Geometric Transformer for Fast and Robust Point Cloud Registration
Geometric Transformer for Fast and Robust Point Cloud Registration阅读笔记
Abstract
提出了一种无关键点的点云配准方法,跳过了传统关键点检测的步骤,适用于低重叠场景。该方法通过对下采样的超点进行配准,简化了配准的流程。同时该模型能够学习几何特征,尤其是点对之间的距离pair-wise distances和三点之间的角度triplet-wise angles,从而增强低重叠场景下的鲁棒性,并且对刚体变换具有不变性。同时Geometric Transformer没有使用传统的RANSAC算法来估计配准变换,而是使用了Local-to-Global Registration,并实现了100倍的加速。此外,模型的性能也非常好。
Introduction
介绍了GeoTransformer,其核心目的是在低重叠场景中实现快速、准确的点云配准。该方法采用无关键点和无RANSAC的策略,提高了点云配准的效率和准确性。
背景:点云配准是计算机图形学、计算机视觉和机器人领域的基础任务。随着3D点表示学习和可微优化的快速发展,最近对这一问题的研究获得了新的关注。现有的许多基于学习和对应关系的方法通常依赖于关键点检测,但在重叠区域较小的情况下,这种方法效果不佳,导致配准结果的内点比率较低。
GeoTransformer的设计:为了克服这一问题,GeoTransformer通过下采样输入点云为超点,并通过局部邻域的重叠情况进行匹配。GeoTransformer专注于通过点对之间的距离和点三元组之间的角度来学习几何特征,从而实现变换不变的几何表示。该模型利用自注意力机制来加权重要的超点,有效提取点云的几何结构。
创新损失函数:为实现更好的收敛性,GeoTransformer引入了一种重叠感知圆损失,使模型专注于具有较高重叠的超点对,从而进一步提升配准的准确性。
Related work
Correspondence-based Methods
这一部分是基于对应的方法的思路,首先提取两个点云之间的对应关系,然后利用鲁棒的位姿估计器(如RANSAC)来恢复变换。
根据提取对应关系的方式,可以分为两类:
第一类专注于检测可重复性更高的关键点(keypoint),以便在匹配时提供更可靠的信息。具体包括一些利用深度学习技术来优化关键点描述符的方法。
第二类则不依赖于关键点检测,而是考虑所有可能的匹配。通过全局匹配策略来寻找点云之间的对应关系。
Direct Registration Methods
直接配准方法通过神经网络直接估计点云之间的变换,而无需依赖传统的关键点检测和对应关系提取。直接配准方法可以进一步分为两类:第一类遵循迭代最近点(ICP)的思想,建立软对应关系并通过可微分的加权奇异值分解计算变换。第二类首先为每个点云提取全局特征向量,然后利用这些全局特征向量来回归变换。
Deep Robust Estimators
传统的鲁棒估计器(例如RANSAC)在高比例异常值的情况下,通常面临收敛速度慢和不稳定性的问题。研究者们提出了深度鲁棒估计器作为替代方案,通常包含一个分类网络,用于识别和排除异常值,同时还有一个估计网络用于计算变换。相比之下,本研究的方法采用了一种无参数的局部到全局配准方案,能够实现快速和准确的点云配准。
Method
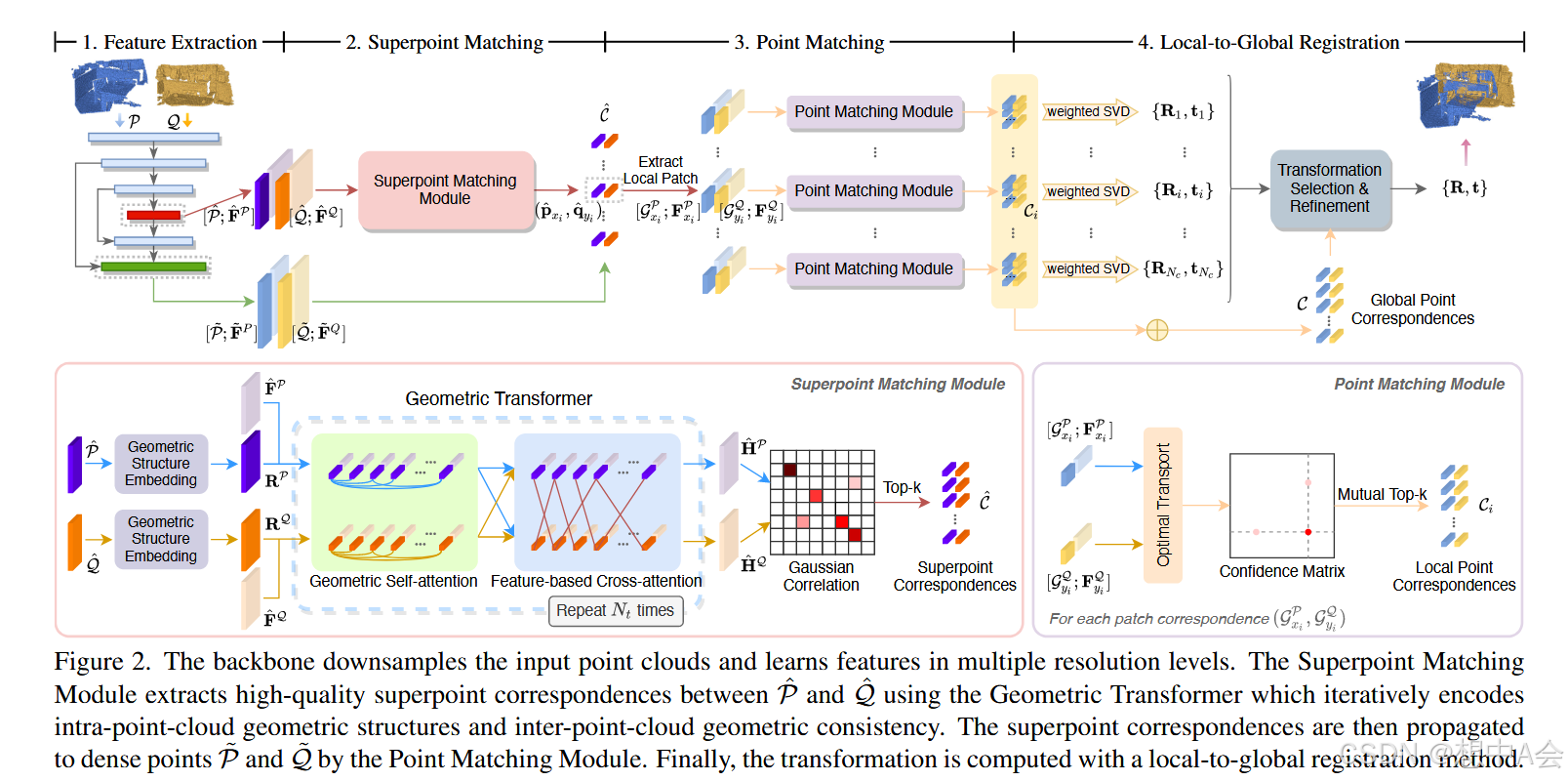
首先,使用KPConv-FPN对输入点云进行下采样并提取点特征,得到密集点和超点。接着,通过超点匹配模块提取邻近局部补丁重叠的超点对应关系,并利用点匹配模块将超点对应关系细化为密集点匹配。
Superpoint Sampling and Feature Extraction
这一部分是关于如何利用KPConv-FPN网络提取点云的多层特征,并进行下采样的过程。点云配准可以通过点集的对应关系来实现。下采样的超点被记作和
