
(3)CART算法
CART算法使用基尼指数来选择划分属性,选择基尼指数最小的属性作为划分属性,
决策树构建实现
本次实验选取其中两种构建方式进行
(1)ID3算法
import math
from collections import Counter
def read_data(filename):
with open(filename, 'r') as f:
data = [line.strip().split(',') for line in f]
return [sample[:-1] for sample in data], [sample[-1] for sample in data]
def entropy(labels):
counts = Counter(labels)
total = len(labels)
return -sum((count / total) * math.log2(count / total) for count in counts.values())
def information_gain(parent_labels, splits):
parent_entropy = entropy(parent_labels)
total = len(parent_labels)
return parent_entropy - sum(
(len(split) / total) * entropy(split)
for split in splits.values()
)
def best_split_id3(X, y, features):
best_gain = -1
best_feature = None
for feature in features:
splits = {}
for i, val in enumerate([x[feature] for x in X]):
splits.setdefault(val, []).append(y[i])
gain = information_gain(y, splits)
if gain > best_gain:
best_gain = gain
best_feature = feature
return best_feature
def build_id3(X, y, features):
if len(set(y)) == 1:
return y[0]
if not features:
return Counter(y).most_common(1)[0][0]
best_feature = best_split_id3(X, y, features)
tree = {best_feature: {}}
new_features = [f for f in features if f != best_feature]
feature_values = set(sample[best_feature] for sample in X)
for value in feature_values:
sub_X = [x for x in X if x[best_feature] == value]
sub_y = [y[i] for i, x in enumerate(X) if x[best_feature] == value]
tree[best_feature][value] = build_id3(sub_X, sub_y, new_features)
return tree
X_train, y_train = read_data('dataset.txt')
features = list(range(len(X_train[0])))
id3_tree = build_id3(X_train, y_train, features)
print("ID3决策树结构:", id3_tree)
(2)CART算法
from collections import Counter
def read_data(filename):
with open(filename, 'r') as f:
data = [line.strip().split(',') for line in f]
return [sample[:-1] for sample in data], [sample[-1] for sample in data]
def gini(labels):
counts = Counter(labels)
total = len(labels)
return 1 - sum((count / total) ** 2 for count in counts.values())
def gini_for_feature(X, y, feature):
splits = {}
for i, val in enumerate([x[feature] for x in X]):
splits.setdefault(val, []).append(y[i])
return sum((len(split) / len(y)) * gini(split) for split in splits.values())
def best_split_cart(X, y, features):
best_gini = float('inf')
best_feature = None
for feature in features:
splits = {}
for i, val in enumerate([x[feature] for x in X]):
splits.setdefault(val, []).append(y[i])
gini_val = sum((len(split) / len(y)) * gini(split) for split in splits.values())
if gini_val < best_gini:
best_gini, best_feature = gini_val, feature
return best_feature
def build_cart(X, y, features):
if len(set(y)) == 1:
return y[0]
if not features:
return Counter(y).most_common(1)[0][0]
best_feature = best_split_cart(X, y, features)
tree = {best_feature: {}}
feature_values = set(sample[best_feature] for sample in X)
for value in feature_values:
sub_X = [x for x in X if x[best_feature] == value]
sub_y = [y[i] for i, x in enumerate(X) if x[best_feature] == value]
tree[best_feature][value] = build_cart(sub_X, sub_y, features)
return tree
X_train, y_train = read_data('dataset.txt')
features = list(range(len(X_train[0])))
print("候选特征基尼指数:")
for i in features:
print(f"特征{i}: {gini_for_feature(X_train, y_train, i):.3f}")
cart_tree = build_cart(X_train, y_train, features)
print("\nCART决策树结构:", cart_tree)
决策树构建结果
实验结果: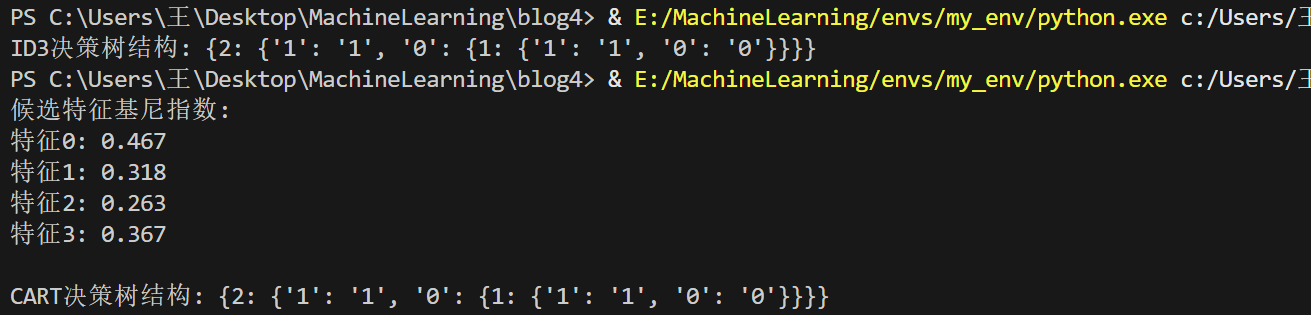
本次用ID3和CART算法构建决策树,ID3基于信息增益,CART基于基尼指数。在该训练集和测试集上,二者生成的决策树结构一致,均以特征2为根节点,并且CART输出的特征2基尼指数最小,表明特征2在两种评估标准下最优。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)