,关联的特征矩阵是
和
,对于密集点的采样,同理记作
和
,对应的特征矩阵是
和
,然后对于每个超点,通过点到节点的分组策略构建局部补丁,也就是每个普通点去找几何空间中离它最近的超点。最后移除空补丁的超点(也就是没有普通点匹配的)。
Superpoint Matching Module
本文提出的模型既可以编码高层特征,又可以捕捉点云内部几何结构和点云间的几何一致性。该模型包含几何自注意力模块和基于特征的交叉注意力模块,交替进行混合特征的提取。
几何自注意力模块学习超点间的全局关联,权重系数通过归一化的softmax进行计算,这里参考attention的计算。对于交叉注意力,适用于输入点云间的特征交换,过程类似于几何自注意力模块。
Point Matching Module
这一部分是如何从超点对应关系中提取点对应关系。通过超点匹配解决了全局模糊性以后,就可以通过局部特征来进行点级的匹配。对于每个超点的对应关系,首先需要计算一个成本矩阵,描述两个点云中局部点之间的相似度。然后将成本矩阵进行增强,方便后续更好地匹配,接下来通过Sinkhorn算法处理增强后的矩阵,得到最终的结果,并提取点的对应关系。
RANSAC-free Local-to-Global Registration
这一部分提出了一种新的点云配准方案—LGR,传统的方法依赖于RANSAC这种稳健估计器,但是其开销大而且速度慢,因此引入了LGR。
首先是local阶段,原理就是对于每个点,找到与其匹配的最近的超点,就是密集点找超点。然后是global阶段,目的是从得到的多个候选变换中选择最优的全局变换,来最大化匹配点对数量的变换。总的来说,局部阶段为每个超点匹配求解局部变换,通过最小化局部点对的误差来得到局部对齐。全局阶段从所有局部变换中,选择能够最大化全局匹配数量的那个变换,并进一步通过内点匹配迭代优化。
Loss Function
这一部分是损失函数的计算,定义了两种损失函数,分别是重叠感知的圆圈损失用于超点匹配,以及点匹配损失用于点匹配。
Overlap-aware circle loss
普通方法将超点匹配视为一个多标签分类问题,使用交叉熵损失来分区并匹配,但是该方法会导致正样本类别的高置信度被抑制,因此作者采用了重叠感知的圆圈损失,并通过对重叠度高的匹配赋予更多的权重。
Point matching loss
采用负对数似然损失来衡量点的匹配质量。
将上述的两个损失函数相加得到最终的整体损失。
多标签分类
在超点匹配问题中,每个超点可能会匹配多个其他超点,这就是多标签分类问题。每个超点在目标点云中对应的多个超点被标记为正样本,而没有对应关系的超点被标记为负样本。当模型对某个正样本已经预测得很好,也就是说模型给出了较高的置信度(接近1),此时交叉熵损失的梯度就会变得很小。模型的学习力度会变弱,参数更新的幅度也很小。因此使用度量学习来代替交叉熵损失。
Experiments
首先是室内数据集的评估,使用了3DMatch和3DLoMatch两个数据集,和很多方法进行了对比,发现确实优于其它的方法,而且在低重叠的场景中也表现出色。
然后是室外数据集的对比,在KITTI odometry数据集上的表现表明,它不仅能够与当前最好的RANSAC方法抗衡,还能在与非RANSAC方法的比较中表现出色,特别是在配准精度和鲁棒性方面。使用LGR(基于局部几何的鲁棒配准)时,GeoTransformer在RTE和RRE上超越了所有基于RANSAC的方法。
Conclusion
Geometric Transformer是一种用于点云配准的几何变换模型,旨在通过从粗到精的对应关系学习实现稳健的点云配准。该方法通过编码超点(superpoints)之间的成对距离和三点角度来捕捉点云之间的几何一致性,并且对变换具有不变性。这种方法可以在不依赖RANSAC的情况下,实现快速且准确的配准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)